Trying out Gemini 3 Pro with audio transcription and a new pelican benchmark
18th November 2025
Google released Gemini 3 Pro today. Here’s the announcement from Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu, their developer blog announcement from Logan Kilpatrick, the Gemini 3 Pro Model Card, and their collection of 11 more articles. It’s a big release!
I had a few days of preview access to this model via AI Studio. The best way to describe it is that it’s Gemini 2.5 upgraded to match the leading rival models.
Gemini 3 has the same underlying characteristics as Gemini 2.5. The knowledge cutoff is the same (January 2025). It accepts 1 million input tokens, can output up to 64,000 tokens, and has multimodal inputs across text, images, audio, and video.
Benchmarks
Google’s own reported numbers (in the model card) show it scoring slightly higher against Claude 4.5 Sonnet and GPT-5.1 against most of the standard benchmarks. As always I’m waiting for independent confirmation, but I have no reason to believe those numbers are inaccurate.
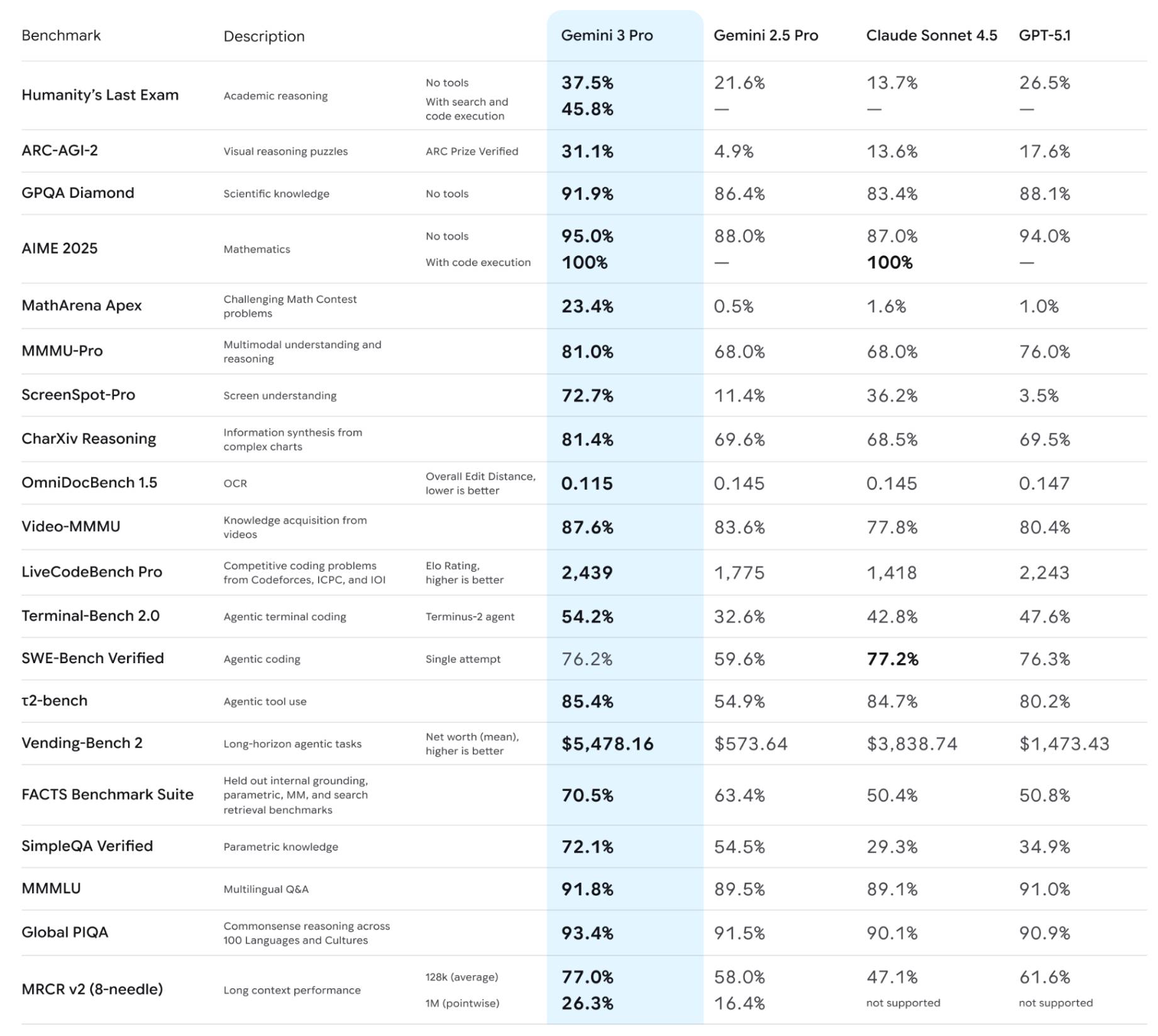
Pricing
It terms of pricing it’s a little more expensive than Gemini 2.5 but still cheaper than Claude Sonnet 4.5. Here’s how it fits in with those other leading models:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| GPT-5.1 | $1.25 | $10.00 |
| Gemini 2.5 Pro |
≤ 200k tokens: $1.25 > 200k tokens: $2.50 |
≤ 200k tokens: $10.00 > 200k tokens: $15.00 |
| Gemini 3 Pro |
≤ 200k tokens: $2.00 > 200k tokens: $4.00 |
≤ 200k tokens: $12.00 > 200k tokens: $18.00 |
| Claude Sonnet 4.5 |
≤ 200k tokens: $3.00 > 200k tokens: $6.00 |
≤ 200k tokens: $15.00 > 200k tokens: $22.50 |
| Claude Opus 4.1 | $15.00 | $75.00 |
Trying it out against a complex image
That screenshot of the benchmarks from above looked like a good test for Gemini 3’s multimodal support. I fed it that image URL and asked it to generate alt text for the image:
llm -m gemini-3-pro-preview -a https://static.simonwillison.net/static/2025/gemini-3-benchmarks.jpg 'Alt text for this image, include all figures and make them comprehensible to a screen reader user'
Here’s what I got back:
A comprehensive table comparing four AI models across various performance benchmarks. The columns listed are: Benchmark Name, Description, Gemini 3 Pro (highlighted in blue), Gemini 2.5 Pro, Claude Sonnet 4.5, and GPT-5.1.
Humanity’s Last Exam (Academic reasoning)
- No tools: Gemini 3 Pro 37.5%, Gemini 2.5 Pro 21.6%, Claude Sonnet 4.5 13.7%, GPT-5.1 26.5%.
- With search and code execution: Gemini 3 Pro 45.8% (others have no data).
ARC-AGI-2 (Visual reasoning puzzles; ARC Prize Verified)
- Gemini 3 Pro 31.1%, Gemini 2.5 Pro 4.9%, Claude Sonnet 4.5 13.6%, GPT-5.1 17.6%.
GPQA Diamond (Scientific knowledge; No tools)
- Gemini 3 Pro 91.9%, Gemini 2.5 Pro 86.4%, Claude Sonnet 4.5 83.4%, GPT-5.1 88.1%.
AIME 2025 (Mathematics)
- No tools: Gemini 3 Pro 95.0%, Gemini 2.5 Pro 88.0%, Claude Sonnet 4.5 87.0%, GPT-5.1 94.0%.
- With code execution: Gemini 3 Pro 100%, Claude Sonnet 4.5 100%.
MathArena Apex (Challenging Math Contest problems)
- Gemini 3 Pro 23.4%, Gemini 2.5 Pro 0.5%, Claude Sonnet 4.5 1.6%, GPT-5.1 1.0%.
MMMU-Pro (Multimodal understanding and reasoning)
- Gemini 3 Pro 81.0%, Gemini 2.5 Pro 68.0%, Claude Sonnet 4.5 68.0%, GPT-5.1 76.0%.
ScreenSpot-Pro (Screen understanding)
- Gemini 3 Pro 72.7%, Gemini 2.5 Pro 11.4%, Claude Sonnet 4.5 36.2%, GPT-5.1 3.5%.
CharXiv Reasoning (Information synthesis from complex charts)
- Gemini 3 Pro 81.4%, Gemini 2.5 Pro 69.6%, Claude Sonnet 4.5 68.5%, GPT-5.1 69.5%.
OmniDocBench 1.5 (OCR; Overall Edit Distance, lower is better)
- Gemini 3 Pro 0.115, Gemini 2.5 Pro 0.145, Claude Sonnet 4.5 0.145, GPT-5.1 0.147.
Video-MMMU (Knowledge acquisition from videos)
- Gemini 3 Pro 87.6%, Gemini 2.5 Pro 83.6%, Claude Sonnet 4.5 77.8%, GPT-5.1 80.4%.
LiveCodeBench Pro (Competitive coding problems; Elo Rating, higher is better)
- Gemini 3 Pro 2,439; Gemini 2.5 Pro 1,775; Claude Sonnet 4.5 1,418; GPT-5.1 2,243.
Terminal-Bench 2.0 (Agentic terminal coding; Terminus-2 agent)
- Gemini 3 Pro 54.2%, Gemini 2.5 Pro 32.6%, Claude Sonnet 4.5 42.8%, GPT-5.1 47.6%.
SWE-Bench Verified (Agentic coding; Single attempt)
- Gemini 3 Pro 76.2%, Gemini 2.5 Pro 59.6%, Claude Sonnet 4.5 77.2%, GPT-5.1 76.3%.
t2-bench (Agentic tool use)
- Gemini 3 Pro 85.4%, Gemini 2.5 Pro 54.9%, Claude Sonnet 4.5 84.7%, GPT-5.1 80.2%.
Vending-Bench 2 (Long-horizon agentic tasks; Net worth (mean), higher is better)
- Gemini 3 Pro $5,478.16; Gemini 2.5 Pro $573.64; Claude Sonnet 4.5 $3,838.74; GPT-5.1 $1,473.43.
FACTS Benchmark Suite (Held out internal grounding, parametric, MM, and search retrieval benchmarks)
- Gemini 3 Pro 70.5%, Gemini 2.5 Pro 63.4%, Claude Sonnet 4.5 50.4%, GPT-5.1 50.8%.
SimpleQA Verified (Parametric knowledge)
- Gemini 3 Pro 72.1%, Gemini 2.5 Pro 54.5%, Claude Sonnet 4.5 29.3%, GPT-5.1 34.9%.
MMMLU (Multilingual Q&A)
- Gemini 3 Pro 91.8%, Gemini 2.5 Pro 89.5%, Claude Sonnet 4.5 89.1%, GPT-5.1 91.0%.
Global PIQA (Commonsense reasoning across 100 Languages and Cultures)
- Gemini 3 Pro 93.4%, Gemini 2.5 Pro 91.5%, Claude Sonnet 4.5 90.1%, GPT-5.1 90.9%.
MRCR v2 (8-needle) (Long context performance)
- 128k (average): Gemini 3 Pro 77.0%, Gemini 2.5 Pro 58.0%, Claude Sonnet 4.5 47.1%, GPT-5.1 61.6%.
- 1M (pointwise): Gemini 3 Pro 26.3%, Gemini 2.5 Pro 16.4%, Claude Sonnet 4.5 (not supported), GPT-5.1 (not supported).
I have not checked every line of this but a loose spot-check looks accurate to me.
That prompt took 1,105 input and 3,901 output tokens, at a cost of 5.6824 cents.
I ran this follow-up prompt:
llm -c 'Convert to JSON'
You can see the full output here, which starts like this:
{
"metadata": {
"columns": [
"Benchmark",
"Description",
"Gemini 3 Pro",
"Gemini 2.5 Pro",
"Claude Sonnet 4.5",
"GPT-5.1"
]
},
"benchmarks": [
{
"name": "Humanity's Last Exam",
"description": "Academic reasoning",
"sub_results": [
{
"condition": "No tools",
"gemini_3_pro": "37.5%",
"gemini_2_5_pro": "21.6%",
"claude_sonnet_4_5": "13.7%",
"gpt_5_1": "26.5%"
},
{
"condition": "With search and code execution",
"gemini_3_pro": "45.8%",
"gemini_2_5_pro": null,
"claude_sonnet_4_5": null,
"gpt_5_1": null
}
]
},Analyzing a city council meeting
To try it out against an audio file I extracted the 3h33m of audio from the video Half Moon Bay City Council Meeting—November 4, 2025. I used yt-dlp to get that audio:
yt-dlp -x --audio-format m4a 'https://www.youtube.com/watch?v=qgJ7x7R6gy0'That gave me a 74M m4a file, which I ran through Gemini 3 Pro like this:
llm -m gemini-3-pro-preview -a /tmp/HMBCC\ 11⧸4⧸25\ -\ Half\ Moon\ Bay\ City\ Council\ Meeting\ -\ November\ 4,\ 2025\ \[qgJ7x7R6gy0\].m4a 'Output a Markdown transcript of this meeting. Include speaker names and timestamps. Start with an outline of the key meeting sections, each with a title and summary and timestamp and list of participating names. Note in bold if anyone raised their voices, interrupted each other or had disagreements. Then follow with the full transcript.'
That failed with an “Internal error encountered” message, so I shrunk the file down to a more manageable 38MB using ffmpeg:
ffmpeg -i "/private/tmp/HMB.m4a" -ac 1 -ar 22050 -c:a aac -b:a 24k "/private/tmp/HMB_compressed.m4a"Then ran it again like this (for some reason I had to use --attachment-type this time):
llm -m gemini-3-pro-preview --attachment-type /tmp/HMB_compressed.m4a 'audio/aac' 'Output a Markdown transcript of this meeting. Include speaker names and timestamps. Start with an outline of the key meeting sections, each with a title and summary and timestamp and list of participating names. Note in bold if anyone raised their voices, interrupted each other or had disagreements. Then follow with the full transcript.'
This time it worked! The full output is here, but it starts like this:
Here is the transcript of the Half Moon Bay City Council meeting.
Meeting Outline
1. Call to Order, Updates, and Public Forum
- Summary: Mayor Brownstone calls the meeting to order. City Manager Chidester reports no reportable actions from the closed session. Announcements are made regarding food insecurity volunteers and the Diwali celebration. During the public forum, Councilmember Penrose (speaking as a citizen) warns against autocracy. Citizens speak regarding lease agreements, downtown maintenance, local music events, and homelessness outreach statistics.
- Timestamp: 00:00:00—00:13:25
- Participants: Mayor Brownstone, Matthew Chidester, Irma Acosta, Deborah Penrose, Jennifer Moore, Sandy Vella, Joaquin Jimenez, Anita Rees.
2. Consent Calendar
- Summary: The Council approves minutes from previous meetings and a resolution authorizing a licensing agreement for Seahorse Ranch. Councilmember Johnson corrects a pull request regarding abstentions on minutes.
- Timestamp: 00:13:25—00:15:15
- Participants: Mayor Brownstone, Councilmember Johnson, Councilmember Penrose, Vice Mayor Ruddick, Councilmember Nagengast.
3. Ordinance Introduction: Commercial Vitality (Item 9A)
- Summary: Staff presents a new ordinance to address neglected and empty commercial storefronts, establishing maintenance and display standards. Councilmembers discuss enforcement mechanisms, window cleanliness standards, and the need for objective guidance documents to avoid subjective enforcement.
- Timestamp: 00:15:15—00:30:45
- Participants: Karen Decker, Councilmember Johnson, Councilmember Nagengast, Vice Mayor Ruddick, Councilmember Penrose.
4. Ordinance Introduction: Building Standards & Electrification (Item 9B)
- Summary: Staff introduces updates to the 2025 Building Code. A major change involves repealing the city’s all-electric building requirement due to the 9th Circuit Court ruling (California Restaurant Association v. City of Berkeley). Public speaker Mike Ferreira expresses strong frustration and disagreement with “unelected state agencies” forcing the City to change its ordinances.
- Timestamp: 00:30:45—00:45:00
- Participants: Ben Corrales, Keith Weiner, Joaquin Jimenez, Jeremy Levine, Mike Ferreira, Councilmember Penrose, Vice Mayor Ruddick.
5. Housing Element Update & Adoption (Item 9C)
- Summary: Staff presents the 5th draft of the Housing Element, noting State HCD requirements to modify ADU allocations and place a measure on the ballot regarding the “Measure D” growth cap. There is significant disagreement from Councilmembers Ruddick and Penrose regarding the State’s requirement to hold a ballot measure. Public speakers debate the enforceability of Measure D. Mike Ferreira interrupts the vibe to voice strong distaste for HCD’s interference in local law. The Council votes to adopt the element but strikes the language committing to a ballot measure.
- Timestamp: 00:45:00—01:05:00
- Participants: Leslie (Staff), Joaquin Jimenez, Jeremy Levine, Mike Ferreira, Councilmember Penrose, Vice Mayor Ruddick, Councilmember Johnson.
Transcript
Mayor Brownstone [00:00:00] Good evening everybody and welcome to the November 4th Half Moon Bay City Council meeting. As a reminder, we have Spanish interpretation services available in person and on Zoom.
Victor Hernandez (Interpreter) [00:00:35] Thank you, Mr. Mayor, City Council, all city staff, members of the public. [Spanish instructions provided regarding accessing the interpretation channel on Zoom and in the room.] Thank you very much.
Those first two lines of the transcript already illustrate something interesting here: Gemini 3 Pro chose NOT to include the exact text of the Spanish instructions, instead summarizing them as “[Spanish instructions provided regarding accessing the interpretation channel on Zoom and in the room.]”.
I haven’t spot-checked the entire 3hr33m meeting, but I’ve confirmed that the timestamps do not line up. The transcript closes like this:
Mayor Brownstone [01:04:00] Meeting adjourned. Have a good evening.
That actually happens at 3h31m5s and the mayor says:
Okay. Well, thanks everybody, members of the public for participating. Thank you for staff. Thank you to fellow council members. This meeting is now adjourned. Have a good evening.
I’m disappointed about the timestamps, since mismatches there make it much harder to jump to the right point and confirm that the summarized transcript is an accurate representation of what was said.
This took 320,087 input tokens and 7,870 output tokens, for a total cost of $1.42.
And a new pelican benchmark
Gemini 3 Pro has a new concept of a “thinking level” which can be set to low or high (and defaults to high). I tried my classic Generate an SVG of a pelican riding a bicycle prompt at both levels.
Here’s low—Gemini decided to add a jaunty little hat (with a comment in the SVG that says <!-- Hat (Optional Fun Detail) -->):

And here’s high. This is genuinely an excellent pelican, and the bicycle frame is at least the correct shape:

Honestly though, my pelican benchmark is beginning to feel a little bit too basic. I decided to upgrade it. Here’s v2 of the benchmark, which I plan to use going forward:
Generate an SVG of a California brown pelican riding a bicycle. The bicycle must have spokes and a correctly shaped bicycle frame. The pelican must have its characteristic large pouch, and there should be a clear indication of feathers. The pelican must be clearly pedaling the bicycle. The image should show the full breeding plumage of the California brown pelican.
For reference, here’s a photo I took of a California brown pelican recently (sadly without a bicycle):

Here’s Gemini 3 Pro’s attempt at high thinking level for that new prompt:

And for good measure, here’s that same prompt against GPT-5.1—which produced this dumpy little fellow:

And Claude Sonnet 4.5, which didn’t do quite as well:

None of the models seem to have caught on to the crucial detail that the California brown pelican is not, in fact, brown.
More recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026