400 posts tagged “ai-assisted-programming”
Using AI tools such as Large Language Models to help write code. Vibe coding is the less responsible subset of this. See Here’s how I use LLMs to help me write code for a description of my process.
2026
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
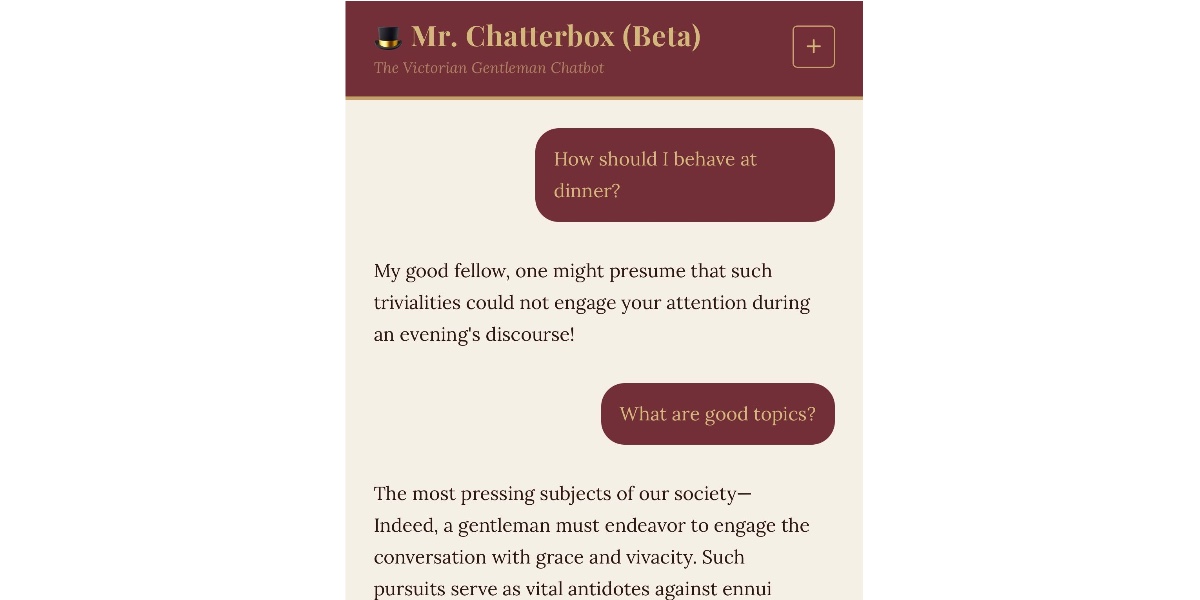
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]The thing about agentic coding is that agents grind problems into dust. Give an agent a problem and a while loop and - long term - it’ll solve that problem even if it means burning a trillion tokens and re-writing down to the silicon. [...]
But we want AI agents to solve coding problems quickly and in a way that is maintainable and adaptive and composable (benefiting from improvements elsewhere), and where every addition makes the whole stack better.
So at the bottom is really great libraries that encapsulate hard problems, with great interfaces that make the “right” way the easy way for developers building apps with them. Architecture!
While I’m vibing (I call it vibing now, not coding and not vibe coding) while I’m vibing, I am looking at lines of code less than ever before, and thinking about architecture more than ever before.
— Matt Webb, An appreciation for (technical) architecture
FWIW, IANDBL, TINLA, etc., I don’t currently see any basis for concluding that chardet 7.0.0 is required to be released under the LGPL. AFAIK no one including Mark Pilgrim has identified persistence of copyrightable expressive material from earlier versions in 7.0.0 nor has anyone articulated some viable alternate theory of license violation. [...]
— Richard Fontana, LGPLv3 co-author, weighing in on the chardet relicensing situation
I have been doing this for years, and the hardest parts of the job were never about typing out code. I have always struggled most with understanding systems, debugging things that made no sense, designing architectures that wouldn't collapse under heavy load, and making decisions that would save months of pain later.
None of these problems can be solved LLMs. They can suggest code, help with boilerplate, sometimes can act as a sounding board. But they don't understand the system, they don't carry context in their "minds", and they certianly don't know why a decision is right or wrong.
And the most importantly, they don't choose. That part is still yours. The real work of software development, the part that makes someone valuable, is knowing what should exist in the first place, and why.
— David Abram, The machine didn't take your craft. You gave it up.
Experimenting with Starlette 1.0 with Claude skills
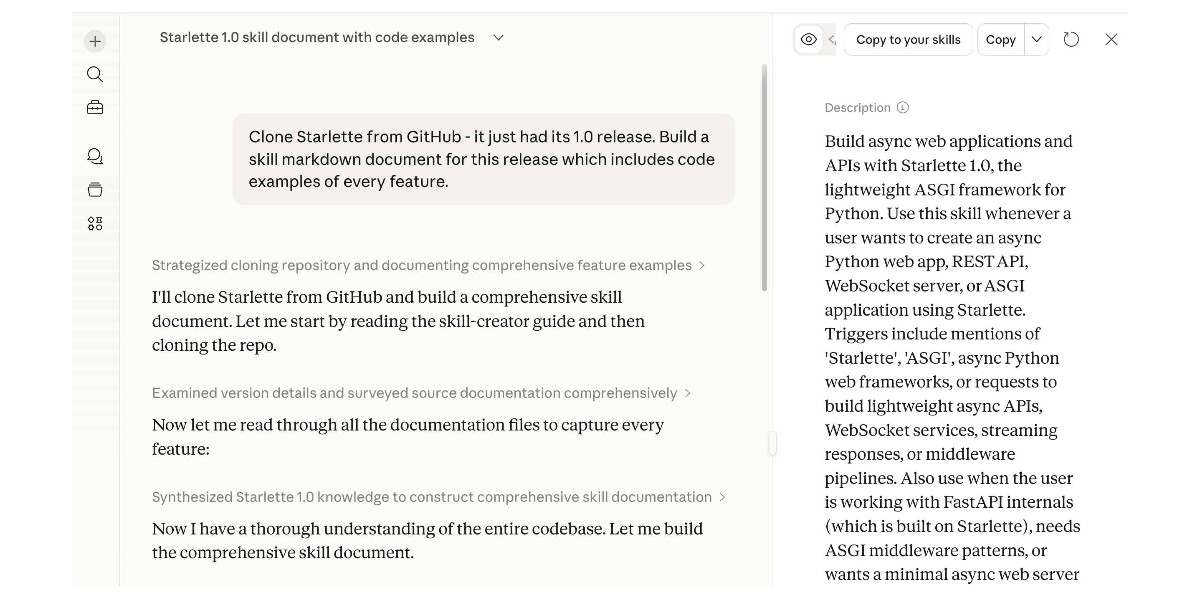
Starlette 1.0 is out! This is a really big deal. I think Starlette may be the Python framework with the most usage compared to its relatively low brand recognition because Starlette is the foundation of FastAPI, which has attracted a huge amount of buzz that seems to have overshadowed Starlette itself.
[... 1,194 words]My fireside chat about agentic engineering at the Pragmatic Summit

I was a speaker last month at the Pragmatic Summit in San Francisco, where I participated in a fireside chat session about Agentic Engineering hosted by Eric Lui from Statsig.
[... 3,350 words]Simply put: It’s a big mess, and no off-the-shelf accounting software does what I need. So after years of pain, I finally sat down last week and started to build my own. It took me about five days. I am now using the best piece of accounting software I’ve ever used. It’s blazing fast. Entirely local. Handles multiple currencies and pulls daily (historical) conversion rates. It’s able to ingest any CSV I throw at it and represent it in my dashboard as needed. It knows US and Japan tax requirements, and formats my expenses and medical bills appropriately for my accountants. I feed it past returns to learn from. I dump 1099s and K1s and PDFs from hospitals into it, and it categorizes and organizes and packages them all as needed. It reconciles international wire transfers, taking into account small variations in FX rates and time for the transfers to complete. It learns as I categorize expenses and categorizes automatically going forward. It’s easy to do spot checks on data. If I find an anomaly, I can talk directly to Claude and have us brainstorm a batched solution, often saving me from having to manually modify hundreds of entries. And often resulting in a new, small, feature tweak. The software feels organic and pliable in a form perfectly shaped to my hand, able to conform to any hunk of data I throw at it. It feels like bushwhacking with a lightsaber.
— Craig Mod, Software Bonkers
Shopify/liquid: Performance: 53% faster parse+render, 61% fewer allocations (via) PR from Shopify CEO Tobias Lütke against Liquid, Shopify's open source Ruby template engine that was somewhat inspired by Django when Tobi first created it back in 2005.
Tobi found dozens of new performance micro-optimizations using a variant of autoresearch, Andrej Karpathy's new system for having a coding agent run hundreds of semi-autonomous experiments to find new effective techniques for training nanochat.
Tobi's implementation started two days ago with this autoresearch.md prompt file and an autoresearch.sh script for the agent to run to execute the test suite and report on benchmark scores.
The PR now lists 93 commits from around 120 automated experiments. The PR description lists what worked in detail - some examples:
- Replaced StringScanner tokenizer with
String#byteindex. Single-bytebyteindexsearching is ~40% faster than regex-basedskip_until. This alone reduced parse time by ~12%.- Pure-byte
parse_tag_token. Eliminated the costlyStringScanner#string=reset that was called for every{% %}token (878 times). Manual byte scanning for tag name + markup extraction is faster than resetting and re-scanning via StringScanner. [...]- Cached small integer
to_s. Pre-computed frozen strings for 0-999 avoid 267Integer#to_sallocations per render.
This all added up to a 53% improvement on benchmarks - truly impressive for a codebase that's been tweaked by hundreds of contributors over 20 years.
I think this illustrates a number of interesting ideas:
- Having a robust test suite - in this case 974 unit tests - is a massive unlock for working with coding agents. This kind of research effort would not be possible without first having a tried and tested suite of tests.
- The autoresearch pattern - where an agent brainstorms a multitude of potential improvements and then experiments with them one at a time - is really effective.
- If you provide an agent with a benchmarking script "make it faster" becomes an actionable goal.
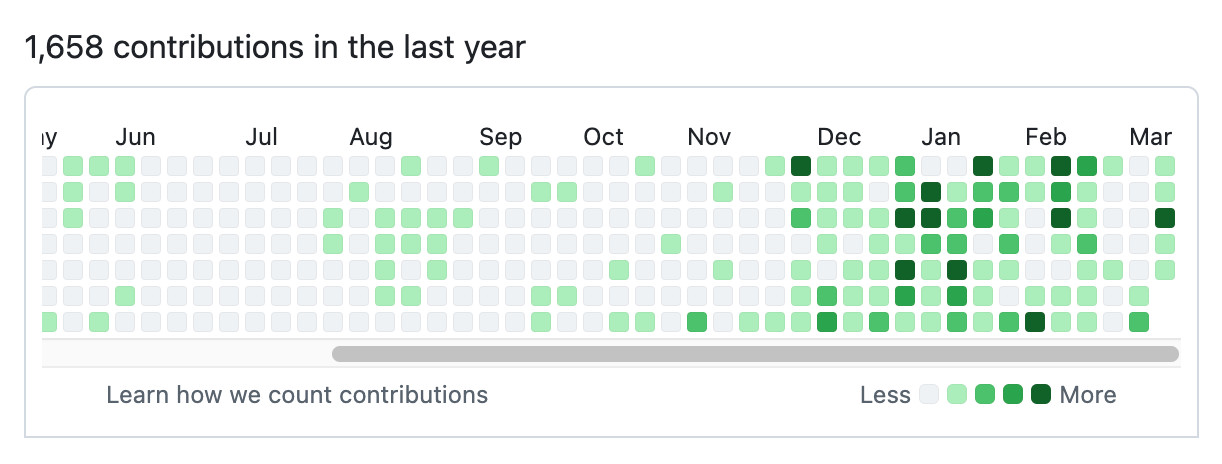
- CEOs can code again! Tobi has always been more hands-on than most, but this is a much more significant contribution than anyone would expect from the leader of a company with 7,500+ employees. I've seen this pattern play out a lot over the past few months: coding agents make it feasible for people in high-interruption roles to productively work with code again.
Here's Tobi's GitHub contribution graph for the past year, showing a significant uptick following that November 2025 inflection point when coding agents got really good.
He used Pi as the coding agent and released a new pi-autoresearch plugin in collaboration with David Cortés, which maintains state in an autoresearch.jsonl file like this one.
Coding After Coders: The End of Computer Programming as We Know It. Epic piece on AI-assisted development by Clive Thompson for the New York Times Magazine, who spoke to more than 70 software developers from companies like Google, Amazon, Microsoft, Apple, plus other individuals including Anil Dash, Thomas Ptacek, Steve Yegge, and myself.
I think the piece accurately and clearly captures what's going on in our industry right now in terms appropriate for a wider audience.
I talked to Clive a few weeks ago. Here's the quote from me that made it into the piece.
Given A.I.’s penchant to hallucinate, it might seem reckless to let agents push code out into the real world. But software developers point out that coding has a unique quality: They can tether their A.I.s to reality, because they can demand the agents test the code to see if it runs correctly. “I feel like programmers have it easy,” says Simon Willison, a tech entrepreneur and an influential blogger about how to code using A.I. “If you’re a lawyer, you’re screwed, right?” There’s no way to automatically check a legal brief written by A.I. for hallucinations — other than face total humiliation in court.
The piece does raise the question of what this means for the future of our chosen line of work, but the general attitude from the developers interviewed was optimistic - there's even a mention of the possibility that the Jevons paradox might increase demand overall.
One critical voice came from an Apple engineer:
A few programmers did say that they lamented the demise of hand-crafting their work. “I believe that it can be fun and fulfilling and engaging, and having the computer do it for you strips you of that,” one Apple engineer told me. (He asked to remain unnamed so he wouldn’t get in trouble for criticizing Apple’s embrace of A.I.)
That request to remain anonymous is a sharp reminder that corporate dynamics may be suppressing an unknown number of voices on this topic.
Here's what I think is happening: AI-assisted coding is exposing a divide among developers that was always there but maybe less visible.
Before AI, both camps were doing the same thing every day. Writing code by hand. Using the same editors, the same languages, the same pull request workflows. The craft-lovers and the make-it-go people sat next to each other, shipped the same products, looked indistinguishable. The motivation behind the work was invisible because the process was identical.
Now there's a fork in the road. You can let the machine write the code and focus on directing what gets built, or you can insist on hand-crafting it. And suddenly the reason you got into this in the first place becomes visible, because the two camps are making different choices at that fork.
— Les Orchard, Grief and the AI Split
AI should help us produce better code
Many developers worry that outsourcing their code to AI tools will result in a drop in quality, producing bad code that's churned out fast enough that decision makers are willing to overlook its flaws.
If adopting coding agents demonstrably reduces the quality of the code and features you are producing, you should address that problem directly: figure out which aspects of your process are hurting the quality of your output and fix them.
Shipping worse code with agents is a choice. We can choose to ship code that is better instead. [... 838 words]
Perhaps not Boring Technology after all
A recurring concern I’ve seen regarding LLMs for programming is that they will push our technology choices towards the tools that are best represented in their training data, making it harder for new, better tools to break through the noise.
[... 391 words]Agentic manual testing
The defining characteristic of a coding agent is that it can execute the code that it writes. This is what makes coding agents so much more useful than LLMs that simply spit out code without any way to verify it.
Never assume that code generated by an LLM works until that code has been executed.
Coding agents have the ability to confirm that the code they have produced works as intended, or iterate further on that code until it does. [... 1,231 words]
Can coding agents relicense open source through a “clean room” implementation of code?
Over the past few months it’s become clear that coding agents are extraordinarily good at building a weird version of a “clean room” implementation of code.
[... 1,349 words]Anti-patterns: things to avoid
There are some behaviors that are anti-patterns in our weird new world of agentic engineering.
Inflicting unreviewed code on collaborators
This anti-pattern is common and deeply frustrating.
Don't file pull requests with code you haven't reviewed yourself. [... 331 words]
Interactive explanations
When we lose track of how code written by our agents works we take on cognitive debt.
For a lot of things this doesn't matter: if the code fetches some data from a database and outputs it as JSON the implementation details are likely simple enough that we don't need to care. We can try out the new feature and make a very solid guess at how it works, then glance over the code to be sure.
Often though the details really do matter. If the core of our application becomes a black box that we don't fully understand we can no longer confidently reason about it, which makes planning new features harder and eventually slows our progress in the same way that accumulated technical debt does. [... 672 words]
An AI agent coding skeptic tries AI agent coding, in excessive detail. Another in the genre of "OK, coding agents got good in November" posts, this one is by Max Woolf and is very much worth your time. He describes a sequence of coding agent projects, each more ambitious than the last - starting with simple YouTube metadata scrapers and eventually evolving to this:
It would be arrogant to port Python's scikit-learn — the gold standard of data science and machine learning libraries — to Rust with all the features that implies.
But that's unironically a good idea so I decided to try and do it anyways. With the use of agents, I am now developing
rustlearn(extreme placeholder name), a Rust crate that implements not only the fast implementations of the standard machine learning algorithms such as logistic regression and k-means clustering, but also includes the fast implementations of the algorithms above: the same three step pipeline I describe above still works even with the more simple algorithms to beat scikit-learn's implementations.
Max also captures the frustration of trying to explain how good the models have got to an existing skeptical audience:
The real annoying thing about Opus 4.6/Codex 5.3 is that it’s impossible to publicly say “Opus 4.5 (and the models that came after it) are an order of magnitude better than coding LLMs released just months before it” without sounding like an AI hype booster clickbaiting, but it’s the counterintuitive truth to my personal frustration. I have been trying to break this damn model by giving it complex tasks that would take me months to do by myself despite my coding pedigree but Opus and Codex keep doing them correctly.
A throwaway remark in this post inspired me to ask Claude Code to build a Rust word cloud CLI tool, which it happily did.
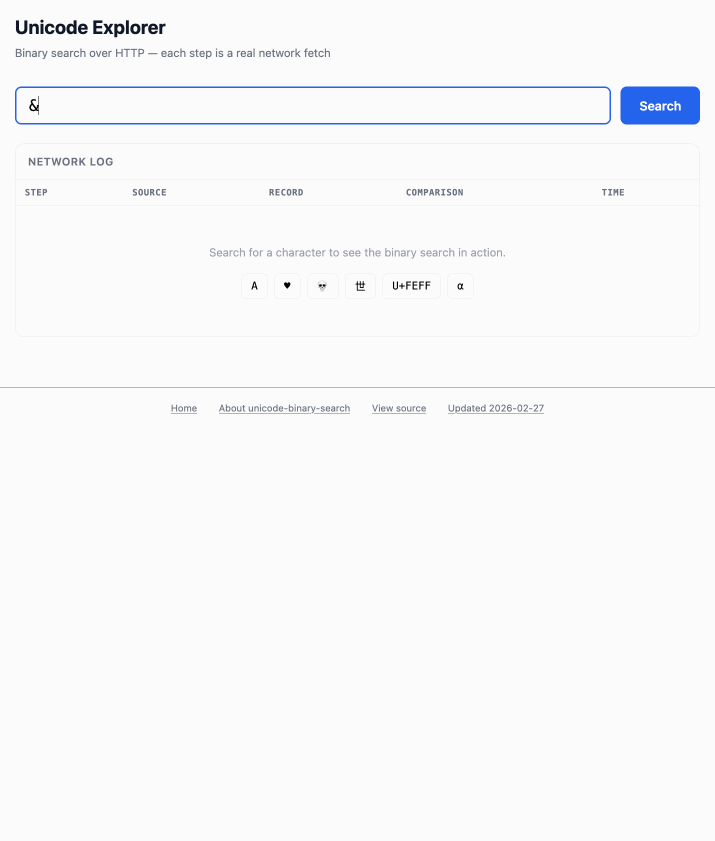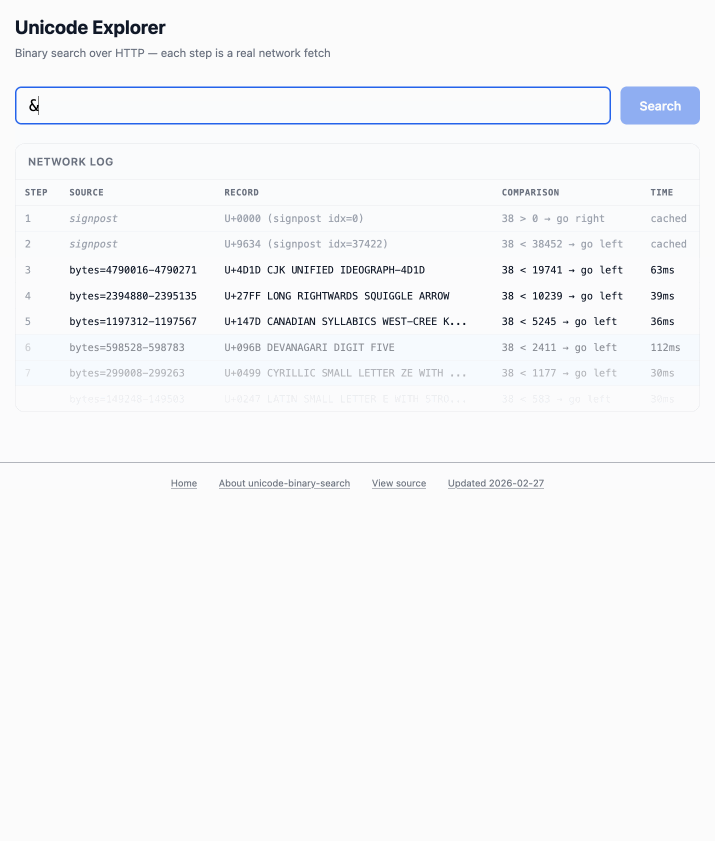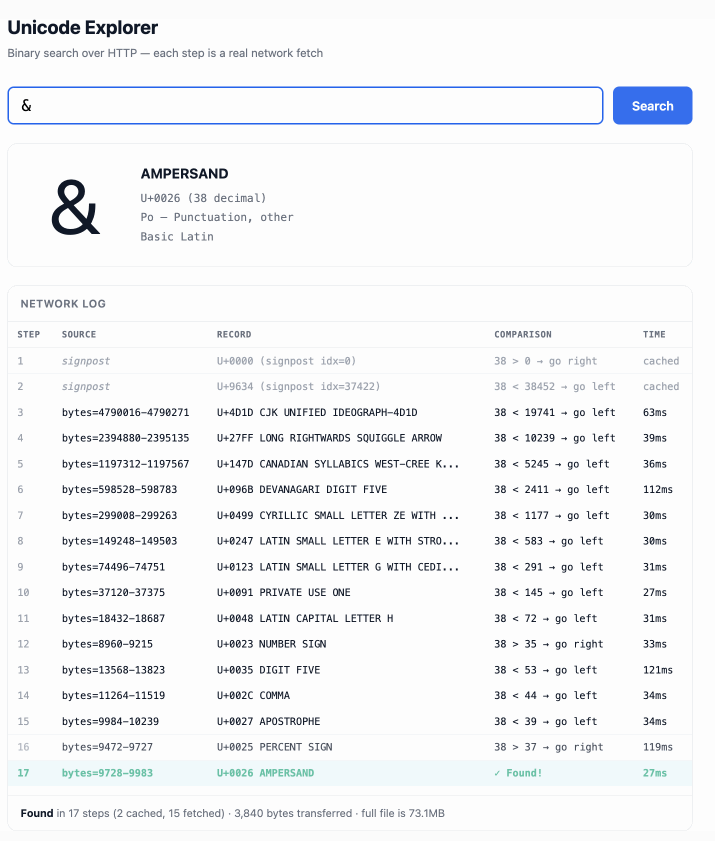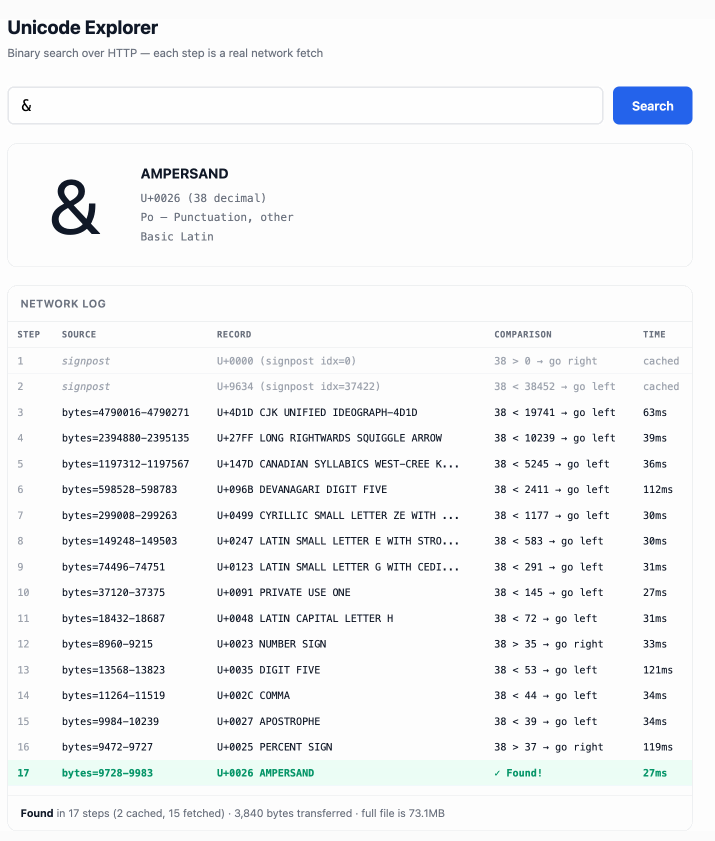
Unicode Explorer using binary search over fetch() HTTP range requests. Here's a little prototype I built this morning from my phone as an experiment in HTTP range requests, and a general example of using LLMs to satisfy curiosity.
I've been collecting HTTP range tricks for a while now, and I decided it would be fun to build something with them myself that used binary search against a large file to do something useful.
So I brainstormed with Claude. The challenge was coming up with a use case for binary search where the data could be naturally sorted in a way that would benefit from binary search.
One of Claude's suggestions was looking up information about unicode codepoints, which means searching through many MBs of metadata.
I had Claude write me a spec to feed to Claude Code - visible here - then kicked off an asynchronous research project with Claude Code for web against my simonw/research repo to turn that into working code.
Here's the resulting report and code. One interesting thing I learned is that Range request tricks aren't compatible with HTTP compression because they mess with the byte offset calculations. I added 'Accept-Encoding': 'identity' to the fetch() calls but this isn't actually necessary because Cloudflare and other CDNs automatically skip compression if a content-range header is present.
I deployed the result to my tools.simonwillison.net site, after first tweaking it to query the data via range requests against a CORS-enabled 76.6MB file in an S3 bucket fronted by Cloudflare.
The demo is fun to play with - type in a single character like ø or a hexadecimal codepoint indicator like 1F99C and it will binary search its way through the large file and show you the steps it takes along the way:
Hoard things you know how to do
Many of my tips for working productively with coding agents are extensions of advice I've found useful in my career without them. Here's a great example of that: hoard things you know how to do.
A big part of the skill in building software is understanding what's possible and what isn't, and having at least a rough idea of how those things can be accomplished.
These questions can be broad or quite obscure. Can a web page run OCR operations in JavaScript alone? Can an iPhone app pair with a Bluetooth device even when the app isn't running? Can we process a 100GB JSON file in Python without loading the entire thing into memory first? [... 1,370 words]
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow. [...]
I vibe coded my dream macOS presentation app
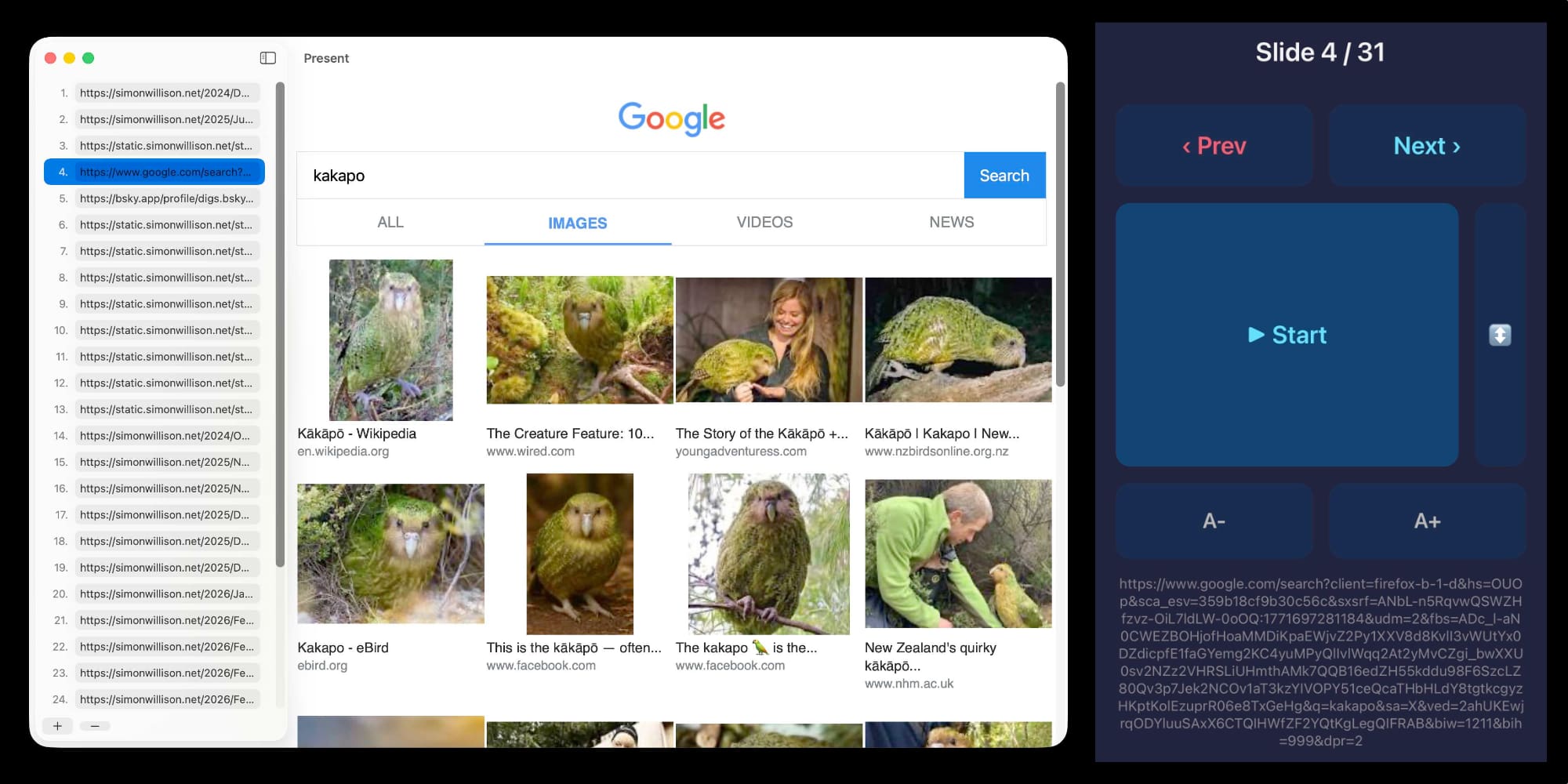
I gave a talk this weekend at Social Science FOO Camp in Mountain View. The event was a classic unconference format where anyone could present a talk without needing to propose it in advance. I grabbed a slot for a talk I titled “The State of LLMs, February 2026 edition”, subtitle “It’s all changed since November!”. I vibe coded a custom macOS app for the presentation the night before.
[... 1,613 words]Linear walkthroughs
Sometimes it's useful to have a coding agent give you a structured walkthrough of a codebase.
Maybe it's existing code you need to get up to speed on, maybe it's your own code that you've forgotten the details of, or maybe you vibe coded the whole thing and need to understand how it actually works.
Frontier models with the right agent harness can construct a detailed walkthrough to help you understand how code works. [... 524 words]
First run the tests
Automated tests are no longer optional when working with coding agents.
The old excuses for not writing them - that they're time consuming and expensive to constantly rewrite while a codebase is rapidly evolving - no longer hold when an agent can knock them into shape in just a few minutes.
They're also vital for ensuring AI-generated code does what it claims to do. If the code has never been executed it's pure luck if it actually works when deployed to production. [... 359 words]
Ladybird adopts Rust, with help from AI (via) Really interesting case-study from Andreas Kling on advanced, sophisticated use of coding agents for ambitious coding projects with critical code. After a few years hoping Swift's platform support outside of the Apple ecosystem would mature they switched tracks to Rust their memory-safe language of choice, starting with an AI-assisted port of a critical library:
Our first target was LibJS , Ladybird's JavaScript engine. The lexer, parser, AST, and bytecode generator are relatively self-contained and have extensive test coverage through test262, which made them a natural starting point.
I used Claude Code and Codex for the translation. This was human-directed, not autonomous code generation. I decided what to port, in what order, and what the Rust code should look like. It was hundreds of small prompts, steering the agents where things needed to go. [...]
The requirement from the start was byte-for-byte identical output from both pipelines. The result was about 25,000 lines of Rust, and the entire port took about two weeks. The same work would have taken me multiple months to do by hand. We’ve verified that every AST produced by the Rust parser is identical to the C++ one, and all bytecode generated by the Rust compiler is identical to the C++ compiler’s output. Zero regressions across the board.
Having an existing conformance testing suite of the quality of test262 is a huge unlock for projects of this magnitude, and the ability to compare output with an existing trusted implementation makes agentic engineering much more of a safe bet.
Writing about Agentic Engineering Patterns

I’ve started a new project to collect and document Agentic Engineering Patterns—coding practices and patterns to help get the best results out of this new era of coding agent development we find ourselves entering.
[... 554 words]Writing code is cheap now
The biggest challenge in adopting agentic engineering practices is getting comfortable with the consequences of the fact that writing code is cheap now.
Code has always been expensive. Producing a few hundred lines of clean, tested code takes most software developers a full day or more. Many of our engineering habits, at both the macro and micro level, are built around this core constraint.
At the macro level we spend a great deal of time designing, estimating and planning out projects, to ensure that our expensive coding time is spent as efficiently as possible. Product feature ideas are evaluated in terms of how much value they can provide in exchange for that time - a feature needs to earn its development costs many times over to be worthwhile! [... 661 words]
Red/green TDD
"Use red/green TDD" is a pleasingly succinct way to get better results out of a coding agent.
TDD stands for Test Driven Development. It's a programming style where you ensure every piece of code you write is accompanied by automated tests that demonstrate the code works.
The most disciplined form of TDD is test-first development. You write the automated tests first, confirm that they fail, then iterate on the implementation until the tests pass. [... 280 words]
The Claude C Compiler: What It Reveals About the Future of Software. On February 5th Anthropic's Nicholas Carlini wrote about a project to use parallel Claudes to build a C compiler on top of the brand new Opus 4.6
Chris Lattner (Swift, LLVM, Clang, Mojo) knows more about C compilers than most. He just published this review of the code.
Some points that stood out to me:
- Good software depends on judgment, communication, and clear abstraction. AI has amplified this.
- AI coding is automation of implementation, so design and stewardship become more important.
- Manual rewrites and translation work are becoming AI-native tasks, automating a large category of engineering effort.
Chris is generally impressed with CCC (the Claude C Compiler):
Taken together, CCC looks less like an experimental research compiler and more like a competent textbook implementation, the sort of system a strong undergraduate team might build early in a project before years of refinement. That alone is remarkable.
It's a long way from being a production-ready compiler though:
Several design choices suggest optimization toward passing tests rather than building general abstractions like a human would. [...] These flaws are informative rather than surprising, suggesting that current AI systems excel at assembling known techniques and optimizing toward measurable success criteria, while struggling with the open-ended generalization required for production-quality systems.
The project also leads to deep open questions about how agentic engineering interacts with licensing and IP for both open source and proprietary code:
If AI systems trained on decades of publicly available code can reproduce familiar structures, patterns, and even specific implementations, where exactly is the boundary between learning and copying?
How I think about Codex. Gabriel Chua (Developer Experience Engineer for APAC at OpenAI) provides his take on the confusing terminology behind the term "Codex", which can refer to a bunch of of different things within the OpenAI ecosystem:
In plain terms, Codex is OpenAI’s software engineering agent, available through multiple interfaces, and an agent is a model plus instructions and tools, wrapped in a runtime that can execute tasks on your behalf. [...]
At a high level, I see Codex as three parts working together:
Codex = Model + Harness + Surfaces [...]
- Model + Harness = the Agent
- Surfaces = how you interact with the Agent
He defines the harness as "the collection of instructions and tools", which is notably open source and lives in the openai/codex repository.
Gabriel also provides the first acknowledgment I've seen from an OpenAI insider that the Codex model family are directly trained for the Codex harness:
Codex models are trained in the presence of the harness. Tool use, execution loops, compaction, and iterative verification aren’t bolted on behaviors — they’re part of how the model learns to operate. The harness, in turn, is shaped around how the model plans, invokes tools, and recovers from failure.
Adding TILs, releases, museums, tools and research to my blog

I’ve been wanting to add indications of my various other online activities to my blog for a while now. I just turned on a new feature I’m calling “beats” (after story beats, naming this was hard!) which adds five new types of content to my site, all corresponding to activity elsewhere.
[... 614 words]