52 posts tagged “atom”
2026
Last month I added a feature I call beats to this blog, pulling in some of my other content from external sources and including it on the homepage, search and various archive pages on the site.
On any given day these frequently outnumber my regular posts. They were looking a little bit thin and were lacking any form of explanation beyond a link, so I've added the ability to annotate them with a "note" which now shows up as part of their display.
Here's what that looks like for the content I published yesterday:
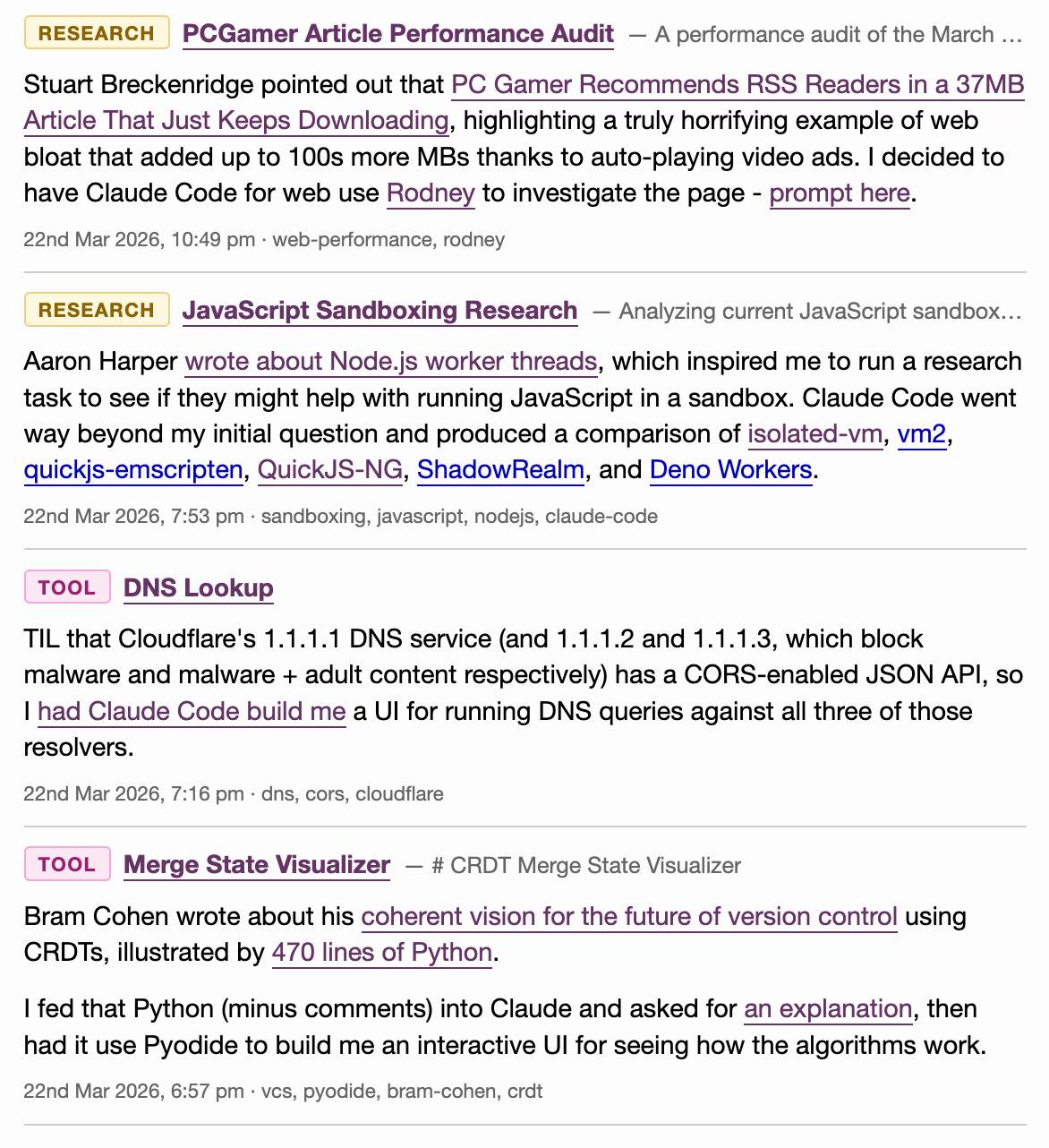
I've also updated the /atom/everything/ Atom feed to include any beats that I've attached notes to.
2025
I was there at the first Atom meeting at the Google offices. We meant so well! And I think the basic publishing spec is good, certainly better technically than the pastiche of different things called RSS.
Alas, a bunch of things then went wrong. Feeds started losing market share. Facebook started doing something useful and interesting that ultimately replaced blog feeds in open formats. The Atom vs RSS spec was at best irrelevant to most people (even programmers) and at worst a confusing market-damaging thing. The XML namespaces in Atom made everyone annoyed. Also there was some confusing “Atom API” for publishing that diluted Atom’s mindshare for feeds.
— Nelson Minar, Comment on lobste.rs
simonw/ollama-models-atom-feed. I setup a GitHub Actions + GitHub Pages Atom feed of scraped recent models data from the Ollama latest models page - Ollama remains one of the easiest ways to run models on a laptop so a new model release from them is worth hearing about.
I built the scraper by pasting example HTML into Claude and asking for a Python script to convert it to Atom - here's the script we wrote together.
Update 25th March 2025: The first version of this included all 160+ models in a single feed. I've upgraded the script to output two feeds - the original atom.xml one and a new atom-recent-20.xml feed containing just the most recent 20 items.
I modified the script using Google's new Gemini 2.5 Pro model, like this:
cat to_atom.py | llm -m gemini-2.5-pro-exp-03-25 \
-s 'rewrite this script so that instead of outputting Atom to stdout it saves two files, one called atom.xml with everything and another called atom-recent-20.xml with just the most recent 20 items - remove the output option entirely'
Here's the full transcript.
Building and deploying a custom site using GitHub Actions and GitHub Pages. I figured out a minimal example of how to use GitHub Actions to run custom scripts to build a website and then publish that static site to GitHub Pages. I turned the example into a template repository, which should make getting started for a new project extremely quick.
I've needed this for various projects over the years, but today I finally put these notes together while setting up a system for scraping the iNaturalist API for recent sightings of the California Brown Pelican and converting those into an Atom feed that I can subscribe to in NetNewsWire:
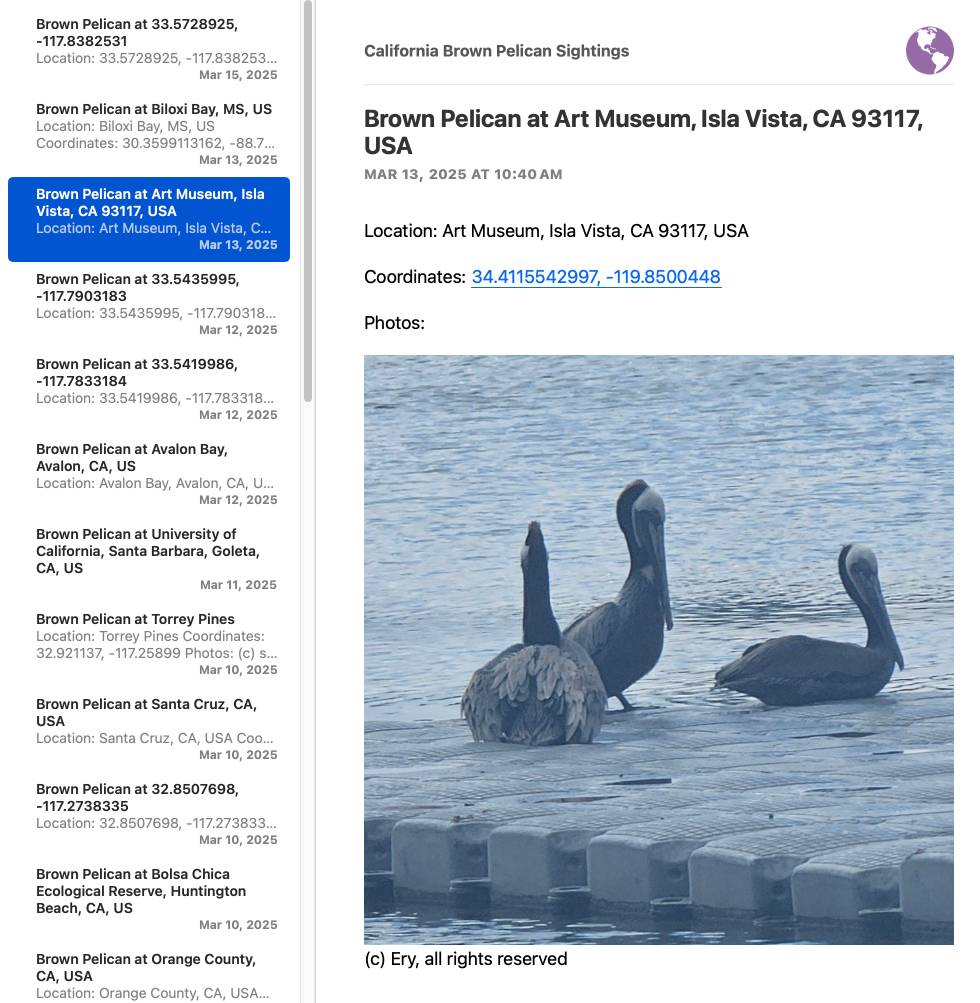
I got Claude to write me the script that converts the scraped JSON to atom.
Update: I just found out iNaturalist have their own atom feeds! Here's their own feed of recent Pelican observations.
2024
Footnotes that work in RSS readers. Chris Coyier explained the mechanism used by Feedbin to render custom footnotes back in 2019.
I stumbled upon this after I spotted an inline footnote rendered in NetNewsWire the other day (from this post by Drew Breunig):
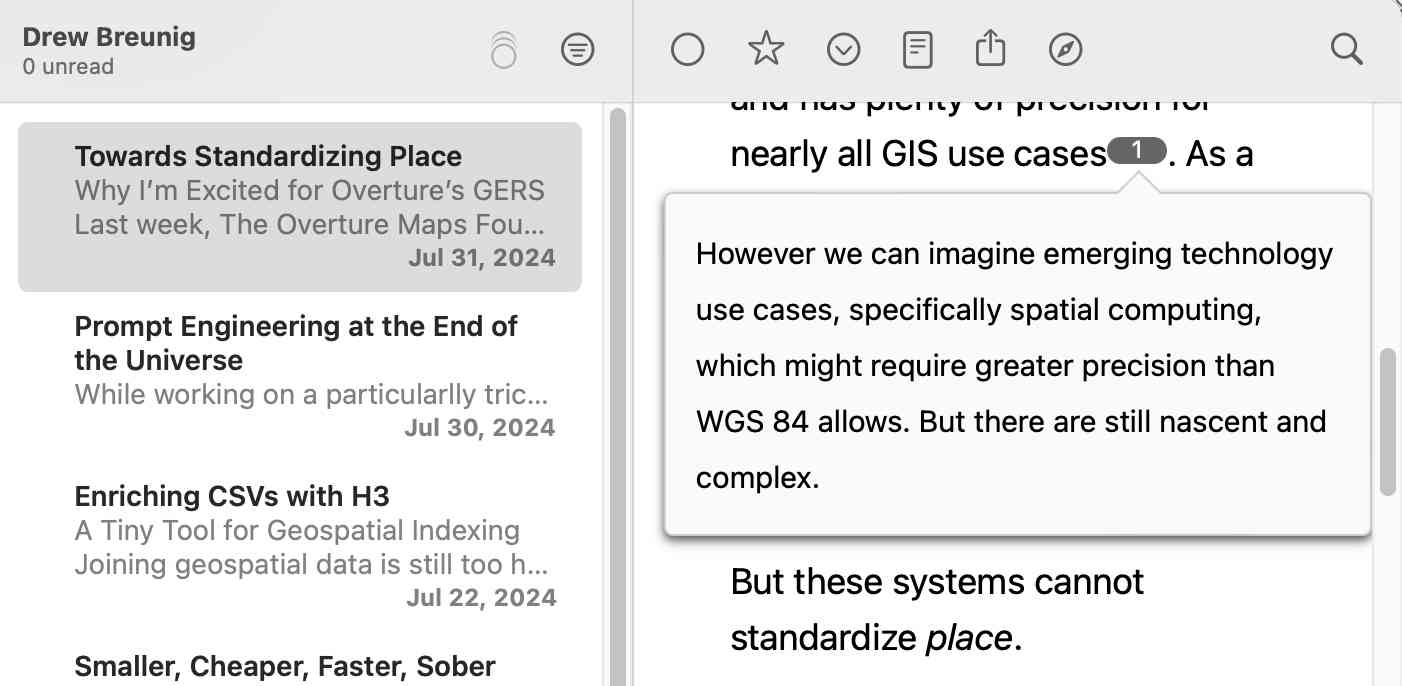
Since feed readers generally strip JavaScript and CSS and only allow a subset of HTML tags I was intrigued to figure out how that worked.
I found this code in the NetNewsWire source (it's MIT licensed) which runs against elements matching this CSS selector:
sup > a[href*='#fn'], sup > div > a[href*='#fn']
So any link with an href attribute containing #fn that is a child of a <sup> (superscript) element.
In Drew's post the HTML looks like this:
<!-- Footnote link: -->
<sup id="fnref:precision" role="doc-noteref">
<a href="#fn:precision" class="footnote" rel="footnote">1</a>
</sup>
<!-- Then at the bottom: -->
<div class="footnotes" role="doc-endnotes">
<ol>
<li id="fn:precision" role="doc-endnote">
<p>This is the footnote.
<a href="#fnref:precision" class="reversefootnote" role="doc-backlink">↩</a>
</p>
</li>
</ol>
</div>
Where did this convention come from? It doesn't seem to be part of any specific standard. Chris linked to www.bigfootjs.com (no longer resolving) which was the site for the bigfoot.js jQuery plugin, so my best guess is the convention came from that.

ooh.directory: A page for every blog. I hadn’t checked in on Phil Gyford’s ooh.directory blog directory since it first launched in November 2022. I’m delighted to see that it’s thriving—2,117 blogs have now been carefully curated, and the latest feature is a page for each blog showing its categories, description, an activity graph and the most recent posts syndicated via RSS/Atom.
2023
2020
Weeknotes: California Protected Areas in Datasette
This week I built a geospatial search engine for protected areas in California, shipped datasette-graphql 1.0 and started working towards the next milestone for Datasette Cloud.
[... 1,099 words]Weeknotes: Datasette 0.43
My main achievement this week was shipping Datasette 0.43, with a collection of smaller improvements and one big one: a redesign of the register_output_renderer plugin hook.
2019
datasette-atom: Define an Atom feed using a custom SQL query
I’ve been having a ton of fun iterating on www.niche-museums.com. I put together some notes on how the site works last week, and I’ve been taking advantage of the Thanksgiving break to continue exploring ways in which Datasette can be used to quickly build database-backed static websites.
[... 1,084 words]Subscribe to my blog on Telegram (via) I created a Telegram bot that’s subscribed to my Atom feed, so if you want to get notifications when I post to my blog you can do that using Telegram now.
2018
How about if, instead of ditching Twitter for Mastodon, we all start blogging and subscribing to each other's Atom feeds again instead? The original distributed social network could still work pretty well if we actually start using it
— @simonw
2009
pubsubhubbub. From Brad Fitzpatrick, a simple but clever way of using web hooks (HTTP callbacks) to inform subscribers that an Atom feed has updated in almost real-time—solving the constant polling problem and making it easier for small sites to offer publish-subscribe APIs. Any Atom feed can delegate subscriber updates to a “hub” server. An example hub server implementation is provided running on App Engine.
A few notes on the Guardian Open Platform
This morning we launched the Guardian Open Platform at a well attended event in our new offices in Kings Place. This is one of the main projects I’ve been helping out with since joining the Guardian last year, and it’s fantastic to finally have it out in the open.
[... 839 words]2008
Magnificent Seven—the value of Atom. The seven core things that Atom solves so that you don’t have to.
FriendFeed Blog: Simple Update Protocol. FriendFeed infamously poll RSS feeds on the 43 services they support millions of times an hour in an effort to keep their content as real-time as possible. SUP is a new proposal by FriendFeed for a sort of “master feed” of changes to a site—instead of hitting the Flickr feed for each of their users they would just poll Flickr’s SUP feed every minute or so to find out who had uploaded a new photo, and only retrieve the RSS feed for those users.
Flickr Developer Blog: API Responses as Feeds (via) Flickr API calls that return a “standard photos response” (e.g. flickr.photos.search and flickr.favorites.getList) can now output eight different feed formats as well, including Atom, RSS flavours, geoatom, geordf and KML. Error codes are returned as X-FlickrErrCode HTTP headers.
RSS Duplicate Detection. “Detecting duplicate items in an RSS feed is something of a black art”. I hadn’t realised quite how involved such a basic function of an aggregator could be.