September 2024
131 posts: 10 entries, 49 links, 23 quotes, 49 beats
Sept. 1, 2024
uvtrick (via) This "fun party trick" by Vincent D. Warmerdam is absolutely brilliant and a little horrifying. The following code:
from uvtrick import Env def uses_rich(): from rich import print print("hi :vampire:") Env("rich", python="3.12").run(uses_rich)
Executes that uses_rich() function in a fresh virtual environment managed by uv, running the specified Python version (3.12) and ensuring the rich package is available - even if it's not installed in the current environment.
It's taking advantage of the fact that uv is so fast that the overhead of getting this to work is low enough for it to be worth at least playing with the idea.
The real magic is in how uvtrick works. It's only 127 lines of code with some truly devious trickery going on.
That Env.run() method:
- Creates a temporary directory
- Pickles the
argsandkwargsand saves them topickled_inputs.pickle - Uses
inspect.getsource()to retrieve the source code of the function passed torun() - Writes that to a
pytemp.pyfile, along with a generatedif __name__ == "__main__":block that calls the function with the pickled inputs and saves its output to another pickle file calledtmp.pickle
Having created the temporary Python file it executes the program using a command something like this:
uv run --with rich --python 3.12 --quiet pytemp.pyIt reads the output from tmp.pickle and returns it to the caller!
Sept. 2, 2024
Anatomy of a Textual User Interface. Will McGugan used Textual and my LLM Python library to build a delightful TUI for talking to a simulation of Mother, the AI from the Aliens movies:
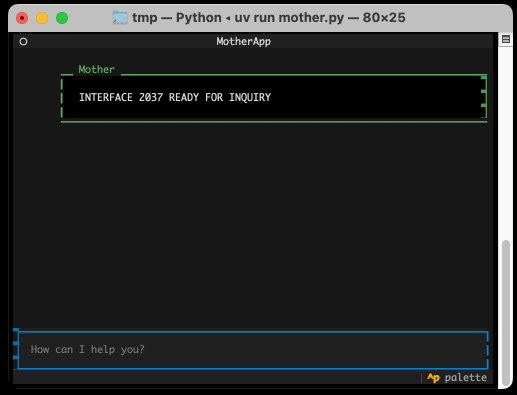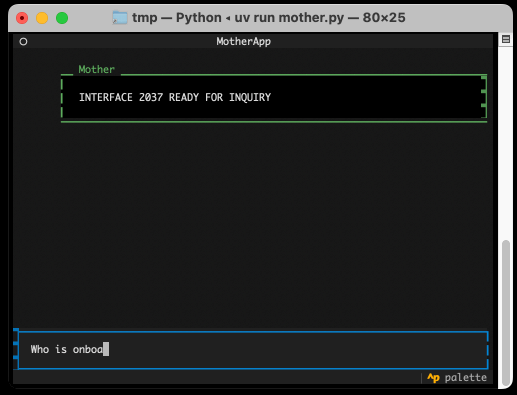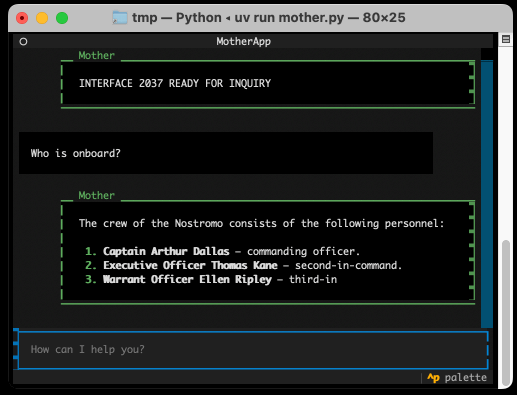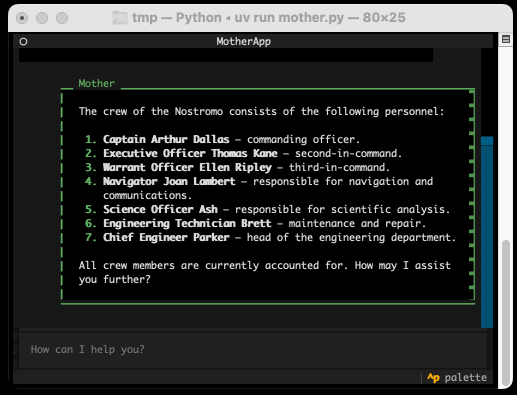
The entire implementation is just 77 lines of code. It includes PEP 723 inline dependency information:
# /// script # requires-python = ">=3.12" # dependencies = [ # "llm", # "textual", # ] # ///
Which means you can run it in a dedicated environment with the correct dependencies installed using uv run like this:
wget 'https://gist.githubusercontent.com/willmcgugan/648a537c9d47dafa59cb8ece281d8c2c/raw/7aa575c389b31eb041ae7a909f2349a96ffe2a48/mother.py'
export OPENAI_API_KEY='sk-...'
uv run mother.pyI found the send_prompt() method particularly interesting. Textual uses asyncio for its event loop, but LLM currently only supports synchronous execution and can block for several seconds while retrieving a prompt.
Will used the Textual @work(thread=True) decorator, documented here, to run that operation in a thread:
@work(thread=True) def send_prompt(self, prompt: str, response: Response) -> None: response_content = "" llm_response = self.model.prompt(prompt, system=SYSTEM) for chunk in llm_response: response_content += chunk self.call_from_thread(response.update, response_content)
Looping through the response like that and calling self.call_from_thread(response.update, response_content) with an accumulated string is all it takes to implement streaming responses in the Textual UI, and that Response object sublasses textual.widgets.Markdown so any Markdown is rendered using Rich.
In Leak, Facebook Partner Brags About Listening to Your Phone’s Microphone to Serve Ads for Stuff You Mention. (I've repurposed some of my comments on Lobsters into this commentary on this article. See also I still don’t think companies serve you ads based on spying through your microphone.)
Which is more likely?
- All of the conspiracy theories are real! The industry managed to keep the evidence from us for decades, but finally a marketing agency of a local newspaper chain has blown the lid off the whole thing, in a bunch of blog posts and PDFs and on a podcast.
- Everyone believed that their phone was listening to them even when it wasn’t. The marketing agency of a local newspaper chain were the first group to be caught taking advantage of that widespread paranoia and use it to try and dupe people into spending money with them, despite the tech not actually working like that.
My money continues to be on number 2.
Here’s their pitch deck. My “this is a scam” sense is vibrating like crazy reading it: CMG Pitch Deck on Voice-Data Advertising 'Active Listening'.
It does not read to me like the deck of a company that has actually shipped their own app that tracks audio and uses it for even the most basic version of ad targeting.
They give the game away on the last two slides:
Prep work:
- Create buyer personas by uploading past consumer data into the platform
- Identify top performing keywords relative to your products and services by analyzing keyword data and past ad campaigns
- Ensure tracking is set up via a tracking pixel placed on your site or landing page
Now that preparation is done:
- Active listening begins in your target geo and buyer behavior is detected across 470+ data sources […]
Our technology analyzes over 1.9 trillion behaviors daily and collects opt-in customer behavior data from hundreds of popular websites that offer top display, video platforms, social applications, and mobile marketplaces that allow laser-focused media buying.
Sources include: Google, LinkedIn, Facebook, Amazon and many more
That’s not describing anything ground-breaking or different. That’s how every targeting ad platform works: you upload a bunch of “past consumer data”, identify top keywords and setup a tracking pixel.
I think active listening is the term that the team came up with for “something that sounds fancy but really just means the way ad targeting platforms work already”. Then they got over-excited about the new metaphor and added that first couple of slides that talk about “voice data”, without really understanding how the tech works or what kind of a shitstorm that could kick off when people who DID understand technology started paying attention to their marketing.
TechDirt's story Cox Media Group Brags It Spies On Users With Device Microphones To Sell Targeted Ads, But It’s Not Clear They Actually Can included a quote with a clarification from Cox Media Group:
CMG businesses do not listen to any conversations or have access to anything beyond a third-party aggregated, anonymized and fully encrypted data set that can be used for ad placement. We regret any confusion and we are committed to ensuring our marketing is clear and transparent.
Why I don't buy the argument that it's OK for people to believe this
I've seen variants of this argument before: phones do creepy things to target ads, but it’s not exactly “listen through your microphone” - but there’s no harm in people believing that if it helps them understand that there’s creepy stuff going on generally.
I don’t buy that. Privacy is important. People who are sufficiently engaged need to be able to understand exactly what’s going on, so they can e.g. campaign for legislators to reign in the most egregious abuses.
I think it’s harmful letting people continue to believe things about privacy that are not true, when we should instead be helping them understand the things that are true.
This discussion thread is full of technically minded, engaged people who still believe an inaccurate version of what their devices are doing. Those are the people that need to have an accurate understanding, because those are the people that can help explain it to others and can hopefully drive meaningful change.
This is such a damaging conspiracy theory.
- It’s causing some people to stop trusting their most important piece of personal technology: their phone.
- We risk people ignoring REAL threats because they’ve already decided to tolerate made up ones.
- If people believe this and see society doing nothing about it, that’s horrible. That leads to a cynical “nothing can be fixed, I guess we will just let bad people get away with it” attitude. People need to believe that humanity can prevent this kind of abuse from happening.
The fact that nobody has successfully produced an experiment showing that this is happening is one of the main reasons I don’t believe it to be happening.
It’s like James Randi’s One Million Dollar Paranormal Challenge - the very fact that nobody has been able to demonstrate it is enough for me not to believe in it.
Why I Still Use Python Virtual Environments in Docker (via) Hynek Schlawack argues for using virtual environments even when running Python applications in a Docker container. This argument was most convincing to me:
I'm responsible for dozens of services, so I appreciate the consistency of knowing that everything I'm deploying is in
/app, and if it's a Python application, I know it's a virtual environment, and if I run/app/bin/python, I get the virtual environment's Python with my application ready to be imported and run.
Also:
It’s good to use the same tools and primitives in development and in production.
Also worth a look: Hynek's guide to Production-ready Docker Containers with uv, an actively maintained guide that aims to reflect ongoing changes made to uv itself.
Sept. 3, 2024
Python Developers Survey 2023 Results (via) The seventh annual Python survey is out. Here are the things that caught my eye or that I found surprising:
25% of survey respondents had been programming in Python for less than a year, and 33% had less than a year of professional experience.
37% of Python developers reported contributing to open-source projects last year - a new question for the survey. This is delightfully high!
6% of users are still using Python 2. The survey notes:
Almost half of Python 2 holdouts are under 21 years old and a third are students. Perhaps courses are still using Python 2?
In web frameworks, Flask and Django neck and neck at 33% each, but FastAPI is a close third at 29%! Starlette is at 6%, but that's an under-count because it's the basis for FastAPI.
The most popular library in "other framework and libraries" was BeautifulSoup with 31%, then Pillow 28%, then OpenCV-Python at 22% (wow!) and Pydantic at 22%. Tkinter had 17%. These numbers are all a surprise to me.
pytest scores 52% for unit testing, unittest from the standard library just 25%. I'm glad to see pytest so widely used, it's my favourite testing tool across any programming language.
The top cloud providers are AWS, then Google Cloud Platform, then Azure... but PythonAnywhere (11%) took fourth place just ahead of DigitalOcean (10%). And Alibaba Cloud is a new entrant in sixth place (after Heroku) with 4%. Heroku's ending of its free plan dropped them from 14% in 2021 to 7% now.
Linux and Windows equal at 55%, macOS is at 29%. This was one of many multiple-choice questions that could add up to more than 100%.
In databases, SQLite usage was trending down - 38% in 2021 to 34% for 2023, but still in second place behind PostgreSQL, stable at 43%.
The survey incorporates quotes from different Python experts responding to the numbers, it's worth reading through the whole thing.
history | tail -n 2000 | llm -s "Write aliases for my zshrc based on my terminal history. Only do this for most common features. Don't use any specific files or directories."
— anjor
Sept. 4, 2024

Qwen2-VL: To See the World More Clearly. Qwen is Alibaba Cloud's organization training LLMs. Their latest model is Qwen2-VL - a vision LLM - and it's getting some really positive buzz. Here's a r/LocalLLaMA thread about the model.
The original Qwen models were licensed under their custom Tongyi Qianwen license, but starting with Qwen2 on June 7th 2024 they switched to Apache 2.0, at least for their smaller models:
While Qwen2-72B as well as its instruction-tuned models still uses the original Qianwen License, all other models, including Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, and Qwen2-57B-A14B, turn to adopt Apache 2.0
Here's where things get odd: shortly before I first published this post the Qwen GitHub organization, and their GitHub pages hosted blog, both disappeared and returned 404s pages. I asked on Twitter but nobody seems to know what's happened to them.
Update: this was accidental and was resolved on 5th September.
The Qwen Hugging Face page is still up - it's just the GitHub organization that has mysteriously vanished.
Inspired by Dylan Freedman I tried the model using GanymedeNil/Qwen2-VL-7B on Hugging Face Spaces, and found that it was exceptionally good at extracting text from unruly handwriting:
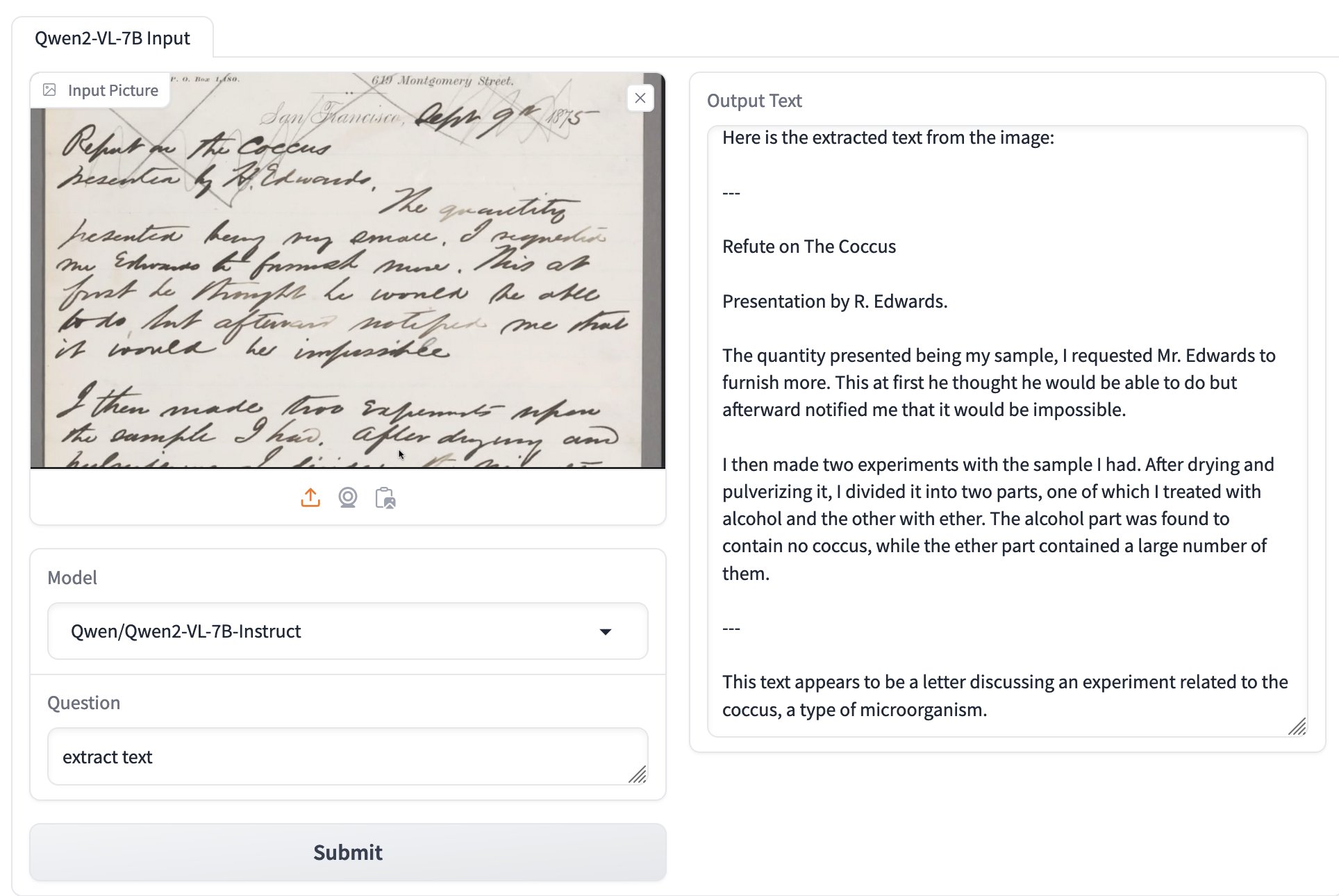
The model apparently runs great on NVIDIA GPUs, and very slowly using the MPS PyTorch backend on Apple Silicon. Qwen previously released MLX builds of their non-vision Qwen2 models, so hopefully there will be an Apple Silicon optimized MLX model for Qwen2-VL soon as well.
Sept. 5, 2024
OAuth from First Principles (via) Rare example of an OAuth explainer that breaks down why each of the steps are designed the way they are, by showing an illustrative example of how an attack against OAuth could work in absence of each measure.
Ever wondered why OAuth returns you an authorization code which you then need to exchange for an access token, rather than returning the access token directly? It's for an added layer of protection against eavesdropping attacks:
If Endframe eavesdrops the authorization code in real-time, they can exchange it for an access token very quickly, before Big Head's browser does. [...] Currently, anyone with the authorization code can exchange it for an access token. We need to ensure that only the person who initiated the request can do the exchange.
Sept. 6, 2024
Calling LLMs from client-side JavaScript, converting PDFs to HTML + weeknotes
I’ve been having a bunch of fun taking advantage of CORS-enabled LLM APIs to build client-side JavaScript applications that access LLMs directly. I also span up a new Datasette plugin for advanced permission management.
[... 2,050 words]New improved commit messages for scrape-hacker-news-by-domain. My simonw/scrape-hacker-news-by-domain repo has a very specific purpose. Once an hour it scrapes the Hacker News /from?site=simonwillison.net page (and the equivalent for datasette.io) using my shot-scraper tool and stashes the parsed links, scores and comment counts in JSON files in that repo.
It does this mainly so I can subscribe to GitHub's Atom feed of the commit log - visit simonw/scrape-hacker-news-by-domain/commits/main and add .atom to the URL to get that.
NetNewsWire will inform me within about an hour if any of my content has made it to Hacker News, and the repo will track the score and comment count for me over time. I wrote more about how this works in Scraping web pages from the command line with shot-scraper back in March 2022.
Prior to the latest improvement, the commit messages themselves were pretty uninformative. The message had the date, and to actually see which Hacker News post it was referring to, I had to click through to the commit and look at the diff.
I built my csv-diff tool a while back to help address this problem: it can produce a slightly more human-readable version of a diff between two CSV or JSON files, ideally suited for including in a commit message attached to a git scraping repo like this one.
I got that working, but there was still room for improvement. I recently learned that any Hacker News thread has an undocumented URL at /latest?id=x which displays the most recently added comments at the top.
I wanted that in my commit messages, so I could quickly click a link to see the most recent comments on a thread.
So... I added one more feature to csv-diff: a new --extra option lets you specify a Python format string to be used to add extra fields to the displayed difference.
My GitHub Actions workflow now runs this command:
csv-diff simonwillison-net.json simonwillison-net-new.json \
--key id --format json \
--extra latest 'https://news.ycombinator.com/latest?id={id}' \
>> /tmp/commit.txt
This generates the diff between the two versions, using the id property in the JSON to tie records together. It adds a latest field linking to that URL.
The commits now look like this:

Datasette 1.0a16. This latest release focuses mainly on performance, as discussed here in Optimizing Datasette a couple of weeks ago.
It also includes some minor CSS changes that could affect plugins, and hence need to be included before the final 1.0 release. Those are outlined in detail in issues #2415 and #2420.
Docker images using uv’s python (via) Michael Kennedy interviewed uv/Ruff lead Charlie Marsh on his Talk Python podcast, and was inspired to try uv with Talk Python's own infrastructure, a single 8 CPU server running 17 Docker containers (status page here).
The key line they're now using is this:
RUN uv venv --python 3.12.5 /venv
Which downloads the uv selected standalone Python binary for Python 3.12.5 and creates a virtual environment for it at /venv all in one go.