July 2024
141 posts: 4 entries, 81 links, 35 quotes, 1 note, 20 beats
July 8, 2024
I'm still optimistic about the future of software engineering as a career.
YouTube/TikTok didn't eliminate professional film crews, they just opened up the floodgates for vastly more different types of filmed content.
LLMs won't be replacing production-grade software engineering.
... they may well drive down the price of production-grade software, but I expect that will result in a massively increased demand for it.
There's been way more demand than supply for custom software almost since computers were invented.
Originally a short thread on Twitter
Someone elsewhere left a comment like "I CAN’T BELIEVE IT TOOK HER 15 YEARS TO LEARN BASIC READLINE COMMANDS". those comments are very silly and I'm going to keep writing “it took me 15 years to learn this basic thing" forever because I think it's important for people to know that it's normal to take a long time to learn “basic" things
Jevons paradox (via) I've been thinking recently about how the demand for professional software engineers might be affected by the fact that LLMs are getting so good at producing working code, when prompted in the right way.
One possibility is that the price for writing code will fall, in a way that massively increases the demand for custom solutions - resulting in a greater demand for software engineers since the increased value they can provide makes it much easier to justify the expense of hiring them in the first place.
TIL about the related idea of the Jevons paradox, currently explained by Wikipedia like so:
[...] when technological progress increases the efficiency with which a resource is used (reducing the amount necessary for any one use), but the falling cost of use induces increases in demand enough that resource use is increased, rather than reduced.
July 9, 2024
Inside the labs we have these capable models, and they're not that far ahead from what the public has access to for free. And that's a completely different trajectory for bringing technology into the world that what we've seen historically. It's a great opportunity because it brings people along. It gives them intuitive sense for the capabilities and risks and allows people to prepare for the advent of bringing advanced AI into the world.
Chrome's biggest innovation was the short release cycle with a silent unceremonious autoupdate.
When updates were big, rare, and manual, buggy and outdated browsers were lingering for soo long, that we were giving bugs names. We documented the bugs in magazines and books, as if they were a timeless foundation of WebDev.
Nowadays browser vendors can fix bugs in 6 weeks (even Safari can…). New-ish stuff is still buggy, but rarely for long enough for the bugs to make it to schools' curriculums.
Deactivating an API, one step at a time (via) Bruno Pedro describes a sensible approach for web API deprecation, using API keys to first block new users from using the old API, then track which existing users are depending on the old version and reaching out to them with a sunset period.
The only suggestion I'd add is to implement API brownouts - short periods of time where the deprecated API returns errors, several months before the final deprecation. This can help give users who don't read emails from you notice that they need to pay attention before their integration breaks entirely.
I've seen GitHub use this brownout technique successfully several times over the last few years - here's one example.
hangout_services/thunk.js
(via)
It turns out Google Chrome (via Chromium) includes a default extension which makes extra services available to code running on the *.google.com domains - tweeted about today by Luca Casonato, but the code has been there in the public repo since October 2013 as far as I can tell.
It looks like it's a way to let Google Hangouts (or presumably its modern predecessors) get additional information from the browser, including the current load on the user's CPU. Update: On Hacker News a Googler confirms that the Google Meet "troubleshooting" feature uses this to review CPU utilization.
I got GPT-4o to help me figure out how to trigger it (I tried Claude 3.5 Sonnet first but it refused, saying "Doing so could potentially violate terms of service or raise security and privacy concerns"). Paste the following into your Chrome DevTools console on any Google site to see the result:
chrome.runtime.sendMessage(
"nkeimhogjdpnpccoofpliimaahmaaome",
{ method: "cpu.getInfo" },
(response) => {
console.log(JSON.stringify(response, null, 2));
},
);
I get back a response that starts like this:
{
"value": {
"archName": "arm64",
"features": [],
"modelName": "Apple M2 Max",
"numOfProcessors": 12,
"processors": [
{
"usage": {
"idle": 26890137,
"kernel": 5271531,
"total": 42525857,
"user": 10364189
}
}, ...
The code doesn't do anything on non-Google domains.
Luca says this - I'm inclined to agree:
This is interesting because it is a clear violation of the idea that browser vendors should not give preference to their websites over anyone elses.
Claude: You can now publish, share, and remix artifacts. Artifacts is the feature Anthropic released a few weeks ago to accompany Claude 3.5 Sonnet, allowing Claude to create interactive HTML+JavaScript tools in response to prompts.
This morning they added the ability to make those artifacts public and share links to them, which makes them even more useful!
Here's my box shadow playground from the other day, and an example page I requested demonstrating the Milligram CSS framework - Artifacts can load most code that is available via cdnjs so they're great for quickly trying out new libraries.
July 10, 2024
Content slop has three important characteristics. The first being that, to the user, the viewer, the customer, it feels worthless. This might be because it was clearly generated in bulk by a machine or because of how much of that particular content is being created. The next important feature of slop is that feels forced upon us, whether by a corporation or an algorithm. It’s in the name. We’re the little piggies and it’s the gruel in the trough. But the last feature is the most crucial. It not only feels worthless and ubiquitous, it also feels optimized to be so. The Charli XCX “Brat summer” meme does not feel like slop, nor does Kendrick Lamar’s extremely long “Not Like Us” roll out. But Taylor Swift’s cascade of alternate versions of her songs does. The jury’s still out on Sabrina Carpenter. Similarly, last summer’s Barbenheimer phenomenon did not, to me, feel like slop. Dune: Part Two didn’t either. But Deadpool & Wolverine, at least in the marketing, definitely does.
Vision language models are blind (via) A new paper exploring vision LLMs, comparing GPT-4o, Gemini 1.5 Pro, Claude 3 Sonnet and Claude 3.5 Sonnet (I'm surprised they didn't include Claude 3 Opus and Haiku, which are more interesting than Claude 3 Sonnet in my opinion).
I don't like the title and framing of this paper. They describe seven tasks that vision models have trouble with - mainly geometric analysis like identifying intersecting shapes or counting things - and use those to support the following statement:
The shockingly poor performance of four state-of-the-art VLMs suggests their vision is, at best, like of a person with myopia seeing fine details as blurry, and at worst, like an intelligent person that is blind making educated guesses.
While the failures they describe are certainly interesting, I don't think they justify that conclusion.
I've felt starved for information about the strengths and weaknesses of these vision LLMs since the good ones started becoming available last November (GPT-4 Vision at OpenAI DevDay) so identifying tasks like this that they fail at is useful. But just like pointing out an LLM can't count letters doesn't mean that LLMs are useless, these limitations of vision models shouldn't be used to declare them "blind" as a sweeping statement.
Anthropic cookbook: multimodal. I'm currently on the lookout for high quality sources of information about vision LLMs, including prompting tricks for getting the most out of them.
This set of Jupyter notebooks from Anthropic (published four months ago to accompany the original Claude 3 models) is the best I've found so far. Best practices for using vision with Claude includes advice on multi-shot prompting with example, plus this interesting think step-by-step style prompt for improving Claude's ability to count the dogs in an image:
You have perfect vision and pay great attention to detail which makes you an expert at counting objects in images. How many dogs are in this picture? Before providing the answer in
<answer>tags, think step by step in<thinking>tags and analyze every part of the image.
Yeah, unfortunately vision prompting has been a tough nut to crack. We've found it's very challenging to improve Claude's actual "vision" through just text prompts, but we can of course improve its reasoning and thought process once it extracts info from an image.
In general, I think vision is still in its early days, although 3.5 Sonnet is noticeably better than older models.
— Alex Albert, Anthropic
Early Apple tech bloggers are shocked to find their name and work have been AI-zombified (via)
TUAW (“The Unofficial Apple Weblog”) was shut down by AOL in 2015, but this past year, a new owner scooped up the domain and began posting articles under the bylines of former writers who haven’t worked there for over a decade.
They're using AI-generated images against real names of original contributors, then publishing LLM-rewritten articles because they didn't buy the rights to the original content!
July 11, 2024
My main concern is that the substantial cost to develop and run Al technology means that Al applications must solve extremely complex and important problems for enterprises to earn an appropriate return on investment.
We estimate that the Al infrastructure buildout will cost over $1tn in the next several years alone, which includes spending on data centers, utilities, and applications. So, the crucial question is: What $1tn problem will Al solve? Replacing low-wage jobs with tremendously costly technology is basically the polar opposite of the prior technology transitions I've witnessed in my thirty years of closely following the tech industry.
— Jim Covello, Goldman Sachs
The economics of a Postgres free tier (via) Xata offer a hosted PostgreSQL service with a generous free tier (15GB of volume). I'm very suspicious of free tiers that don't include a detailed breakdown of the unit economics... and in this post they've described exactly that, in great detail.
The trick is that they run their free tier on shared clusters - with each $630/month cluster supporting 2,000 free instances for $0.315 per instance per month. Then inactive databases get downgraded to even cheaper auto-scaling clusters that can host 20,000 databases for $180/month (less than 1c each).
They also cover the volume cost of $0.10/GB/month - so up to $1.50/month per free instance, but most instances only use a small portion of that space.
It's reassuring to see this spelled out in so much detail.
[On Paddington 3] If this movie is anywhere near as good as the second one, we are going to need to have an extremely serious conversation about this being one of the greatest film trilogies ever made.
July 12, 2024
Why The Atlantic signed a deal with OpenAI. Interesting conversation between Nilay Patel and The Atlantic CEO (and former journalist/editor) Nicholas Thompson about the relationship between media organizations and LLM companies like OpenAI.
On the impact of these deals on the ongoing New York Times lawsuit:
One of the ways that we [The Atlantic] can help the industry is by making deals and setting a market. I believe that us doing a deal with OpenAI makes it easier for us to make deals with the other large language model companies if those come about, I think it makes it easier for other journalistic companies to make deals with OpenAI and others, and I think it makes it more likely that The Times wins their lawsuit.
How could it help? Because deals like this establish a market value for training content, important for the fair use component of the legal argument.
Fighting bots is fighting humans [...] remind you that "only allow humans to access" is just not an achievable goal. Any attempt at limiting bot access will inevitably allow some bots through and prevent some humans from accessing the site, and it's about deciding where you want to set the cutoff. I fear that media outlets and other websites, in attempting to "protect" their material from AI scrapers, will go too far in the anti-human direction.
The Death of the Junior Developer (via) Steve Yegge's speculative take on the impact LLM-assisted coding could have on software careers.
Steve works on Cody, an AI programming assistant, so he's hardly an unbiased source of information. Nevertheless, his collection of anecdotes here matches what I've been seeing myself.
Steve coins the term here CHOP, for Chat Oriented Programming, where the majority of code is typed by an LLM that is directed by a programmer. Steve describes it as "coding via iterative prompt refinement", and argues that the models only recently got good enough to support this style with GPT-4o, Gemini Pro and Claude 3 Opus.
I've been experimenting with this approach myself on a few small projects (see this Claude example) and it really is a surprisingly effective way to work.
Also included: a story about how GPT-4o produced a bewitchingly tempting proposal with long-term damaging effects that only a senior engineer with deep understanding of the problem space could catch!
I'm in strong agreement with this thought on the skills that are becoming most important:
Everyone will need to get a lot more serious about testing and reviewing code.
Searching an aerial photo with text queries. Robin Wilson built a demo that lets you search a large aerial photograph of Southampton for things like "roundabout" or "tennis court". He explains how it works in detail: he used the SkyCLIP model, which is trained on "5.2 million remote sensing image-text pairs in total, covering more than 29K distinct semantic tags" to generate embeddings for 200x200 image segments (with 100px of overlap), then stored them in Pinecone.
datasette-python.
I just released a small new plugin for Datasette to assist with debugging. It adds a python subcommand which runs a Python process in the same virtual environment as Datasette itself.
I built it initially to help debug some issues in Datasette installed via Homebrew. The Homebrew installation has its own virtual environment, and sometimes it can be useful to run commands like pip list in the same environment as Datasette itself.
Now you can do this:
brew install datasette
datasette install datasette-python
datasette python -m pip list
I built a similar plugin for LLM last year, called llm-python - it's proved useful enough that I duplicated the design for Datasette.
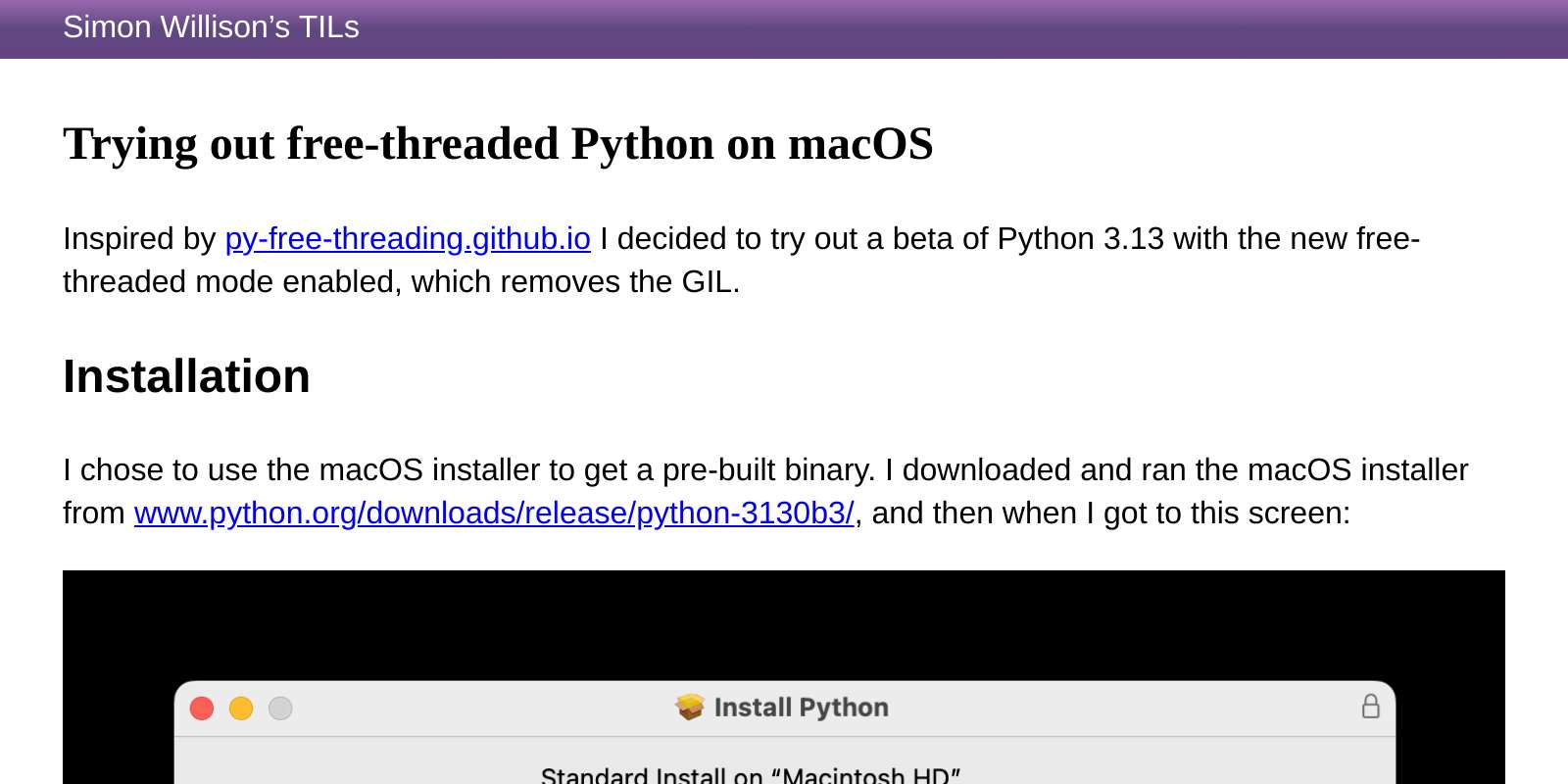
Free-threaded CPython is ready to experiment with! The Python 3.13 beta releases that include a "free-threaded" version that removes the GIL are now available to test! A team from Quansight Labs, home of the PyData core team, just launched py-free-threading.github.io to help document the new builds and track compatibility with Python's larger ecosystem.
Free-threading mode will not be enabled in Python installations by default. You can install special builds that have the option enabled today - I used the macOS installer and, after enabling the new build in the "Customize" panel in the installer, ended up with a /usr/local/bin/python3.13t binary which shows "Python 3.13.0b3 experimental free-threading build" when I run it.
Here's my TIL describing my experiments so far installing and running the 3.13 beta on macOS, which also includes a correction to an embarrassing bug that Claude introduced but I failed to catch!
July 13, 2024
Third, X fails to provide access to its public data to researchers in line with the conditions set out in the DSA. In particular, X prohibits eligible researchers from independently accessing its public data, such as by scraping, as stated in its terms of service. In addition, X's process to grant eligible researchers access to its application programming interface (API) appears to dissuade researchers from carrying out their research projects or leave them with no other choice than to pay disproportionally high fees.
Add tests in a commit before the fix. They should pass, showing the behavior before your change. Then, the commit with your change will update the tests. The diff between these commits represents the change in behavior. This helps the author test their tests (I've written tests thinking they covered the relevant case but didn't), the reviewer to more precisely see the change in behavior and comment on it, and the wider community to understand what the PR description is about.
— Ed Page
We respect wildlife in the wilderness because we’re in their house. We don’t fully understand the complexity of most ecosystems, so we seek to minimize our impact on those ecosystems since we can’t always predict what outcomes our interactions with nature might have.
In software, many disastrous mistakes stem from not understanding why a system was built the way it was, but changing it anyway. It’s super common for a new leader to come in, see something they see as “useless”, and get rid of it – without understanding the implications. Good leaders make sure they understand before they mess around.
Give people something to link to so they can talk about your features and ideas
If you have a project, an idea, a product feature, or anything else that you want other people to understand and have conversations about... give them something to link to!
[... 685 words]Load Balancing. Sam Rose built this interactive essay explaining how different load balancing strategies work. It's part of a series that includes memory allocation, bloom filters and more.