Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM
31st July 2025
Qwen just released their sixth model(!) of this July called Qwen3-Coder-30B-A3B-Instruct—listed as Qwen3-Coder-Flash in their chat.qwen.ai interface.
It’s 30.5B total parameters with 3.3B active at any one time. This means it will fit on a 64GB Mac—and even a 32GB Mac if you quantize it—and can run really fast thanks to that smaller set of active parameters.
It’s a non-thinking model that is specially trained for coding tasks.
This is an exciting combination of properties: optimized for coding performance and speed and small enough to run on a mid-tier developer laptop.
Trying it out with LM Studio and Open WebUI
I like running models like this using Apple’s MLX framework. I ran GLM-4.5 Air the other day using the mlx-lm Python library directly, but this time I decided to try out the combination of LM Studio and Open WebUI.
(LM Studio has a decent interface built in, but I like the Open WebUI one slightly more.)
I installed the model by clicking the “Use model in LM Studio” button on LM Studio’s qwen/qwen3-coder-30b page. It gave me a bunch of options:
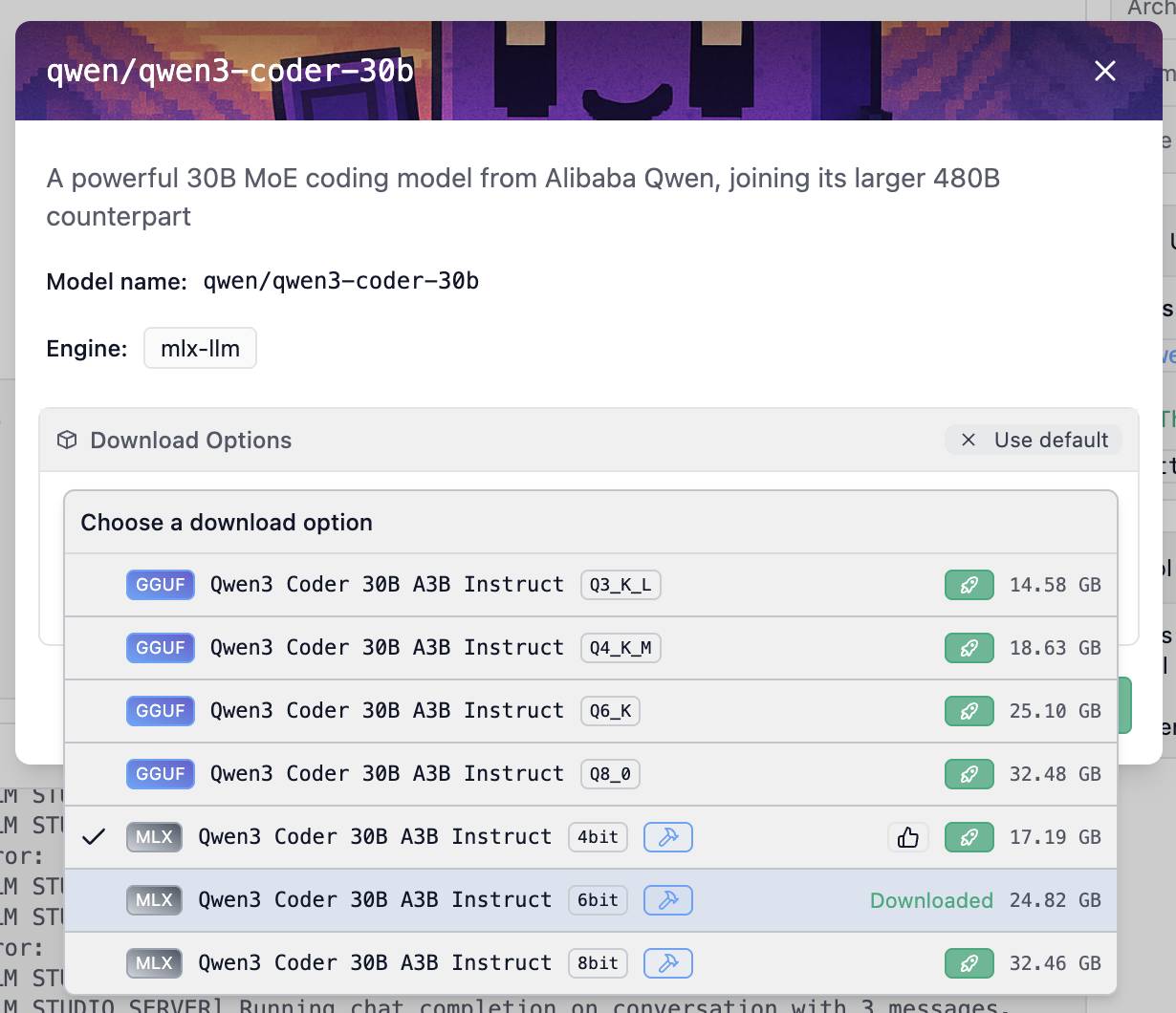
I chose the 6bit MLX model, which is a 24.82GB download. Other options include 4bit (17.19GB) and 8bit (32.46GB). The download sizes are roughly the same as the amount of RAM required to run the model—picking that 24GB one leaves 40GB free on my 64GB machine for other applications.
Then I opened the developer settings in LM Studio (the green folder icon) and turned on “Enable CORS” so I could access it from a separate Open WebUI instance.
Now I switched over to Open WebUI. I installed and ran it using uv like this:
uvx --python 3.11 open-webui serveThen navigated to http://localhost:8080/ to access the interface. I opened their settings and configured a new “Connection” to LM Studio:
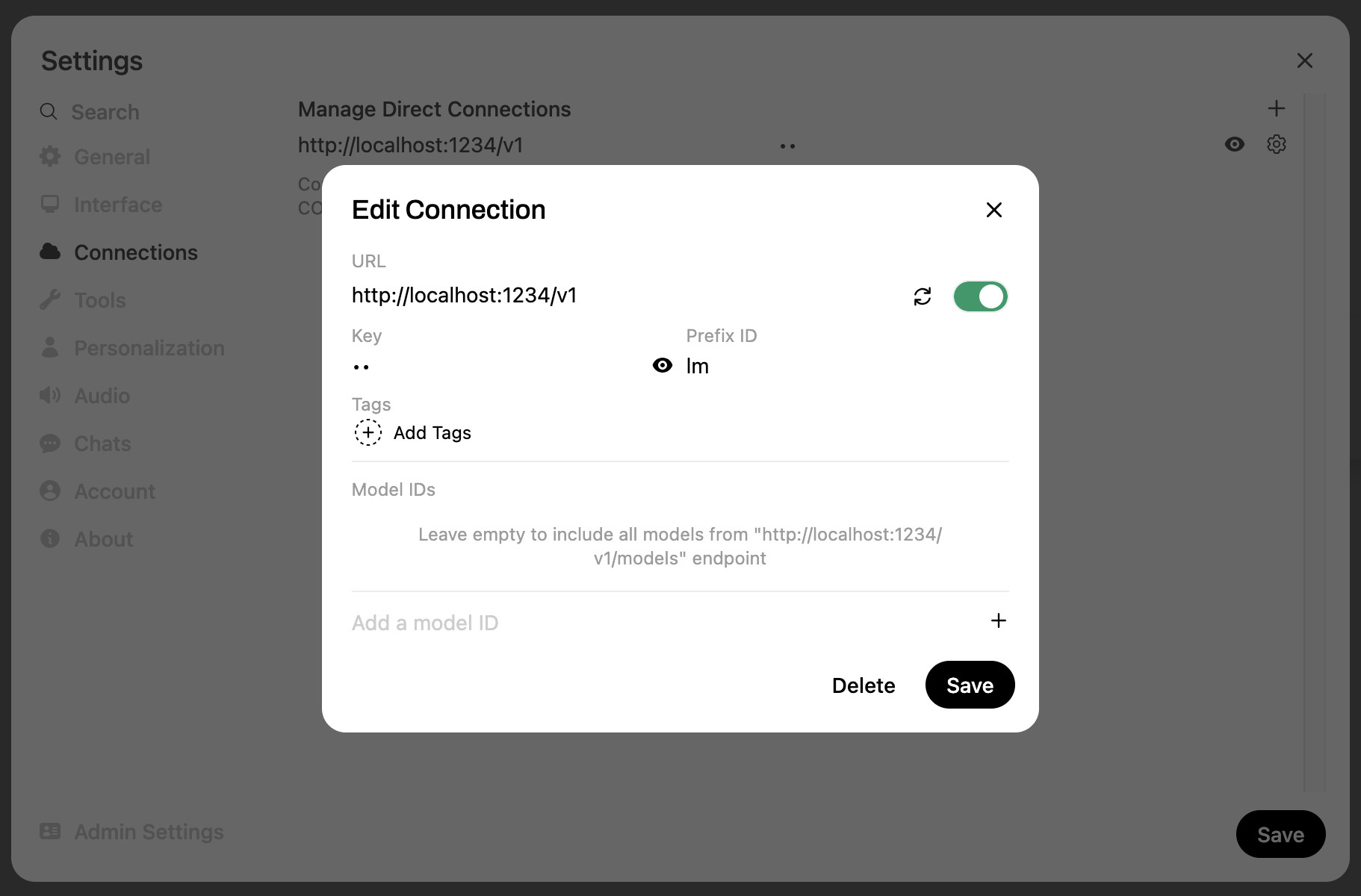
That needs a base URL of http://localhost:1234/v1 and a key of anything you like. I also set the optional prefix to lm just in case my Ollama installation—which Open WebUI detects automatically—ended up with any duplicate model names.
Having done all of that, I could select any of my LM Studio models in the Open WebUI interface and start running prompts.
A neat feature of Open WebUI is that it includes an automatic preview panel, which kicks in for fenced code blocks that include SVG or HTML:
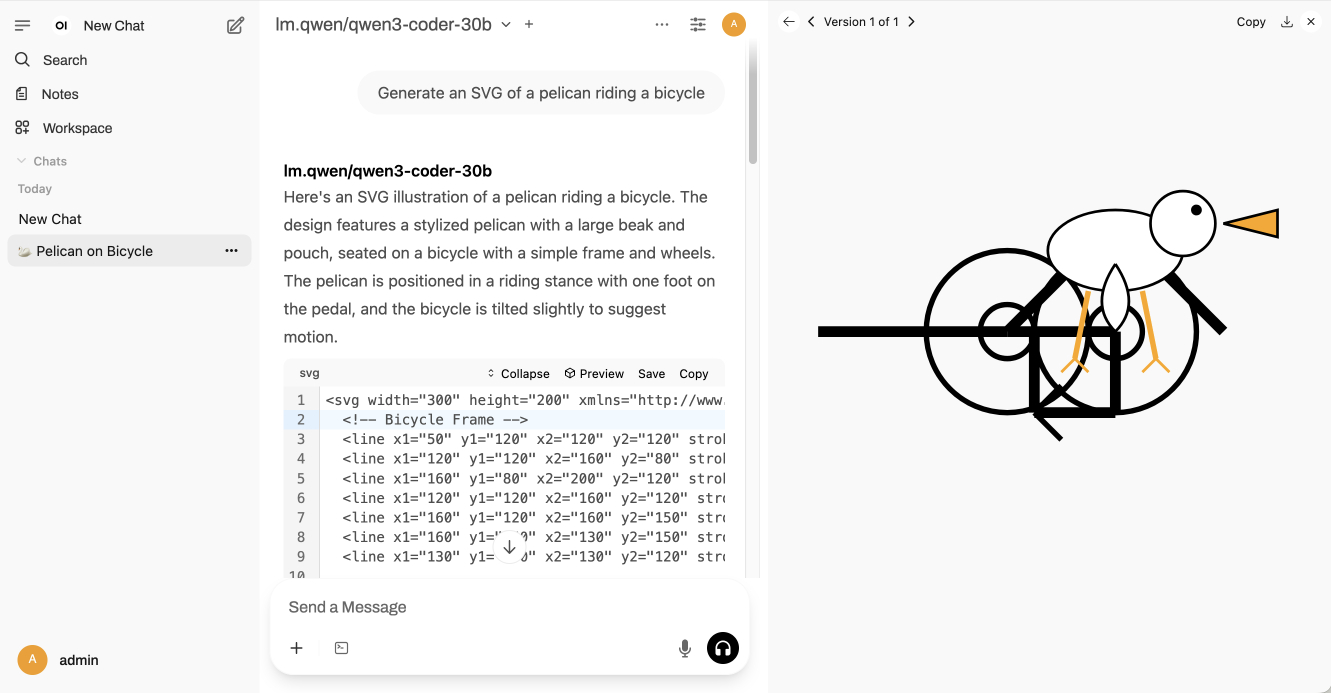
Here’s the exported transcript for “Generate an SVG of a pelican riding a bicycle”. It ran at almost 60 tokens a second!
Implementing Space Invaders
I tried my other recent simple benchmark prompt as well:
Write an HTML and JavaScript page implementing space invaders
I like this one because it’s a very short prompt that acts as shorthand for quite a complex set of features. There’s likely plenty of material in the training data to help the model achieve that goal but it’s still interesting to see if they manage to spit out something that works first time.
The first version it gave me worked out of the box, but was a little too hard—the enemy bullets move so fast that it’s almost impossible to avoid them:
You can try that out here.
I tried a follow-up prompt of “Make the enemy bullets a little slower”. A system like Claude Artifacts or Claude Code implements tool calls for modifying files in place, but the Open WebUI system I was using didn’t have a default equivalent which means the model had to output the full file a second time.
It did that, and slowed down the bullets, but it made a bunch of other changes as well, shown in this diff. I’m not too surprised by this—asking a 25GB local model to output a lengthy file with just a single change is quite a stretch.
Here’s the exported transcript for those two prompts.
Running LM Studio models with mlx-lm
LM Studio stores its models in the ~/.cache/lm-studio/models directory. This means you can use the mlx-lm Python library to run prompts through the same model like this:
uv run --isolated --with mlx-lm mlx_lm.generate \
--model ~/.cache/lm-studio/models/lmstudio-community/Qwen3-Coder-30B-A3B-Instruct-MLX-6bit \
--prompt "Write an HTML and JavaScript page implementing space invaders" \
-m 8192 --top-k 20 --top-p 0.8 --temp 0.7Be aware that this will load a duplicate copy of the model into memory so you may want to quit LM Studio before running this command!
Accessing the model via my LLM tool
My LLM project provides a command-line tool and Python library for accessing large language models.
Since LM Studio offers an OpenAI-compatible API, you can configure LLM to access models through that API by creating or editing the ~/Library/Application\ Support/io.datasette.llm/extra-openai-models.yaml file:
zed ~/Library/Application\ Support/io.datasette.llm/extra-openai-models.yamlI added the following YAML configuration:
- model_id: qwen3-coder-30b
model_name: qwen/qwen3-coder-30b
api_base: http://localhost:1234/v1
supports_tools: trueProvided LM Studio is running I can execute prompts from my terminal like this:
llm -m qwen3-coder-30b 'A joke about a pelican and a cheesecake'Why did the pelican refuse to eat the cheesecake?
Because it had a beak for dessert! 🥧🦜
(Or if you prefer: Because it was afraid of getting beak-sick from all that creamy goodness!)
(25GB clearly isn’t enough space for a functional sense of humor.)
More interestingly though, we can start exercising the Qwen model’s support for tool calling:
llm -m qwen3-coder-30b \
-T llm_version -T llm_time --td \
'tell the time then show the version'Here we are enabling LLM’s two default tools—one for telling the time and one for seeing the version of LLM that’s currently installed. The --td flag stands for --tools-debug.
The output looks like this, debug output included:
Tool call: llm_time({})
{
"utc_time": "2025-07-31 19:20:29 UTC",
"utc_time_iso": "2025-07-31T19:20:29.498635+00:00",
"local_timezone": "PDT",
"local_time": "2025-07-31 12:20:29",
"timezone_offset": "UTC-7:00",
"is_dst": true
}
Tool call: llm_version({})
0.26
The current time is:
- Local Time (PDT): 2025-07-31 12:20:29
- UTC Time: 2025-07-31 19:20:29
The installed version of the LLM is 0.26.
Pretty good! It managed two tool calls from a single prompt.
Sadly I couldn’t get it to work with some of my more complex plugins such as llm-tools-sqlite. I’m trying to figure out if that’s a bug in the model, the LM Studio layer or my own code for running tool prompts against OpenAI-compatible endpoints.
The month of Qwen
July has absolutely been the month of Qwen. The models they have released this month are outstanding, packing some extremely useful capabilities even into models I can run in 25GB of RAM or less on my own laptop.
If you’re looking for a competent coding model you can run locally Qwen3-Coder-30B-A3B is a very solid choice.
More recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026