March 2024
149 posts: 8 entries, 74 links, 12 quotes, 55 beats
March 14, 2024
Guidepup. I’ve been hoping to find something like this for years. Guidepup is “a screen reader driver for test automation”—you can use it to automate both VoiceOver on macOS and NVDA on Windows, and it can both drive the screen reader for automated tests and even produce a video at the end of the test.
Also available: @guidepup/playwright, providing integration with the Playwright browser automation testing framework.
I’d love to see open source JavaScript libraries both use something like this for their testing and publish videos of the tests to demonstrate how they work in these common screen readers.
Lateral Thinking with Withered Technology. Gunpei Yokoi’s product design philosophy at Nintendo (“Withered” is also sometimes translated as “Weathered”). Use “mature technology that can be mass-produced cheaply”, then apply lateral thinking to find radical new ways to use it.
This has echos for me of Dan McKinley’s “Choose Boring Technology”, which argues that in software projects you should default to a proven, stable stack so you can focus your innovation tokens on the problems that are unique to your project.

How Figma’s databases team lived to tell the scale (via) The best kind of scaling war story:
"Figma’s database stack has grown almost 100x since 2020. [...] In 2020, we were running a single Postgres database hosted on AWS’s largest physical instance, and by the end of 2022, we had built out a distributed architecture with caching, read replicas, and a dozen vertically partitioned databases."
I like the concept of "colos", their internal name for sharded groups of related tables arranged such that those tables can be queried using joins.
Also smart: separating the migration into "logical sharding" - where queries all still run against a single database, even though they are logically routed as if the database was already sharded - followed by "physical sharding" where the data is actually copied to and served from the new database servers.
Logical sharding was implemented using PostgreSQL views, which can accept both reads and writes:
CREATE VIEW table_shard1 AS SELECT * FROM table
WHERE hash(shard_key) >= min_shard_range AND hash(shard_key) < max_shard_range)
The final piece of the puzzle was DBProxy, a custom PostgreSQL query proxy written in Go that can parse the query to an AST and use that to decide which shard the query should be sent to. Impressively it also has a scatter-gather mechanism, so select * from table can be sent to all shards at once and the results combined back together again.
March 15, 2024
Advanced Topics in Reminders and To Do Lists. Fred Benenson’s advanced guide to the Apple Reminders ecosystem. I live my life by Reminders—I particularly like that you can set them with Siri, so “Hey Siri, remind me to check the chickens made it to bed at 7pm every evening” sets up a recurring reminder without having to fiddle around in the UI. Fred has some useful tips here I hadn’t seen before.
Google Scholar search: “certainly, here is” -chatgpt -llm (via) Searching Google Scholar for “certainly, here is” turns up a huge number of academic papers that include parts that were evidently written by ChatGPT—sections that start with “Certainly, here is a concise summary of the provided sections:” are a dead giveaway.
March 16, 2024
Phanpy. Phanpy is "a minimalistic opinionated Mastodon web client" by Chee Aun.
I think that description undersells it. It's beautifully crafted and designed and has a ton of innovative ideas - they way it displays threads and replies, the "Catch-up" beta feature, it's all a really thoughtful and fresh perspective on how Mastodon can work.
I love that all Mastodon servers (including my own dedicated instance) offer a CORS-enabled JSON API which directly supports building these kinds of alternative clients.
Building a full-featured client like this one is a huge amount of work, but building a much simpler client that just displays the user's incoming timeline could be a pretty great educational project for people who are looking to deepen their front-end development skills.
npm install everything, and the complete and utter chaos that follows (via) Here’s an experiment which went really badly wrong: a team of mostly-students decided to see if it was possible to install every package from npm (all 2.5 million of them) on the same machine. As part of that experiment they created and published their own npm package that depended on every other package in the registry.
Unfortunately, in response to the leftpad incident a few years ago npm had introduced a policy that a package cannot be removed from the registry if there exists at least one other package that lists it as a dependency. The new “everything” package inadvertently prevented all 2.5m packages—including many that had no other dependencies—from ever being removed!
One year since GPT-4 release. Hope you all enjoyed some time to relax; it’ll have been the slowest 12 months of AI progress for quite some time to come.
— Leopold Aschenbrenner, OpenAI
Weeknotes: the aftermath of NICAR
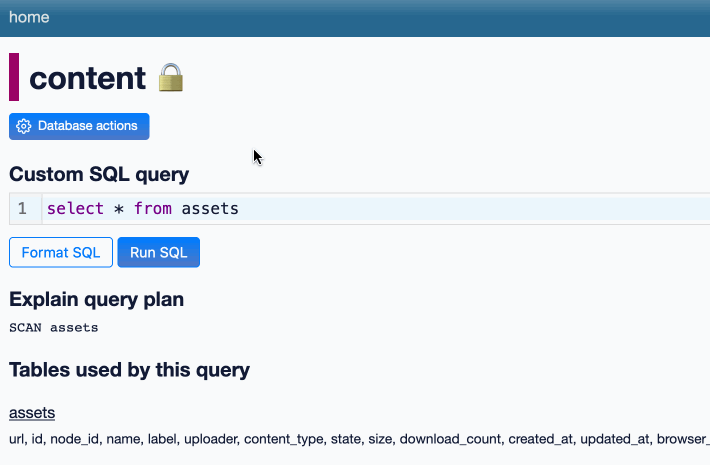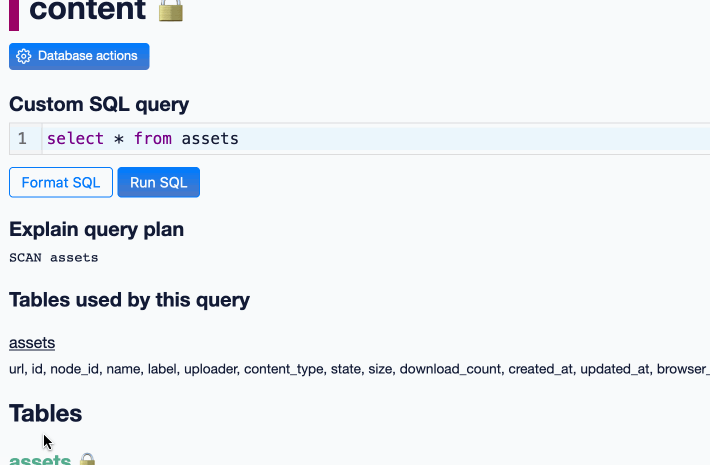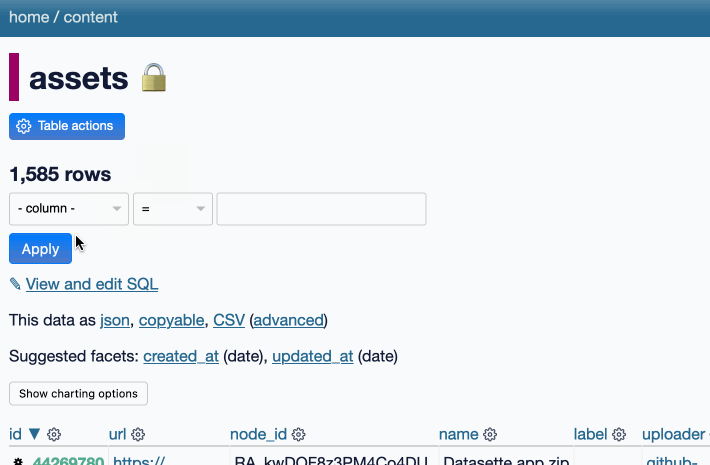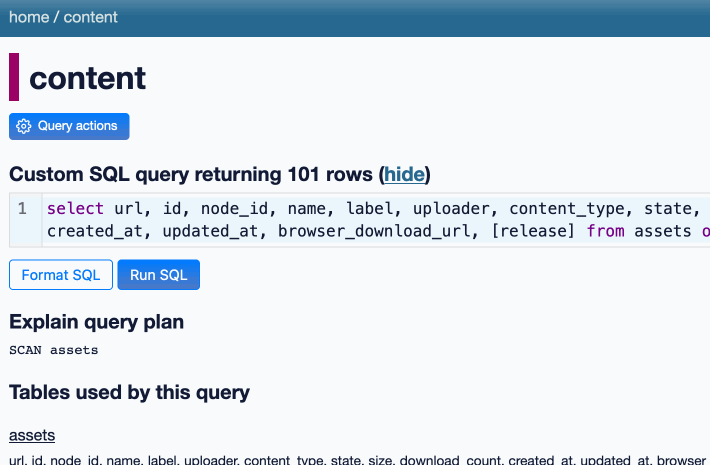
NICAR was fantastic this year. Alex and I ran a successful workshop on Datasette and Datasette Cloud, and I gave a lightning talk demonstrating two new GPT-4 powered Datasette plugins—datasette-enrichments-gpt and datasette-extract. I need to write more about the latter one: it enables populating tables from unstructured content (using a variant of this technique) and it’s really effective. I got it working just in time for the conference.
[... 1,430 words]March 17, 2024
How does SQLite store data? Michal Pitr explores the design of the SQLite on-disk file format, as part of building an educational implementation of SQLite from scratch in Go.
Add ETag header for static responses. I’ve been procrastinating on adding better caching headers for static assets (JavaScript and CSS) served by Datasette for several years, because I’ve been wanting to implement the perfect solution that sets far-future cache headers on every asset and ensures the URLs change when they are updated.
Agustin Bacigalup just submitted the best kind of pull request: he observed that adding ETag support for static assets would side-step the complexity while adding much of the benefit, and implemented it along with tests.
It’s a substantial performance improvement for any Datasette instance with a number of JavaScript plugins... like the ones we are building on Datasette Cloud. I’m just annoyed we didn’t ship something like this sooner!
Grok-1 code and model weights release (via) xAI have released their Grok-1 model under an Apache 2 license (for both weights and code). It's distributed as a 318.24G torrent file and likely requires 320GB of VRAM to run, so needs some very hefty hardware.
The accompanying blog post says "Trained from scratch by xAI using a custom training stack on top of JAX and Rust in October 2023", and describes it as a "314B parameter Mixture-of-Experts model with 25% of the weights active on a given token".
Very little information on what it was actually trained on, all we know is that it was "a large amount of text data, not fine-tuned for any particular task".

March 18, 2024
It's hard to overstate the value of LLM support when coding for fun in an unfamiliar language. [...] This example is totally trivial in hindsight, but might have taken me a couple mins to figure out otherwise. This is a bigger deal than it seems! Papercuts add up fast and prevent flow. (A lot of being a senior engineer is just being proficient enough to avoid papercuts).
900 Sites, 125 million accounts, 1 vulnerability (via) Google’s Firebase development platform encourages building applications (mobile an web) which talk directly to the underlying data store, reading and writing from “collections” with access protected by Firebase Security Rules.
Unsurprisingly, a lot of development teams make mistakes with these.
This post describes how a security research team built a scanner that found over 124 million unprotected records across 900 different applications, including huge amounts of PII: 106 million email addresses, 20 million passwords (many in plaintext) and 27 million instances of “Bank details, invoices, etc”.
Most worrying of all, only 24% of the site owners they contacted shipped a fix for the misconfiguration.
March 19, 2024
The Tokenizer Playground (via) I built a tool like this a while ago, but this one is much better: it provides an interface for experimenting with tokenizers from a wide range of model architectures, including Llama, Claude, Mistral and Grok-1—all running in the browser using Transformers.js.