March 2023
100 posts: 10 entries, 47 links, 20 quotes, 23 beats
March 14, 2023

We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less capable than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks. [...] We’ve spent 6 months iteratively aligning GPT-4 using lessons from our adversarial testing program as well as ChatGPT, resulting in our best-ever results (though far from perfect) on factuality, steerability, and refusing to go outside of guardrails.
— OpenAI
Introducing Claude. Anthropic released the first two versions of Claude, "a next-generation AI assistant based on Anthropic’s research into training helpful, honest, and harmless AI systems". Claude and Claude Instant are both available via a web chat interface and through their API.
(I back-filled this link on Feb 25th 2026 to help fill out my llm-release tag.)
GPT-4 Technical Report (PDF). 98 pages of much more detailed information about GPT-4. The appendices are particularly interesting, including examples of advanced prompt engineering as well as examples of harmful outputs before and after tuning attempts to try and suppress them.
March 15, 2023
GPT-4 Developer Livestream. 25 minutes of live demos from OpenAI co-founder Greg Brockman at the GPT-4 launch. These demos are all fascinating, including code writing and multimodal vision inputs. The one that really struck me is when Greg pasted in a copy of the tax code and asked GPT-4 to answer some sophisticated tax questions, involving step-by-step calculations that cited parts of the tax code it was working with.
We call on the field to recognize that applications that aim to believably mimic humans bring risk of extreme harms. Work on synthetic human behavior is a bright line in ethical Al development, where downstream effects need to be understood and modeled in order to block foreseeable harm to society and different social groups.
— Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell
"AI" has for recent memory been a marketing term anyway. Deep learning and variations have had a good run at being what people mean when they refer to AI, probably overweighting towards big convolution based computer vision models.
Now, "AI" in people's minds means generative models.
That's it, it doesn't mean generative models are replacing CNNs, just like CNNs don't replace SVMs or regression or whatever. It's just that pop culture has fallen in love with something else.
March 16, 2023
bloomz.cpp (via) Nouamane Tazi Adapted the llama.cpp project to run against the BLOOM family of language models, which were released in July 2022 and trained in France on 45 natural languages and 12 programming languages using the Jean Zay Public Supercomputer, provided by the French government and powered using mostly nuclear energy.
It’s under the RAIL license which allows (limited) commercial use, unlike LLaMA.
Nouamane reports getting 16 tokens/second from BLOOMZ-7B1 running on an M1 Pro laptop.
I expect GPT-4 will have a LOT of applications in web scraping
The increased 32,000 token limit will be large enough to send it the full DOM of most pages, serialized to HTML - then ask questions to extract data
Or... take a screenshot and use the GPT4 image input mode to ask questions about the visually rendered page instead!
Might need to dust off all of those old semantic web dreams, because the world's information is rapidly becoming fully machine readable
— Me
As an NLP researcher I'm kind of worried about this field after 10-20 years. Feels like these oversized LLMs are going to eat up this field and I'm sitting in my chair thinking, "What's the point of my research when GPT-4 can do it better?"
Not By AI: Your AI-free Content Deserves a Badge (via) A badge for non-AI generated content. Interesting to note that they set the cutoff at 90%: “Use this badge if your article, including blog posts, essays, research, letters, and other text-based content, contains less than 10% of AI output.”
Train and run Stanford Alpaca on your own machine. The team at Replicate managed to train their own copy of Stanford’s Alpaca—a fine-tuned version of LLaMA that can follow instructions like ChatGPT. Here they provide step-by-step instructions for recreating Alpaca yourself—running the training needs one or more A100s for a few hours, which you can rent through various cloud providers.
Transformers.js. Hugging Face Transformers is a library of Transformer machine learning models plus a Python package for loading and running them. Transformers.js provides a JavaScript alternative interface which runs in your browser, thanks to a set of precompiled WebAssembly binaries for a selection of models. This interactive demo is incredible: in particular, try running the Image classification with google/vit-base-patch16-224 (91MB) model against any photo to get back labels representing that photo. Dropping one of these models onto a page is as easy as linking to a hosted CDN script and running a few lines of JavaScript.
March 17, 2023
The surprising ease and effectiveness of AI in a loop (via) Matt Webb on the langchain Python library and the ReAct design pattern, where you plug additional tools into a language model by teaching it to work in a “Thought... Act... Observation” loop where the Act specifies an action it wishes to take (like searching Wikipedia) and an extra layer of software than carries out that action and feeds back the result as the Observation. Matt points out that the ChatGPT 1/10th price drop makes this kind of model usage enormously more cost effective than it was before.
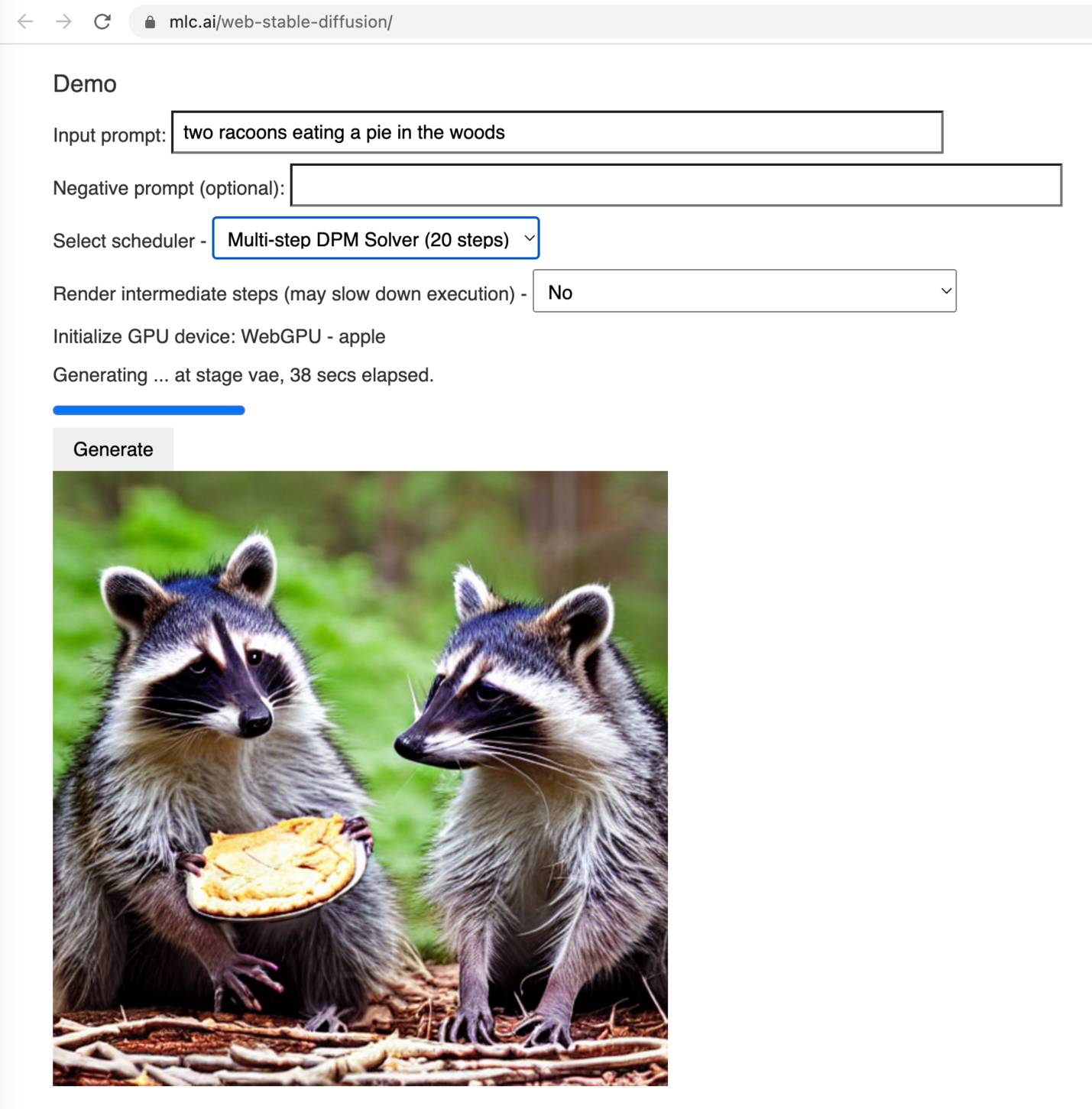
Web Stable Diffusion (via) I just ran the full Stable Diffusion image generation model entirely in my browser, and used it to generate an image of two raccoons eating pie in the woods. I had to use Google Chrome Canary since this depends on WebGPU which still isn't fully rolled out, but it worked perfectly.
A simple Python implementation of the ReAct pattern for LLMs. I implemented the ReAct pattern (for Reason+Act) described in this paper. It's a pattern where you implement additional actions that an LLM can take - searching Wikipedia or running calculations for example - and then teach it how to request that those actions are run, then feed their results back into the LLM.

Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
I think it’s now possible to train a large language model with similar functionality to GPT-3 for $85,000. And I think we might soon be able to run the resulting model entirely in the browser, and give it capabilities that leapfrog it ahead of ChatGPT.
[... 1,751 words]The Unpredictable Abilities Emerging From Large AI Models (via) Nice write-up of the most interesting aspect of large language models: the fact that they gain emergent abilities at certain “breakthrough” size points, and no-one is entirely sure they understand why.
Fine-tune LLaMA to speak like Homer Simpson. Replicate spent 90 minutes fine-tuning LLaMA on 60,000 lines of dialog from the first 12 seasons of the Simpsons, and now it can do a good job of producing invented dialog from any of the characters from the series. This is a really interesting result: I’ve been skeptical about how much value can be had from fine-tuning large models on just a tiny amount of new data, assuming that the new data would be statistically irrelevant compared to the existing model. Clearly my mental model around this was incorrect.
March 18, 2023
A conversation about prompt engineering with CBC Day 6
I’m on Canadian radio this morning! I was interviewed by Peter Armstrong for CBC Day 6 about the developing field of prompt engineering.
[... 1,742 words]March 21, 2023
Was on a plane yesterday, studying some physics; got confused about something and I was able to solve my problem by just asking alpaca-13B—running locally on my machine—for an explanation. Felt straight-up spooky.
OpenAI to discontinue support for the Codex API (via) OpenAI shutting off access to their Codex model—a GPT3 variant fine-tuned for code related tasks, but that was being used for all sorts of other purposes—partly because it had been in a beta phase for over a year where OpenAI didn’t charge anything for it. This feels to me like a major strategic misstep for OpenAI: they’re only giving three days notice, which is shaking people’s confidence in them as a stable platform for building on at the very moment when competition from other vendors (and open source alternatives) is heating up.
Adobe made an AI image generator — and says it didn’t steal artists’ work to do it. Adobe Firefly is a brand new text-to-image model which Adobe claim was trained entirely on fully licensed imagery—either out of copyright, specially licensed or part of the existing Adobe Stock library. I’m sure they have the license, but I still wouldn’t be surprised to hear complaints from artists who licensed their content to Adobe Stock who didn’t anticipate it being used for model training.
Bing Image Creator comes to the new Bing. Bing Chat is integrating DALL-E directly into their interface, giving it the ability to generate images when prompted to do so.
Prompt Engineering. Extremely detailed introduction to the field of prompt engineering by Lilian Weng, who leads applied research at OpenAI.
Google Bard is now live. Google Bard launched today. There’s a waiting list, but I made it through within a few hours of signing up, as did other people I’ve talked to. It’s similar to ChatGPT and Bing—it’s the same chat interface, and it can clearly run searches under the hood (though unlike Bing it doesn’t tell you what it’s looking for).
Here are some absurdly expensive things you can do on a trip to Tokyo: Buy a golden toilet. There is a toilet in Tokyo that is made of gold and costs around 10 million yen. If you are looking for a truly absurd experience, you can buy this toilet and use it for your next bowel movement. [...]
The Age of AI has begun. Bill Gates calls GPT-class large language models “the most important advance in technology since the graphical user interface”. His essay here focuses on the philanthropy angle, mostly from the point of view of AI applications in healthcare, education and concerns about keeping access to these new technologies as equitable as possible.
