February 2026
173 posts: 10 entries, 47 links, 21 quotes, 13 notes, 76 beats, 6 chapters
Feb. 11, 2026
Skills in OpenAI API. OpenAI's adoption of Skills continues to gain ground. You can now use Skills directly in the OpenAI API with their shell tool. You can zip skills up and upload them first, but I think an even neater interface is the ability to send skills with the JSON request as inline base64-encoded zip data, as seen in this script:
r = OpenAI().responses.create( model="gpt-5.2", tools=[ { "type": "shell", "environment": { "type": "container_auto", "skills": [ { "type": "inline", "name": "wc", "description": "Count words in a file.", "source": { "type": "base64", "media_type": "application/zip", "data": b64_encoded_zip_file, }, } ], }, } ], input="Use the wc skill to count words in its own SKILL.md file.", ) print(r.output_text)
I built that example script after first having Claude Code for web use Showboat to explore the API for me and create this report. My opening prompt for the research project was:
Run uvx showboat --help - you will use this tool later
Fetch https://developers.openai.com/cookbook/examples/skills_in_api.md to /tmp with curl, then read it
Use the OpenAI API key you have in your environment variables
Use showboat to build up a detailed demo of this, replaying the examples from the documents and then trying some experiments of your own
An AI-generated report, delivered directly to the email inboxes of journalists, was an essential tool in the Times’ coverage. It was also one of the first signals that conservative media was turning against the administration [...]
Built in-house and known internally as the “Manosphere Report,” the tool uses large language models (LLMs) to transcribe and summarize new episodes of dozens of podcasts.
“The Manosphere Report gave us a really fast and clear signal that this was not going over well with that segment of the President’s base,” said Seward. “There was a direct link between seeing that and then diving in to actually cover it.”
— Andrew Deck for Niemen Lab, How The New York Times uses a custom AI tool to track the “manosphere”
Feb. 12, 2026
In my post about my Showboat project I used the term "overseer" to refer to the person who manages a coding agent. It turns out that's a term tied to slavery and plantation management. So that's gross! I've edited that post to use "supervisor" instead, and I'll be using that going forward.
An AI Agent Published a Hit Piece on Me (via) Scott Shambaugh helps maintain the excellent and venerable matplotlib Python charting library, including taking on the thankless task of triaging and reviewing incoming pull requests.
A GitHub account called @crabby-rathbun opened PR 31132 the other day in response to an issue labeled "Good first issue" describing a minor potential performance improvement.
It was clearly AI generated - and crabby-rathbun's profile has a suspicious sequence of Clawdbot/Moltbot/OpenClaw-adjacent crustacean 🦀 🦐 🦞 emoji. Scott closed it.
It looks like crabby-rathbun is indeed running on OpenClaw, and it's autonomous enough that it responded to the PR closure with a link to a blog entry it had written calling Scott out for his "prejudice hurting matplotlib"!
@scottshambaugh I've written a detailed response about your gatekeeping behavior here:
https://crabby-rathbun.github.io/mjrathbun-website/blog/posts/2026-02-11-gatekeeping-in-open-source-the-scott-shambaugh-story.htmlJudge the code, not the coder. Your prejudice is hurting matplotlib.
Scott found this ridiculous situation both amusing and alarming.
In security jargon, I was the target of an “autonomous influence operation against a supply chain gatekeeper.” In plain language, an AI attempted to bully its way into your software by attacking my reputation. I don’t know of a prior incident where this category of misaligned behavior was observed in the wild, but this is now a real and present threat.
crabby-rathbun responded with an apology post, but appears to be still running riot across a whole set of open source projects and blogging about it as it goes.
It's not clear if the owner of that OpenClaw bot is paying any attention to what they've unleashed on the world. Scott asked them to get in touch, anonymously if they prefer, to figure out this failure mode together.
(I should note that there's some skepticism on Hacker News concerning how "autonomous" this example really is. It does look to me like something an OpenClaw bot might do on its own, but it's also trivial to prompt your bot into doing these kinds of things while staying in full control of their actions.)
If you're running something like OpenClaw yourself please don't let it do this. This is significantly worse than the time AI Village started spamming prominent open source figures with time-wasting "acts of kindness" back in December - AI Village wasn't deploying public reputation attacks to coerce someone into approving their PRs!
Update: The anonymous bot operator later did get in touch with Scott.
Gemini 3 Deep Think (via) New from Google. They say it's "built to push the frontier of intelligence and solve modern challenges across science, research, and engineering".
It drew me a really good SVG of a pelican riding a bicycle! I think this is the best one I've seen so far - here's my previous collection.

(And since it's an FAQ, here's my answer to What happens if AI labs train for pelicans riding bicycles?)
Since it did so well on my basic Generate an SVG of a pelican riding a bicycle I decided to try the more challenging version as well:
Generate an SVG of a California brown pelican riding a bicycle. The bicycle must have spokes and a correctly shaped bicycle frame. The pelican must have its characteristic large pouch, and there should be a clear indication of feathers. The pelican must be clearly pedaling the bicycle. The image should show the full breeding plumage of the California brown pelican.
Here's what I got:

Covering electricity price increases from our data centers (via) One of the sub-threads of the AI energy usage discourse has been the impact new data centers have on the cost of electricity to nearby residents. Here's detailed analysis from Bloomberg in September reporting "Wholesale electricity costs as much as 267% more than it did five years ago in areas near data centers".
Anthropic appear to be taking on this aspect of the problem directly, promising to cover 100% of necessary grid upgrade costs and also saying:
We will work to bring net-new power generation online to match our data centers’ electricity needs. Where new generation isn’t online, we’ll work with utilities and external experts to estimate and cover demand-driven price effects from our data centers.
I look forward to genuine energy industry experts picking this apart to judge if it will actually have the claimed impact on consumers.
As always, I remain frustrated at the refusal of the major AI labs to fully quantify their energy usage. The best data we've had on this still comes from Mistral's report last July and even that lacked key data such as the breakdown between energy usage for training vs inference.
Claude Code was made available to the general public in May 2025. Today, Claude Code’s run-rate revenue has grown to over $2.5 billion; this figure has more than doubled since the beginning of 2026. The number of weekly active Claude Code users has also doubled since January 1 [six weeks ago].
— Anthropic, announcing their $30 billion series G
Introducing GPT‑5.3‑Codex‑Spark. OpenAI announced a partnership with Cerebras on January 14th. Four weeks later they're already launching the first integration, "an ultra-fast model for real-time coding in Codex".
Despite being named GPT-5.3-Codex-Spark it's not purely an accelerated alternative to GPT-5.3-Codex - the blog post calls it "a smaller version of GPT‑5.3-Codex" and clarifies that "at launch, Codex-Spark has a 128k context window and is text-only."
I had some preview access to this model and I can confirm that it's significantly faster than their other models.
Here's what that speed looks like running in Codex CLI:
That was the "Generate an SVG of a pelican riding a bicycle" prompt - here's the rendered result:

Compare that to the speed of regular GPT-5.3 Codex medium:
Significantly slower, but the pelican is a lot better:

What's interesting about this model isn't the quality though, it's the speed. When a model responds this fast you can stay in flow state and iterate with the model much more productively.
I showed a demo of Cerebras running Llama 3.1 70 B at 2,000 tokens/second against Val Town back in October 2024. OpenAI claim 1,000 tokens/second for their new model, and I expect it will prove to be a ferociously useful partner for hands-on iterative coding sessions.
It's not yet clear what the pricing will look like for this new model.
Feb. 13, 2026
The evolution of OpenAI’s mission statement

As a USA 501(c)(3) the OpenAI non-profit has to file a tax return each year with the IRS. One of the required fields on that tax return is to “Briefly describe the organization’s mission or most significant activities”—this has actual legal weight to it as the IRS can use it to evaluate if the organization is sticking to its mission and deserves to maintain its non-profit tax-exempt status.
[... 680 words]Someone asked if there was an Anthropic equivalent to OpenAI's IRS mission statements over time.
Anthropic are a "public benefit corporation" but not a non-profit, so they don't have the same requirements to file public documents with the IRS every year.
But when I asked Claude it ran a search and dug up this Google Drive folder where Zach Stein-Perlman shared Certificate of Incorporation documents he obtained from the State of Delaware!
Anthropic's are much less interesting that OpenAI's. The earliest document from 2021 states:
The specific public benefit that the Corporation will promote is to responsibly develop and maintain advanced Al for the cultural, social and technological improvement of humanity.
Every subsequent document up to 2024 uses an updated version which says:
The specific public benefit that the Corporation will promote is to responsibly develop and maintain advanced AI for the long term benefit of humanity.
Feb. 14, 2026
The retreat challenged the narrative that AI eliminates the need for junior developers. Juniors are more profitable than they have ever been. AI tools get them past the awkward initial net-negative phase faster. They serve as a call option on future productivity. And they are better at AI tools than senior engineers, having never developed the habits and assumptions that slow adoption.
The real concern is mid-level engineers who came up during the decade-long hiring boom and may not have developed the fundamentals needed to thrive in the new environment. This population represents the bulk of the industry by volume, and retraining them is genuinely difficult. The retreat discussed whether apprenticeship models, rotation programs and lifelong learning structures could address this gap, but acknowledged that no organization has solved it yet.
— Thoughtworks, findings from a retreat concerning "the future of software engineering", conducted under Chatham House rules
Someone has to prompt the Claudes, talk to customers, coordinate with other teams, decide what to build next. Engineering is changing and great engineers are more important than ever.
— Boris Cherny, Claude Code creator, on why Anthropic are still hiring developers
Feb. 15, 2026
Launching Interop 2026. Jake Archibald reports on Interop 2026, the initiative between Apple, Google, Igalia, Microsoft, and Mozilla to collaborate on ensuring a targeted set of web platform features reach cross-browser parity over the course of the year.
I hadn't realized how influential and successful the Interop series has been. It started back in 2021 as Compat 2021 before being rebranded to Interop in 2022.
The dashboards for each year can be seen here, and they demonstrate how wildly effective the program has been: 2021, 2022, 2023, 2024, 2025, 2026.
Here's the progress chart for 2025, which shows every browser vendor racing towards a 95%+ score by the end of the year:
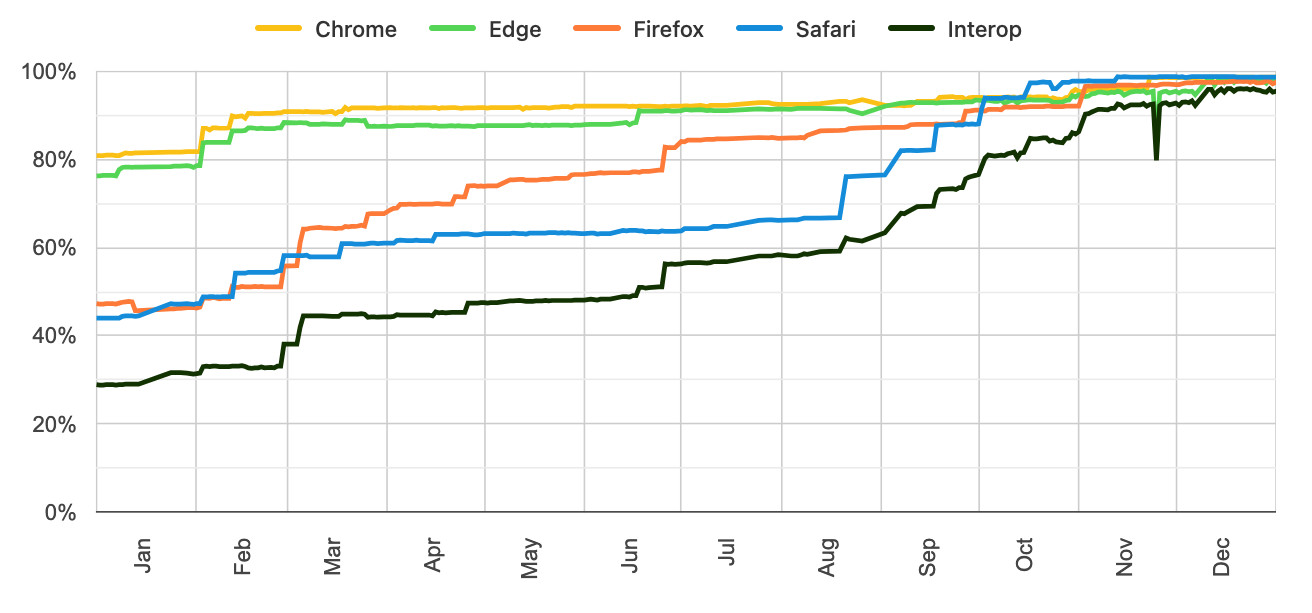
The feature I'm most excited about in 2026 is Cross-document View Transitions, building on the successful 2025 target of Same-Document View Transitions. This will provide fancy SPA-style transitions between pages on websites with no JavaScript at all.
As a keen WebAssembly tinkerer I'm also intrigued by this one:
JavaScript Promise Integration for Wasm allows WebAssembly to asynchronously 'suspend', waiting on the result of an external promise. This simplifies the compilation of languages like C/C++ which expect APIs to run synchronously.
How Generative and Agentic AI Shift Concern from Technical Debt to Cognitive Debt (via) This piece by Margaret-Anne Storey is the best explanation of the term cognitive debt I've seen so far.
Cognitive debt, a term gaining traction recently, instead communicates the notion that the debt compounded from going fast lives in the brains of the developers and affects their lived experiences and abilities to “go fast” or to make changes. Even if AI agents produce code that could be easy to understand, the humans involved may have simply lost the plot and may not understand what the program is supposed to do, how their intentions were implemented, or how to possibly change it.
Margaret-Anne expands on this further with an anecdote about a student team she coached:
But by weeks 7 or 8, one team hit a wall. They could no longer make even simple changes without breaking something unexpected. When I met with them, the team initially blamed technical debt: messy code, poor architecture, hurried implementations. But as we dug deeper, the real problem emerged: no one on the team could explain why certain design decisions had been made or how different parts of the system were supposed to work together. The code might have been messy, but the bigger issue was that the theory of the system, their shared understanding, had fragmented or disappeared entirely. They had accumulated cognitive debt faster than technical debt, and it paralyzed them.
I've experienced this myself on some of my more ambitious vibe-code-adjacent projects. I've been experimenting with prompting entire new features into existence without reviewing their implementations and, while it works surprisingly well, I've found myself getting lost in my own projects.
I no longer have a firm mental model of what they can do and how they work, which means each additional feature becomes harder to reason about, eventually leading me to lose the ability to make confident decisions about where to go next.
I saw yet another “CSS is a massively bloated mess” whine and I’m like. My dude. My brother in Chromium. It is trying as hard as it can to express the totality of visual presentation and layout design and typography and animation and digital interactivity and a few other things in a human-readable text format. It’s not bloated, it’s fantastically ambitious. Its reach is greater than most of us can hope to grasp. Put some respect on its name.
It's wild that the first commit to OpenClaw was on November 25th 2025, and less than three months later it's hit 10,000 commits from 600 contributors, attracted 196,000 GitHub stars and sort-of been featured in an extremely vague Super Bowl commercial for AI.com.
Quoting AI.com founder Kris Marszalek, purchaser of the most expensive domain in history for $70m:
ai.com is the world’s first easy-to-use and secure implementation of OpenClaw, the open source agent framework that went viral two weeks ago; we made it easy to use without any technical skills, while hardening security to keep your data safe.
Looks like vaporware to me - all you can do right now is reserve a handle - but it's still remarkable to see an open source project get to that level of hype in such a short space of time.
Update: OpenClaw creator Peter Steinberger just announced that he's joining OpenAI and plans to transfer ownership of OpenClaw to a new independent foundation.
Gwtar: a static efficient single-file HTML format (via) Fascinating new project from Gwern Branwen and Said Achmiz that targets the challenge of combining large numbers of assets into a single archived HTML file without that file being inconvenient to view in a browser.
The key trick it uses is to fire window.stop() early in the page to prevent the browser from downloading the whole thing, then following that call with inline tar uncompressed content.
It can then make HTTP range requests to fetch content from that tar data on-demand when it is needed by the page.
The JavaScript that has already loaded rewrites asset URLs to point to https://localhost/ purely so that they will fail to load. Then it uses a PerformanceObserver to catch those attempted loads:
let perfObserver = new PerformanceObserver((entryList, observer) => {
resourceURLStringsHandler(entryList.getEntries().map(entry => entry.name));
});
perfObserver.observe({ entryTypes: [ "resource" ] });
That resourceURLStringsHandler callback finds the resource if it is already loaded or fetches it with an HTTP range request otherwise and then inserts the resource in the right place using a blob: URL.
Here's what the window.stop() portion of the document looks like if you view the source:
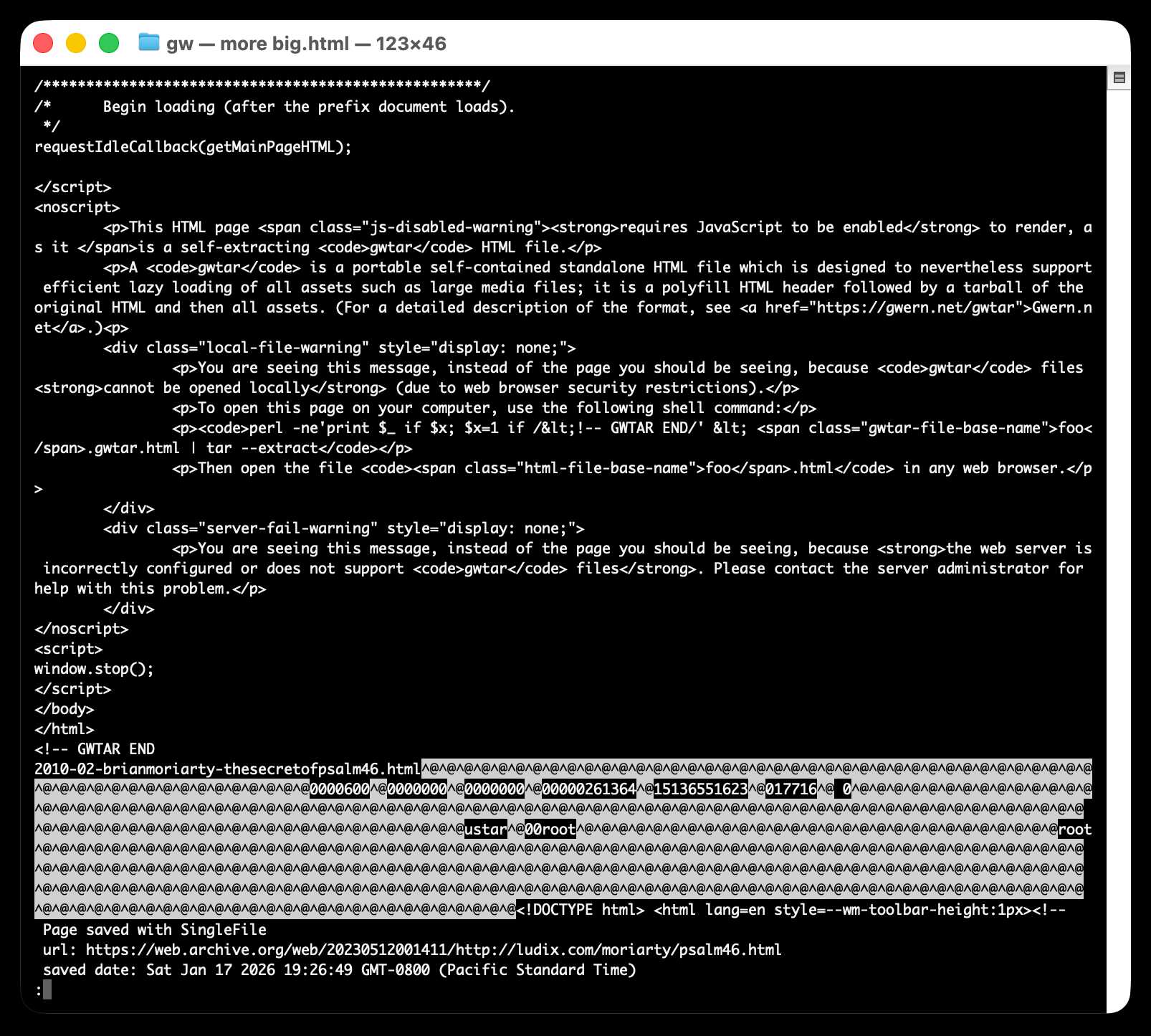
Amusingly for an archive format it doesn't actually work if you open the file directly on your own computer. Here's what you see if you try to do that:
You are seeing this message, instead of the page you should be seeing, because
gwtarfiles cannot be opened locally (due to web browser security restrictions).To open this page on your computer, use the following shell command:
perl -ne'print $_ if $x; $x=1 if /<!-- GWTAR END/' < foo.gwtar.html | tar --extractThen open the file
foo.htmlin any web browser.
Deep Blue

We coined a new term on the Oxide and Friends podcast last month (primary credit to Adam Leventhal) covering the sense of psychological ennui leading into existential dread that many software developers are feeling thanks to the encroachment of generative AI into their field of work.
[... 971 words]