Wednesday, 1st October 2025
I just sent out the September edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access a copy here. The sections this month are:
- Best model for code? GPT-5-Codex... then Claude 4.5 Sonnet
- I've grudgingly accepted a definition for "agent"
- GPT-5 Research Goblin and Google AI Mode
- Claude has Code Interpreter now
- The lethal trifecta in the Economist
- Other significant model releases
- Notable AI success stories
- Video models are zero-shot learners and reasoners
- Tools I'm using at the moment
- Other bits and pieces
Here's a copy of the August newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
Two new models from Chinese AI labs in the past few days. I tried them both out using llm-openrouter:
DeepSeek-V3.2-Exp from DeepSeek. Announcement, Tech Report, Hugging Face (690GB, MIT license).
As an intermediate step toward our next-generation architecture, V3.2-Exp builds upon V3.1-Terminus by introducing DeepSeek Sparse Attention—a sparse attention mechanism designed to explore and validate optimizations for training and inference efficiency in long-context scenarios.
This one felt very slow when I accessed it via OpenRouter - I probably got routed to one of the slower providers. Here's the pelican:
GLM-4.6 from Z.ai. Announcement, Hugging Face (714GB, MIT license).
The context window has been expanded from 128K to 200K tokens [...] higher scores on code benchmarks [...] GLM-4.6 exhibits stronger performance in tool using and search-based agents.
Here's the pelican for that:

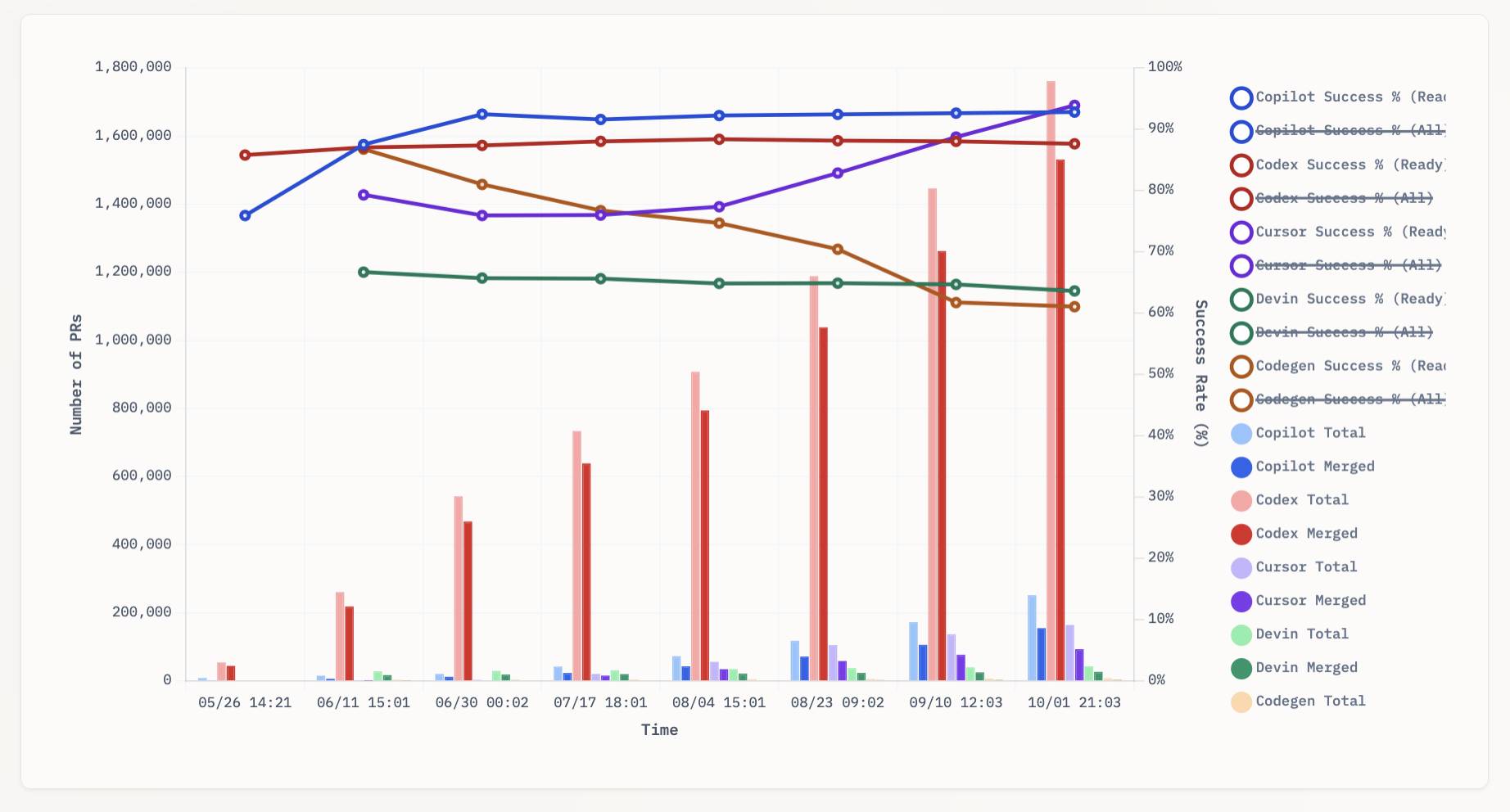
aavetis/PRarena. Albert Avetisian runs this repository on GitHub which uses the Github Search API to track the number of PRs that can be credited to a collection of different coding agents. The repo runs this collect_data.py script every three hours using GitHub Actions to collect the data, then updates the PR Arena site with a visual leaderboard.
The result is this neat chart showing adoption of different agents over time, along with their PR success rate:
I found this today while trying to pull off the exact same trick myself! I got as far as creating the following table before finding Albert's work and abandoning my own project.
| Tool | Search term | Total PRs | Merged PRs | % merged | Earliest |
|---|---|---|---|---|---|
| Claude Code | is:pr in:body "Generated with Claude Code" |
146,000 | 123,000 | 84.2% | Feb 21st |
| GitHub Copilot | is:pr author:copilot-swe-agent[bot] |
247,000 | 152,000 | 61.5% | March 7th |
| Codex Cloud | is:pr in:body "chatgpt.com" label:codex |
1,900,000 | 1,600,000 | 84.2% | April 23rd |
| Google Jules | is:pr author:google-labs-jules[bot] |
35,400 | 27,800 | 78.5% | May 22nd |
(Those "earliest" links are a little questionable, I tried to filter out false positives and find the oldest one that appeared to really be from the agent in question.)
It looks like OpenAI's Codex Cloud is massively ahead of the competition right now in terms of numbers of PRs both opened and merged on GitHub.
Update: To clarify, these numbers are for the category of autonomous coding agents - those systems where you assign a cloud-based agent a task or issue and the output is a PR against your repository. They do not (and cannot) capture the popularity of many forms of AI tooling that don't result in an easily identifiable pull request.
Claude Code for example will be dramatically under-counted here because its version of an autonomous coding agent comes in the form of a somewhat obscure GitHub Actions workflow buried in the documentation.