August 2023
102 posts: 7 entries, 28 links, 10 quotes, 57 beats
Aug. 1, 2023
Run Llama 2 on your own Mac using LLM and Homebrew
Llama 2 is the latest commercially usable openly licensed Large Language Model, released by Meta AI a few weeks ago. I just released a new plugin for my LLM utility that adds support for Llama 2 and many other llama-cpp compatible models.
[... 1,423 words]Aug. 3, 2023
Catching up on the weird world of LLMs

I gave a talk on Sunday at North Bay Python where I attempted to summarize the last few years of development in the space of LLMs—Large Language Models, the technology behind tools like ChatGPT, Google Bard and Llama 2.
[... 10,489 words]Aug. 4, 2023

You can stop using user-scalable=no and maximum-scale=1 in viewport meta tags now. Luke Plant points out that your meta viewport tag should stick to just “width=device-width, initial-scale=1” these days—the user-scalable=no and maximum-scale=1 attributes are no longer necessary, and have a negative impact on accessibility, especially for Android users.
Aug. 5, 2023
Weeknotes: Plugins for LLM, sqlite-utils and Datasette
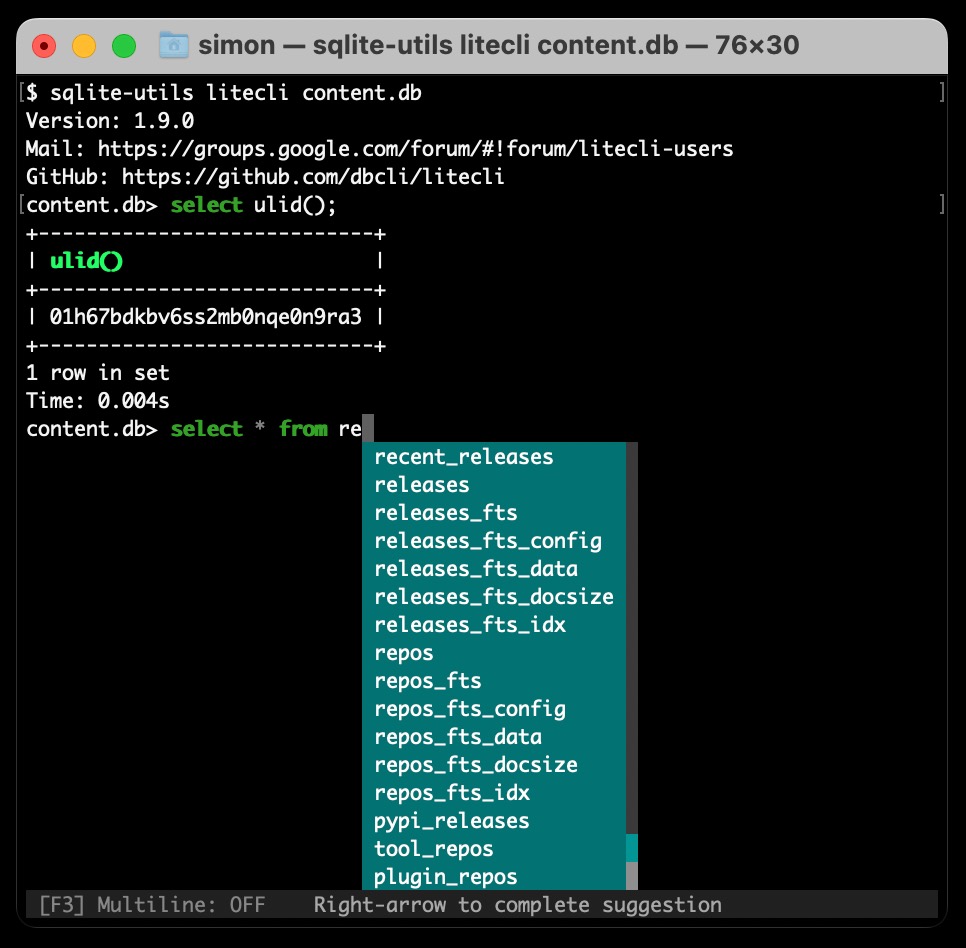
The principle theme for the past few weeks has been plugins.
[... 1,203 words]Aug. 6, 2023
How I make annotated presentations
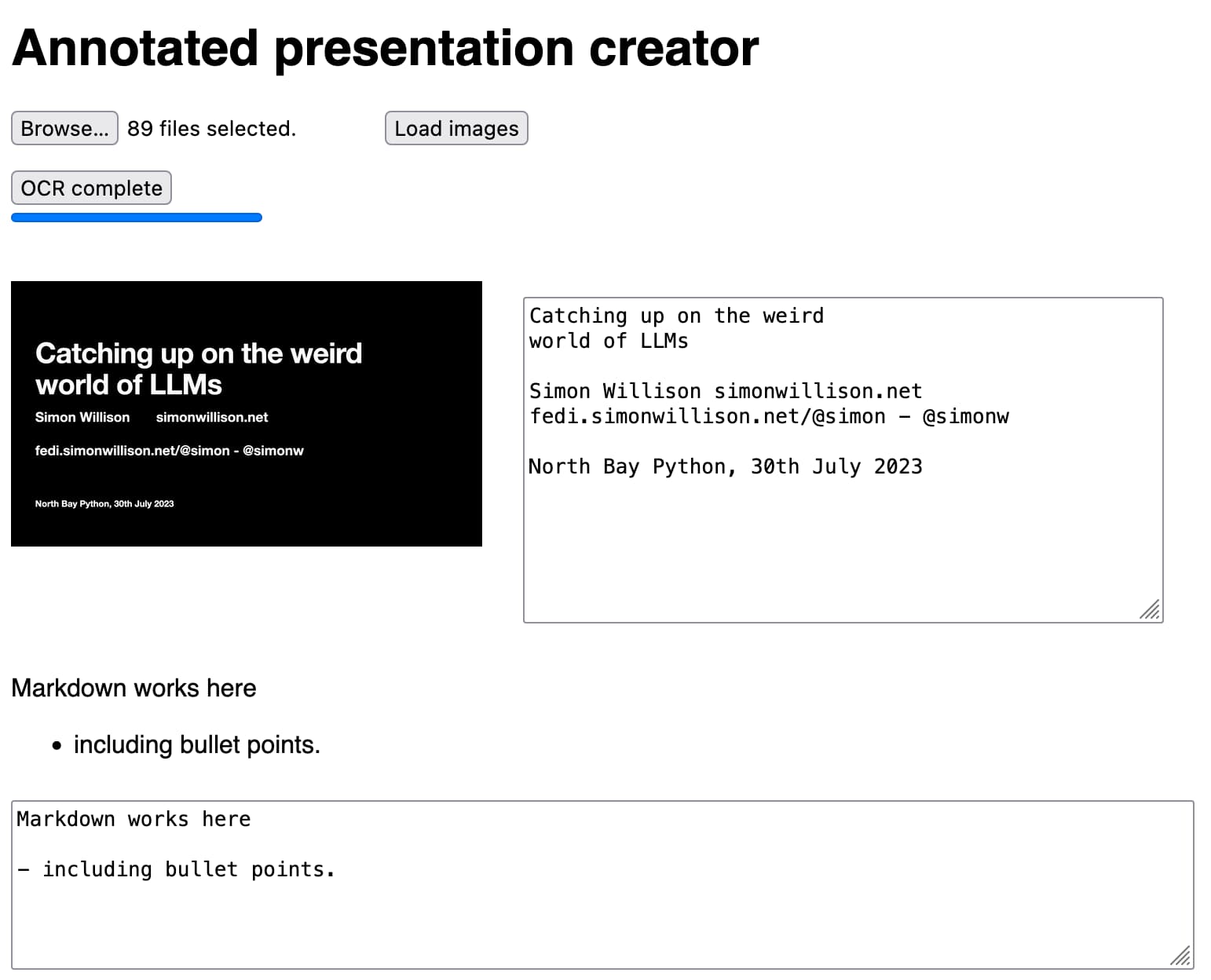
Giving a talk is a lot of work. I go by a rule of thumb I learned from Damian Conway: a minimum of ten hours of preparation for every one hour spent on stage.
[... 2,128 words]Python cocktail: mix a context manager and an iterator in equal parts (via) Explanation of a neat trick used by the Tenacity Python library, which provides a mechanism for retrying a chunk of code automatically on errors up to three times using a mixture of an iterator and a context manager to work around Python’s lack of multi-line lambda functions.
Aug. 8, 2023
Aug. 9, 2023
Llama from scratch (or how to implement a paper without crying) (via) Brian Kitano implemented the model described in the Llama paper against TinyShakespeare, from scratch, using Python and PyTorch. This write-up is fantastic—meticulous, detailed and deeply informative. It would take several hours to fully absorb and follow everything Brian does here but it would provide multiple valuable lessons in understanding how all of this stuff fits together.
Datasette 1.0a3. A new Datasette alpha release. This one previews the new default JSON API design that’s coming in 1.0—the single most significant change in the 1.0 milestone, since I plan to keep that API stable for many years to come.
Aug. 10, 2023
Getting creative with embeddings (via) Amelia Wattenberger describes a neat application of embeddings I haven’t seen before: she wanted to build a system that could classify individual sentences in terms of how “concrete” or “abstract” they are. So she generated several example sentences for each of those categories, embedded then and calculated the average of those embeddings.
And now she can get a score for how abstract vs concrete a new sentence is by calculating its embedding and seeing where it falls in the 1500 dimension space between those two other points.


Aug. 11, 2023
Shamir Secret Sharing (via) Cracking war story from Max Levchin about the early years of PayPal, in which he introduces an implementation of Shamir Secret Sharing to encrypt their master payment credential table... and then finds that the 3-of-8 passwords needed to decrypt it and bring the site back online don’t appear to work.
Dependency Management Data (via) This is a really neat CLI tool by Jamie Tanna, built using Go and SQLite but with a feature that embeds a Datasette instance (literally shelling out to start the process running from within the Go application) to provide an interface for browsing the resulting database.
It addresses the challenge of keeping track of the dependencies used across an organization, by gathering them into a SQLite database from a variety of different sources—currently Dependabot, Renovate and some custom AWS tooling.
The “Example” page links to a live Datasette instance and includes video demos of the tool in action.
Aug. 12, 2023
llm-mlc (via) My latest plugin for LLM adds support for models that use the MLC Python library—which is the first library I’ve managed to get to run Llama 2 with GPU acceleration on my M2 Mac laptop.

deno_python (via) A wildly impressive hack: deno_python uses Deno’s FFI interface to load your system’s Python framework (.dll/.dylib/.so) and sets up JavaScript proxy objects for imported Python objects—so you can run JavaScript code that instantiates objects from Python libraries and uses them to process data in different ways.
The latest release added pip support, so things like ’const np = await pip.import(“numpy”)’ now work.
Aug. 13, 2023
Lark parsing library JSON tutorial (via) A very convincing tutorial for a new-to-me parsing library for Python called Lark.
The tutorial covers building a full JSON parser from scratch, which ends up being just 19 lines of grammar definition code and 15 lines for the transformer to turn that tree into the final JSON.
It then gets into the details of optimization—the default Earley algorithm is quite slow, but swapping that out for a LALR parser (a one-line change) provides a 5x speedup for this particular example.