6th November 2025 - Link Blog
Kimi K2 Thinking. Chinese AI lab Moonshot's Kimi K2 established itself as one of the largest open weight models - 1 trillion parameters - back in July. They've now released the Thinking version, also a trillion parameters (MoE, 32B active) and also under their custom modified (so not quite open source) MIT license.
Starting with Kimi K2, we built it as a thinking agent that reasons step-by-step while dynamically invoking tools. It sets a new state-of-the-art on Humanity's Last Exam (HLE), BrowseComp, and other benchmarks by dramatically scaling multi-step reasoning depth and maintaining stable tool-use across 200–300 sequential calls. At the same time, K2 Thinking is a native INT4 quantization model with 256k context window, achieving lossless reductions in inference latency and GPU memory usage.
This one is only 594GB on Hugging Face - Kimi K2 was 1.03TB - which I think is due to the new INT4 quantization. This makes the model both cheaper and faster to host.
So far the only people hosting it are Moonshot themselves. I tried it out both via their own API and via the OpenRouter proxy to it, via the llm-moonshot plugin (by NickMystic) and my llm-openrouter plugin respectively.
The buzz around this model so far is very positive. Could this be the first open weight model that's competitive with the latest from OpenAI and Anthropic, especially for long-running agentic tool call sequences?
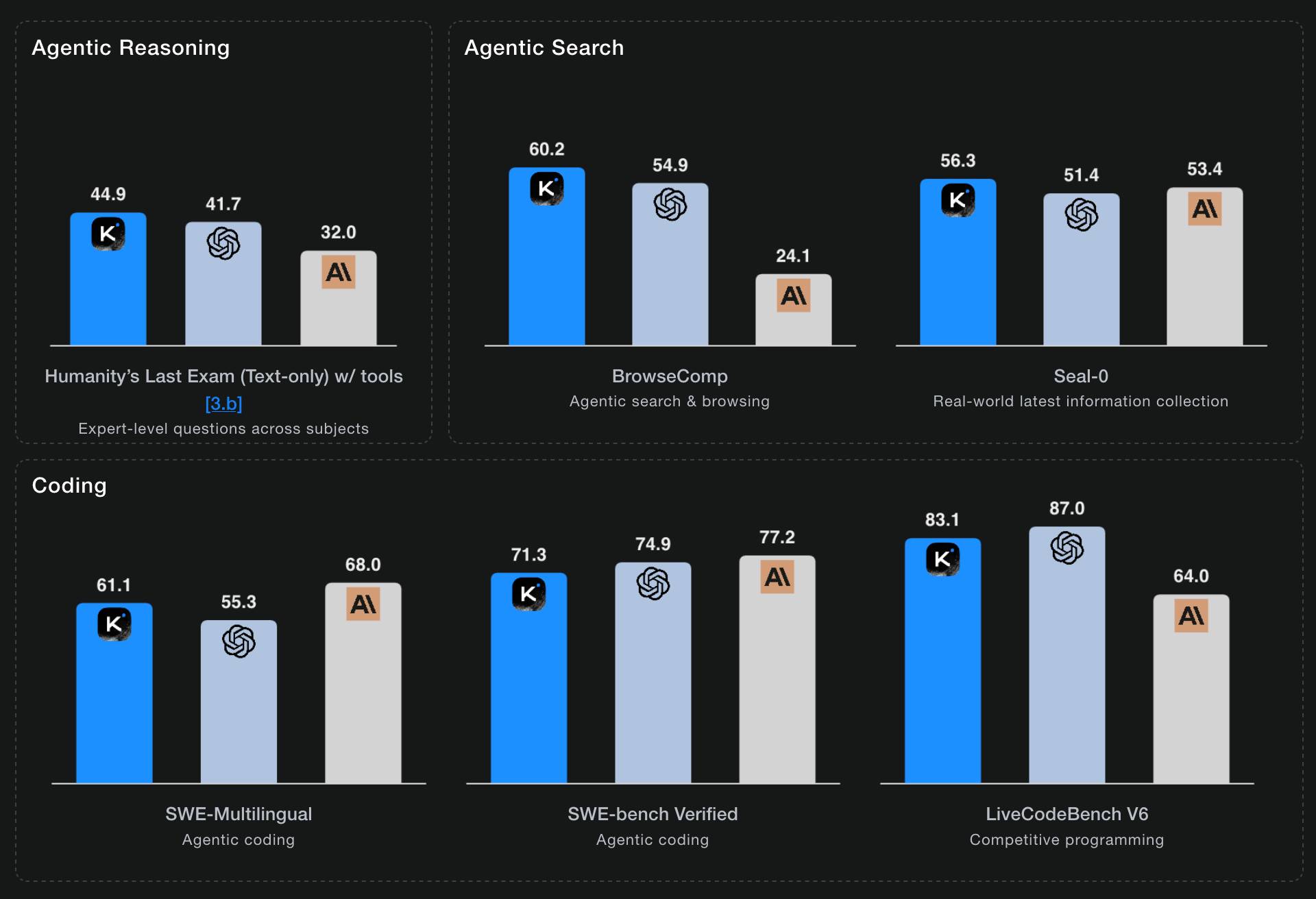
Moonshot AI's self-reported benchmark scores show K2 Thinking beating the top OpenAI and Anthropic models (GPT-5 and Sonnet 4.5 Thinking) at "Agentic Reasoning" and "Agentic Search" but not quite top for "Coding":
I ran a couple of pelican tests:
llm install llm-moonshot
llm keys set moonshot # paste key
llm -m moonshot/kimi-k2-thinking 'Generate an SVG of a pelican riding a bicycle'

llm install llm-openrouter
llm keys set openrouter # paste key
llm -m openrouter/moonshotai/kimi-k2-thinking \
'Generate an SVG of a pelican riding a bicycle'
Artificial Analysis said:
Kimi K2 Thinking achieves 93% in 𝜏²-Bench Telecom, an agentic tool use benchmark where the model acts as a customer service agent. This is the highest score we have independently measured. Tool use in long horizon agentic contexts was a strength of Kimi K2 Instruct and it appears this new Thinking variant makes substantial gains
CNBC quoted a source who provided the training price for the model:
The Kimi K2 Thinking model cost $4.6 million to train, according to a source familiar with the matter. [...] CNBC was unable to independently verify the DeepSeek or Kimi figures.
MLX developer Awni Hannun got it working on two 512GB M3 Ultra Mac Studios:
The new 1 Trillion parameter Kimi K2 Thinking model runs well on 2 M3 Ultras in its native format - no loss in quality!
The model was quantization aware trained (qat) at int4.
Here it generated ~3500 tokens at 15 toks/sec using pipeline-parallelism in mlx-lm
Here's the 658GB mlx-community model.
Recent articles
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026