21 posts tagged “vector-search”
2025
Scaling HNSWs (via) Salvatore Sanfilippo spent much of this year working on vector sets for Redis, which first shipped in Redis 8 in May.
A big part of that work involved implementing HNSW - Hierarchical Navigable Small World - an indexing technique first introduced in this 2016 paper by Yu. A. Malkov and D. A. Yashunin.
Salvatore's detailed notes on the Redis implementation here offer an immersive trip through a fascinating modern field of computer science. He describes several new contributions he's made to the HNSW algorithm, mainly around efficient deletion and updating of existing indexes.
Since embedding vectors are notoriously memory-hungry I particularly appreciated this note about how you can scale a large HNSW vector set across many different nodes and run parallel queries against them for both reads and writes:
[...] if you have different vectors about the same use case split in different instances / keys, you can ask VSIM for the same query vector into all the instances, and add the WITHSCORES option (that returns the cosine distance) and merge the results client-side, and you have magically scaled your hundred of millions of vectors into multiple instances, splitting your dataset N times [One interesting thing about such a use case is that you can query the N instances in parallel using multiplexing, if your client library is smart enough].
Another very notable thing about HNSWs exposed in this raw way, is that you can finally scale writes very easily. Just hash your element modulo N, and target the resulting Redis key/instance. Multiple instances can absorb the (slow, but still fast for HNSW standards) writes at the same time, parallelizing an otherwise very slow process.
It's always exciting to see new implementations of fundamental algorithms and data structures like this make it into Redis because Salvatore's C code is so clearly commented and pleasant to read - here's vector-sets/hnsw.c and vector-sets/vset.c.
The case against pgvector (via) I wasn't keen on the title of this piece but the content is great: Alex Jacobs talks through lessons learned trying to run the popular pgvector PostgreSQL vector indexing extension at scale, in particular the challenges involved in maintaining a large index with close-to-realtime updates using the IVFFlat or HNSW index types.
The section on pre-v.s.-post filtering is particularly useful:
Okay but let's say you solve your index and insert problems. Now you have a document search system with millions of vectors. Documents have metadata---maybe they're marked as
draft,published, orarchived. A user searches for something, and you only want to return published documents.[...] should Postgres filter on status first (pre-filter) or do the vector search first and then filter (post-filter)?
This seems like an implementation detail. It’s not. It’s the difference between queries that take 50ms and queries that take 5 seconds. It’s also the difference between returning the most relevant results and… not.
The Hacker News thread for this article attracted a robust discussion, including some fascinating comments by Discourse developer Rafael dos Santos Silva (xfalcox) about how they are using pgvector at scale:
We [run pgvector in production] at Discourse, in thousands of databases, and it's leveraged in most of the billions of page views we serve. [...]
Also worth mentioning that we use quantization extensively:
- halfvec (16bit float) for storage - bit (binary vectors) for indexes
Which makes the storage cost and on-going performance good enough that we could enable this in all our hosting. [...]
In Discourse embeddings power:
- Related Topics, a list of topics to read next, which uses embeddings of the current topic as the key to search for similar ones
- Suggesting tags and categories when composing a new topic
- Augmented search
- RAG for uploaded files
I recently spoke with the CTO of a popular AI note-taking app who told me something surprising: they spend twice as much on vector search as they do on OpenAI API calls. Think about that for a second. Running the retrieval layer costs them more than paying for the LLM itself.
— James Luan, Engineering architect of Milvus
Cursor: Security (via) Cursor's security documentation page includes a surprising amount of detail about how the Cursor text editor's backend systems work.
I've recently learned that checking an organization's list of documented subprocessors is a great way to get a feel for how everything works under the hood - it's a loose "view source" for their infrastructure! That was how I confirmed that Anthropic's search features used Brave search back in March.
Cursor's list includes AWS, Azure and GCP (AWS for primary infrastructure, Azure and GCP for "some secondary infrastructure"). They host their own custom models on Fireworks and make API calls out to OpenAI, Anthropic, Gemini and xAI depending on user preferences. They're using turbopuffer as a hosted vector store.
The most interesting section is about codebase indexing:
Cursor allows you to semantically index your codebase, which allows it to answer questions with the context of all of your code as well as write better code by referencing existing implementations. […]
At our server, we chunk and embed the files, and store the embeddings in Turbopuffer. To allow filtering vector search results by file path, we store with every vector an obfuscated relative file path, as well as the line range the chunk corresponds to. We also store the embedding in a cache in AWS, indexed by the hash of the chunk, to ensure that indexing the same codebase a second time is much faster (which is particularly useful for teams).
At inference time, we compute an embedding, let Turbopuffer do the nearest neighbor search, send back the obfuscated file path and line range to the client, and read those file chunks on the client locally. We then send those chunks back up to the server to answer the user’s question.
When operating in privacy mode - which they say is enabled by 50% of their users - they are careful not to store any raw code on their servers for longer than the duration of a single request. This is why they store the embeddings and obfuscated file paths but not the code itself.
Reading this made me instantly think of the paper Text Embeddings Reveal (Almost) As Much As Text about how vector embeddings can be reversed. The security documentation touches on that in the notes:
Embedding reversal: academic work has shown that reversing embeddings is possible in some cases. Current attacks rely on having access to the model and embedding short strings into big vectors, which makes us believe that the attack would be somewhat difficult to do here. That said, it is definitely possible for an adversary who breaks into our vector database to learn things about the indexed codebases.
Redis is open source again (via) Salvatore Sanfilippo:
Five months ago, I rejoined Redis and quickly started to talk with my colleagues about a possible switch to the AGPL license, only to discover that there was already an ongoing discussion, a very old one, too. [...]
I’ll be honest: I truly wanted the code I wrote for the new Vector Sets data type to be released under an open source license. [...]
So, honestly, while I can’t take credit for the license switch, I hope I contributed a little bit to it, because today I’m happy. I’m happy that Redis is open source software again, under the terms of the AGPLv3 license.
I'm absolutely thrilled to hear this. Redis 8.0 is out today under the new license, including a beta release of Vector Sets. I've been watching Salvatore's work on those with fascination, while sad that I probably wouldn't use it often due to the janky license. That concern is now gone. I'm looking forward to putting them through their paces!
See also Redis is now available under the AGPLv3 open source license on the Redis blog. An interesting note from that is that they are also:
Integrating Redis Stack technologies, including JSON, Time Series, probabilistic data types, Redis Query Engine and more into core Redis 8 under AGPL
That's a whole bunch of new things that weren't previously part of Redis core.
I hadn't encountered Redis Query Engine before - it looks like that's a whole set of features that turn Redis into more of an Elasticsearch-style document database complete with full-text, vector search operations and geospatial operations and aggregations. It supports search syntax that looks a bit like this:
FT.SEARCH places "museum @city:(san francisco|oakland) @shape:[CONTAINS $poly]" PARAMS 2 poly 'POLYGON((-122.5 37.7, -122.5 37.8, -122.4 37.8, -122.4 37.7, -122.5 37.7))' DIALECT 3
(Noteworthy that Elasticsearch chose the AGPL too when they switched back from the SSPL to an open source license last year).
2024
Looking back, it's clear we overcomplicated things. While embeddings fundamentally changed how we can represent and compare content, they didn't need an entirely new infrastructure category. What we label as "vector databases" are, in reality, search engines with vector capabilities. The market is already correcting this categorization—vector search providers rapidly add traditional search features while established search engines incorporate vector search capabilities. This category convergence isn't surprising: building a good retrieval engine has always been about combining multiple retrieval and ranking strategies. Vector search is just another powerful tool in that toolbox, not a category of its own.
From where I left. Four and a half years after he left the project, Redis creator Salvatore Sanfilippo is returning to work on Redis.
Hacking randomly was cool but, in the long run, my feeling was that I was lacking a real purpose, and every day I started to feel a bigger urgency to be part of the tech world again. At the same time, I saw the Redis community fragmenting, something that was a bit concerning to me, even as an outsider.
I'm personally still upset at the license change, but Salvatore sees it as necessary to support the commercial business model for Redis Labs. It feels to me like a betrayal of the volunteer efforts by previous contributors. I posted about that on Hacker News and Salvatore replied:
I can understand that, but the thing about the BSD license is that such value never gets lost. People are able to fork, and after a fork for the original project to still lead will be require to put something more on the table.
Salvatore's first new project is an exploration of adding vector sets to Redis. The vector similarity API he previews in this post reminds me of why I fell in love with Redis in the first place - it's clean, simple and feels obviously right to me.
VSIM top_1000_movies_imdb ELE "The Matrix" WITHSCORES
1) "The Matrix"
2) "0.9999999403953552"
3) "Ex Machina"
4) "0.8680362105369568"
...
Hybrid full-text search and vector search with SQLite. As part of Alex’s work on his sqlite-vec SQLite extension - adding fast vector lookups to SQLite - he’s been investigating hybrid search, where search results from both vector similarity and traditional full-text search are combined together.
The most promising approach looks to be Reciprocal Rank Fusion, which combines the top ranked items from both approaches. Here’s Alex’s SQL query:
-- the sqlite-vec KNN vector search results
with vec_matches as (
select
article_id,
row_number() over (order by distance) as rank_number,
distance
from vec_articles
where
headline_embedding match lembed(:query)
and k = :k
),
-- the FTS5 search results
fts_matches as (
select
rowid,
row_number() over (order by rank) as rank_number,
rank as score
from fts_articles
where headline match :query
limit :k
),
-- combine FTS5 + vector search results with RRF
final as (
select
articles.id,
articles.headline,
vec_matches.rank_number as vec_rank,
fts_matches.rank_number as fts_rank,
-- RRF algorithm
(
coalesce(1.0 / (:rrf_k + fts_matches.rank_number), 0.0) * :weight_fts +
coalesce(1.0 / (:rrf_k + vec_matches.rank_number), 0.0) * :weight_vec
) as combined_rank,
vec_matches.distance as vec_distance,
fts_matches.score as fts_score
from fts_matches
full outer join vec_matches on vec_matches.article_id = fts_matches.rowid
join articles on articles.rowid = coalesce(fts_matches.rowid, vec_matches.article_id)
order by combined_rank desc
)
select * from final;I’ve been puzzled in the past over how to best do that because the distance scores from vector similarity and the relevance scores from FTS are meaningless in comparison to each other. RRF doesn’t even attempt to compare them - it uses them purely for row_number() ranking within each set and combines the results based on that.
Introducing Contextual Retrieval (via) Here's an interesting new embedding/RAG technique, described by Anthropic but it should work for any embedding model against any other LLM.
One of the big challenges in implementing semantic search against vector embeddings - often used as part of a RAG system - is creating "chunks" of documents that are most likely to semantically match queries from users.
Anthropic provide this solid example where semantic chunks might let you down:
Imagine you had a collection of financial information (say, U.S. SEC filings) embedded in your knowledge base, and you received the following question: "What was the revenue growth for ACME Corp in Q2 2023?"
A relevant chunk might contain the text: "The company's revenue grew by 3% over the previous quarter." However, this chunk on its own doesn't specify which company it's referring to or the relevant time period, making it difficult to retrieve the right information or use the information effectively.
Their proposed solution is to take each chunk at indexing time and expand it using an LLM - so the above sentence would become this instead:
This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter.
This chunk was created by Claude 3 Haiku (their least expensive model) using the following prompt template:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
Here's the really clever bit: running the above prompt for every chunk in a document could get really expensive thanks to the inclusion of the entire document in each prompt. Claude added context caching last month, which allows you to pay around 1/10th of the cost for tokens cached up to your specified beakpoint.
By Anthropic's calculations:
Assuming 800 token chunks, 8k token documents, 50 token context instructions, and 100 tokens of context per chunk, the one-time cost to generate contextualized chunks is $1.02 per million document tokens.
Anthropic provide a detailed notebook demonstrating an implementation of this pattern. Their eventual solution combines cosine similarity and BM25 indexing, uses embeddings from Voyage AI and adds a reranking step powered by Cohere.
The notebook also includes an evaluation set using JSONL - here's that evaluation data in Datasette Lite.
OpenAI: Improve file search result relevance with chunk ranking (via) I've mostly been ignoring OpenAI's Assistants API. It provides an alternative to their standard messages API where you construct "assistants", chatbots with optional access to additional tools and that store full conversation threads on the server so you don't need to pass the previous conversation with every call to their API.
I'm pretty comfortable with their existing API and I found the assistants API to be quite a bit more complicated. So far the only thing I've used it for is a script to scrape OpenAI Code Interpreter to keep track of updates to their enviroment's Python packages.
Code Interpreter aside, the other interesting assistants feature is File Search. You can upload files in a wide variety of formats and OpenAI will chunk them, store the chunks in a vector store and make them available to help answer questions posed to your assistant - it's their version of hosted RAG.
Prior to today OpenAI had kept the details of how this worked undocumented. I found this infuriating, because when I'm building a RAG system the details of how files are chunked and scored for relevance is the whole game - without understanding that I can't make effective decisions about what kind of documents to use and how to build on top of the tool.
This has finally changed! You can now run a "step" (a round of conversation in the chat) and then retrieve details of exactly which chunks of the file were used in the response and how they were scored using the following incantation:
run_step = client.beta.threads.runs.steps.retrieve( thread_id="thread_abc123", run_id="run_abc123", step_id="step_abc123", include=[ "step_details.tool_calls[*].file_search.results[*].content" ] )
(See what I mean about the API being a little obtuse?)
I tried this out today and the results were very promising. Here's a chat transcript with an assistant I created against an old PDF copy of the Datasette documentation - I used the above new API to dump out the full list of snippets used to answer the question "tell me about ways to use spatialite".
It pulled in a lot of content! 57,017 characters by my count, spread across 20 search results (customizable), for a total of 15,021 tokens as measured by ttok. At current GPT-4o-mini prices that would cost 0.225 cents (less than a quarter of a cent), but with regular GPT-4o it would cost 7.5 cents.
OpenAI provide up to 1GB of vector storage for free, then charge $0.10/GB/day for vector storage beyond that. My 173 page PDF seems to have taken up 728KB after being chunked and stored, so that GB should stretch a pretty long way.
Confession: I couldn't be bothered to work through the OpenAI code examples myself, so I hit Ctrl+A on that web page and copied the whole lot into Claude 3.5 Sonnet, then prompted it:
Based on this documentation, write me a Python CLI app (using the Click CLi library) with the following features:
openai-file-chat add-files name-of-vector-store *.pdf *.txt
This creates a new vector store called name-of-vector-store and adds all the files passed to the command to that store.
openai-file-chat name-of-vector-store1 name-of-vector-store2 ...
This starts an interactive chat with the user, where any time they hit enter the question is answered by a chat assistant using the specified vector stores.
We iterated on this a few times to build me a one-off CLI app for trying out the new features. It's got a few bugs that I haven't fixed yet, but it was a very productive way of prototyping against the new API.
Using DuckDB for Embeddings and Vector Search (via) Sören Brunk's comprehensive tutorial combining DuckDB 1.0, a subset of German Wikipedia from Hugging Face (loaded using Parquet), the BGE M3 embedding model and DuckDB's new vss extension for implementing an HNSW vector index.
I’m writing a new vector search SQLite Extension.
Alex Garcia is working on sqlite-vec, a spiritual successor to his sqlite-vss project. The new SQLite C extension will have zero other dependencies (sqlite-vss used some tricky C++ libraries) and will work using virtual tables, storing chunks of vectors in shadow tables to avoid needing to load everything into memory at once.
My binary vector search is better than your FP32 vectors. I’m still trying to get my head around this, but here’s what I understand so far.
Embedding vectors as calculated by models such as OpenAI text-embedding-3-small are arrays of floating point values, which look something like this:
[0.0051681744, 0.017187592, -0.018685209, -0.01855924, -0.04725188...]—1356 elements long
Different embedding models have different lengths, but they tend to be hundreds up to low thousands of numbers. If each float is 32 bits that’s 4 bytes per float, which can add up to a lot of memory if you have millions of embedding vectors to compare.
If you look at those numbers you’ll note that they are all pretty small positive or negative numbers, close to 0.
Binary vector search is a trick where you take that sequence of floating point numbers and turn it into a binary vector—just a list of 1s and 0s, where you store a 1 if the corresponding float was greater than 0 and a 0 otherwise.
For the above example, this would start [1, 1, 0, 0, 0...]
Incredibly, it looks like the cosine distance between these 0 and 1 vectors captures much of the semantic relevant meaning present in the distance between the much more accurate vectors. This means you can use 1/32nd of the space and still get useful results!
Ce Gao here suggests a further optimization: use the binary vectors for a fast brute-force lookup of the top 200 matches, then run a more expensive re-ranking against those filtered values using the full floating point vectors.
2023
Embeddings: What they are and why they matter
Embeddings are a really neat trick that often come wrapped in a pile of intimidating jargon.
[... 5,835 words]LLM now provides tools for working with embeddings

LLM is my Python library and command-line tool for working with language models. I just released LLM 0.9 with a new set of features that extend LLM to provide tools for working with embeddings.
[... 3,521 words]sqlite-vss v0.1.1 Annotated Release Notes (via) Alex Garcia’s sqlite-vss adds vector search directly to SQLite through a custom extension. It’s now easily installed for Python, Node.js, Deno, Elixir, Go, Rust and Ruby (“gem install sqlite-vss”), and is being used actively by enough people that Alex is getting actionable feedback, including fixes for memory leaks spotted in production.
Vector Search. Amjith Ramanujam provides a very thorough tutorial on implementing vector similarity search using SentenceTransformers embeddings (all-MiniLM-L6-v2) executed using sqlite-utils, then served via datasette-sqlite-vss and deployed using Fly.
Introducing sqlite-vss: A SQLite Extension for Vector Search (via) This latest SQLite extension from Alex Garcia is possibly his best yet: it adds FAISS-powered vector similarity search directly to SQLite, enabling fast KNN similarity lookups against a virtual table that feels a lot like SQLite’s own built-in full text search feature. This write-up includes interactive demos using Datasette called from an Observable notebook, running similarity searches against an index of 200,000 news headlines and summaries in less than 50ms.
Weeknotes: AI hacking and a SpatiaLite tutorial
Short weeknotes this time because the key things I worked on have already been covered here:
How to implement Q&A against your documentation with GPT3, embeddings and Datasette
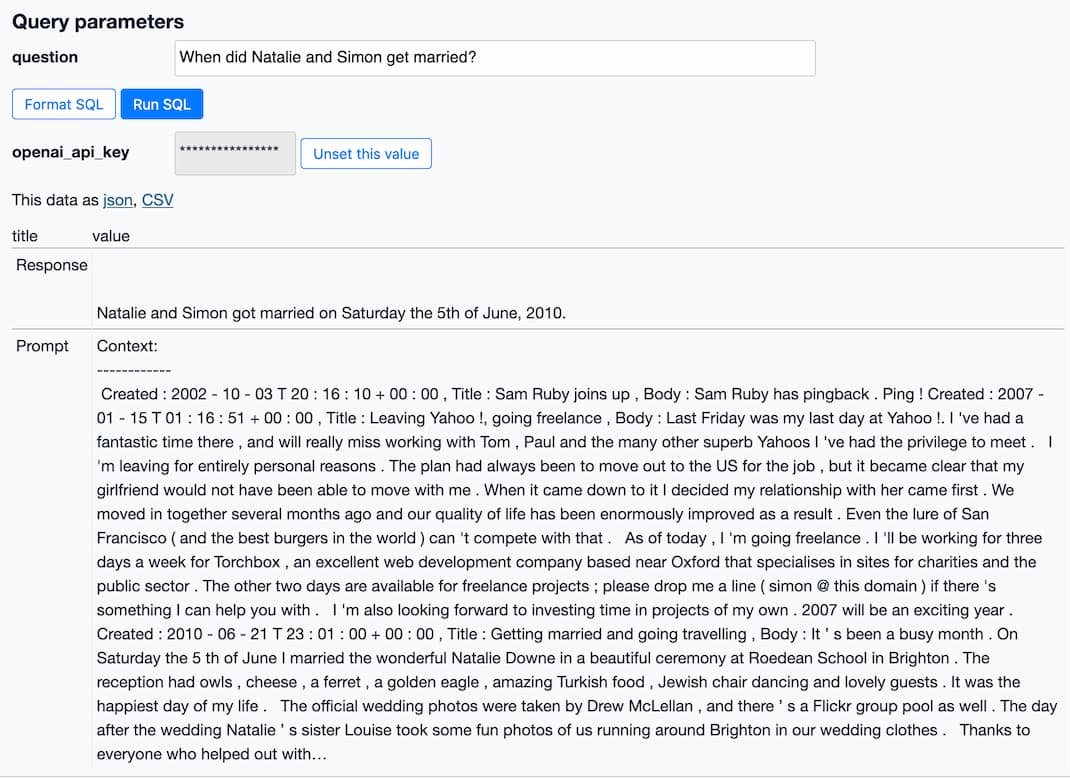
If you’ve spent any time with GPT-3 or ChatGPT, you’ve likely thought about how useful it would be if you could point them at a specific, current collection of text or documentation and have it use that as part of its input for answering questions.
[... 3,447 words]2003
Vector search engines
Building a Vector Space Search Engine in Perl by Maciej Cegłowski:
[... 307 words]