7 posts tagged “steve-krouse”
2025
The fact that MCP is a difference surface from your normal API allows you to ship MUCH faster to MCP. This has been unlocked by inference at runtime
Normal APIs are promises to developers, because developer commit code that relies on those APIs, and then walk away. If you break the API, you break the promise, and you break that code. This means a developer gets woken up at 2am to fix the code
But MCP servers are called by LLMs which dynamically read the spec every time, which allow us to constantly change the MCP server. It doesn't matter! We haven't made any promises. The LLM can figure it out afresh every time
When you vibe code, you are incurring tech debt as fast as the LLM can spit it out. Which is why vibe coding is perfect for prototypes and throwaway projects: It's only legacy code if you have to maintain it! [...]
The worst possible situation is to have a non-programmer vibe code a large project that they intend to maintain. This would be the equivalent of giving a credit card to a child without first explaining the concept of debt. [...]
If you don't understand the code, your only recourse is to ask AI to fix it for you, which is like paying off credit card debt with another credit card.
— Steve Krouse, Vibe code is legacy code
There's a new kind of coding I call "hype coding" where you fully give into the hype, and what's coming right around the corner, that you lose sight of whats' possible today. Everything is changing so fast that nobody has time to learn any tool, but we should aim to use as many as possible. Any limitation in the technology can be chalked up to a 'skill issue' or that it'll be solved in the next AI release next week. Thinking is dead. Turn off your brain and let the computer think for you. Scroll on tiktok while the armies of agents code for you. If it isn't right, tell it to try again. Don't read. Feed outputs back in until it works. If you can't get it to work, wait for the next model or tool release. Maybe you didn't use enough MCP servers? Don't forget to add to the hype cycle by aggrandizing all your successes. Don't read this whole tweet, because it's too long. Get an AI to summarize it for you. Then call it "cope". Most importantly, immediately mischaracterize "hype coding" to mean something different than this definition. Oh the irony! The people who don't care about details don't read the details about not reading the details
What we learned copying all the best code assistants (via) Steve Krouse describes Val Town's experience so far building features that use LLMs, starting with completions (powered by Codeium and Val Town's own codemirror-codeium extension) and then rolling through several versions of their Townie code assistant, initially powered by GPT 3.5 but later upgraded to Claude 3.5 Sonnet.
This is a really interesting space to explore right now because there is so much activity in it from larger players. Steve classifies Val Town's approach as "fast following" - trying to spot the patterns that are proven to work and bring them into their own product.
It's challenging from a strategic point of view because Val Town's core differentiator isn't meant to be AI coding assistance: they're trying to build the best possible ecosystem for hosting and iterating lightweight server-side JavaScript applications. Isn't this stuff all a distraction from that larger goal?
Steve concludes:
However, it still feels like there’s a lot to be gained with a fully-integrated web AI code editor experience in Val Town – even if we can only get 80% of the features that the big dogs have, and a couple months later. It doesn’t take that much work to copy the best features we see in other tools. The benefits to a fully integrated experience seems well worth that cost. In short, we’ve had a lot of success fast-following so far, and think it’s worth continuing to do so.
It continues to be wild to me how features like this are easy enough to build now that they can be part-time side features at a small startup, and not the entire project.
2024
Cerebras Coder (via) Val Town founder Steve Krouse has been building demos on top of the Cerebras API that runs Llama3.1-70b at 2,000 tokens/second.
Having a capable LLM with that kind of performance turns out to be really interesting. Cerebras Coder is a demo that implements Claude Artifact-style on-demand JavaScript apps, and having it run at that speed means changes you request are visible within less than a second:
Steve's implementation (created with the help of Townie, the Val Town code assistant) demonstrates the simplest possible version of an iframe sandbox:
<iframe
srcDoc={code}
sandbox="allow-scripts allow-modals allow-forms allow-popups allow-same-origin allow-top-navigation allow-downloads allow-presentation allow-pointer-lock"
/>
Where code is populated by a setCode(...) call inside a React component.
The most interesting applications of LLMs continue to be where they operate in a tight loop with a human - this can make those review loops potentially much faster and more productive.
Building search-based RAG using Claude, Datasette and Val Town
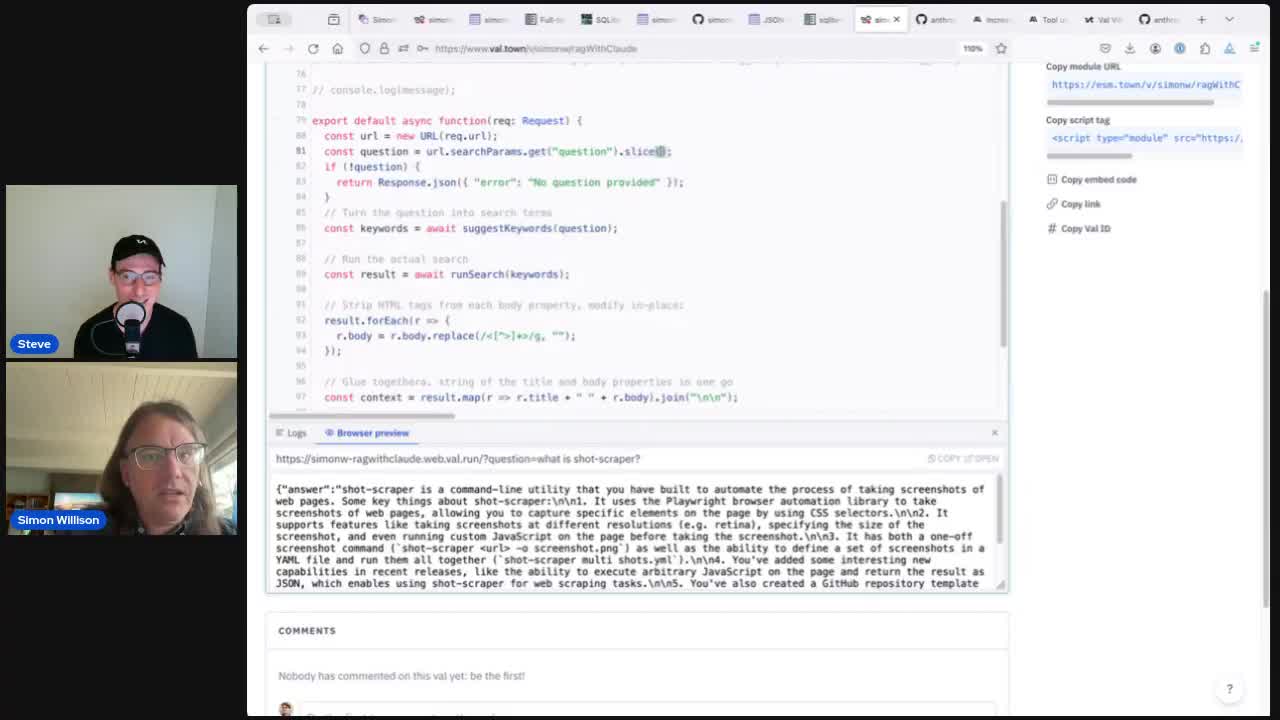
Retrieval Augmented Generation (RAG) is a technique for adding extra “knowledge” to systems built on LLMs, allowing them to answer questions against custom information not included in their training data. A common way to implement this is to take a question from a user, translate that into a set of search queries, run those against a search engine and then feed the results back into the LLM to generate an answer.
[... 3,372 words]Val Town Newsletter 15 (via) I really like how Val Town founder Steve Krouse now accompanies their “what’s new” newsletter with a video tour of the new features. I’m seriously considering imitating this for my own projects.