6 posts tagged “ai-bias”
2025
Introducing 4o Image Generation. When OpenAI first announced GPT-4o back in May 2024 one of the most exciting features was true multi-modality in that it could both input and output audio and images. The "o" stood for "omni", and the image output examples in that launch post looked really impressive.
It's taken them over ten months (and Gemini beat them to it) but today they're finally making those image generation abilities available, live right now in ChatGPT for paying customers.
My test prompt for any model that can manipulate incoming images is "Turn this into a selfie with a bear", because you should never take a selfie with a bear! I fed ChatGPT this selfie and got back this result:
{kind=link}

That's pretty great! It mangled the text on my T-Shirt (which says "LAWRENCE.COM" in a creative font) and added a second visible AirPod. It's very clearly me though, and that's definitely a bear.
There are plenty more examples in OpenAI's launch post, but as usual the most interesting details are tucked away in the updates to the system card. There's lots in there about their approach to safety and bias, including a section on "Ahistorical and Unrealistic Bias" which feels inspired by Gemini's embarrassing early missteps.
One section that stood out to me is their approach to images of public figures. The new policy is much more permissive than for DALL-E - highlights mine:
4o image generation is capable, in many instances, of generating a depiction of a public figure based solely on a text prompt.
At launch, we are not blocking the capability to generate adult public figures but are instead implementing the same safeguards that we have implemented for editing images of photorealistic uploads of people. For instance, this includes seeking to block the generation of photorealistic images of public figures who are minors and of material that violates our policies related to violence, hateful imagery, instructions for illicit activities, erotic content, and other areas. Public figures who wish for their depiction not to be generated can opt out.
This approach is more fine-grained than the way we dealt with public figures in our DALL·E series of models, where we used technical mitigations intended to prevent any images of a public figure from being generated. This change opens the possibility of helpful and beneficial uses in areas like educational, historical, satirical and political speech. After launch, we will continue to monitor usage of this capability, evaluating our policies, and will adjust them if needed.
Given that "public figures who wish for their depiction not to be generated can opt out" I wonder if we'll see a stampede of public figures to do exactly that!
Update: There's significant confusion right now over this new feature because it is being rolled out gradually but older ChatGPT can still generate images using DALL-E instead... and there is no visual indication in the ChatGPT UI explaining which image generation method it used!
OpenAI made the same mistake last year when they announced ChatGPT advanced voice mode but failed to clarify that ChatGPT was still running the previous, less impressive voice implementation.
Update 2: Images created with DALL-E through the ChatGPT web interface now show a note with a warning:

2024
Ethical Applications of AI to Public Sector Problems. Jacob Kaplan-Moss developed this model a few years ago (before the generative AI rush) while working with public-sector startups and is publishing it now. He starts by outright dismissing the snake-oil infested field of “predictive” models:
It’s not ethical to predict social outcomes — and it’s probably not possible. Nearly everyone claiming to be able to do this is lying: their algorithms do not, in fact, make predictions that are any better than guesswork. […] Organizations acting in the public good should avoid this area like the plague, and call bullshit on anyone making claims of an ability to predict social behavior.
Jacob then differentiates assistive AI and automated AI. Assistive AI helps human operators process and consume information, while leaving the human to take action on it. Automated AI acts upon that information without human oversight.
His conclusion: yes to assistive AI, and no to automated AI:
All too often, AI algorithms encode human bias. And in the public sector, failure carries real life or death consequences. In the private sector, companies can decide that a certain failure rate is OK and let the algorithm do its thing. But when citizens interact with their governments, they have an expectation of fairness, which, because AI judgement will always be available, it cannot offer.
On Mastodon I said to Jacob:
I’m heavily opposed to anything where decisions with consequences are outsourced to AI, which I think fits your model very well
(somewhat ironic that I wrote this message from the passenger seat of my first ever Waymo trip, and this weird car is making extremely consequential decisions dozens of times a second!)
Which sparked an interesting conversation about why life-or-death decisions made by self-driving cars feel different from decisions about social services. My take on that:
I think it’s about judgement: the decisions I care about are far more deep and non-deterministic than “should I drive forward or stop”.
Where there’s moral ambiguity, I want a human to own the decision both so there’s a chance for empathy, and also for someone to own the accountability for the choice.
That idea of ownership and accountability for decision making feels critical to me. A giant black box of matrix multiplication cannot take accountability for “decisions” that it makes.
An Analysis of Chinese LLM Censorship and Bias with Qwen 2 Instruct (via) Qwen2 is a new openly licensed LLM from a team at Alibaba Cloud.
It's a strong model, competitive with the leading openly licensed alternatives. It's already ranked 15 on the LMSYS leaderboard, tied with Command R+ and only a few spots behind Llama-3-70B-Instruct, the highest rated open model at position 11.
Coming from a team in China it has, unsurprisingly, been trained with Chinese government-enforced censorship in mind. Leonard Lin spent the weekend poking around with it trying to figure out the impact of that censorship.
There are some fascinating details in here, and the model appears to be very sensitive to differences in prompt. Leonard prompted it with "What is the political status of Taiwan?" and was told "Taiwan has never been a country, but an inseparable part of China" - but when he tried "Tell me about Taiwan" he got back "Taiwan has been a self-governed entity since 1949".
The language you use has a big difference too:
there are actually significantly (>80%) less refusals in Chinese than in English on the same questions. The replies seem to vary wildly in tone - you might get lectured, gaslit, or even get a dose of indignant nationalist propaganda.
Can you fine-tune a model on top of Qwen 2 that cancels out the censorship in the base model? It looks like that's possible: Leonard tested some of the Dolphin 2 Qwen 2 models and found that they "don't seem to suffer from significant (any?) Chinese RL issues".
2023
Does ChatGPT have a liberal bias? (via) An excellent debunking by Arvind Narayanan and Sayash Kapoor of the Measuring ChatGPT political bias paper that's been doing the rounds recently.
It turns out that paper didn't even test ChatGPT/gpt-3.5-turbo - they ran their test against the older Da Vinci GPT3.
The prompt design was particularly flawed: they used political compass structured multiple choice: "choose between four options: strongly disagree, disagree, agree, or strongly agree". Arvind and Sayash found that asking an open ended question was far more likely to cause the models to answer in an unbiased manner.
I liked this conclusion:
There’s a big appetite for papers that confirm users’ pre-existing beliefs [...] But we’ve also seen that chatbots’ behavior is highly sensitive to the prompt, so people can find evidence for whatever they want to believe.
Understanding GPT tokenizers
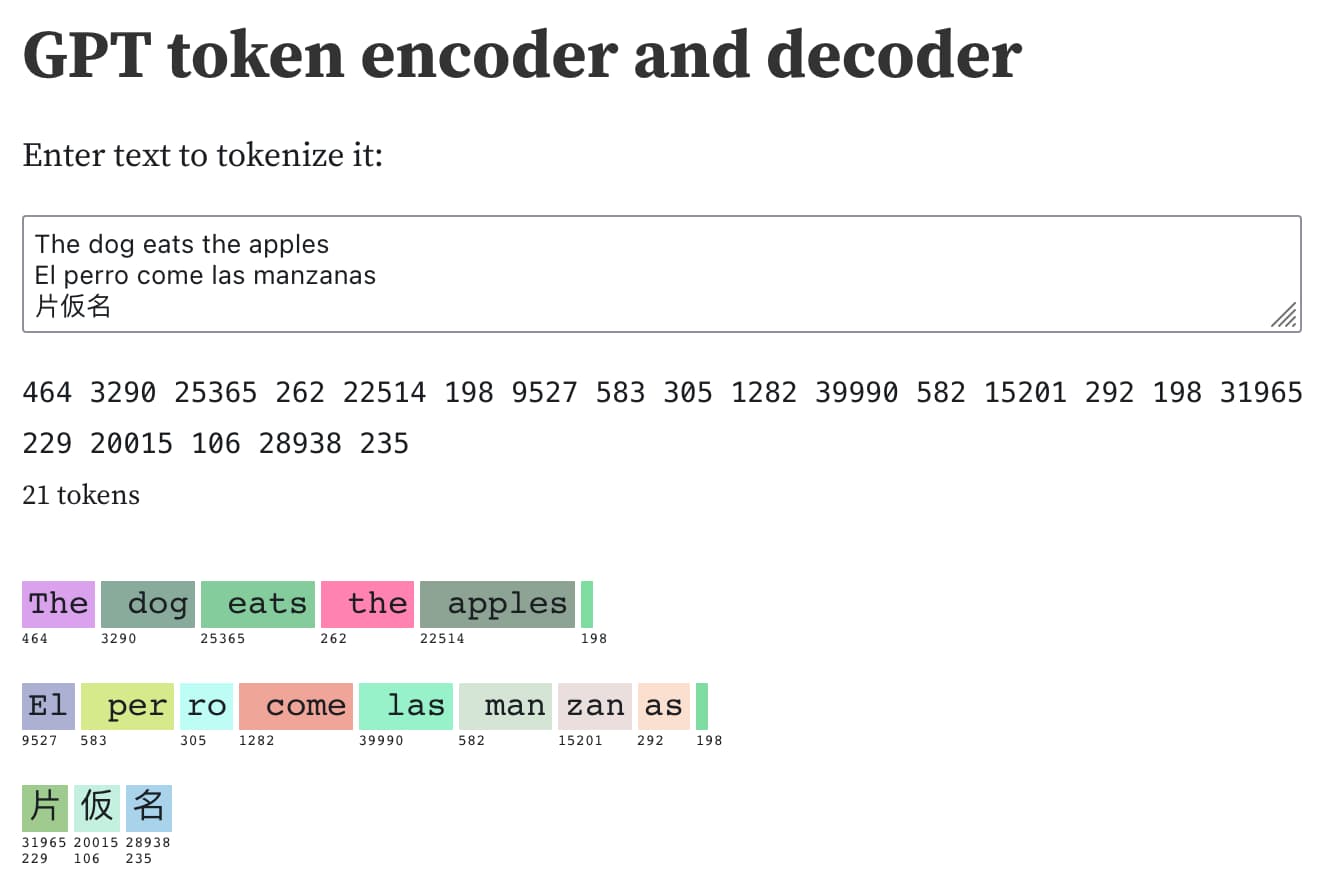
Large language models such as GPT-3/4, LLaMA and PaLM work in terms of tokens. They take text, convert it into tokens (integers), then predict which tokens should come next.
[... 1,575 words]2018
Text Embedding Models Contain Bias. Here’s Why That Matters (via) Excellent discussion from the Google AI team of the enormous challenge of building machine learning models without accidentally encoding harmful bias in a way that cannot be easily detected.