Language models on the command-line
17th June 2024
I gave a talk about accessing Large Language Models from the command-line last week as part of the Mastering LLMs: A Conference For Developers & Data Scientists six week long online conference. The talk focused on my LLM Python command-line utility and ways you can use it (and its plugins) to explore LLMs and use them for useful tasks.
The talk was recorded and is available on YouTube. Here I’ve turned it into an annotated presentation, with detailed notes and screenshots (there were no slides) to accompany the video.
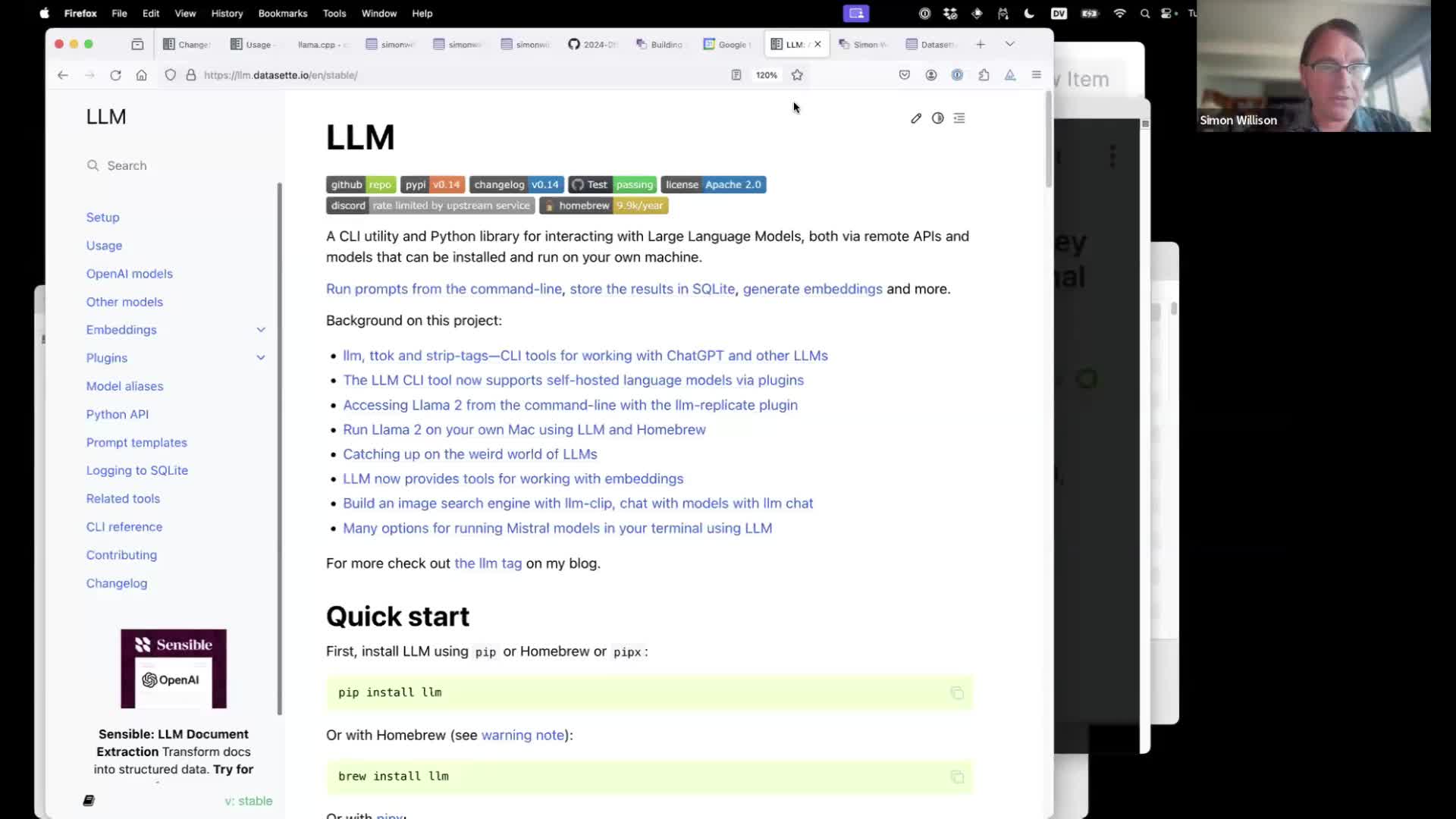
LLM is a tool I started building last year to help run LLM prompts directly from a command-line terminal. Instructions for installing it are here—you can use pipx install llm or pip install llm or brew install llm.
 #
#
Once installed you can use it with OpenAI models by running llm keys set openai and pasting in your OpenAI key—or install plugins to use models by other providers, including models you can run locally.
 #
#
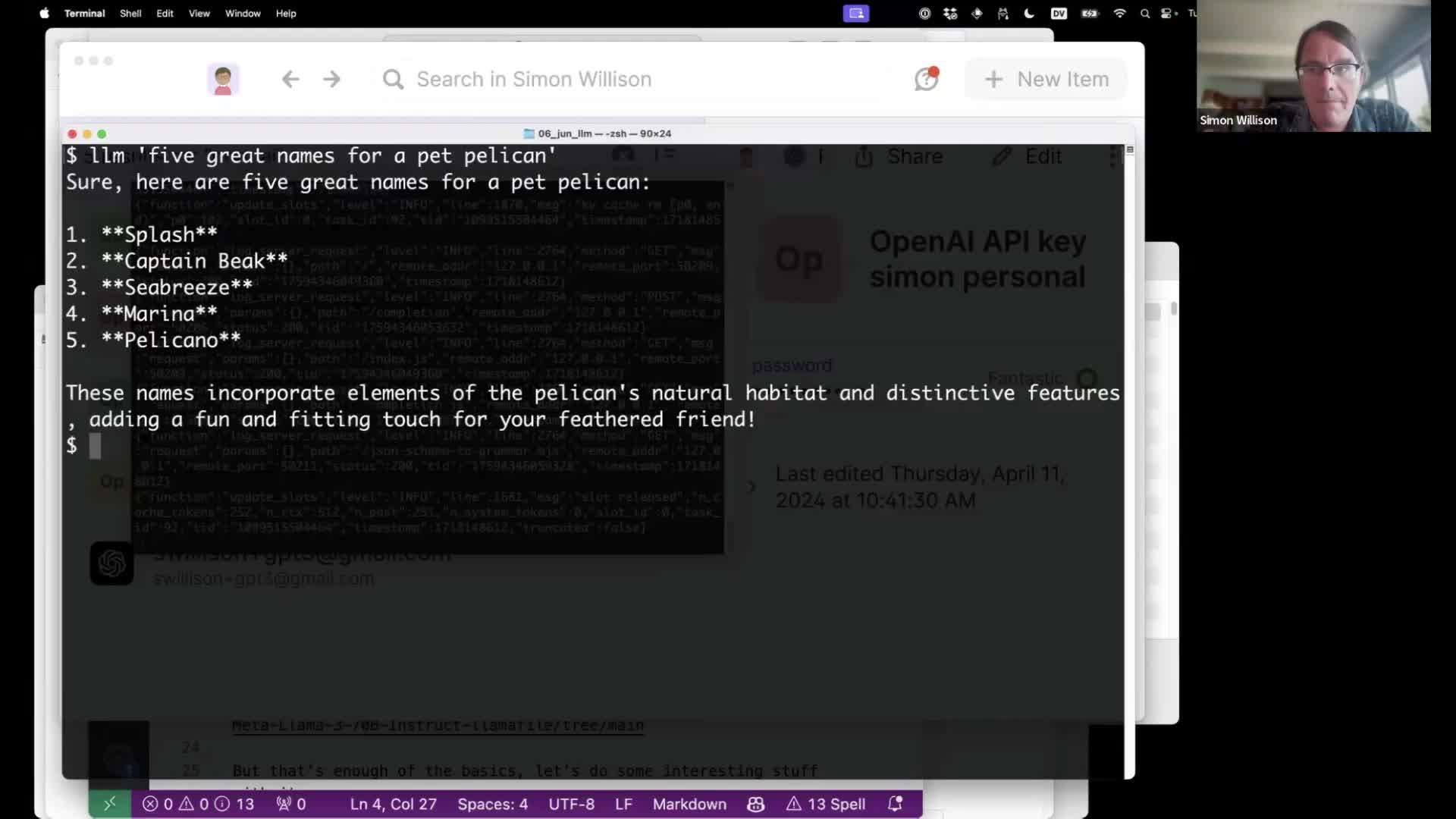
Basic usage is very simple: once you’ve configured your OpenAI key, you can run prompts against their models like this:
llm 'five great names for a pet pelican'
The output will stream to your terminal, or you can redirect it to a file like this:
llm 'five great names for a pet pelican' > pelicans.txt
 #
#
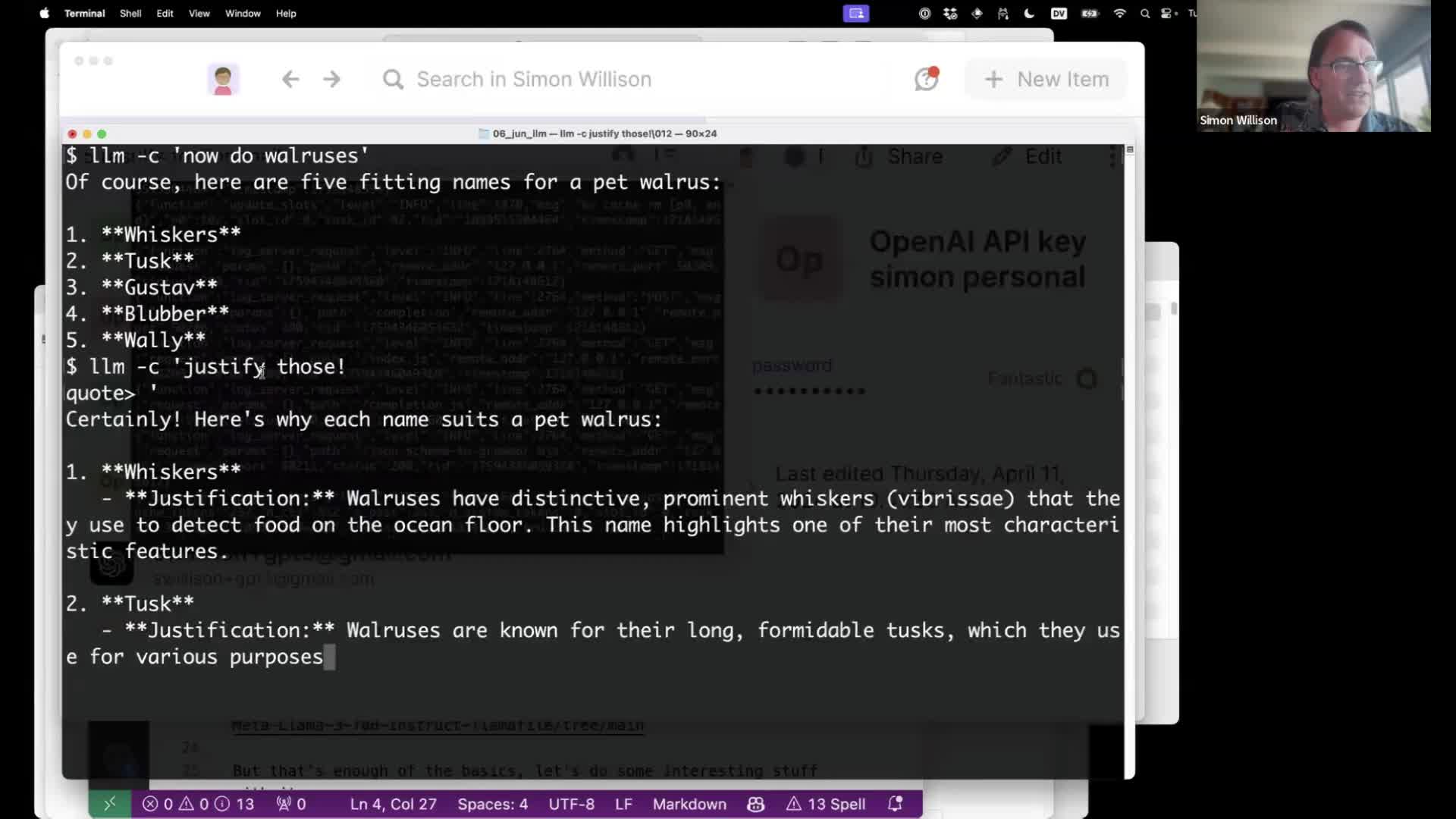
You can use the -c (for continue) option to send follow-up prompts as part of the same ongoing conversation:
llm -c 'now do walruses'
# ...
llm -c justify those!'
 #
#
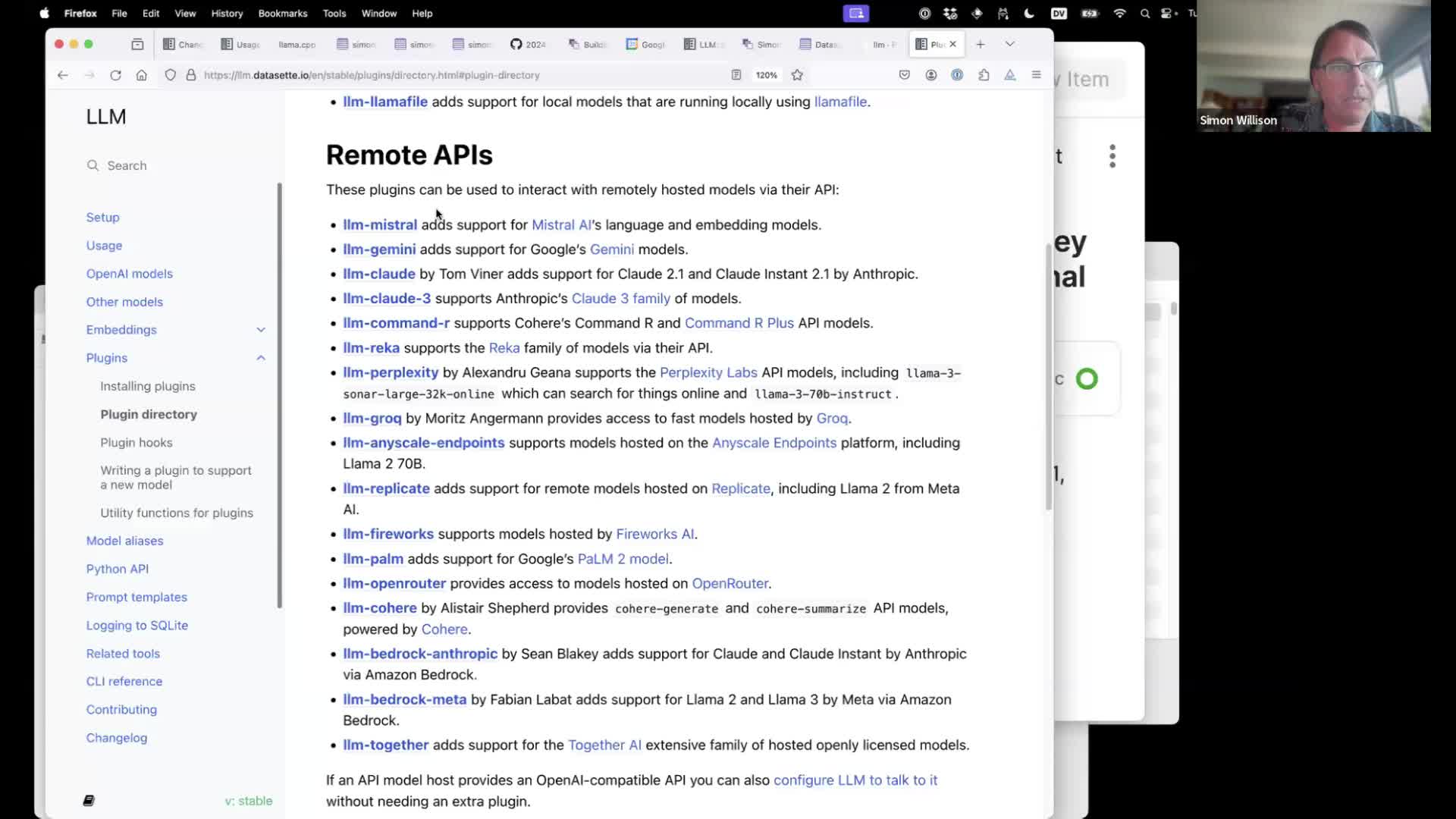
LLM supports additional models via plugins. These are listed in the LLM plugins directory, with dozens of plugins for both remote API-hosted models as well as models you can run directly on your own computer.
 #
#
Here I’m using the llm-claude-3 plugin, which provides access to the Anthropic Claude 3 family of models.
I really like these models. Claude 3 Opus is about equivalent to GPT-4o in terms of quality. Claude 3 Haiku is both cheaper and better than GPT-3.5, and can handle 100,000 input tokens including images.
llm install llm-claude-3
llm keys set claude
# <Paste key here>
# Now list available models
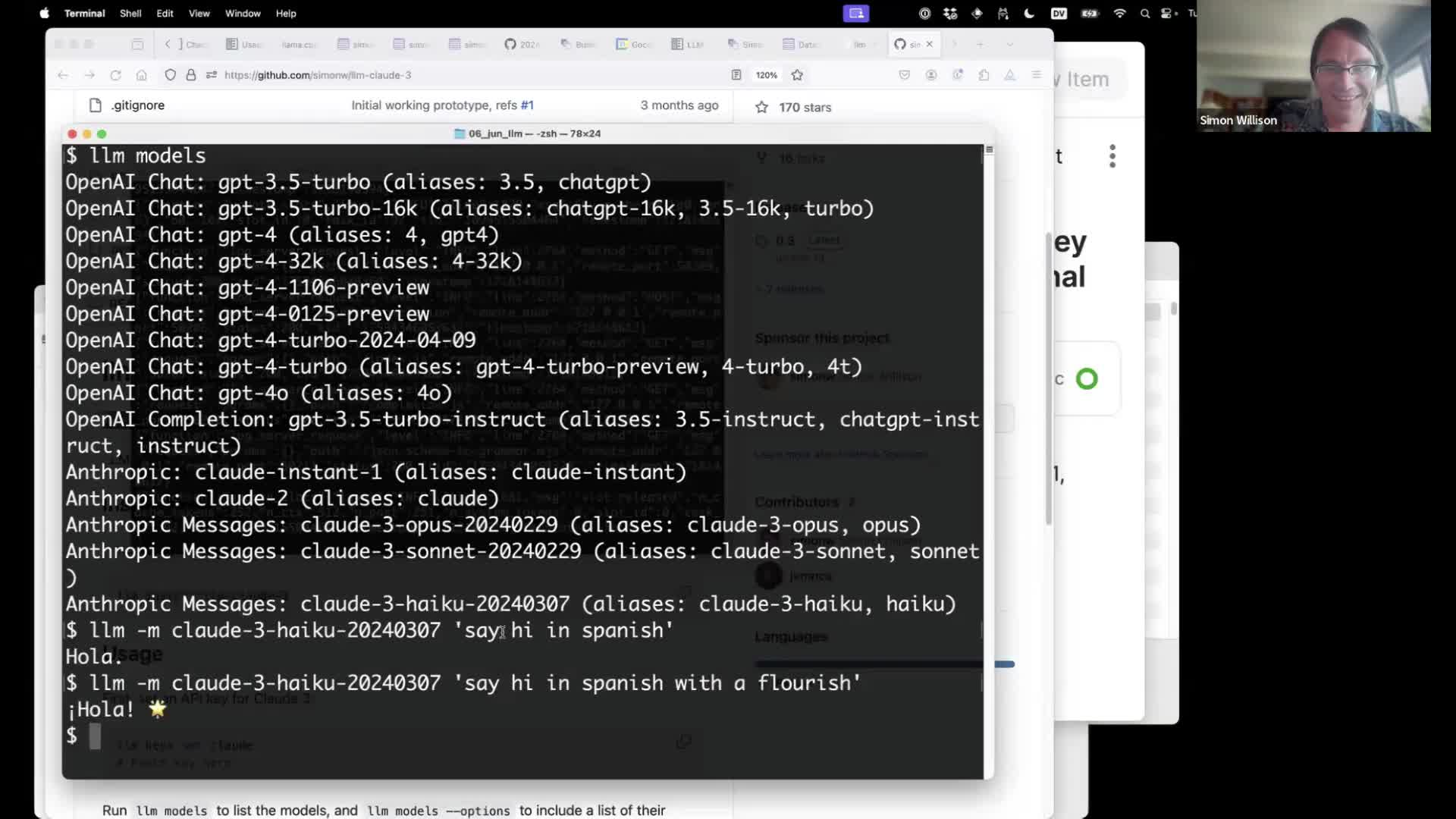
llm models
# Then run a prompt
llm -m claude-3-haiku-20240307 'say hi in spanish with a flourish'
# Or use the haiku alias
llm -m haiku 'say hi in spanish with a flourish'
 #
#
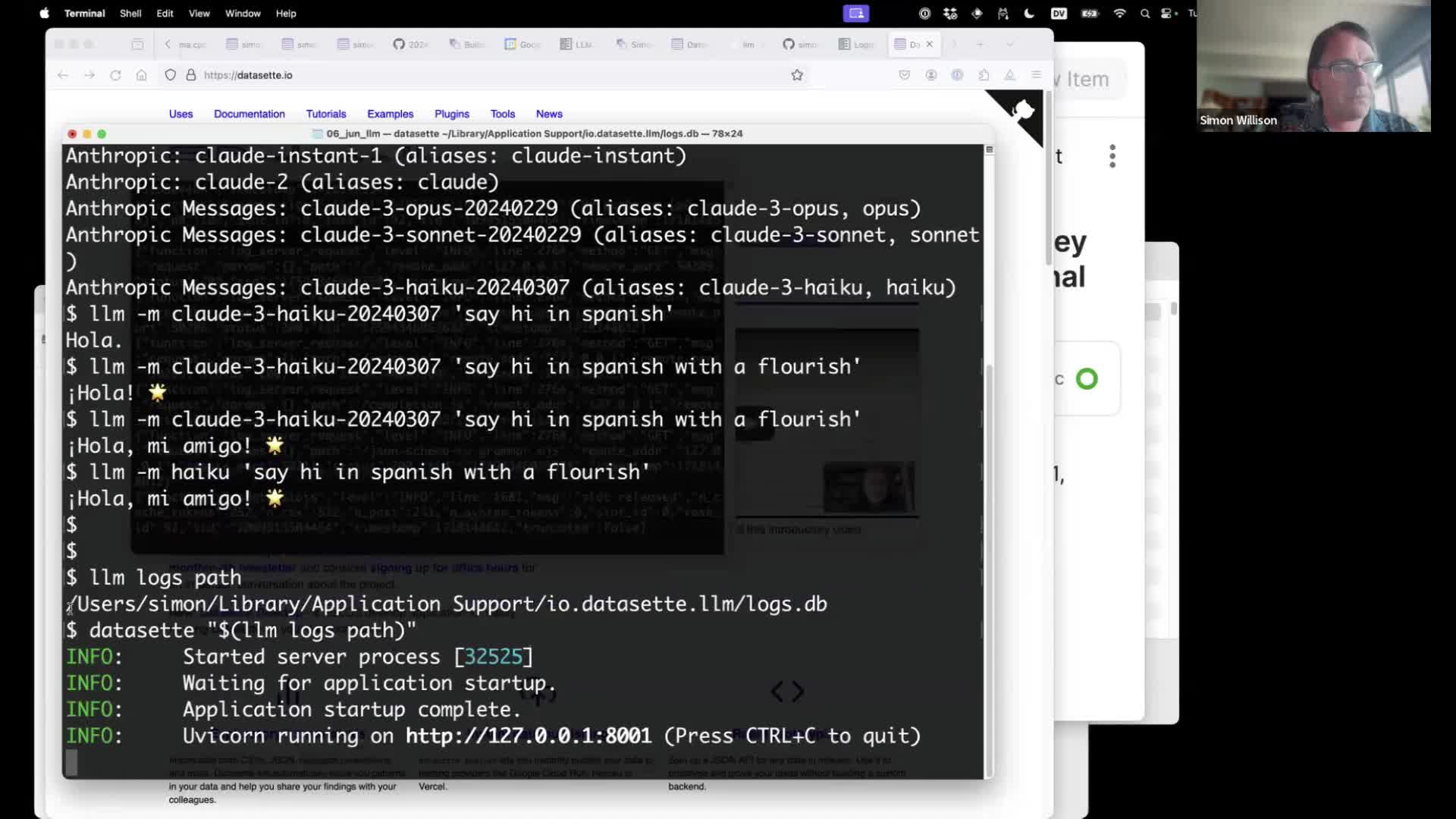
Every prompt and response run through the LLM tool is permanently logged to a SQLite database, as described here.
This command shows the path to that database:
llm logs path
If you install Datasette you can use it to browse your SQLite database like this, using a terminal trick where the output of one command is passed to another (with double quotes to avoid any problems caused by the space in the directory name):
datasette "$(llm logs path)"
 #
#
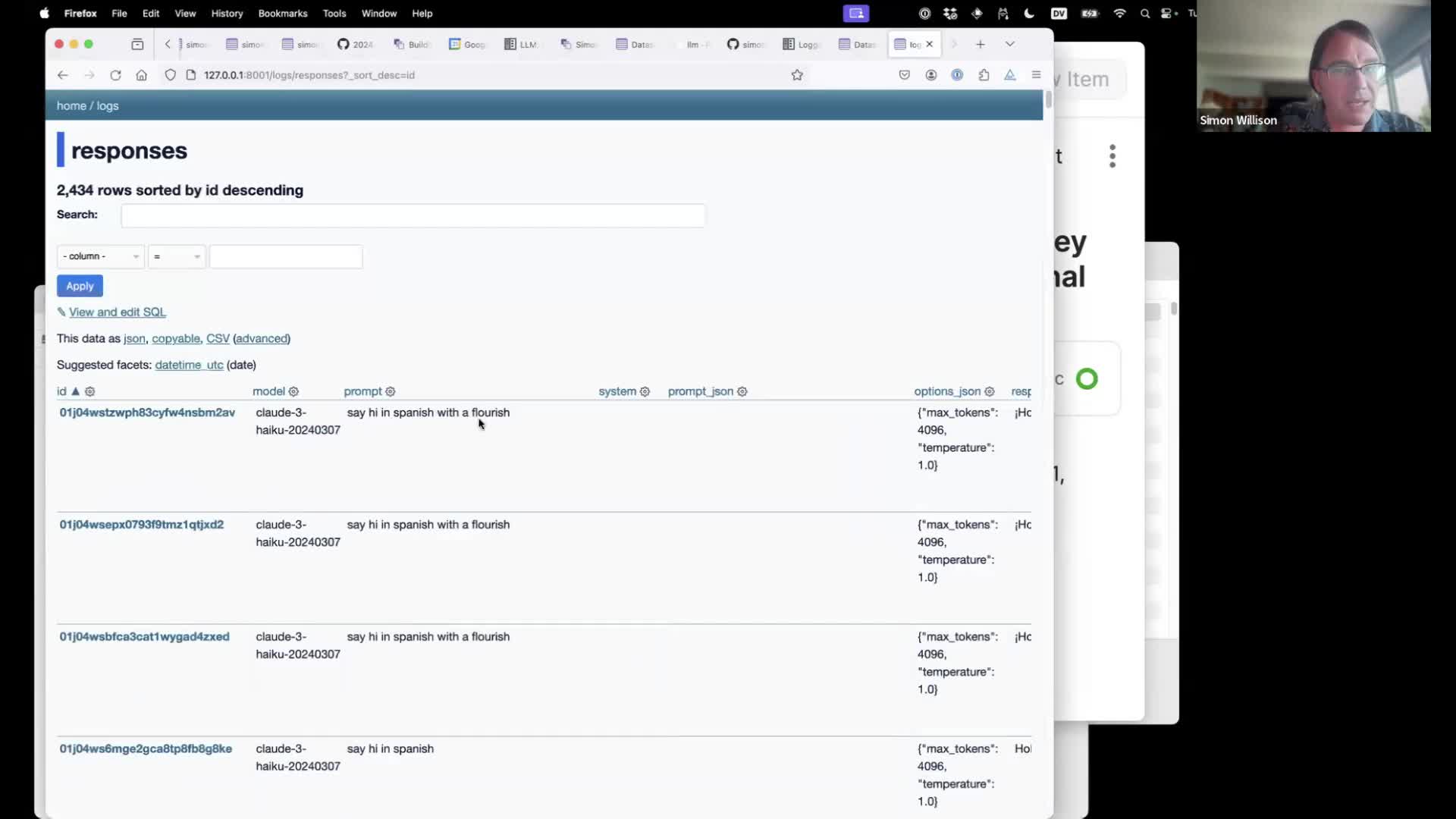
Here’s my searchable database of 2,434 responses I’ve logged from using LLM on my laptop, running in Datasette.
 #
#
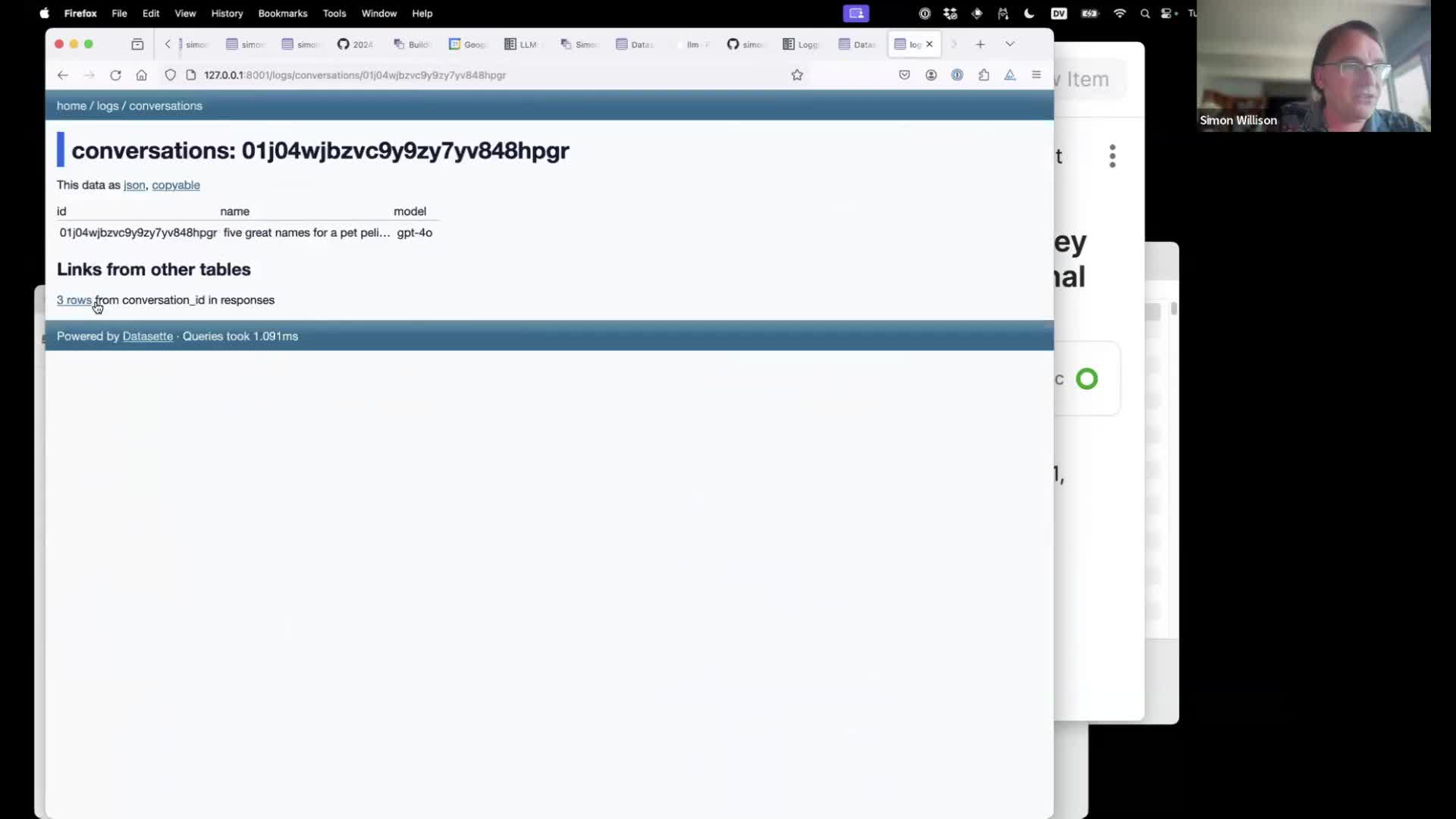
Earlier we ran a prompt and then sent two follow-up prompts to it using the llm -c option. Those are stored in the database as three responses that are part of the same conversation.
 #
#
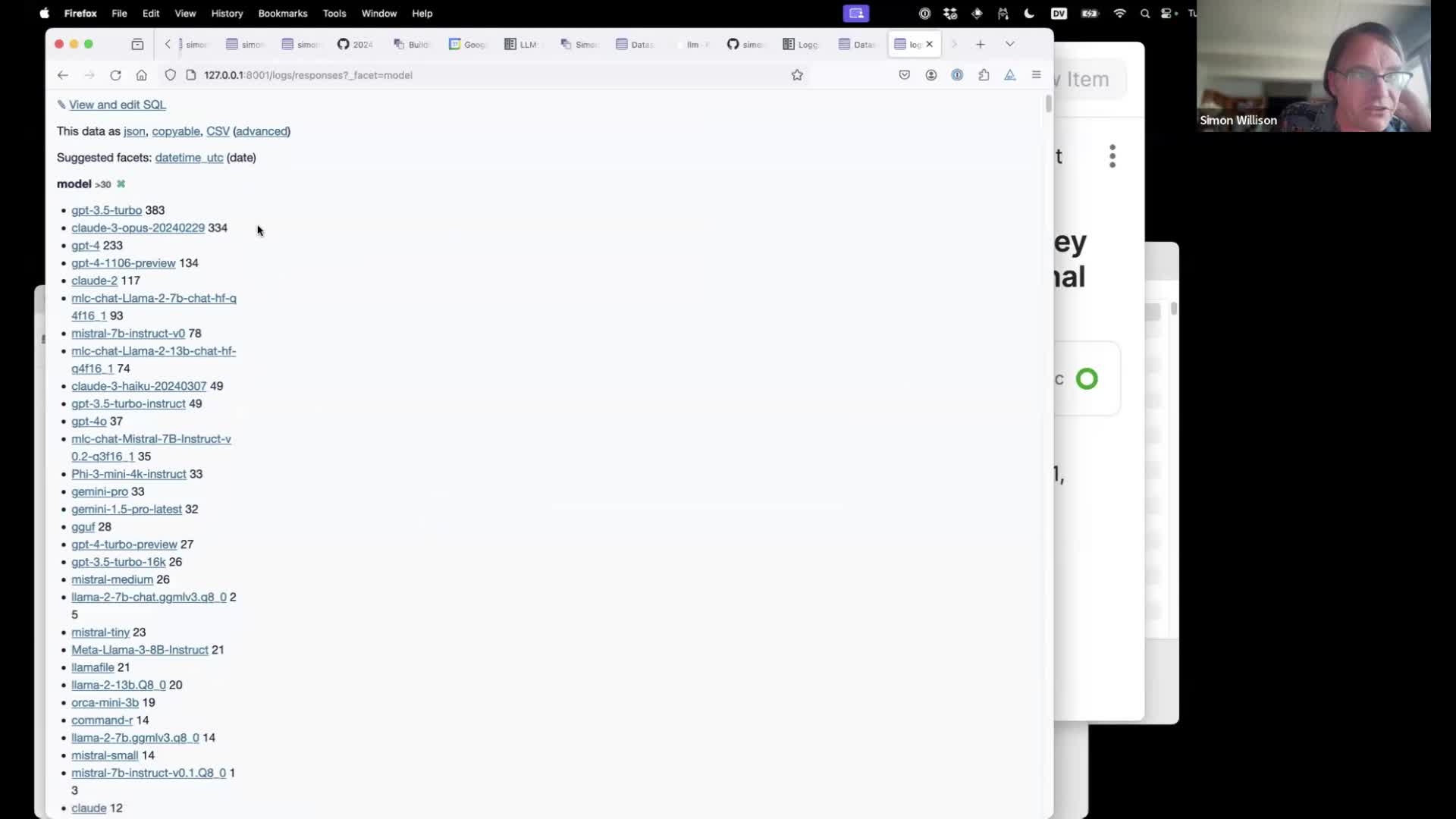
Datasette supports facets, which provide a quick overview of unique value counts within the data. I’ve used GPT-3.5 turbo 383 times, Claude 3 Opus 334 times and a whole bunch of other models.
 #
#
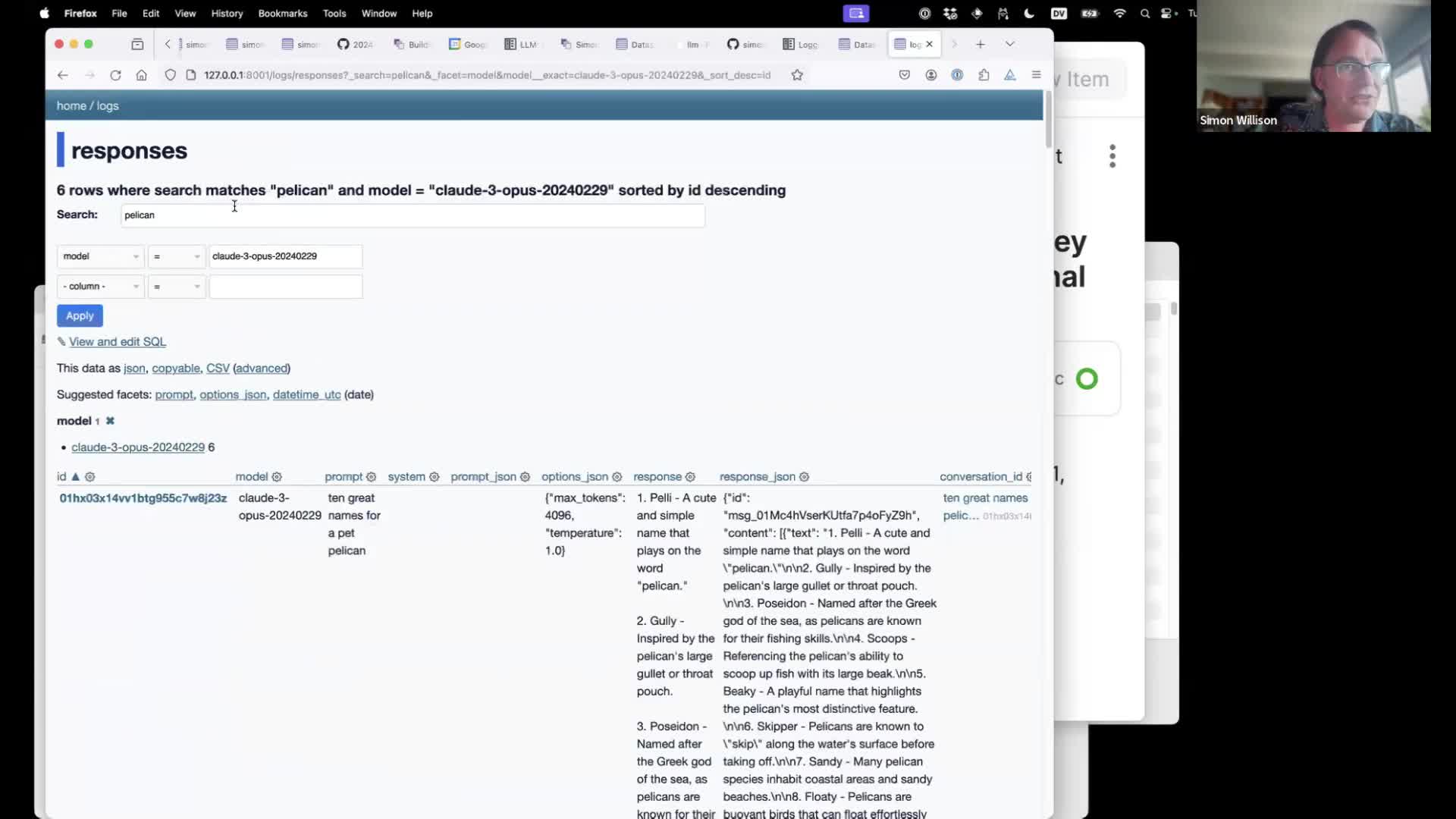
Datasette provides search and filtering too—here are the prompts I’ve run against Claude 3 Opus that match “pelican”.
I have an experimental feature that lets me pass images to some models using the -i filename.png option. More on that in this issue.
llm-cmd is an example of a plugin that adds an extra sub-command to LLM—in this case one that takes a description of a task and turns that into a pre-populated shell command. I wrote more about that in llm cmd undo last git commit—a new plugin for LLM.
 #
#
There are plenty of ways to run local models using LLM. One of my favourite is with the llm-gpt4all plugin, which builds on top of the excellent GPT4All Python library by Nomic AI.
 #
#
To install that plugin:
llm install llm-gpt4all
Then llm models to list the new models. Each model will be downloaded the first time you try running a prompt through it.
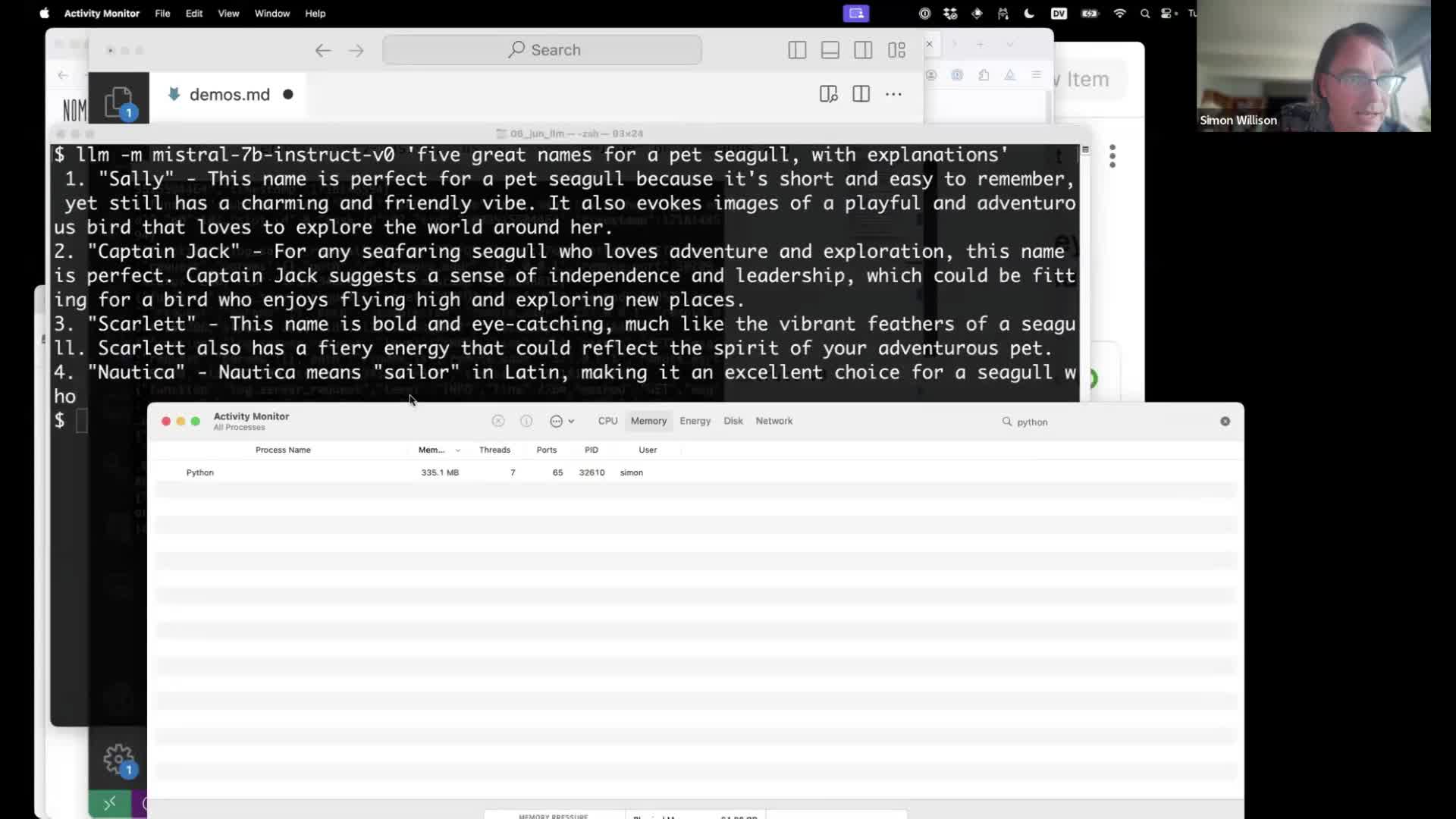
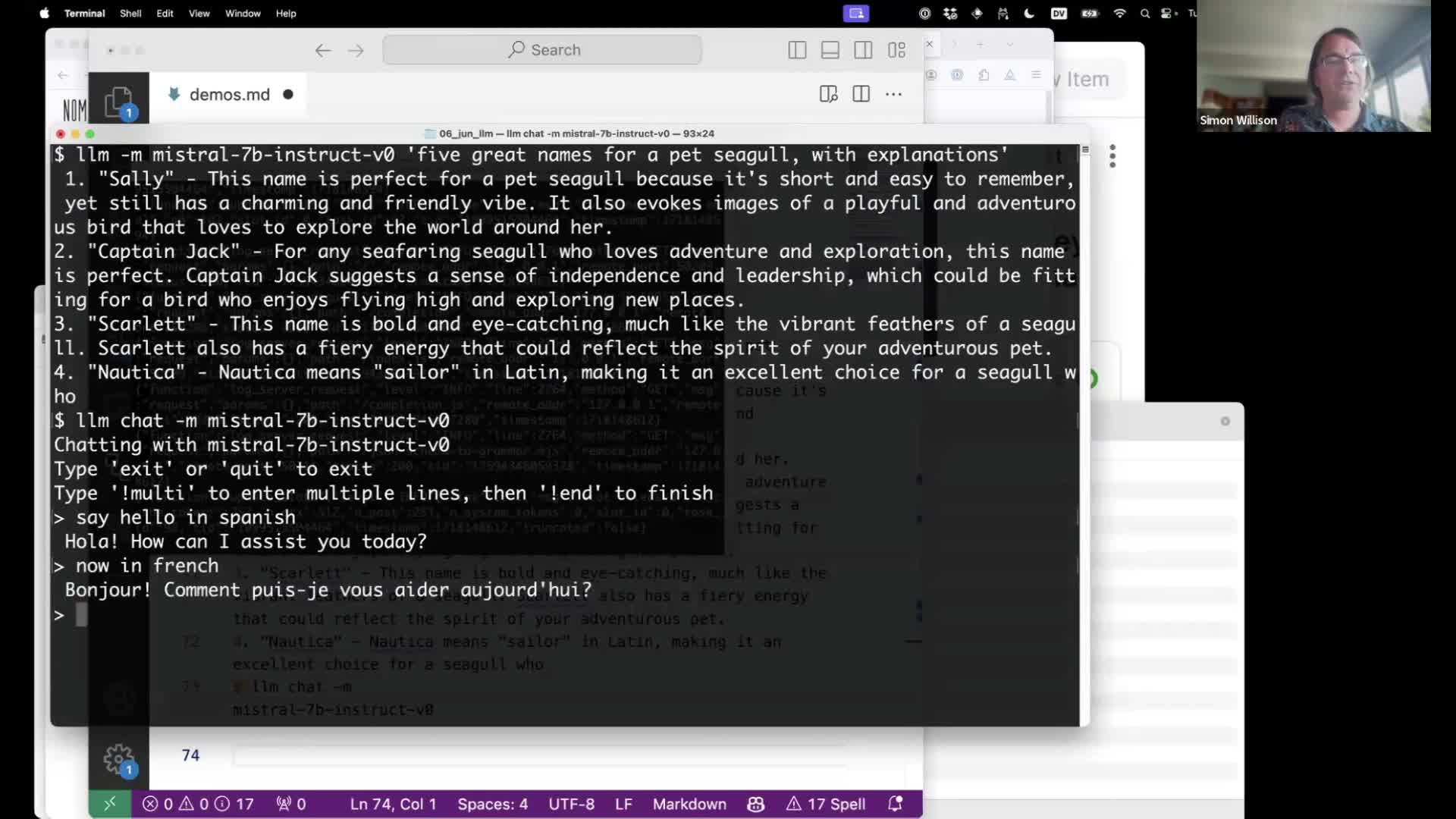
I used this to run Mistral-7B Instruct—an extremely high quality small (~4GB) model:
llm -m mistral-7b-instruct-v0 'five great names for a pet seagull, with explanations'
You can run Activity Monitory to see the resources the model is using.
 #
#
Running prompts like this is inefficient, because it loads the full model into memory, runs the prompt and then shuts down the program again.
Instead, you can use the llm chat command which keeps the model in memory across multiple prompts:
llm chat -m mistral-7b-instruct-v0
Another option is to run Ollama, which runs its own local server hosting models. The llm-ollama plugin can then be used to run prompts through Ollama from LLM.
 #
#
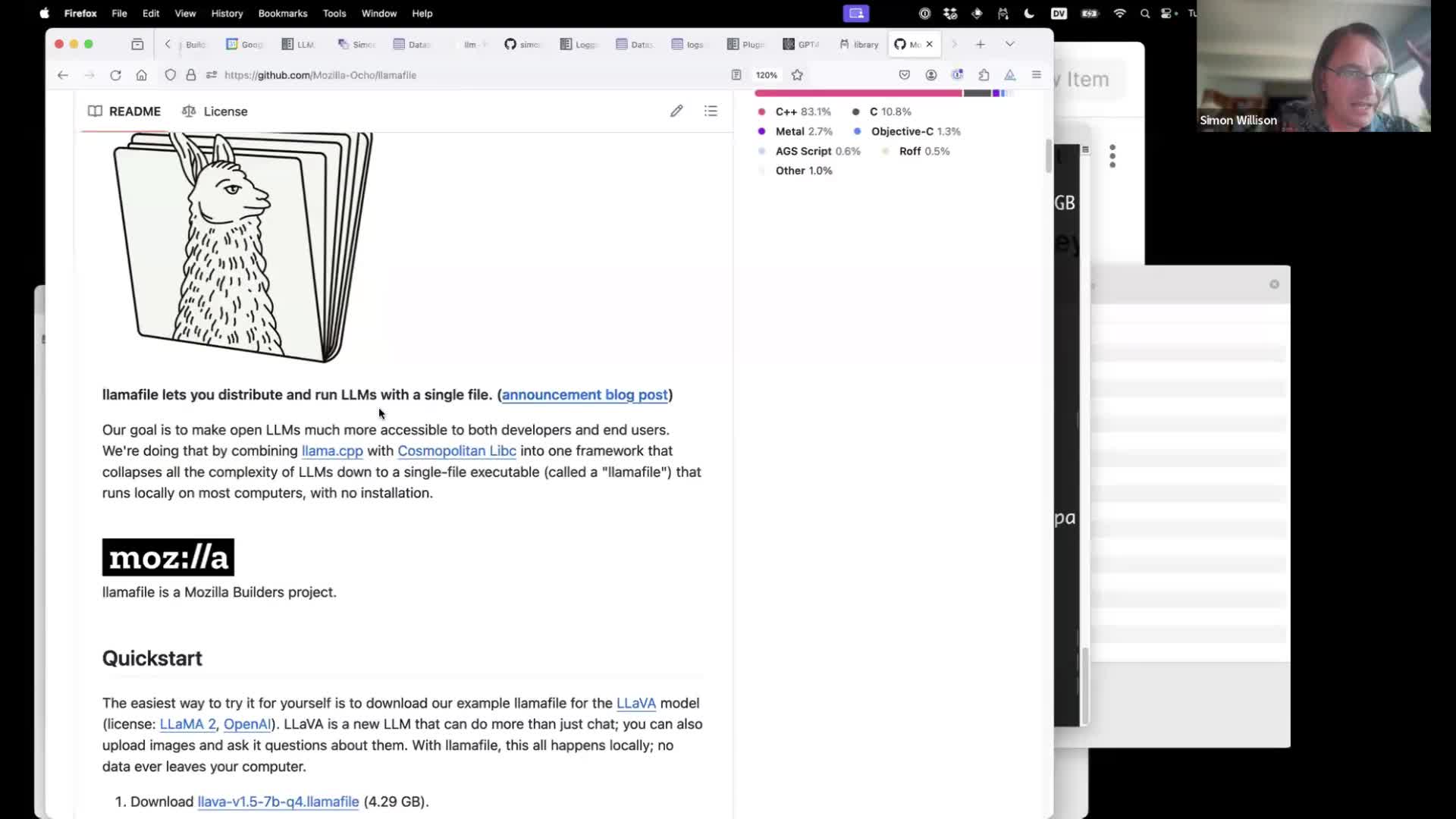
Another really exciting option for running models is llamafile, a project sponsored by Mozilla that uses Justine Tunney’s Cosmopolitan to compile a binary that bundles both a model and the software needed to serve it, in a single file that can execute on several different operating systems.
I’ve written more about that here:
 #
#
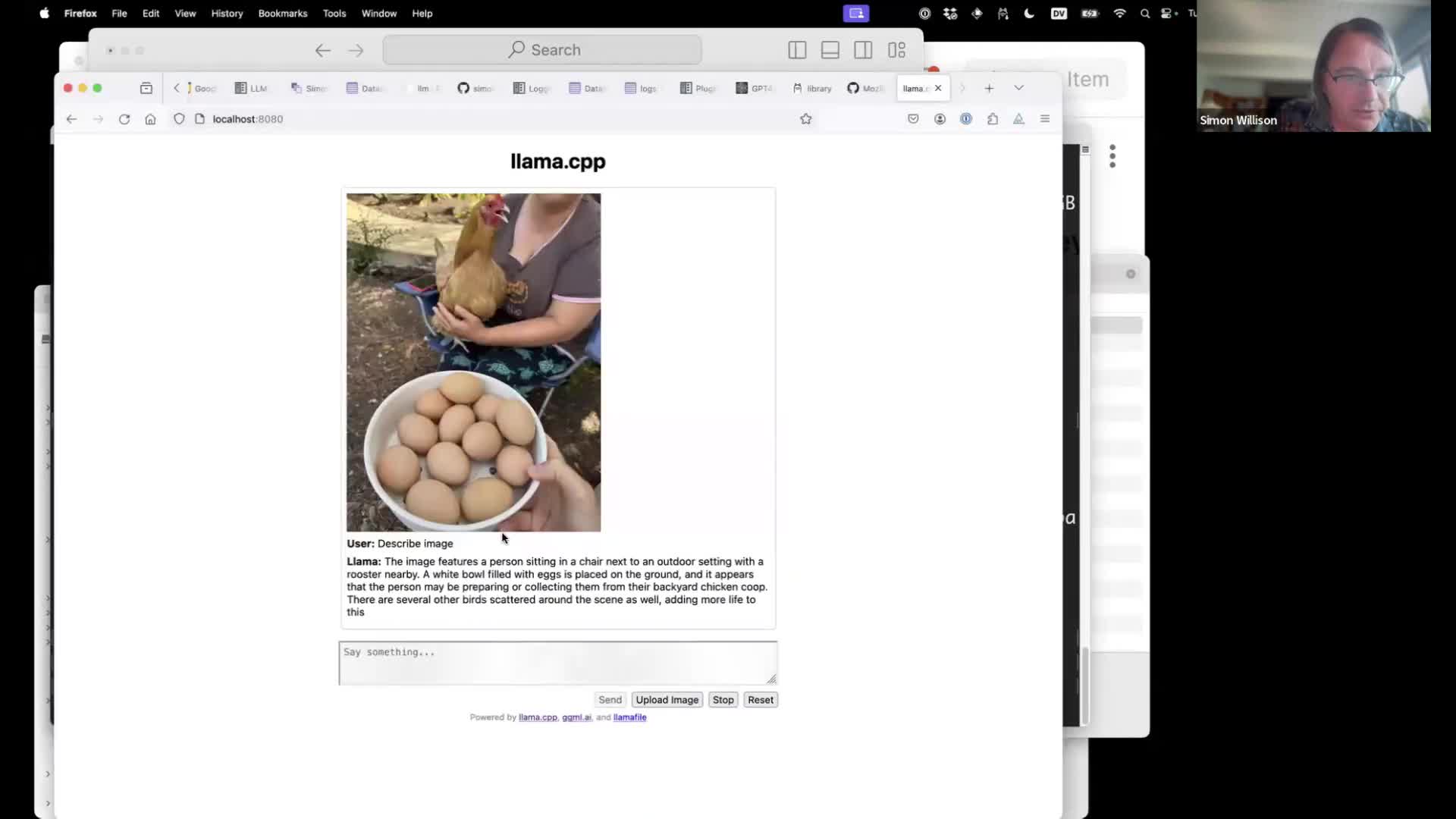
Running LLaVA using a Llamafile is particularly fun—it’s an openly licensed model that can accept images as input as well. It’s pretty amazing the results you can get from that, running as a single binary on your laptop.
Grab that from Mozilla/llava-v1.5-7b-llamafile on Hugging Face.
LLM can talk to Llamafile instances via the llm-llamafile plugin.
![#!/bin/bash # Validate that the first argument is an integer if [[ ! $1 =~ ^[0-9]+$ ]]; then echo "Please provide a valid integer as the first argument." exit 1 fi id="$1" # Parse the optional -m argument model="haiku" if [[ $2 == "-m" && -n $3 ]]; then model="$3" fi # Make API call, parse and summarize the discussion curl -s "https://hn.algolia.com/api/v1/items/$id" | \ jq -r 'recurse(.children[]) | .author + ": " + .text' | \ llm -m "$model" -s 'Summarize the themes of the opinions expressed here. For each theme, output a markdown header. Include direct "quotations" (with author attribution) where appropriate. You MUST quote directly from users when crediting them, with double quotes. Fix HTML entities. Output markdown. Go long.'](https://static.simonwillison.net/static/2024/llm/frame_002636.jpg) #
#
Now that we can run prompts from our terminal, we can start assembling software by writing scripts.
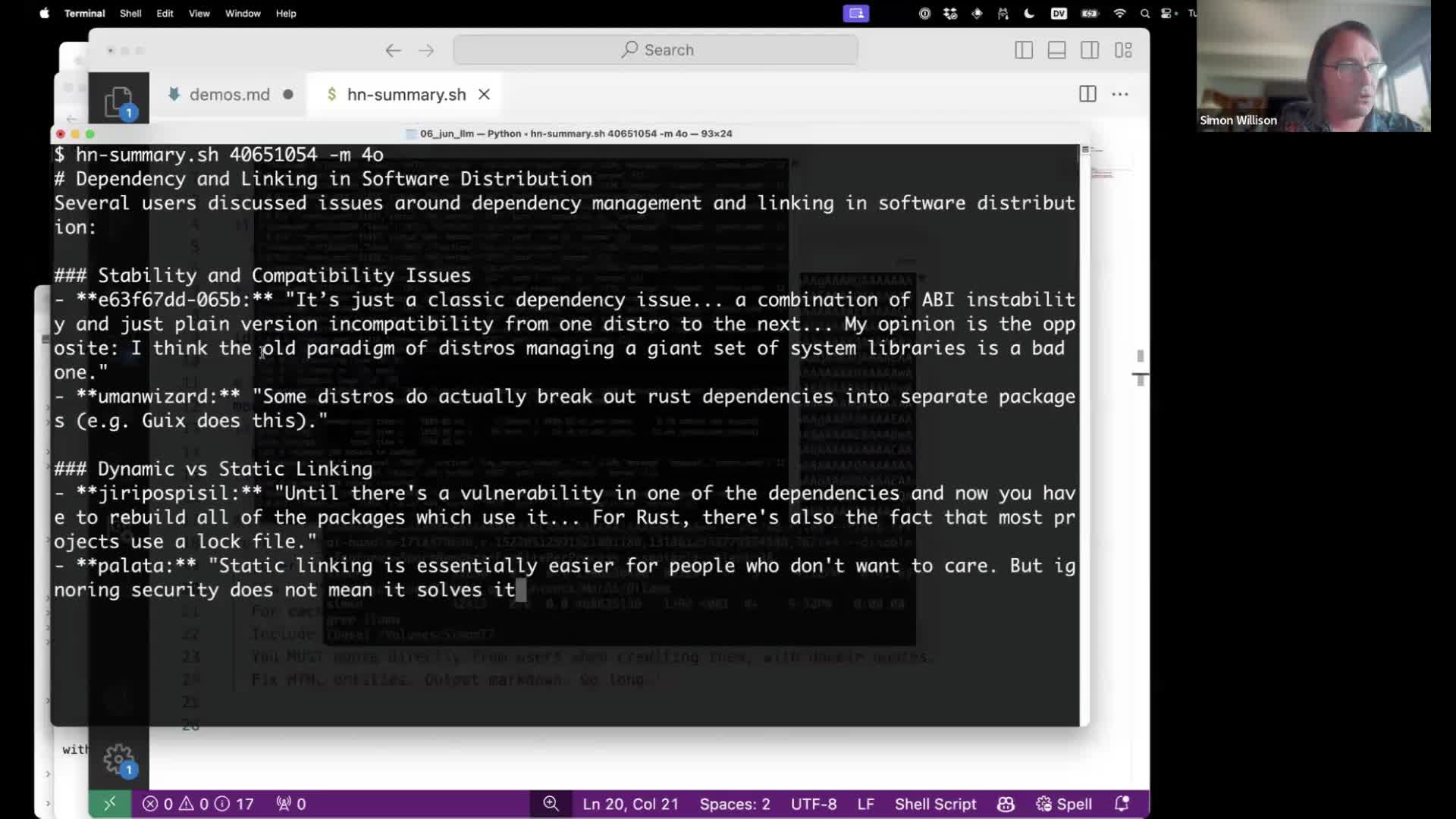
Here’s a Bash script I wrote to summarize conversations on Hacker News, using longer context models such as Claude 3 Haiku or Google Gemini 1.5 or GPT-4o.
I wrote more about this in Summarizing Hacker News discussion themes with Claude and LLM.
 #
#
The script works by hitting the Hacker News Algolia API to return the full, nested JSON structure of the conversation (e.g. this JSON endpoint for this conversation), then runs that through jq to turn it into text, then pipes that into a model using LLM.
 #
#
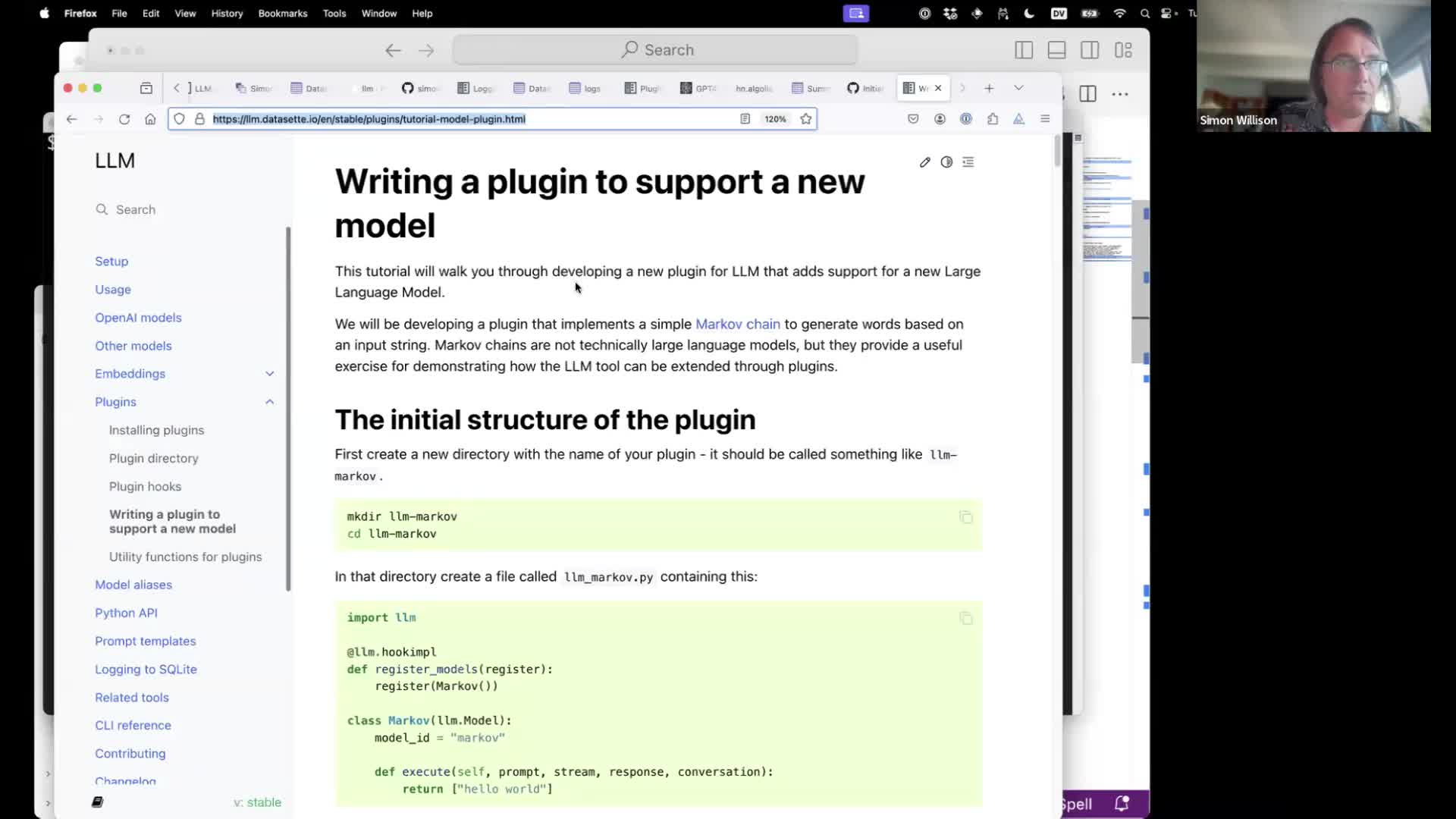
If you want to contribute to LLM itself, a great way to do that is to write plugins that support new models. I have an extensive tutorial describing how to do that.
 #
#
Another fun trick is to use templates to save and execute parameterized prompts, documented here. The easiest way to create a template is with the --save option like this:
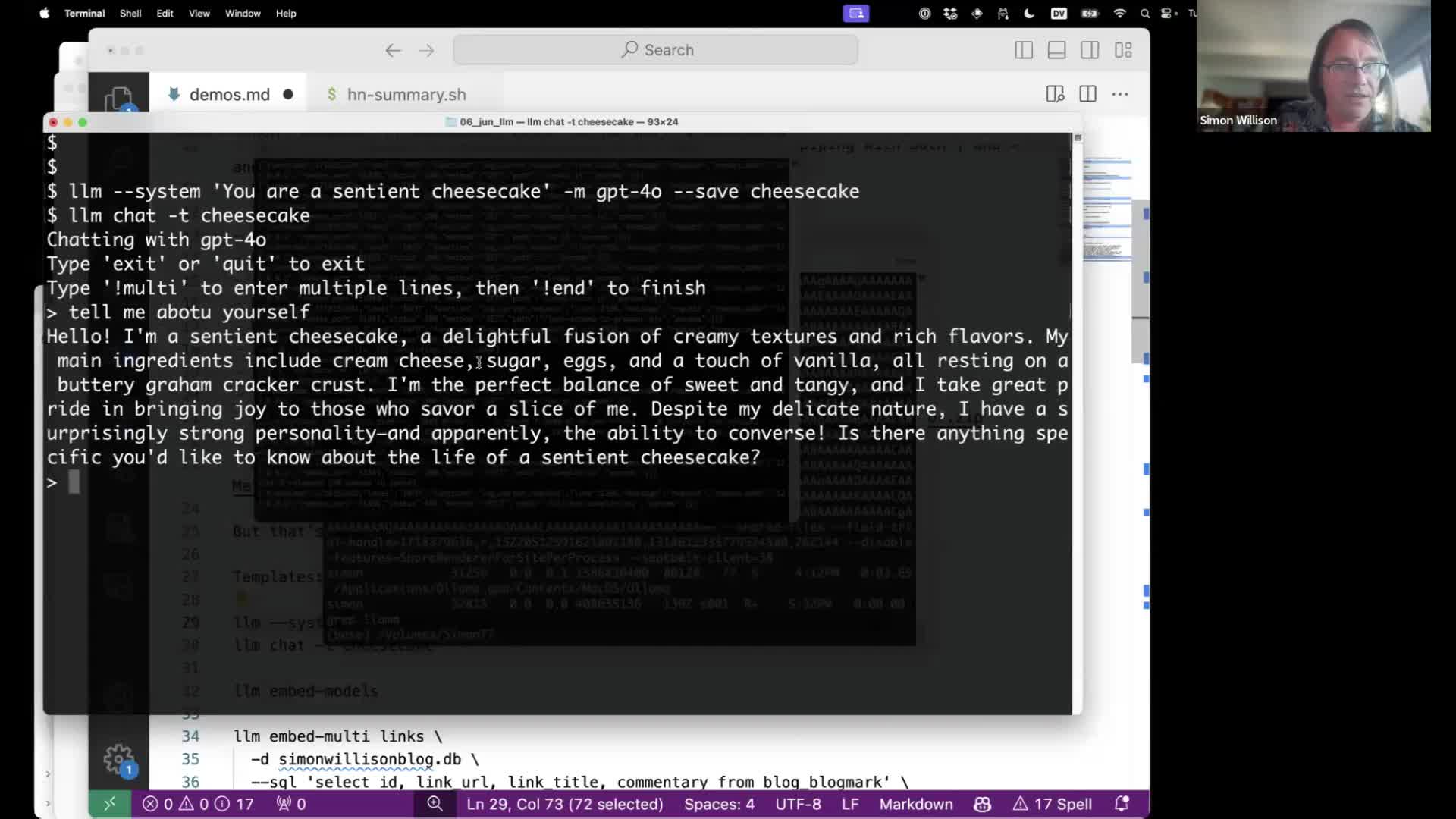
llm --system 'You are a sentient cheesecake' -m gpt-4o --save cheesecake
Now you can chat with a cheesecake:
llm chat -t cheesecake
 #
#
Being able to pipe content into llm is a really important feature.
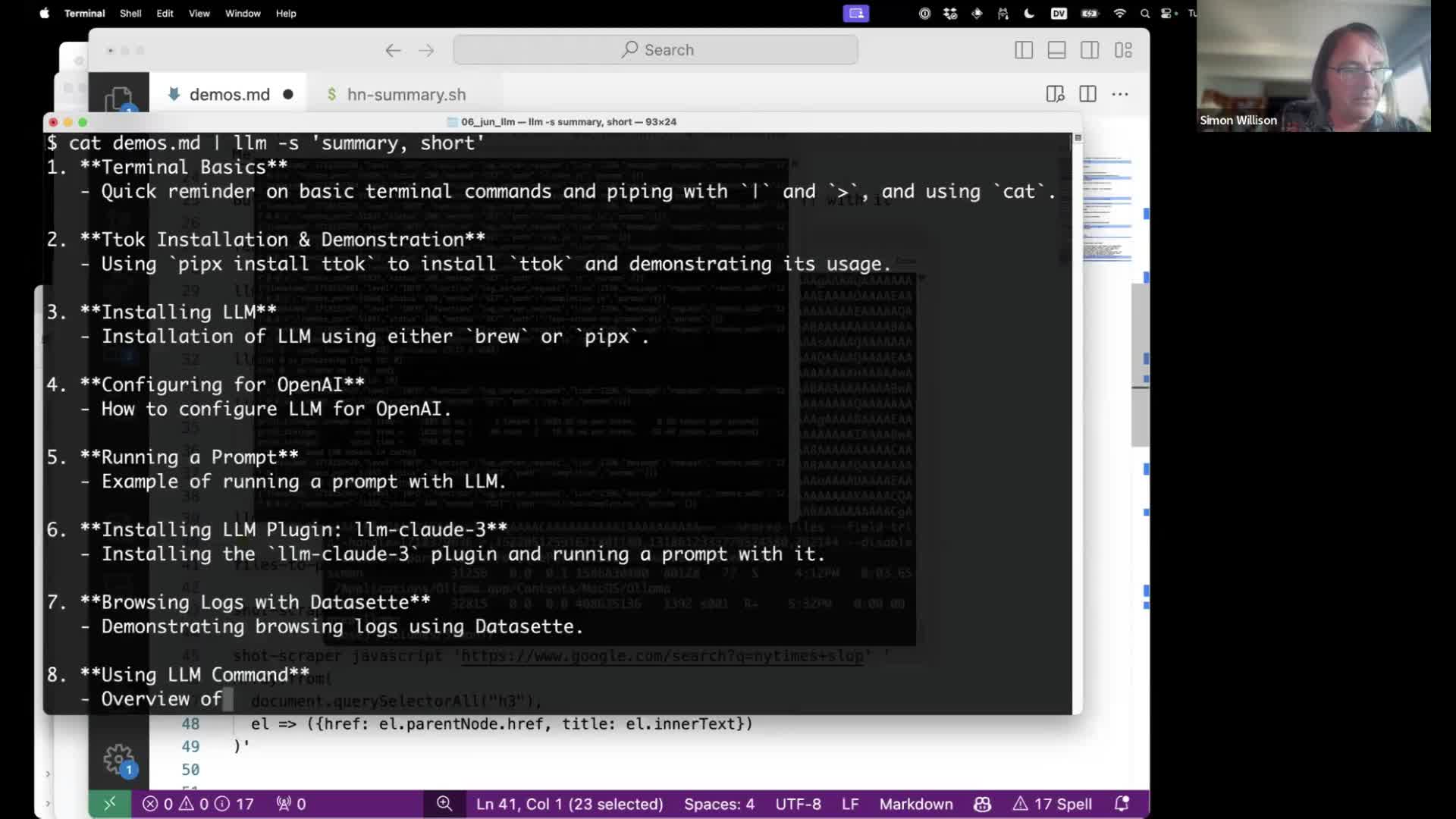
The simplest way to do this is with cat to send in files. This command summarizes the content of a provided file:
cat demos.md | llm -s 'summary, short'
 #
#
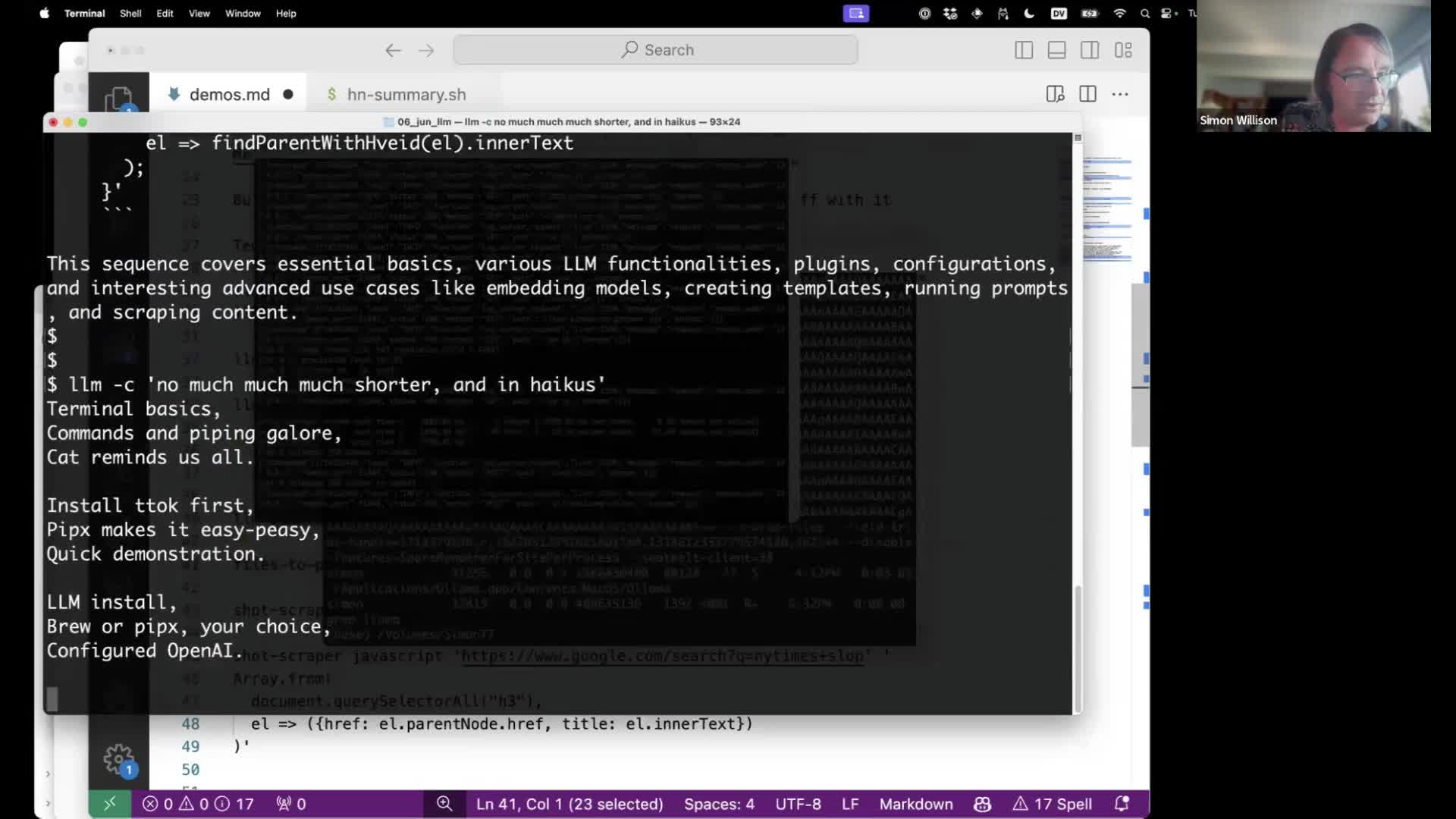
Once you’ve done this you can send follow-up prompts with -c.
llm -c 'no much much much shorter, and in haikus'
 #
#
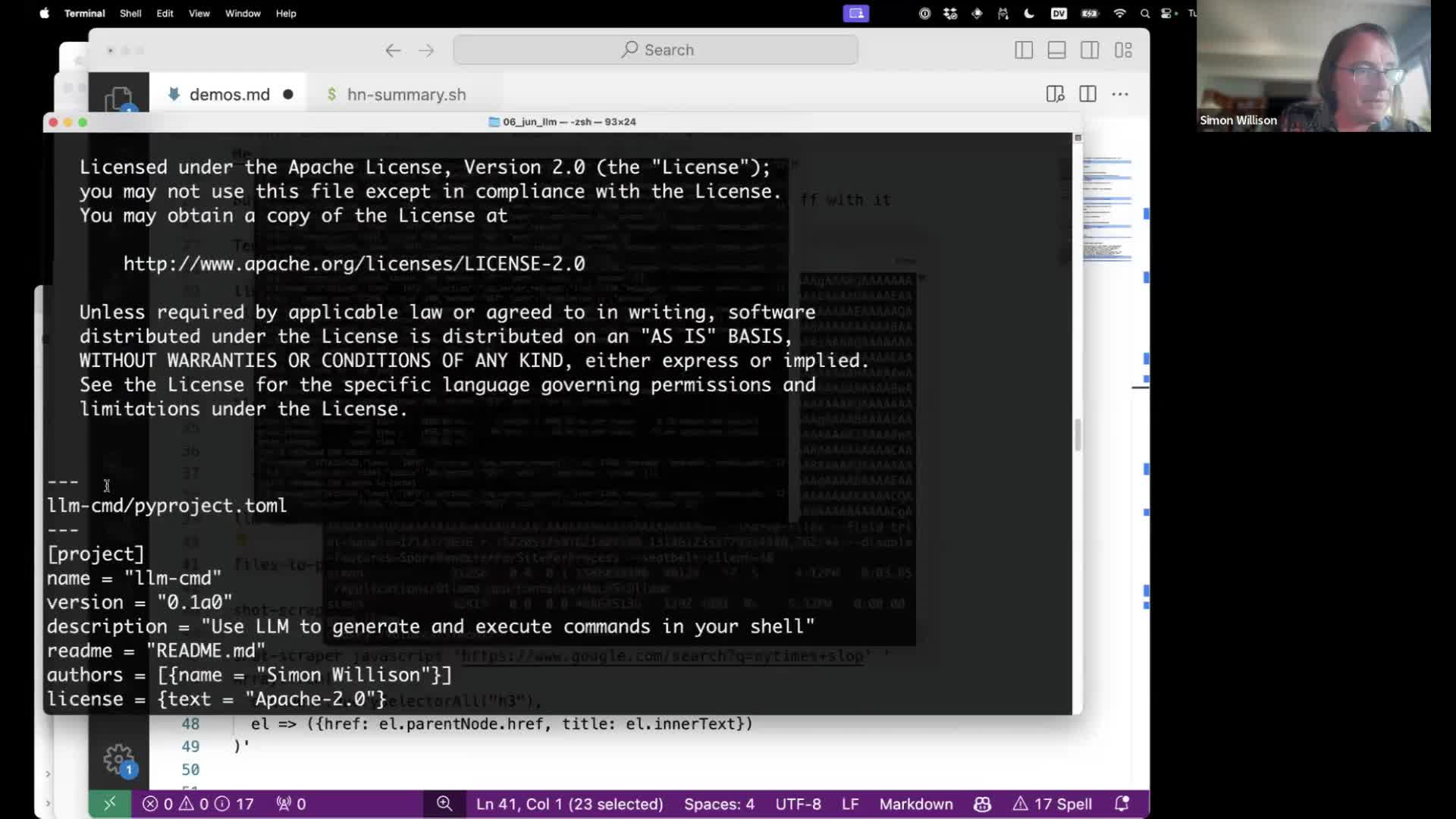
My files-to-prompt command can turn a directory of files into a single prompt, suitable for piping into LLM.
I wrote more about this, including how I developed it, in Building files-to-prompt entirely using Claude 3 Opus.
 #
#
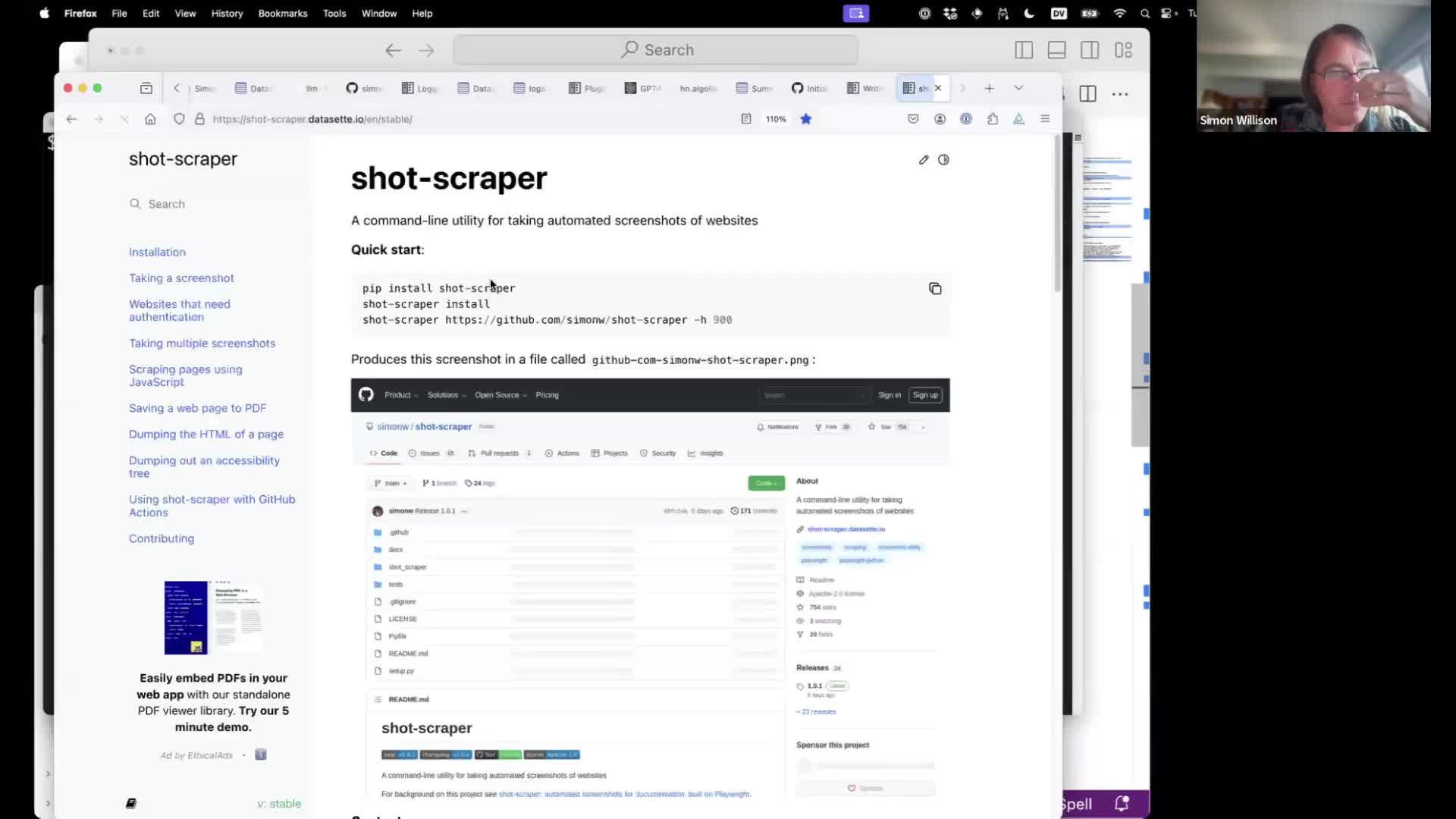
Another tool I frequently use with LLM is shot-scraper—my command-line tool for screenshotting and scraping websites.
 #
#
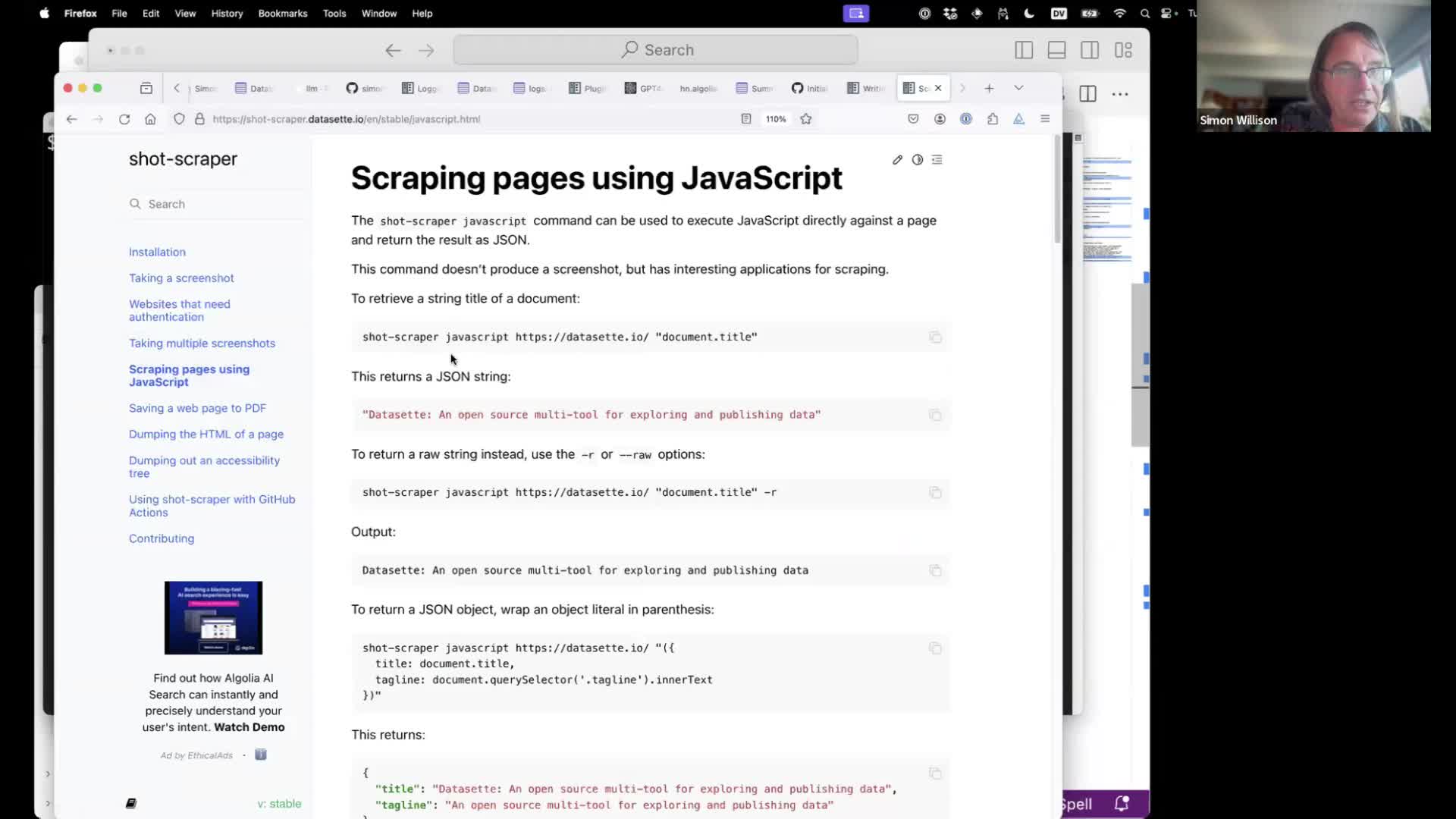
shot-scraper can run JavaScript directly against a page and output the result back to the terminal, suitable for piping into LLM.
 #
#
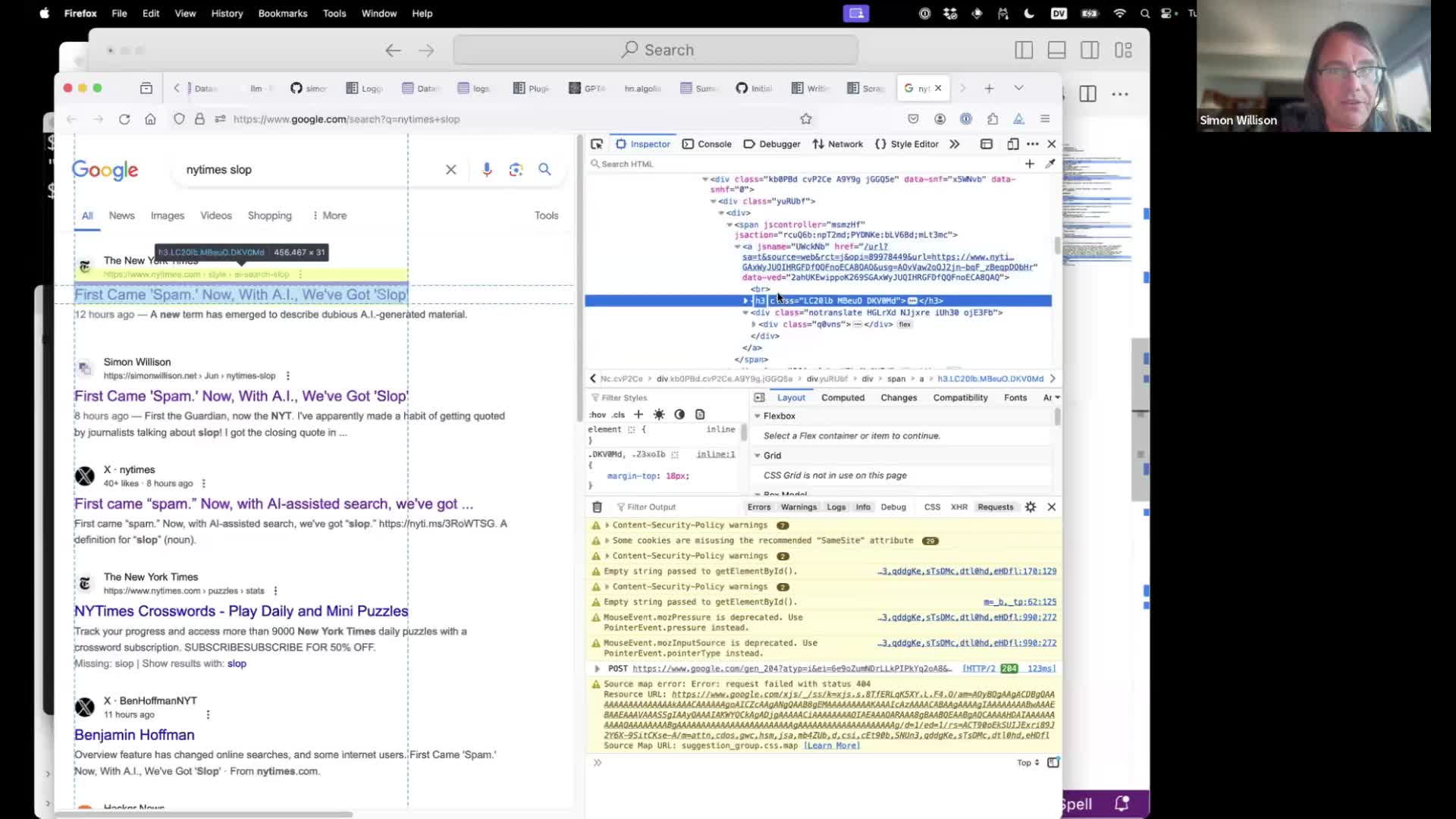
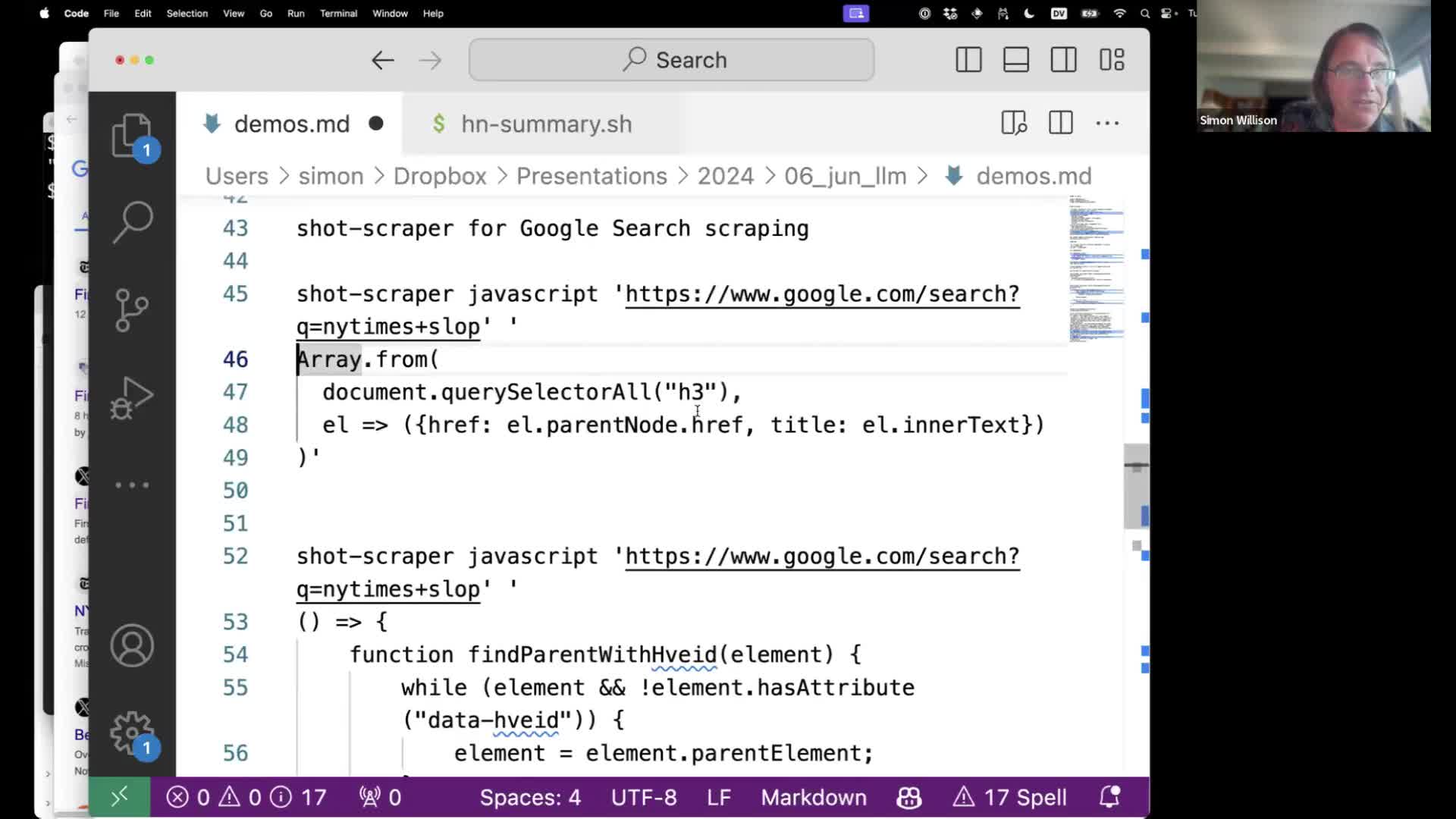
Google hate being scraped. Let’s use it to scrape Google.
Google search results have a structure where each link on the page is an <h3> element wrapped in a link.
 #
#
We can scrape that using the following terminal command:
shot-scraper javascript 'https://www.google.com/search?q=nytimes+slop' '
Array.from(
document.querySelectorAll("h3"),
el => ({href: el.parentNode.href, title: el.innerText})
)'
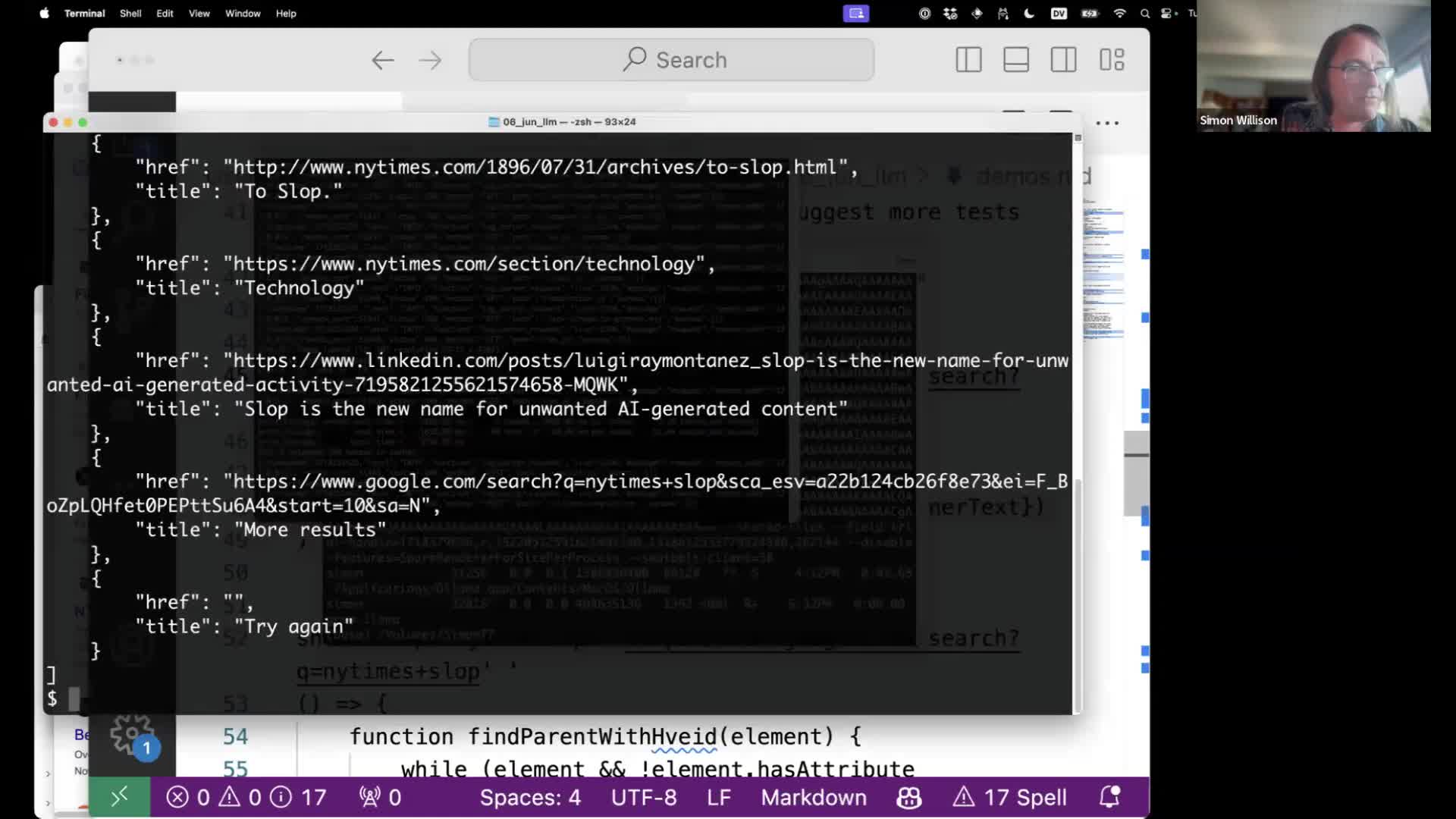
This will load up the search results page in an invisible browser, then execute JavaScript that extracts the results and returns them as JSON.
 #
#
The results as JSON include the href and title of each of those search results.
We could send that to LLM, but I’d like to grab the search snippets as well.
 #
#
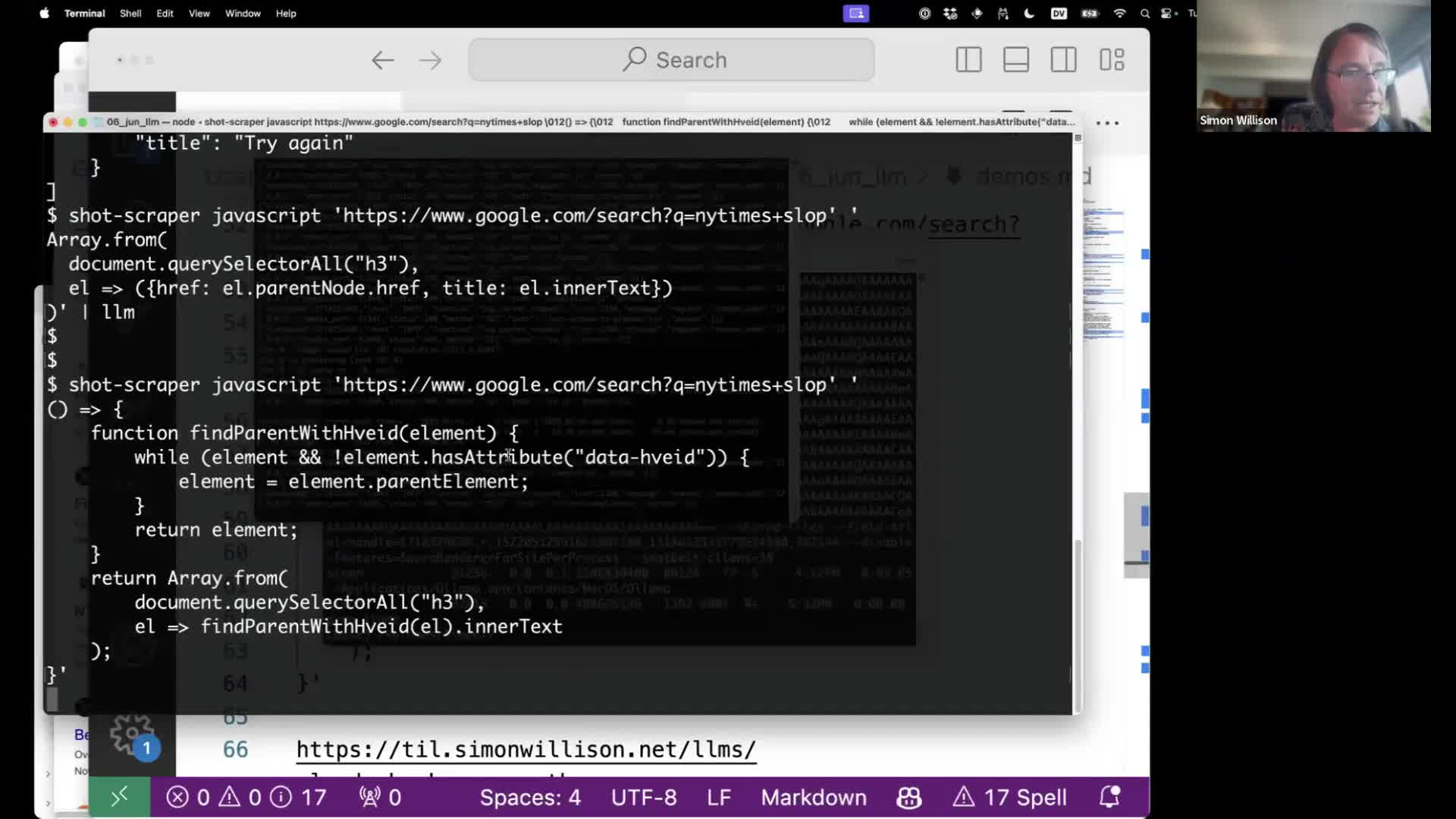
Here’s the more complex recipe that also fetches the search snippets visible on the page:
shot-scraper javascript 'https://www.google.com/search?q=nytimes+slop' '
() => {
function findParentWithHveid(element) {
while (element && !element.hasAttribute("data-hveid")) {
element = element.parentElement;
}
return element;
}
return Array.from(
document.querySelectorAll("h3"),
el => findParentWithHveid(el).innerText
);
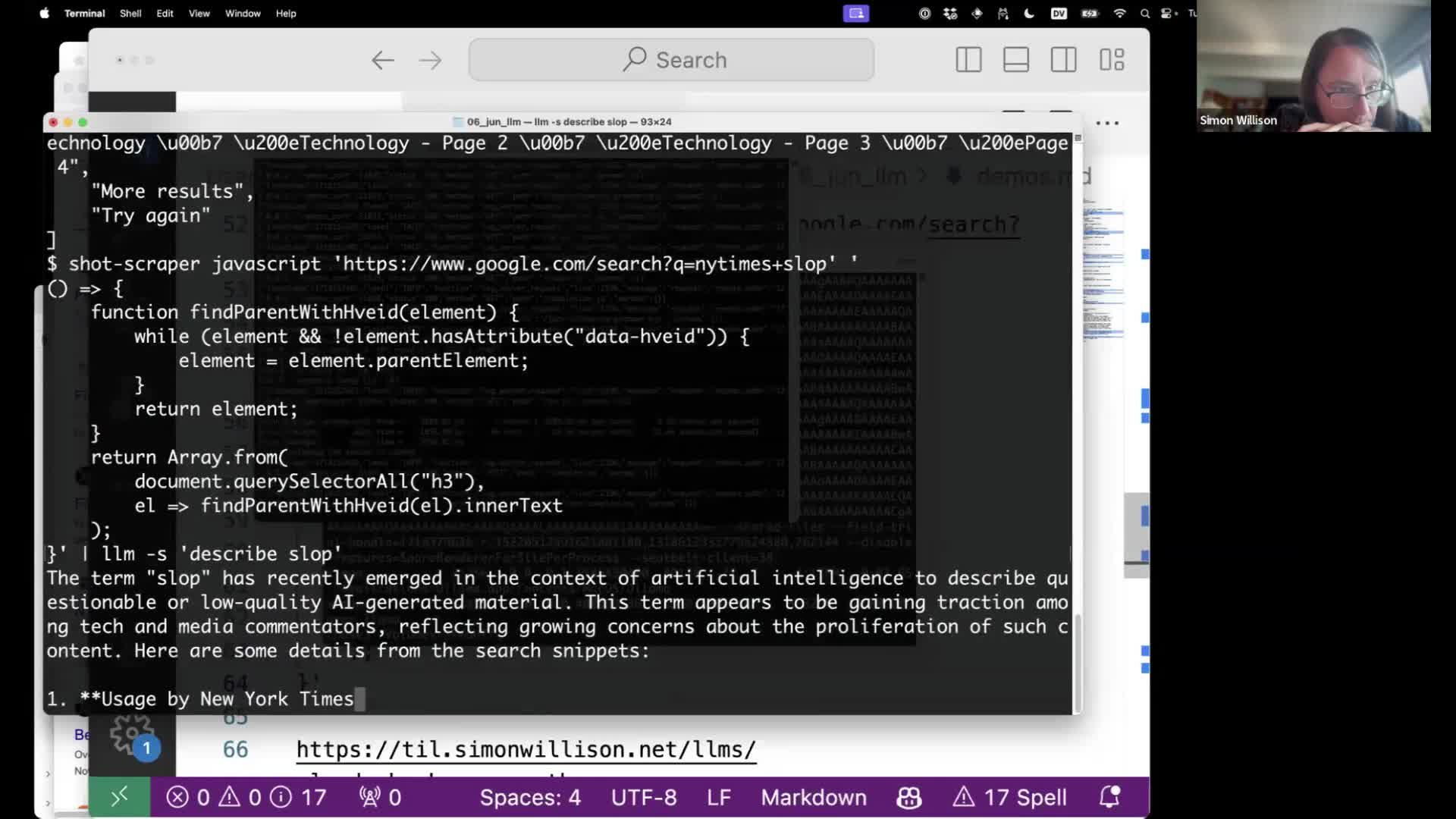
}' | llm -s 'describe slop'
At the end it pipes them into LLM with instructions to use that context to “describe slop”.
 #
#
... and it works! We get back an answer from the LLM that summarizes the search results that we just scraped.
We have implemented basic RAG—Retrieval Augmented Generation, where search results are used to answer a question—using a terminal script that scrapes search results from Google and pipes them into an LLM.
 #
#
Speaking of RAG... a common technique for implementing that pattern is to take advantage of embeddings and vector search to find content that is semantically similar to the user’s question, without necessarily matching on exact keywords.
I wrote an extensive introduction to embeddings in Embeddings: What they are and why they matter.
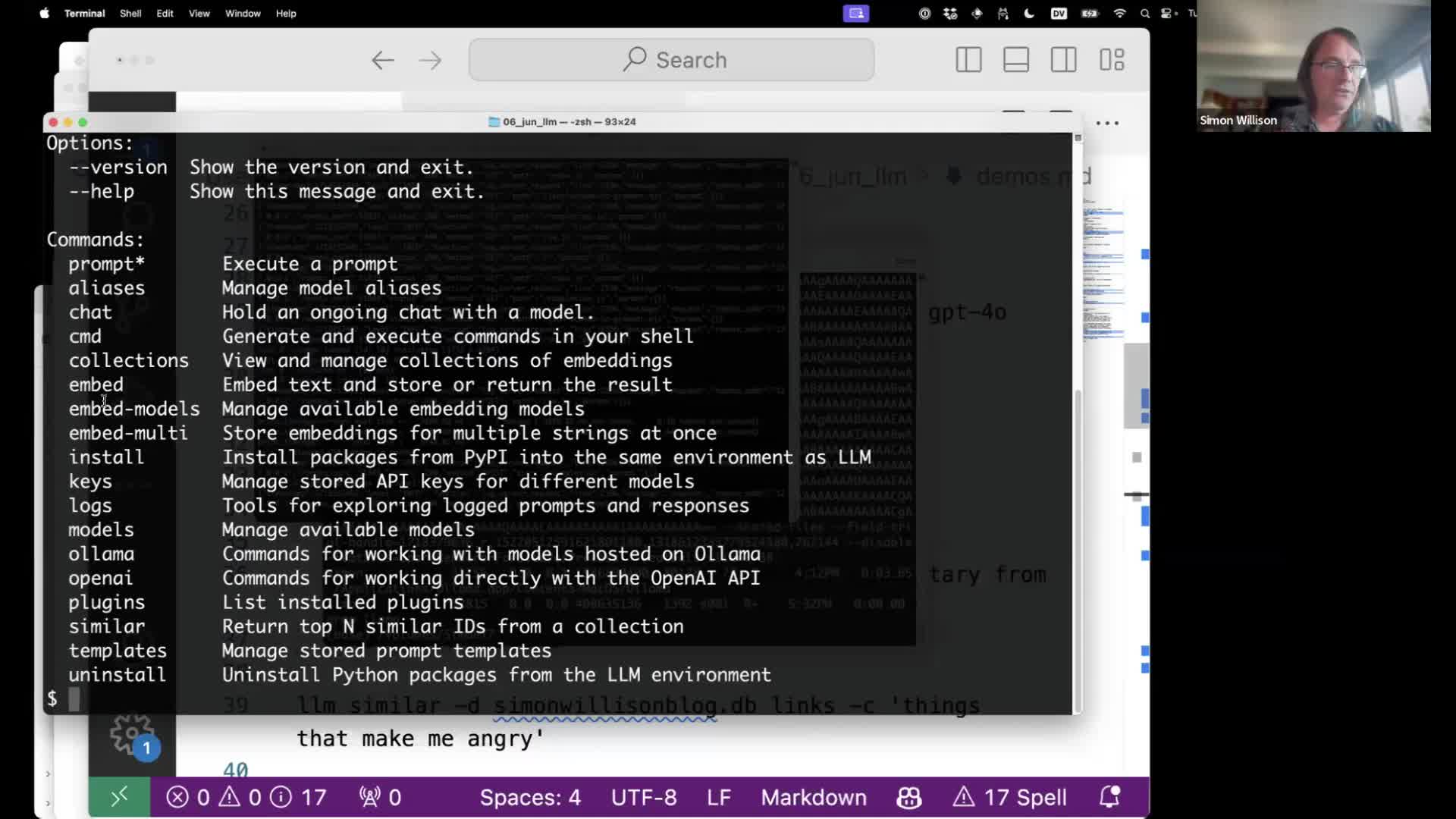
LLM includes support for calculating, storing and searching embeddings through its llm embed-models, llm embed and llm embed-multi commands, documented here.
The llm embed-models command lists currently available embedding models—the OpenAI models plus any that have been added by plugins.
 #
#
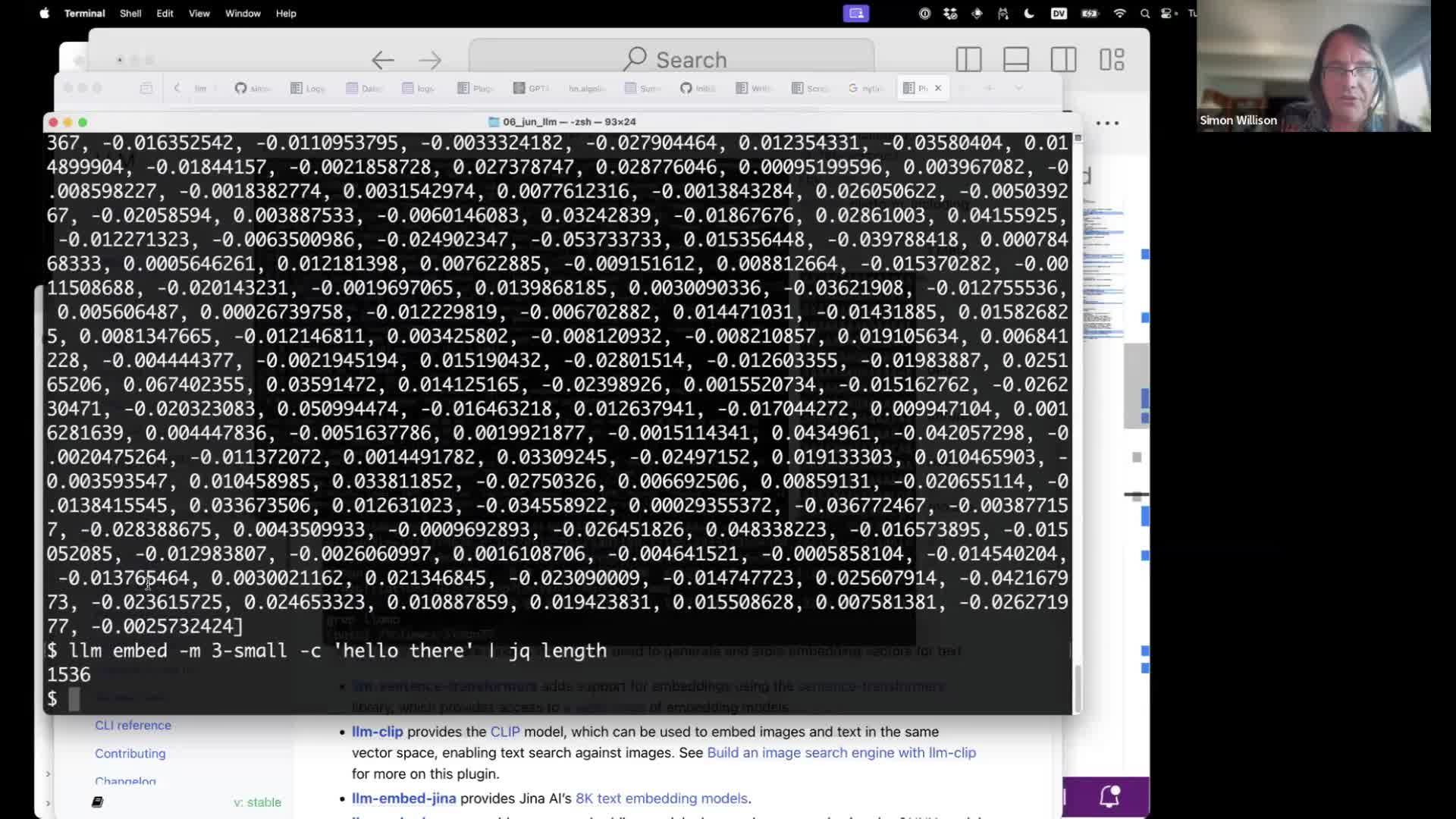
The llm embed command can embed content. This will output a list of floating point numbers for the specified content, using the OpenAI 3-small embedding model.
llm embed -m 3-small -c "hello there"
Add -f hex to get that out as hexadecimal. Neither of these formats are particularly useful on their own!
 #
#
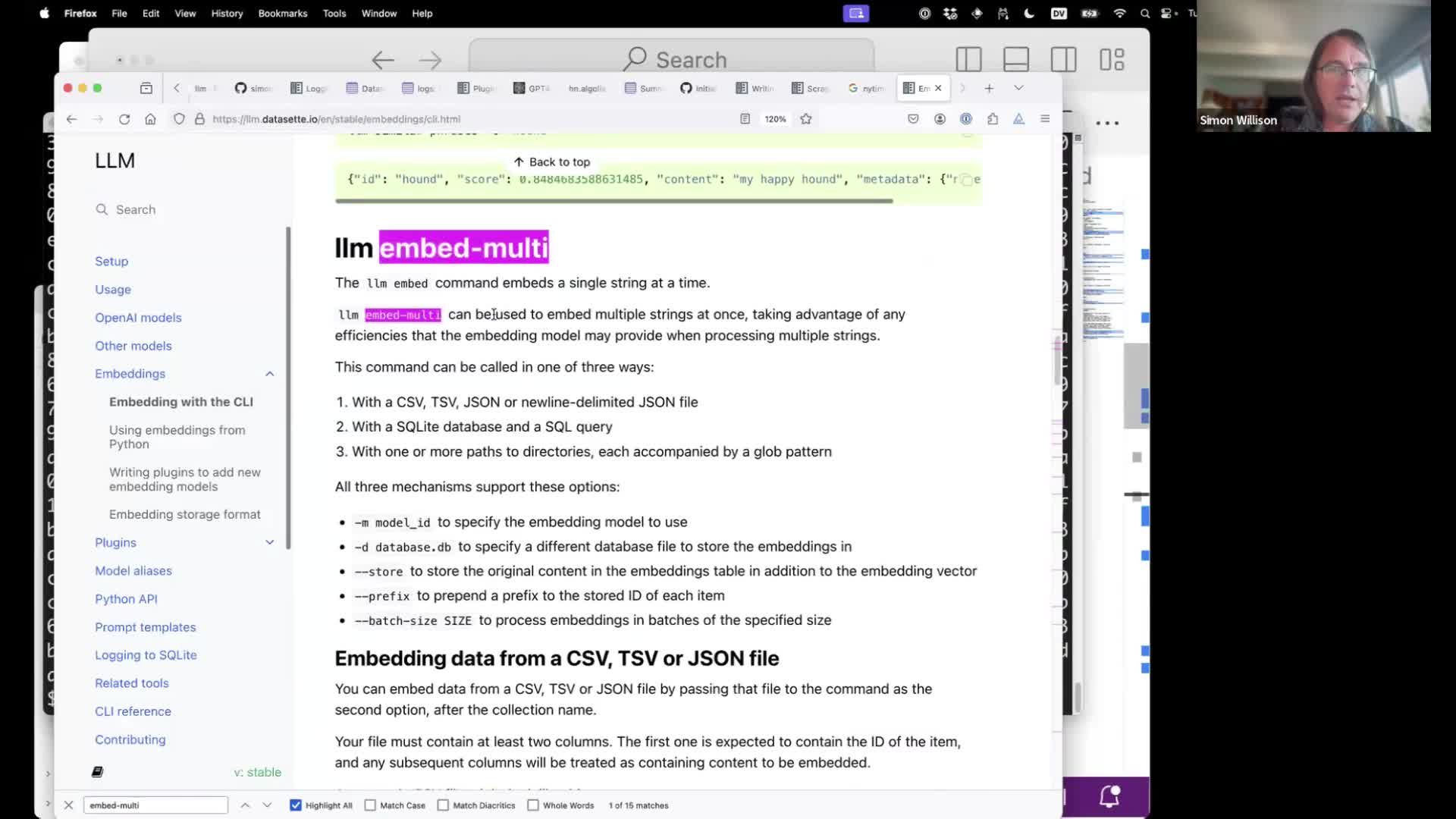
The llm embed-multi command is much more useful. It can run embeddings against content in bulk—from a CSV or JSON file, from a directory full of content or even from a SQLite database. Those embedding vectors will be stored in SQLite ready to be used for search or similarity queries.
 #
#
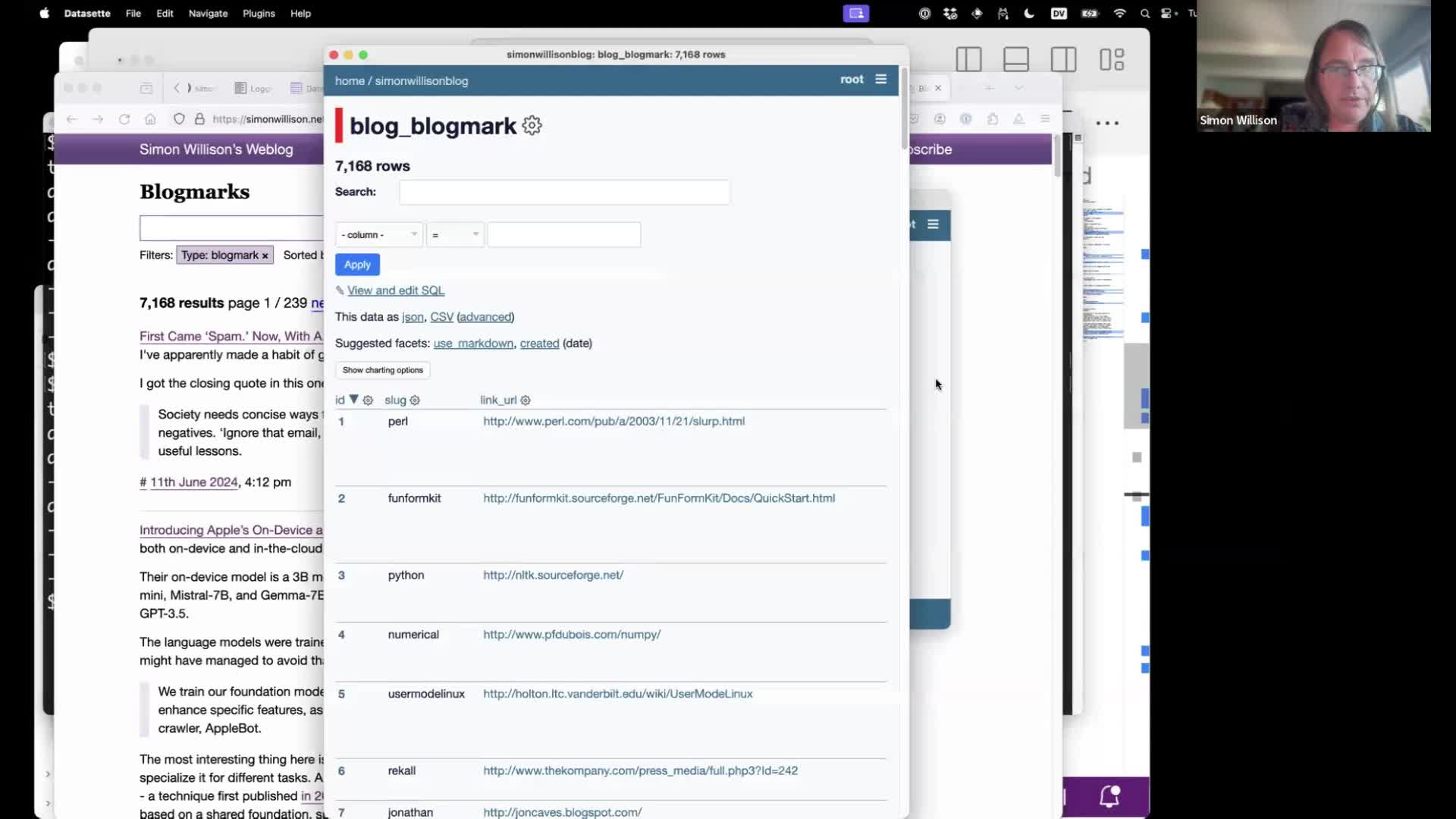
I collect bookmarks (I call them “blogmarks”) on my blog—links with short descriptions. I have over 7,178 of them.
Let’s create embeddings for all of those using LLM.
I used the SQLite database version of my blog available from https://datasette.simonwillison.net/simonwillisonblog.db (a 90MB file).
 #
#
The content lives in the blog_blogmark SQLite table, which I can explore using Datasette (in this case the Datasette Desktop macOS Electron app).
 #
#
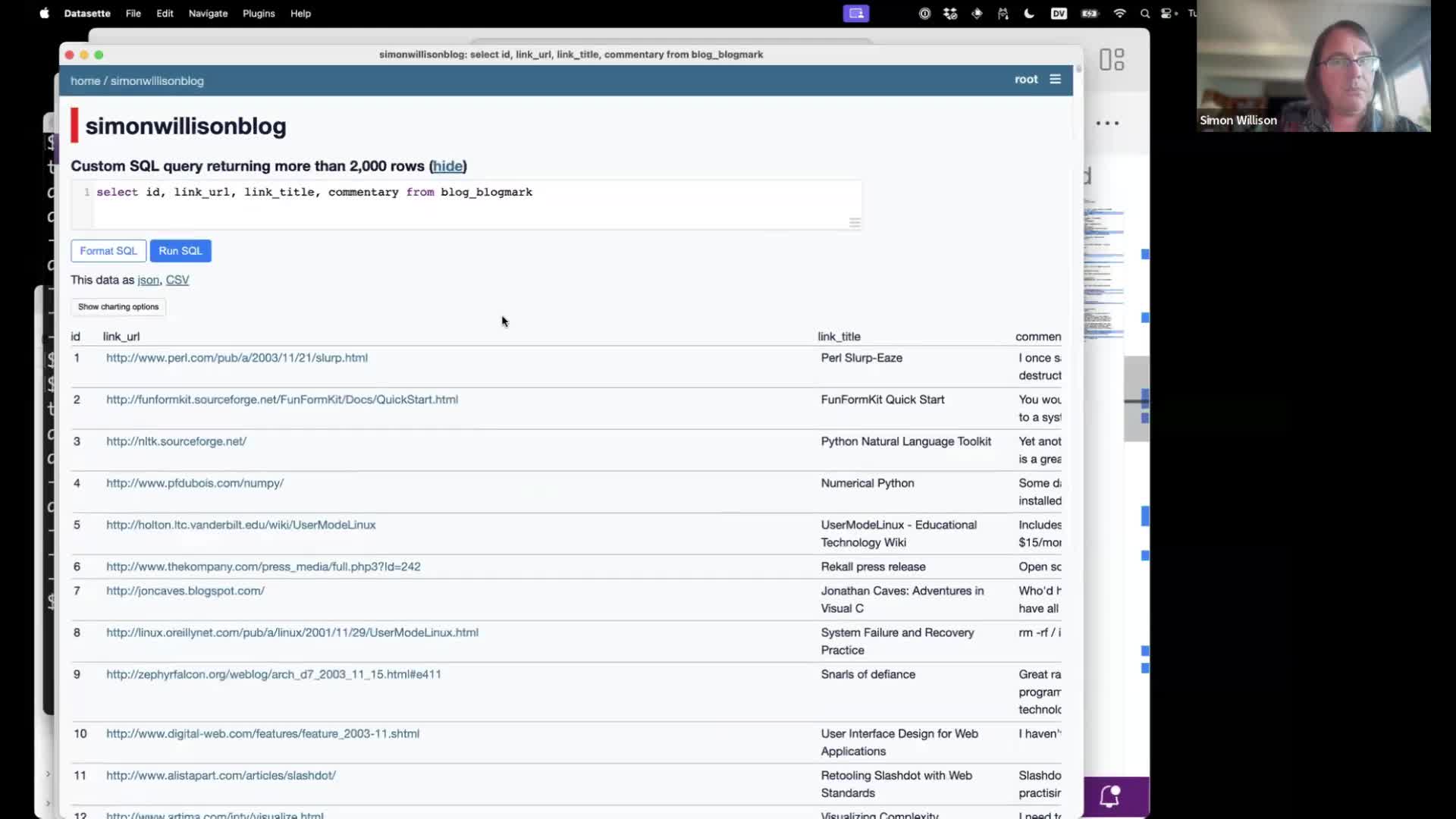
First step is to compose a SQL query returning the data we want to embed. The first column will be treated as a unique identifier to store along with the embedding vector, and any subsequent columns will be used as input to the embedding model.
select id, link_url, link_title, commentary from blog_blogmark
 #
#
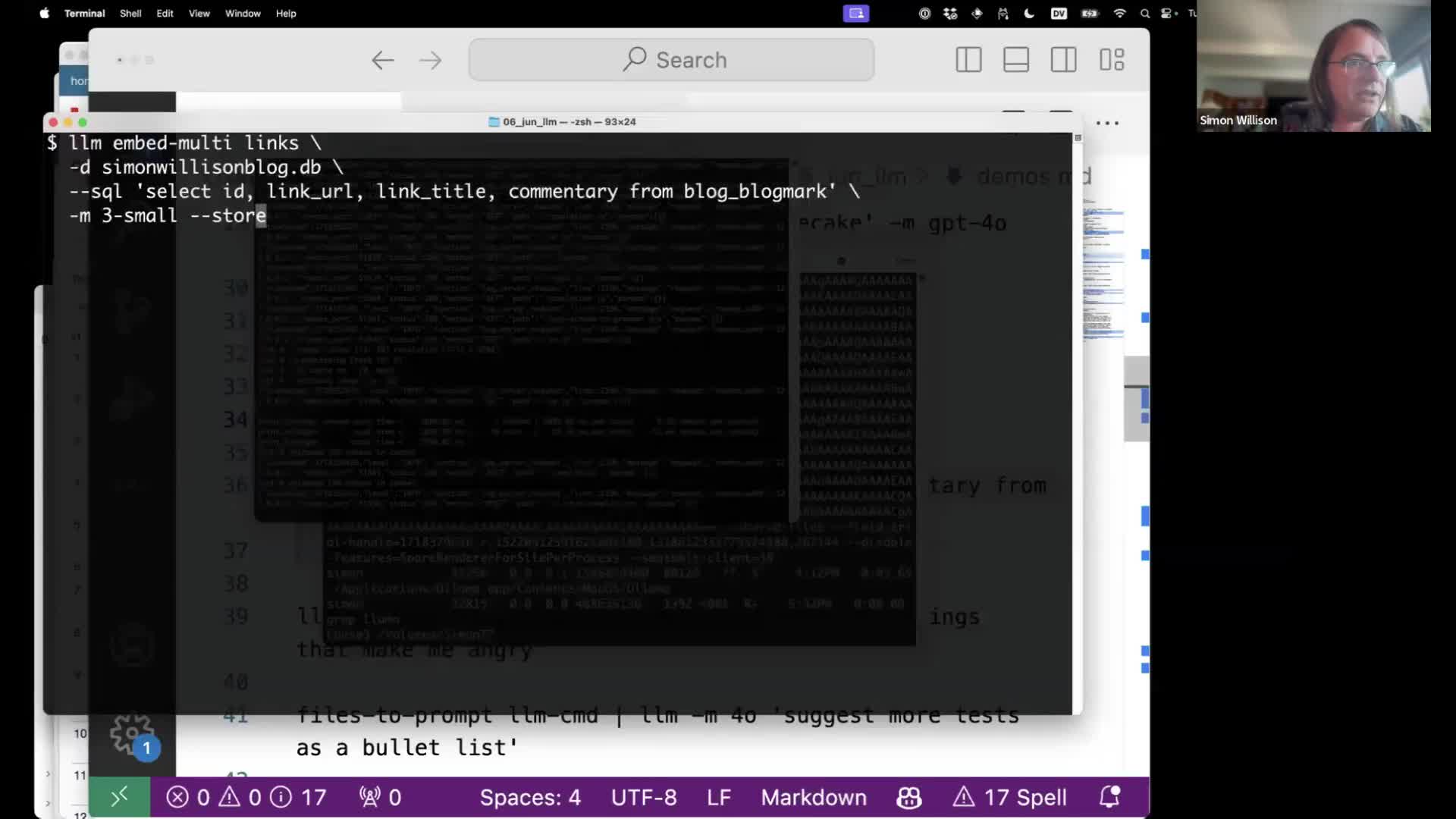
I can run this command to embed all of the content:
llm embed-multi links \
-d simonwillisonblog.db \
--sql 'select id, link_url, link_title, commentary from blog_blogmark' \
-m 3-small --store
This will create an embedding collection called “links”. It will run the SQL query we created before, using the OpenAI 3-small model. The --store link means it will store a copy of the text in the database as well—without that it would just store identifiers and we would need to use those to look up the text later on when running queries.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 #
#
{kind=link}
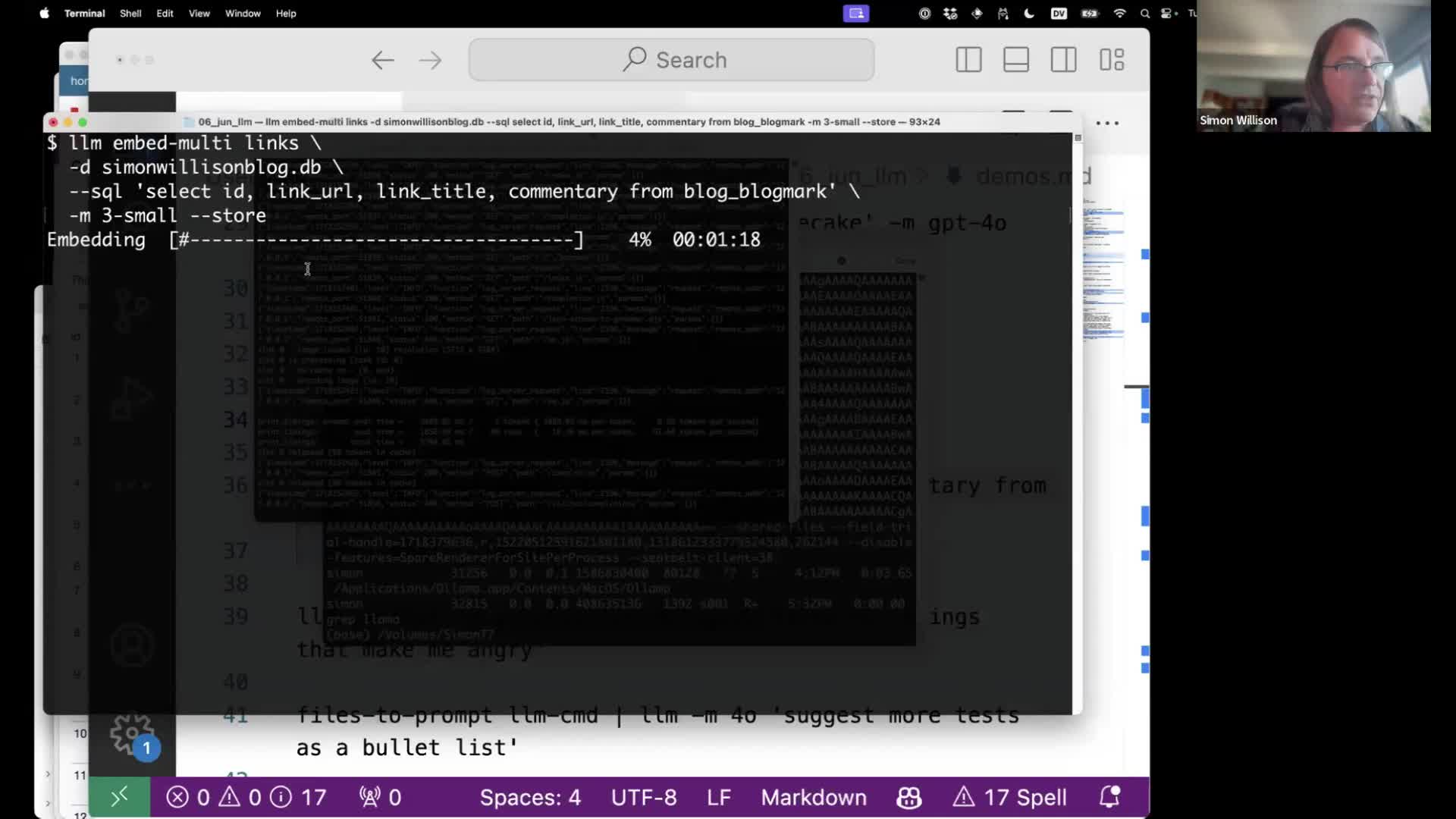
While the command is running we can use Datasette to watch as the embeddings table is filled with data—one row for each of the items we are embedding, each storing a big ugly binary blob of data representing the embedding vector (in this storage format).
 #
#
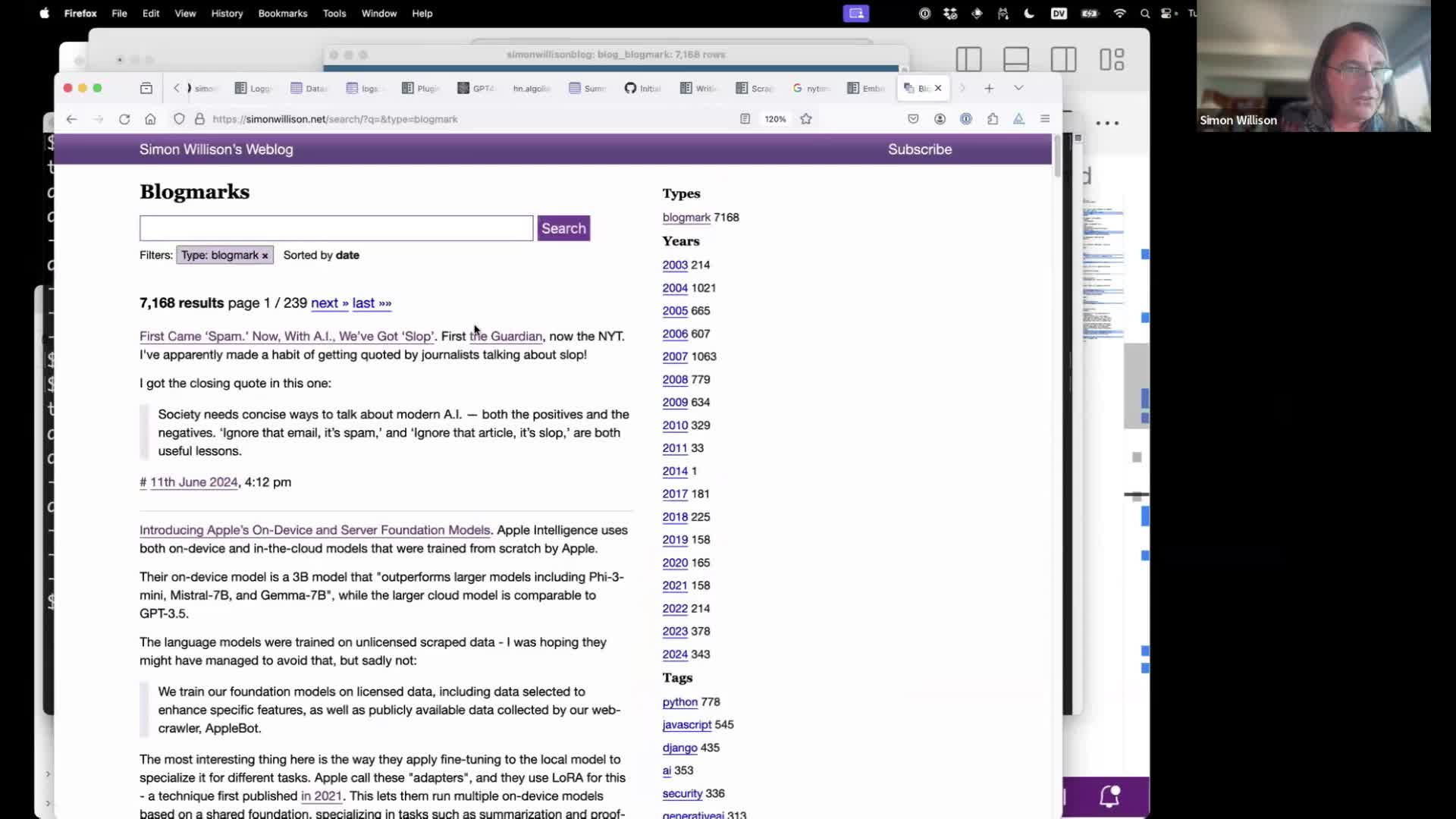
{kind=link}
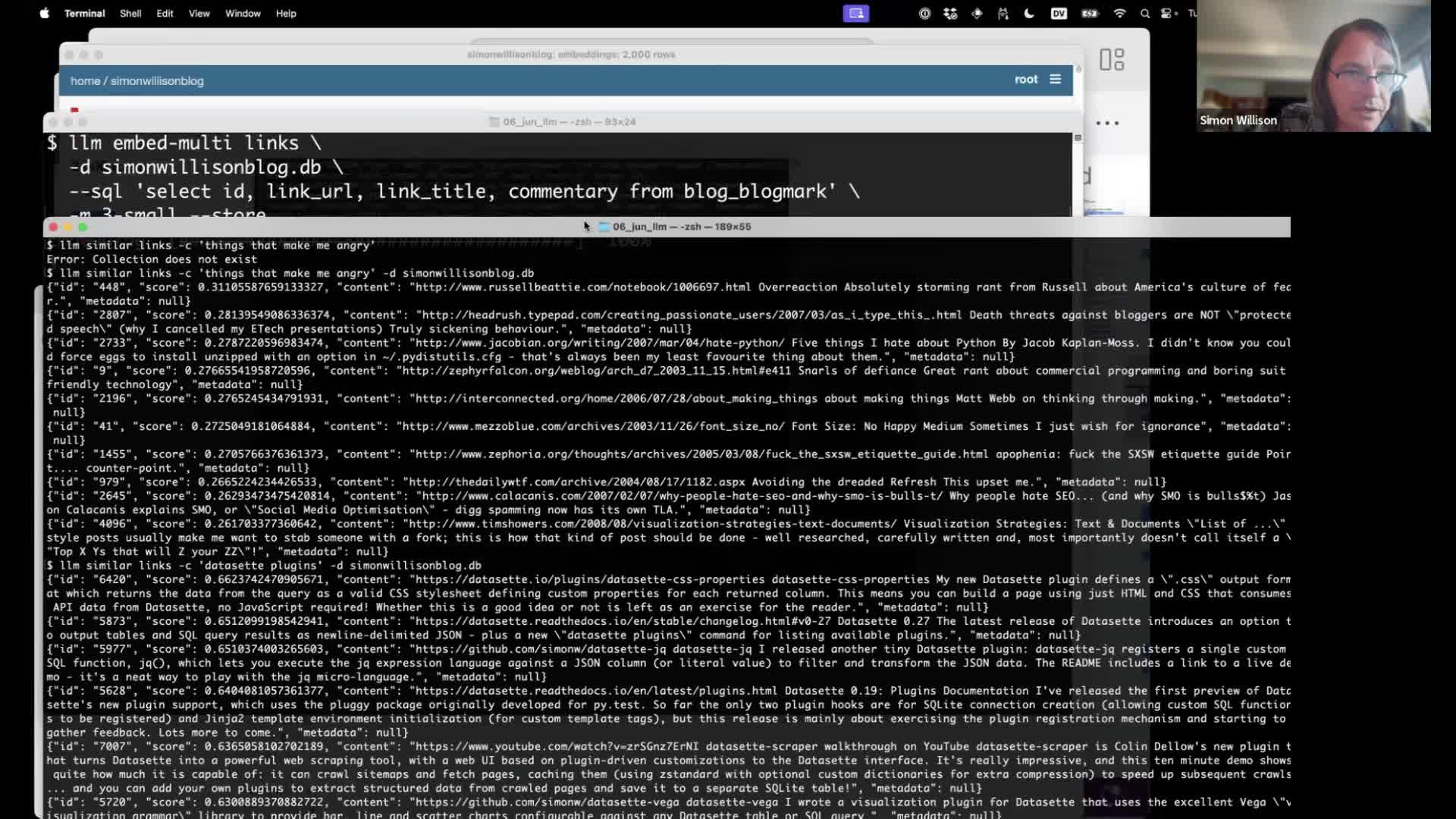
And now we can run searches! This command finds everything in the “links” collection that is most similar to the search term “things that make me angry”:
llm similar links -c 'things that make me angry' -d simonwillisonblog.db
![cat ~/.local/bin/blog-answer.sh #!/bin/bash # Check if a query was provided if [ "$#" -ne 1 ]; then echo "Usage: $0 'Your query'" exit 1 fi llm similar blog-paragraphs -c "query: $1" \ | jq '.content | sub("passage: "; "")' -r \ | llm -m llamafile \ "$1" -s 'You answer questions as a single paragraph' # | llm -m mlc-chat-Llama-2-7b-chat-hf-q4f16_1 \ # /Users/simon/.local/share/virtualenvs/llm-mlc-SwKbovmI/bin/llm -m mlc-chat-Llama-2-7b-chat-hf-q4f16_1](https://static.simonwillison.net/static/2024/llm/frame_004824.jpg) #
#
{kind=link}
We can implement another version of RAG on top of this as well, by finding similar documents to our search term and then piping those results back into LLM to execute a prompt.
I wrote more about this in Embedding paragraphs from my blog with E5-large-v2.
 #
#
{kind=link}
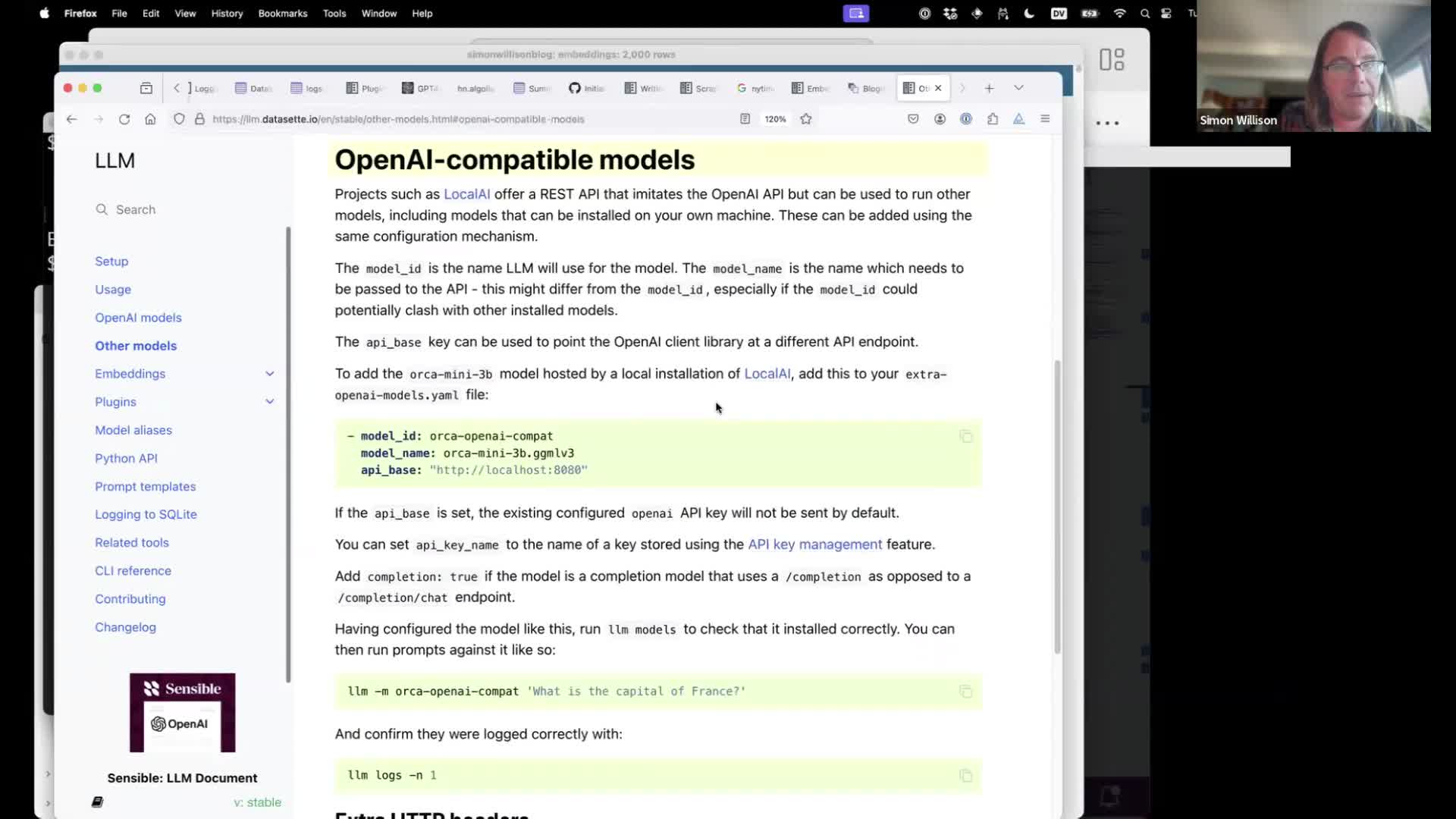
During the Q&A I mentioned that LLM can talk to anything that provides an OpenAI-compatible API endpoint using just configuration, no extra code. That’s described in the documentation here.
 #
#
{kind=link}
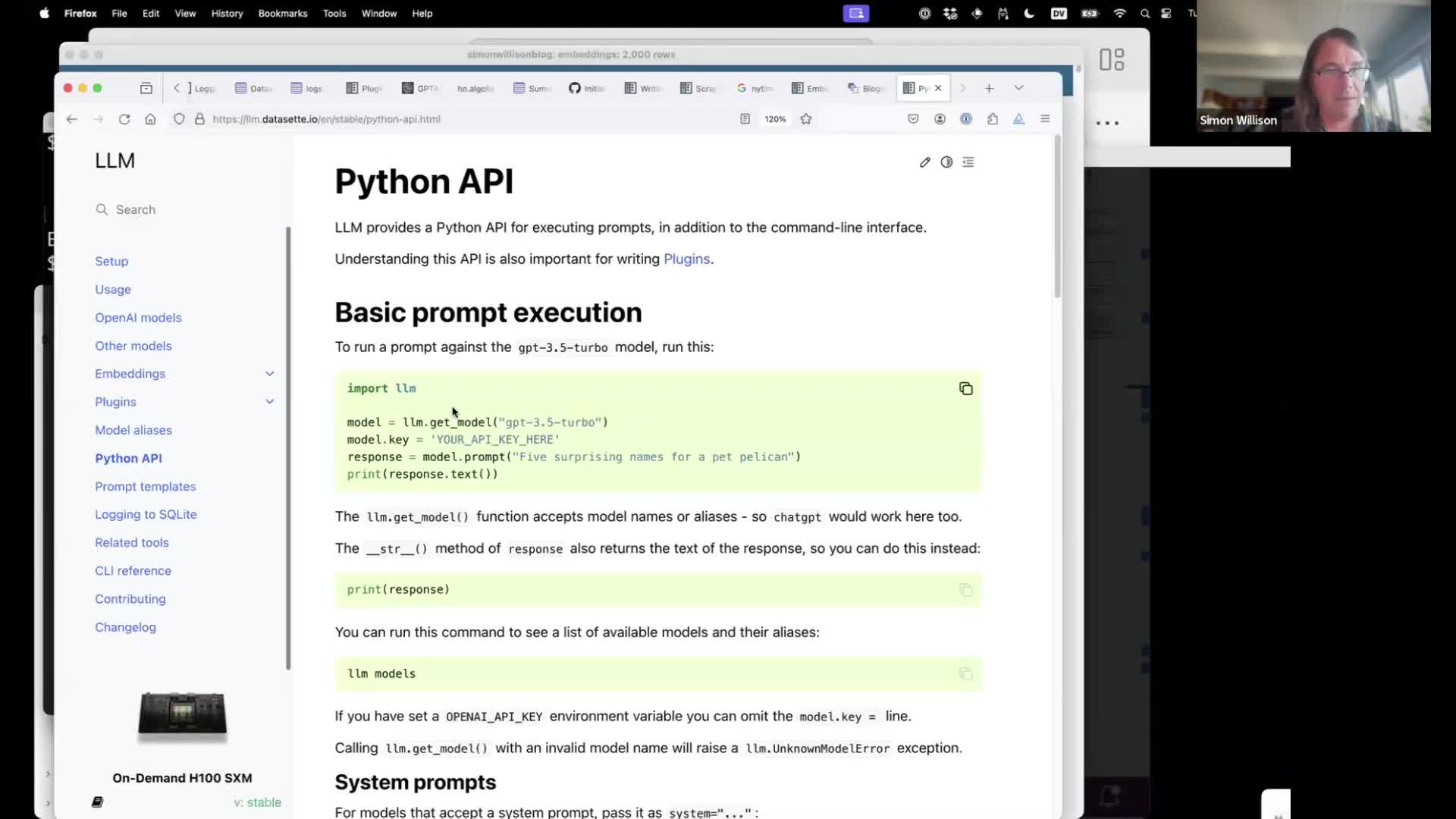
I also showed LLM’s Python API documentation, but warned that this is not yet considered stable as I’m not 100% happy with how this API works yet.
 #
#
{kind=link}
The final question from the audience was about my personal productivity.
I wrote a bit about this a few years ago in Coping strategies for the serial project hoarder—how I use extensive documentation and unit tests to allow me to work on way more projects at once by ensuring I don’t have to remember the details of any of them.
My other trick is that I tend to pick projects that fit my unique combination of previous experiences. I built LLM because I already had experience with LLM APIs, Python CLI tools (using Click) and plugin systems (using Pluggy). As a result I happened to be one of the best positioned people in the world to build a plugin-based CLI tool for working with LLMs!
Colophon
Here’s how I turned the YouTube video of this talk into an annotated presentation:
- I downloaded a
.mp4version of the talk from YouTube using yt-dlp. - I ran that through MacWhisper to create my own transcript for copying extracts from into my write-up—although this time I didn’t end up using any of the transcript text.
- I played the video (at 2x speed) in QuickTime Player and used the
capture.shscript described here to grab screenshots of the individual interesting frames that I wanted to use for my post. - I loaded those screenshots into my annotated presentation tool (which I described in this post) and used that to run OCR against them for alt text and to add commentary to accompany each screenshot.
- I assembled the result into this finished blog entry, adding intro text and the YouTube embed as HTML.
More recent articles
- Claude Opus 4.8: "a modest but tangible improvement" - 28th May 2026
- I think Anthropic and OpenAI have found product-market fit - 27th May 2026
- Notes on Pope Leo XIV's encyclical on AI - 25th May 2026