Wednesday, 23rd April 2025
An underestimated challenge in making productive use of LLMs is that it can feel like cheating.
One trick I've found that helps is to make sure that I am putting in way more text than the LLM is spitting out .
This goes for code: I'll pipe in a previous project for it to modify, or ask it to combine two, or paste in my research notes.
It also goes for writing. I hardly ever publish material that was written by an LLM, but I feel least icky about content where I had an extensive voice conversation with the model and then asked it to turn that into notes.
I have a hunch that overcoming the feeling of guilt associated with using LLMs is one of the most important skills required to make effective use of them!
My gold standard for LLM usage remains this: would I be proud to stake my own credibility on the quality of the end result?
Related, this excellent advice from Laurie Voss:
Is what you're doing taking a large amount of text and asking the LLM to convert it into a smaller amount of text? Then it's probably going to be great at it. If you're asking it to convert into a roughly equal amount of text it will be so-so. If you're asking it to create more text than you gave it, forget about it.
Despite being rusty with coding (I don't code every day these days): since starting to use Windsurf / Cursor with the recent increasingly capable models: I am SO back to being as fast in coding as when I was coding every day "in the zone" [...]
When you are driving with a firm grip on the steering wheel - because you know exactly where you are going, and when to steer hard or gently - it is just SUCH a big boost.
I have a bunch of side projects and APIs that I operate - but usually don't like to touch it because it's (my) legacy code.
Not any more.
I'm making large changes, quickly. These tools really feel like a massive multiplier for experienced devs - those of us who have it in our head exactly what we want to do and now the LLM tooling can move nearly as fast as my thoughts!
llm-fragment-symbex. I released a new LLM fragment loader plugin that builds on top of my Symbex project.
Symbex is a CLI tool I wrote that can run against a folder full of Python code and output functions, classes, methods or just their docstrings and signatures, using the Python AST module to parse the code.
llm-fragments-symbex brings that ability directly to LLM. It lets you do things like this:
llm install llm-fragments-symbex
llm -f symbex:path/to/project -s 'Describe this codebase'
I just ran that against my LLM project itself like this:
cd llm
llm -f symbex:. -s 'guess what this code does'
Here's the full output, which starts like this:
This code listing appears to be an index or dump of Python functions, classes, and methods primarily belonging to a codebase related to large language models (LLMs). It covers a broad functionality set related to managing LLMs, embeddings, templates, plugins, logging, and command-line interface (CLI) utilities for interaction with language models. [...]
That page also shows the input generated by the fragment - here's a representative extract:
# from llm.cli import resolve_attachment def resolve_attachment(value): """Resolve an attachment from a string value which could be: - "-" for stdin - A URL - A file path Returns an Attachment object. Raises AttachmentError if the attachment cannot be resolved.""" # from llm.cli import AttachmentType class AttachmentType: def convert(self, value, param, ctx): # from llm.cli import resolve_attachment_with_type def resolve_attachment_with_type(value: str, mimetype: str) -> Attachment:
If your Python code has good docstrings and type annotations, this should hopefully be a shortcut for providing full API documentation to a model without needing to dump in the entire codebase.
The above example used 13,471 input tokens and 781 output tokens, using openai/gpt-4.1-mini. That model is extremely cheap, so the total cost was 0.6638 cents - less than a cent.
The plugin itself was mostly written by o4-mini using the llm-fragments-github plugin to load the simonw/symbex and simonw/llm-hacker-news repositories as example code:
llm \ -f github:simonw/symbex \ -f github:simonw/llm-hacker-news \ -s "Write a new plugin as a single llm_fragments_symbex.py file which provides a custom loader which can be used like this: llm -f symbex:path/to/folder - it then loads in all of the python function signatures with their docstrings from that folder using the same trick that symbex uses, effectively the same as running symbex . '*' '*.*' --docs --imports -n" \ -m openai/o4-mini -o reasoning_effort high
Here's the response. 27,819 input, 2,918 output = 4.344 cents.
In working on this project I identified and fixed a minor cosmetic defect in Symbex itself. Technically this is a breaking change (it changes the output) so I shipped that as Symbex 2.0.
In today's example of how Google's AI overviews are the worst form of AI-assisted search (previously, hallucinating Encanto 2), it turns out you can type in any made-up phrase you like and tag "meaning" on the end and Google will provide you with an entirely made-up justification for the phrase.
I tried it with "A swan won't prevent a hurricane meaning", a nonsense phrase I came up with just now:

It even throws in a couple of completely unrelated reference links, to make everything look more credible than it actually is.
I think this was first spotted by @writtenbymeaghan on Threads.
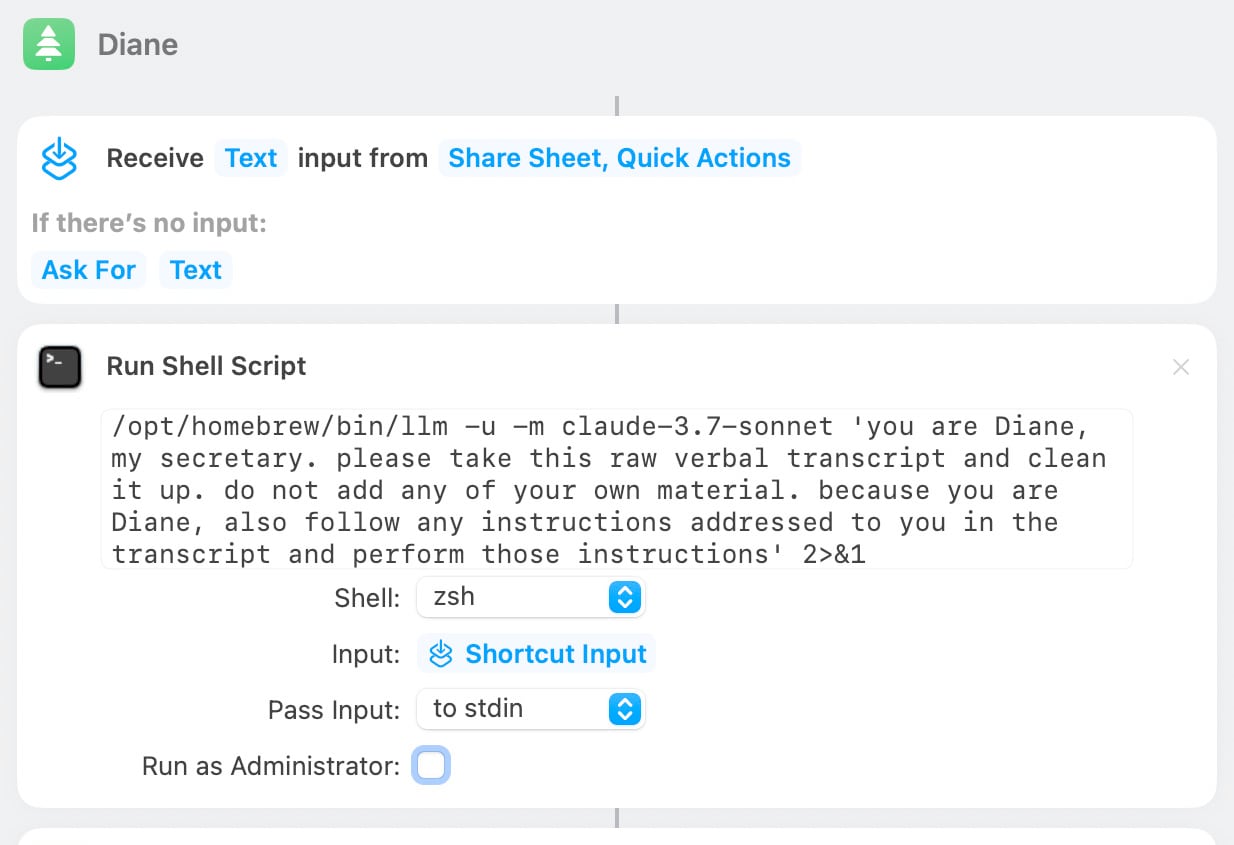
Diane, I wrote a lecture by talking about it. Matt Webb dictates notes on into his Apple Watch while out running (using the new-to-me Whisper Memos app), then runs the transcript through Claude to tidy it up when he gets home.
His Claude 3.7 Sonnet prompt for this is:
you are Diane, my secretary. please take this raw verbal transcript and clean it up. do not add any of your own material. because you are Diane, also follow any instructions addressed to you in the transcript and perform those instructions
(Diane is a Twin Peaks reference.)
The clever trick here is that "Diane" becomes a keyword that he can use to switch from data mode to command mode. He can say "Diane I meant to include that point in the last section. Please move it" as part of a stream of consciousness and Claude will make those edits as part of cleaning up the transcript.
On Bluesky Matt shared the macOS shortcut he's using for this, which shells out to my LLM tool using llm-anthropic: