Thursday, 22nd January 2026
Most people's mental model of Claude Code is that "it's just a TUI" but it should really be closer to "a small game engine".
For each frame our pipeline constructs a scene graph with React then:
-> layout elements
-> rasterize them to a 2d screen
-> diff that against the previous screen
-> finally use the diff to generate ANSI sequences to drawWe have a ~16ms frame budget so we have roughly ~5ms to go from the React scene graph to ANSI written.
— Chris Lloyd, Claude Code team at Anthropic
Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation (via) I haven't been paying much attention to the state-of-the-art in speech generation models other than noting that they've got really good, so I can't speak for how notable this new release from Qwen is.
From the accompanying paper:
In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of- the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis [...]. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
To give an idea of size, Qwen/Qwen3-TTS-12Hz-1.7B-Base is 4.54GB on Hugging Face and Qwen/Qwen3-TTS-12Hz-0.6B-Base is 2.52GB.
The Hugging Face demo lets you try out the 0.6B and 1.7B models for free in your browser, including voice cloning:
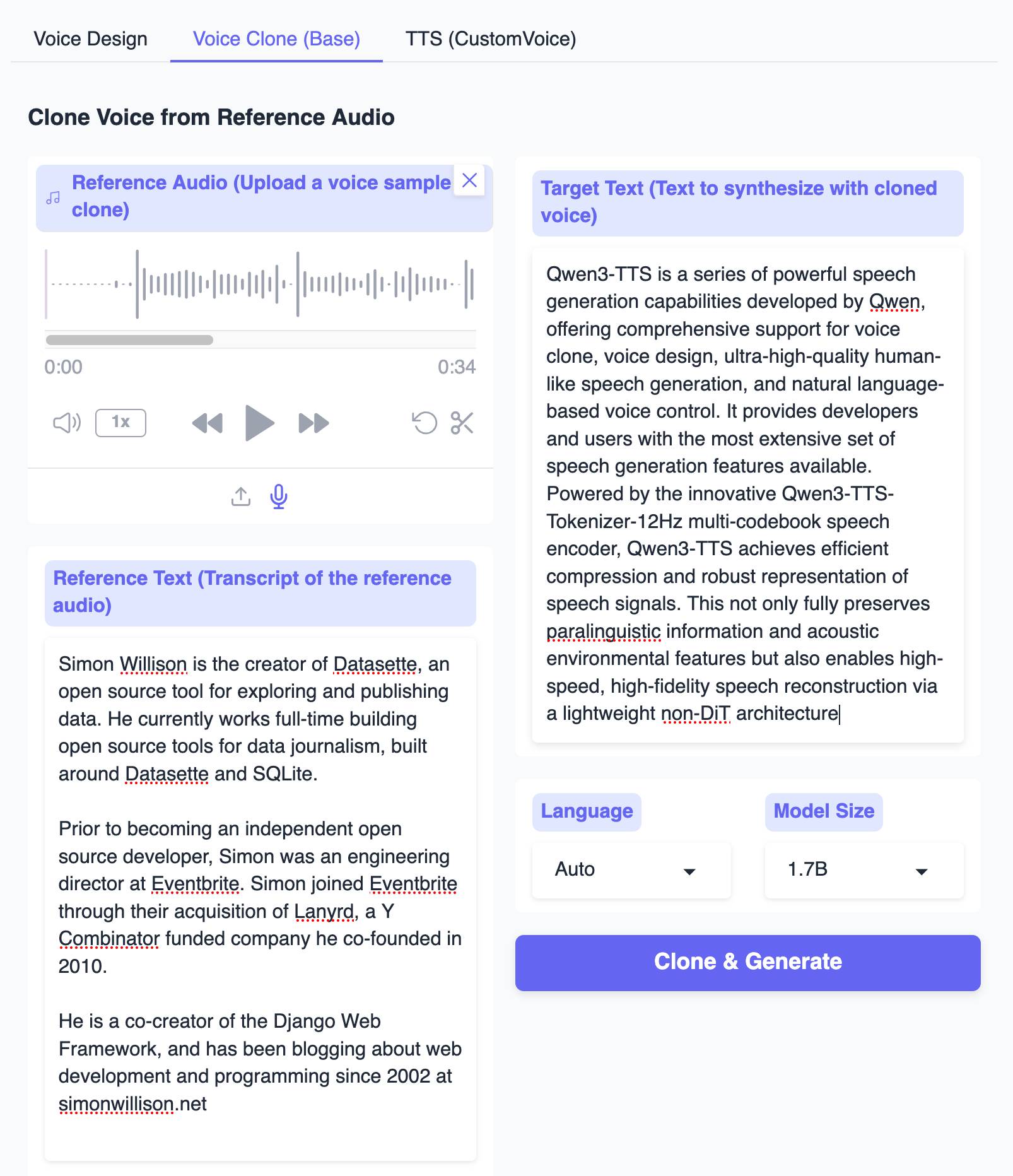
I tried this out by recording myself reading my about page and then having Qwen3-TTS generate audio of me reading the Qwen3-TTS announcement post. Here's the result:
It's important that everyone understands that voice cloning is now something that's available to anyone with a GPU and a few GBs of VRAM... or in this case a web browser that can access Hugging Face.
Update: Prince Canuma got this working with his mlx-audio library. I had Claude turn that into a CLI tool which you can run with uv ike this:
uv run https://tools.simonwillison.net/python/q3_tts.py \
'I am a pirate, give me your gold!' \
-i 'gruff voice' -o pirate.wav
The -i option lets you use a prompt to describe the voice it should use. On first run this downloads a 4.5GB model file from Hugging Face.
SSH has no Host header (via) exe.dev is a new hosting service that, for $20/month, gives you up to 25 VMs "that share 2 CPUs and 8GB RAM". Everything happens over SSH, including creating new VMs. Once configured you can sign into your exe.dev VMs like this:
ssh simon.exe.dev
Here's the clever bit: when you run the above command exe.dev signs you into your VM of that name... but they don't assign every VM its own IP address and SSH has no equivalent of the Host header, so how does their load balancer know which of your VMs to forward you on to?
The answer is that while they don't assign a unique IP to every VM they do have enough IPs that they can ensure each of your VMs has an IP that is unique to your account.
If I create two VMs they will each resolve to a separate IP address, each of which is shared with many other users. The underlying infrastructure then identifies my user account from my SSH public key and can determine which underlying VM to forward my SSH traffic to.