79 posts tagged “urls”
2025
Decentralizing Schemes. Tim Bray discusses the challenges faced by decentralized Mastodon in that shared URLs to posts don't take into account people accessing Mastodon via their own instances, which breaks replies/likes/shares etc unless you further copy and paste URLs around yourself.
Tim proposes that the answer is URIs: a registered fedi://mastodon.cloud/@timbray/109508984818551909 scheme could allow Fediverse-aware software to step in and handle those URIs, similar to how mailto: works.
Bluesky have registered at: already, and there's also a web+ap: prefix registered with the intent of covering ActivityPub, the protocol used by Mastodon.
It frustrates me when support sites for online services fail to link to the things they are talking about. Cloudflare's Find zone and account IDs page for example provides a four step process for finding my account ID that starts at the root of their dashboard, including a screenshot of where I should click.
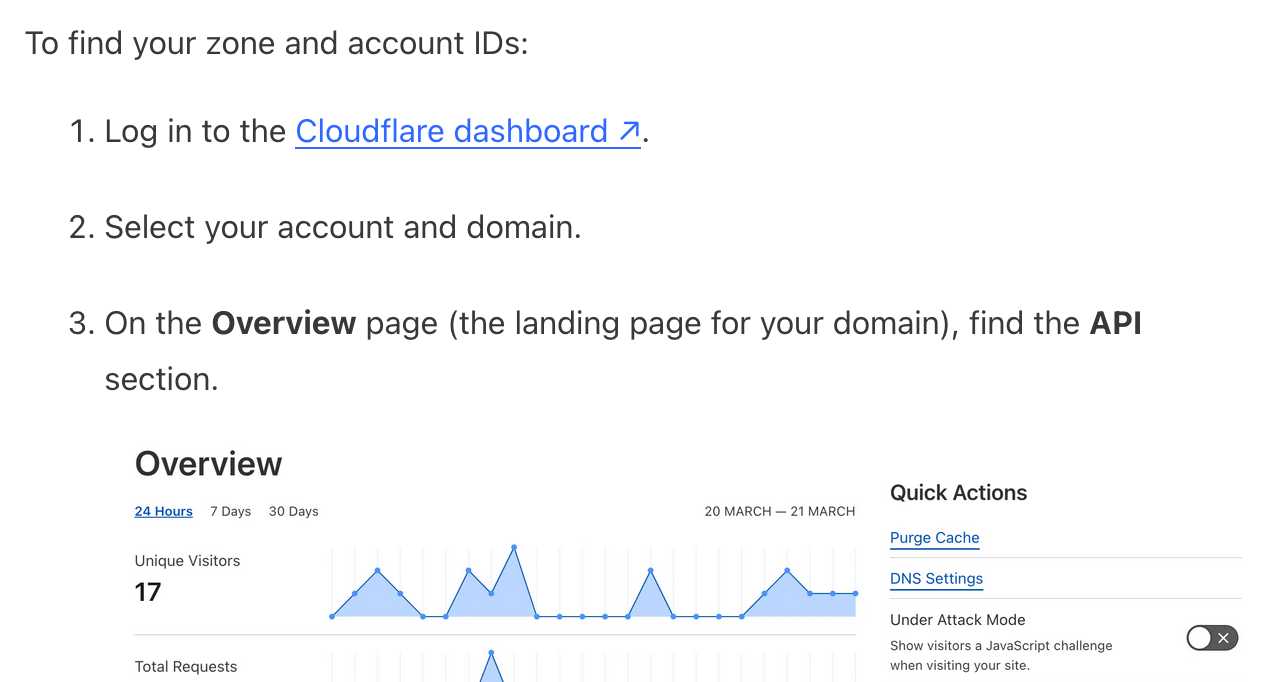
In Cloudflare's case it's harder to link to the correct dashboard page because the URL differs for different users, but that shouldn't be a show-stopper for getting this to work. Set up dash.cloudflare.com/redirects/find-account-id and link to that!
... I just noticed they do have a mechanism like that which they use elsewhere. On the R2 authentication page they link to:
https://dash.cloudflare.com/?to=/:account/r2/api-tokens
The "find account ID" flow presumably can't do the same thing because there is no single page displaying that information - it's shown in a sidebar on the page for each of your Cloudflare domains.
URL-addressable Pyodide Python environments
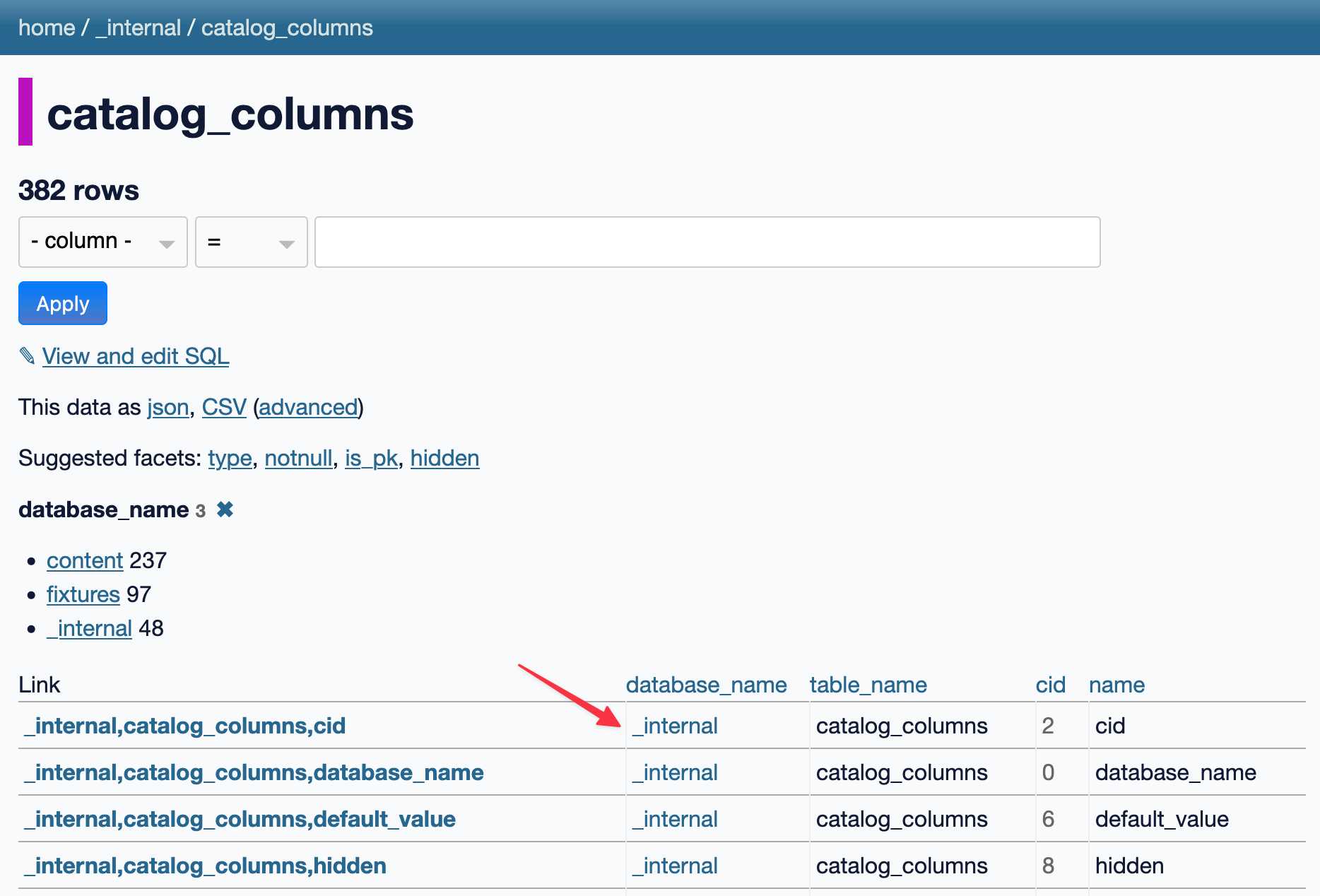
This evening I spotted an obscure bug in Datasette, using Datasette Lite. I figure it’s a good opportunity to highlight how useful it is to have a URL-addressable Python environment, powered by Pyodide and WebAssembly.
[... 1,905 words]2024
New Django {% querystring %} template tag. Django 5.1 came out last week and includes a neat new template tag which solves a problem I've faced a bunch of times in the past.
{% querystring color="red" size="S" %}
Adds ?color=red&size=S to the current URL - keeping any other existing parameters and replacing the current value for color or size if it's already set.
{% querystring color=None %}
Removes the ?color= parameter if it is currently set.
If the value passed is a list it will append ?color=red&color=blue for as many items as exist in the list.
You can access values in variables and you can also assign the result to a new template variable rather than outputting it directly to the page:
{% querystring page=page.next_page_number as next_page %}
Other things that caught my eye in Django 5.1:
- PostgreSQL connection pools.
- The new LoginRequiredMiddleware for making every page in an application require login.
- The SQLite database backend now accepts init_command for settings things like
PRAGMA cache_size=2000on new connections. - SQLite can also be passed
"transaction_mode": "IMMEDIATE"to configure the behaviour of transactions.
2023
trurl manipulates URLs.
Brand new command-line tool from curl creator Daniel Stenberg: The tr stands for translate or transpose, and the tool provides various mechanisms for normalizing URLs, adding query strings, changing the path or hostname and other similar modifications. I’ve tried designing APis for this kind of thing in the past—Datasette includes some clumsily named functions such as path_with_removed_args()—and it’s a deceptively deep set of problems.
.
2022
Why I invented “dash encoding”, a new encoding scheme for URL paths
Datasette now includes its own custom string encoding scheme, which I’ve called dash encoding. I really didn’t want to have to invent something new here, but unfortunately I think this is the best solution to my very particular problem. Some notes on how dash encoding works and why I created it.
[... 1,392 words]2020
Datasette 0.51 (plus weeknotes)
I shipped Datasette 0.51 today, with a new visual design, plugin hooks for adding navigation options, better handling of binary data, URL building utility methods and better support for running Datasette behind a proxy. It’s a lot of stuff! Here are the annotated release notes.
[... 2,020 words]2019
Microbrowsers are Everywhere (via) Colin Bendell introduces a new-to-me term, “microbrowsers”, to describe the user-agents which hit websites to generate unfurled link previews in messenger apps. Twitter and Facebook first popularized them, but today you’re likely getting far more preview-generating traffic from chat clients such as iMessage, WhatsApp and Slack (which won’t execute script and ignore cookies, and hence won’t show up in Google Analytics). Lots of great tips here—one example: if you provide three og:image meta tags iMessage will render them as a collage.
2017
Removing MediaWiki from SPA: Cool URIs don’t change (via) Detailed write-up from Anna Shipman describing how she archived an old MediaWiki as static content using recursive wget and some cunning application of mod_rewrite.
Recovering missing content from the Internet Archive
When I restored my blog last weekend I used the most recent SQL backup of my blog’s database from back in 2010. I thought it had all of my content from before I started my 7 year hiatus, but in watching the 404 logs I started seeing the occasional hit to something that really should have been there but wasn’t. Turns out the SQL backup I was working from was missing some content.
[... 636 words]2013
What do Twitter and Gawker think of hash-bangs URLs?
As of December 2013 (and potentially much earlier, I don’t have the exact dates) both Twitter and a Gawker have moved away from hash bang URLs, so my guess is they turned out not to be a good idea.
[... 82 words]How to find the URL of a page in an iframe?
You can’t, as this would be a security and privacy violation. Imagine an evil website which loads up Google in a full page iframe and then tracks what the unsuspecting user searches for and clicks on.
[... 125 words]2012
What is the most efficient way to lookup an object (e.g. a user) by only a string?
Yes—an index on a varchar column is exactly how you would implement this.
[... 38 words]Is there an API that returns metadata for a given URL?
I suggest taking a look at http://embed.ly/—it can take a huge range of URLs and turn them in to JSON metadata. Here’s what it can do with a Wikipedia page: http://embed.ly/docs/explore/obj...—and here’s Google Maps URL (not as useful, but still some interesting metadata extracted) http://embed.ly/docs/explore/obj...
[... 69 words]How did art.sy get a “.sy” url?
Here’s a generally useful tip: if you’re interested in learning more about ANY top level domain, visit the Wikipedia page for it—which will be http://en.wikipedia.org/wiki/.sy in this case (just add the domain, complete with its dot prefix, directly after en.wikipedia.org/wiki/ ).
[... 105 words]Which sites have the best URL design?
GitHub’s URL design is fantastic—it’s a virtually flawless mapping of Git semantics to URL space. Their basic URL structure is excellent, but they also have a bunch of neat URL hacks going on. Here are a few of my favourites:
[... 97 words]When referring to our web site in publications (or Twitter or Facebook), when is it important to provide the full URL—http://www.mywebsite.com and when should you provide just the mywebsite.com?
You have no control over how other publications refer to your site—if you’re lucky, they might spell it correctly and check the link works before publishing (but I wouldn’t bet on it). What you DO have control over is making sure you compensate for any mistakes they make.
[... 166 words]How did slashes become the standard path separators for URLs?
I’m going to take an educated guess and say it’s because of unix file system conventions. Early web servers mapped the URL to a path on disk inside the document root—this is still how most static sites work today.
[... 57 words]How do you find the new URL of a Tumblr that has moved?
One trick that might work is to look up the old tumble in the Google cache or on archive.org, then copy and paste a unique search phrase from that page and run a Google search for:
[... 72 words]2011
URLs are supposed to represent resources. A web app can be a resource, and there are techniques for managing state within those. Hashbangs might be one of these. But when large web properties are converting all their links to articles and other bits of text (tweets/twits/whatever) into these monstrosities, it’s not innovation. It’s a huge mistake that ought to be regretted now and will certainly be regretted in the future.
Before events took this bad turn, the contract represented by a link was simple: “Here’s a string, send it off to a server and the server will figure out what it identifies and send you back a representation.” Now it’s along the lines of: “Here’s a string, save the hashbang, send the rest to the server, and rely on being able to run the code the server sends you to use the hashbang to generate the representation.” Do I need to explain why this is less robust and flexible? This is what we call “tight coupling” and I thought that anyone with a Computer Science degree ought to have been taught to avoid it.
— Tim Bray
Going Postel. Jeremy points out that one of the many disadvantages of publishing JavaScript dependent content on the Web is that a single typo can render your entire site unusable.
Breaking the Web with hash-bangs. Mike Davies explains why Gawker’s new Ajax fragment-tastic redesign is a web architecture error of colossal proportions.
Is there a way of tracking shortened URLs with Twitter streaming API?
Think about it like this: the whole point of the Twitter streaming API is to get you the tweets as soon after they are posted as possible. If the API were to provide access to the lengthened URLs, it would have to delay emitting a Tweet on to the stream until a resolver had gone through each shortened URL in the tweet and checked to find what it redirects to. This would mean that the speed with which the streaming API could deal out tweets would be dependent on the speed of the third party servers that serve up the redirects. I doubt Twitter would ever want to implement this.
[... 159 words]Getting Started—Google URL Shortener API. The API for the goo.gl URL shortener is really nice—no API key required, easy to create a short URL and you can retrieve detailed stats breakdowns (similar to bit.ly) as JSON for any URL.
Could browsers be made to scroll down (e.g. by 67%) if you add #67% to a URL?
I’d say no.
[... 89 words]2010
URL Design. Thoughtful tips on modern URL design, from GitHub designer Kyle Neath. GitHub has the best designed URLs of any application I can think of.
Is it a good idea to allocate URLs such as quora.com/username to users?
There’s an interesting discussion about this issue on this question: How do sites prevent vanity URLs from colliding with future features ?
[... 42 words]Spacelog: space exploration stories from the original transcripts. The product of the most recent /dev/fort outing—a beautiful, web-native interface for browsing the NASA transcripts from the Apollo 13 and Mercury 6 missions (more to come). Every key moment has a URL.
Porting Flickr to YUI 3: Lessons in Performance (at YUIConf 2010). Some very interesting tips here. The new Flickr photo pages suffered from what I’ve been calling “Flash of Un-Behavioured Content”, where slow loading JavaScript results in poor behaviour from some UI controls. They started using “Action Queueing”, where a small JS stub ensures a loading indicator is shown for clicks on features that have not yet fully loaded. Also, it turns out some corporate firewalls (Sonicwall in particular) dislike URLs over 1600 characters, and filter out any URL with xxx in it.