Monday, 21st October 2024
Dashboard: Tools. I used Django SQL Dashboard to spin up a dashboard that shows all of the URLs to my tools.simonwillison.net site that I've shared on my blog so far. It uses this (Claude assisted) regular expression in a PostgreSQL SQL query:
select distinct on (tool_url)
unnest(regexp_matches(
body,
'(https://tools\.simonwillison\.net/[^<"\s)]+)',
'g'
)) as tool_url,
'https://simonwillison.net/' || left(type, 1) || '/' || id as blog_url,
title,
date(created) as created
from contentI've been really enjoying having a static hosting platform (it's GitHub Pages serving my simonw/tools repo) that I can use to quickly deploy little HTML+JavaScript interactive tools and demos.
Everything I built with Claude Artifacts this week
I’m a huge fan of Claude’s Artifacts feature, which lets you prompt Claude to create an interactive Single Page App (using HTML, CSS and JavaScript) and then view the result directly in the Claude interface, iterating on it further with the bot and then, if you like, copying out the resulting code.
[... 2,273 words]I've often been building single-use apps with Claude Artifacts when I'm helping my children learn. For example here's one on visualizing fractions. [...] What's more surprising is that it is far easier to create an app on-demand than searching for an app in the app store that will do what I'm looking for. Searching for kids' learning apps is typically a nails-on-chalkboard painful experience because 95% of them are addictive garbage. And even if I find something usable, it can't match the fact that I can tell Claude what I want.
sudoku-in-python-packaging (via) Absurdly clever hack by konsti: solve a Sudoku puzzle entirely using the Python package resolver!
First convert the puzzle into a requirements.in file representing the current state of the board:
git clone https://github.com/konstin/sudoku-in-python-packaging
cd sudoku-in-python-packaging
echo '5,3,_,_,7,_,_,_,_
6,_,_,1,9,5,_,_,_
_,9,8,_,_,_,_,6,_
8,_,_,_,6,_,_,_,3
4,_,_,8,_,3,_,_,1
7,_,_,_,2,_,_,_,6
_,6,_,_,_,_,2,8,_
_,_,_,4,1,9,_,_,5
_,_,_,_,8,_,_,7,9' > sudoku.csv
python csv_to_requirements.py sudoku.csv requirements.in
That requirements.in file now contains lines like this for each of the filled-in cells:
sudoku_0_0 == 5
sudoku_1_0 == 3
sudoku_4_0 == 7
Then run uv pip compile to convert that into a fully fleshed out requirements.txt file that includes all of the resolved dependencies, based on the wheel files in the packages/ folder:
uv pip compile \
--find-links packages/ \
--no-annotate \
--no-header \
requirements.in > requirements.txt
The contents of requirements.txt is now the fully solved board:
sudoku-0-0==5
sudoku-0-1==6
sudoku-0-2==1
sudoku-0-3==8
...
The trick is the 729 wheel files in packages/ - each with a name like sudoku_3_4-8-py3-none-any.whl. I decompressed that wheel and it included a sudoku_3_4-8.dist-info/METADATA file which started like this:
Name: sudoku_3_4
Version: 8
Metadata-Version: 2.2
Requires-Dist: sudoku_3_0 != 8
Requires-Dist: sudoku_3_1 != 8
Requires-Dist: sudoku_3_2 != 8
Requires-Dist: sudoku_3_3 != 8
...
With a !=8 line for every other cell on the board that cannot contain the number 8 due to the rules of Sudoku (if 8 is in the 3, 4 spot). Visualized:
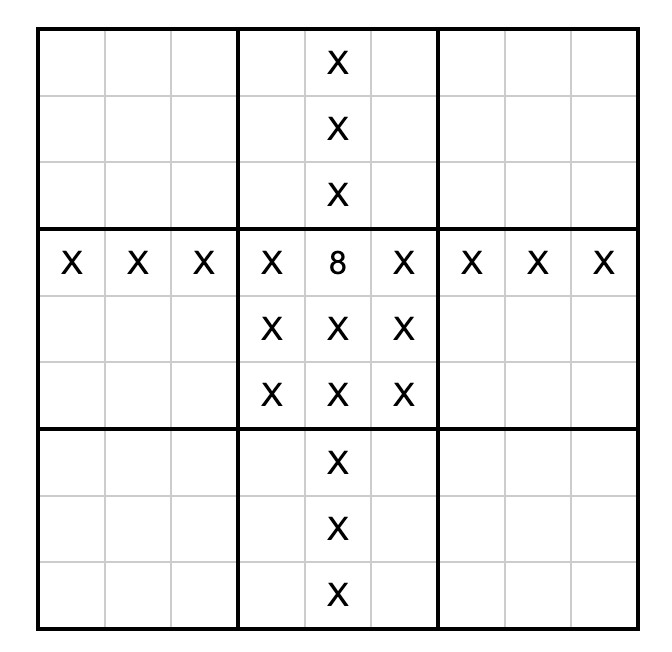
So the trick here is that the Python dependency resolver (now lightning fast thanks to uv) reads those dependencies and rules out every package version that represents a number in an invalid position. The resulting version numbers represent the cell numbers for the solution.
How much faster? I tried the same thing with the pip-tools pip-compile command:
time pip-compile \
--find-links packages/ \
--no-annotate \
--no-header \
requirements.in > requirements.txt
That took 17.72s. On the same machine the time pip uv compile... command took 0.24s.
Update: Here's an earlier implementation of the same idea by Artjoms Iškovs in 2022.