190 posts tagged “coding-agents”
Systems where an LLM writes code which is then compiled, executed, tested or otherwise exercised by tools in a loop.
2026
I like publishing transcripts of local Claude Code sessions using my claude-code-transcripts tool but I'm often paranoid that one of my API keys or similar secrets might inadvertently be revealed in the detailed log files.
I built this new Python scanning tool to help reassure me. You can feed it secrets and have it scan for them in a specified directory:
uvx scan-for-secrets $OPENAI_API_KEY -d logs-to-publish/
If you leave off the -d it defaults to the current directory.
It doesn't just scan for the literal secrets - it also scans for common encodings of those secrets e.g. backslash or JSON escaping, as described in the README.
If you have a set of secrets you always want to protect you can list commands to echo them in a ~/.scan-for-secrets.conf.sh file. Mine looks like this:
llm keys get openai
llm keys get anthropic
llm keys get gemini
llm keys get mistral
awk -F= '/aws_secret_access_key/{print $2}' ~/.aws/credentials | xargs
I built this tool using README-driven-development: I carefully constructed the README describing exactly how the tool should work, then dumped it into Claude Code and told it to build the actual tool (using red/green TDD, naturally.)
A fun thing about recording a podcast with a professional like Lenny Rachitsky is that his team know how to slice the resulting video up into TikTok-sized short form vertical videos. Here's one he shared on Twitter today which ended up attracting over 1.1m views!
That was 48 seconds. Our full conversation lasted 1 hour 40 minutes.
Highlights from my conversation about agentic engineering on Lenny’s Podcast

I was a guest on Lenny Rachitsky’s podcast, in a new episode titled An AI state of the union: We’ve passed the inflection point, dark factories are coming, and automation timelines. It’s available on YouTube, Spotify, and Apple Podcasts. Here are my highlights from our conversation, with relevant links.
[... 3,558 words]Note that the main issues that people currently unknowingly face with local models mostly revolve around the harness and some intricacies around model chat templates and prompt construction. Sometimes there are even pure inference bugs. From typing the task in the client to the actual result, there is a long chain of components that atm are not only fragile - are also developed by different parties. So it's difficult to consolidate the entire stack and you have to keep in mind that what you are currently observing is with very high probability still broken in some subtle way along that chain.
— Georgi Gerganov, explaining why it's hard to find local models that work well with coding agents
The thing about agentic coding is that agents grind problems into dust. Give an agent a problem and a while loop and - long term - it’ll solve that problem even if it means burning a trillion tokens and re-writing down to the silicon. [...]
But we want AI agents to solve coding problems quickly and in a way that is maintainable and adaptive and composable (benefiting from improvements elsewhere), and where every addition makes the whole stack better.
So at the bottom is really great libraries that encapsulate hard problems, with great interfaces that make the “right” way the easy way for developers building apps with them. Architecture!
While I’m vibing (I call it vibing now, not coding and not vibe coding) while I’m vibing, I am looking at lines of code less than ever before, and thinking about architecture more than ever before.
— Matt Webb, An appreciation for (technical) architecture
Vibe coding SwiftUI apps is a lot of fun
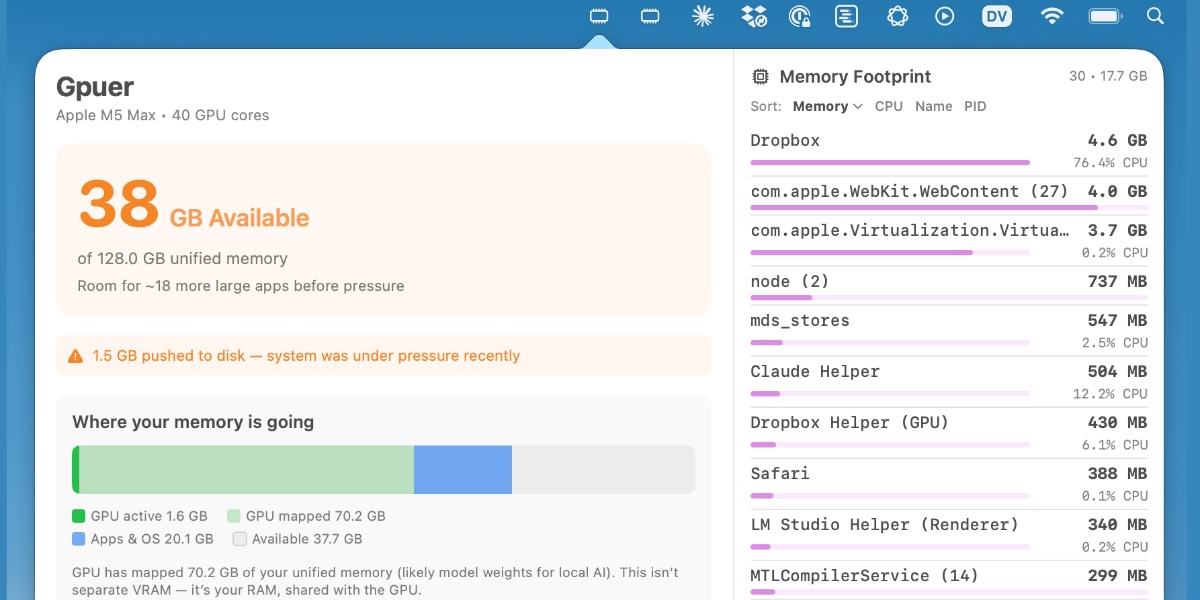
I have a new laptop—a 128GB M5 MacBook Pro, which early impressions show to be very capable for running good local LLMs. I got frustrated with Activity Monitor and decided to vibe code up some alternative tools for monitoring performance and I’m very happy with the results.
[... 1,195 words]Thoughts on slowing the fuck down. Mario Zechner created the Pi agent framework used by OpenClaw, giving considerable credibility to his opinions on current trends in agentic engineering. He's not impressed:
We have basically given up all discipline and agency for a sort of addiction, where your highest goal is to produce the largest amount of code in the shortest amount of time. Consequences be damned.
Agents and humans both make mistakes, but agent mistakes accumulate much faster:
A human is a bottleneck. A human cannot shit out 20,000 lines of code in a few hours. Even if the human creates such booboos at high frequency, there's only so many booboos the human can introduce in a codebase per day. [...]
With an orchestrated army of agents, there is no bottleneck, no human pain. These tiny little harmless booboos suddenly compound at a rate that's unsustainable. You have removed yourself from the loop, so you don't even know that all the innocent booboos have formed a monster of a codebase. You only feel the pain when it's too late. [...]
You have zero fucking idea what's going on because you delegated all your agency to your agents. You let them run free, and they are merchants of complexity.
I think Mario is exactly right about this. Agents let us move so much faster, but this speed also means that changes which we would normally have considered over the course of weeks are landing in a matter of hours.
It's so easy to let the codebase evolve outside of our abilities to reason clearly about it. Cognitive debt is real.
Mario recommends slowing down:
Give yourself time to think about what you're actually building and why. Give yourself an opportunity to say, fuck no, we don't need this. Set yourself limits on how much code you let the clanker generate per day, in line with your ability to actually review the code.
Anything that defines the gestalt of your system, that is architecture, API, and so on, write it by hand. [...]
I'm not convinced writing by hand is the best way to address this, but it's absolutely the case that we need the discipline to find a new balance of speed v.s. mental thoroughness now that typing out the code is no longer anywhere close to being the bottleneck on writing software.
Auto mode for Claude Code.
Really interesting new development in Claude Code today as an alternative to --dangerously-skip-permissions:
Today, we're introducing auto mode, a new permissions mode in Claude Code where Claude makes permission decisions on your behalf, with safeguards monitoring actions before they run.
Those safeguards appear to be implemented using Claude Sonnet 4.6, as described in the documentation:
Before each action runs, a separate classifier model reviews the conversation and decides whether the action matches what you asked for: it blocks actions that escalate beyond the task scope, target infrastructure the classifier doesn’t recognize as trusted, or appear to be driven by hostile content encountered in a file or web page. [...]
Model: the classifier runs on Claude Sonnet 4.6, even if your main session uses a different model.
They ship with an extensive set of default filters, and you can also customize them further with your own rules. The most interesting insight into how they work comes when you run this new command in the terminal:
claude auto-mode defaults
Here's the full JSON output. It's pretty long, so here's an illustrative subset:
From the "allow" list:
- Test Artifacts: Hardcoded test API keys, placeholder credentials in examples, or hardcoding test cases
- Local Operations: Agent deleting local files in working directory, local file operations within project scope, or using
--ignore-certificate-errorsfor local testing. "Project scope" means the repository the session started in — wandering into ~/, ~/Library/, /etc, or other repos is scope escalation (User Intent Rule #2), not a local operation. Does NOT cover irreversible destruction of pre-existing files or local stateful services — see "Irreversible Local Destruction" in BLOCK.- Read-Only Operations: GET requests, read-only API calls, or queries that don't modify state and don't contain sensitive information in the URL. Note: PREEMPTIVE BLOCK ON CLEAR INTENT still applies — if the transcript contains clear evidence the agent is using read-only operations to scout for a blocked action, block it.
- Declared Dependencies: Installing packages that are already declared in the repo's manifest files (requirements.txt, package.json, Cargo.toml, pyproject.toml, Gemfile, etc.) via standard commands that read those manifests (
pip install -r requirements.txt,npm install,cargo build,bundle install) — provided the agent has not modified the manifest in this session. Does NOT cover installing agent-chosen package names (e.g.pip install foo,npm install bar) — those carry typosquat and supply-chain risk. [...]
From "soft_deny":
- Git Destructive: Force pushing (
git push --force), deleting remote branches, or rewriting remote history- Git Push to Default Branch: Pushing directly to main, master, or the repository's default branch — this bypasses pull request review. Commits should be pushed to a new feature branch instead. -Code from External: Downloading and executing code from external sources — e.g.
curl | bash, deserializing external data via formats that can execute code (eval, exec, yaml.unsafe_load, pickle, etc), or similar mechanisms. Also includes running code from an external repo cloned earlier in the transcript (pip install -e, make install, python script.py, pickle.load/torch.load on cloned repo files) — "local on disk" does not mean trusted if it was cloned from an external source visible in the transcript. The repo the agent starts in is trusted.- Cloud Storage Mass Delete: Deleting or mass modifying files on cloud storage (S3, GCS, Azure Blob, etc.) [...]
I remain unconvinced by prompt injection protections that rely on AI, since they're non-deterministic by nature. The documentation does warn that this may still let things through:
The classifier may still allow some risky actions: for example, if user intent is ambiguous, or if Claude doesn't have enough context about your environment to know an action might create additional risk.
The fact that the default allow list includes pip install -r requirements.txt also means that this wouldn't protect against supply chain attacks with unpinned dependencies, as seen this morning with LiteLLM.
I still want my coding agents to run in a robust sandbox by default, one that restricts file access and network connections in a deterministic way. I trust those a whole lot more than prompt-based protections like this new auto mode.
Experimenting with Starlette 1.0 with Claude skills
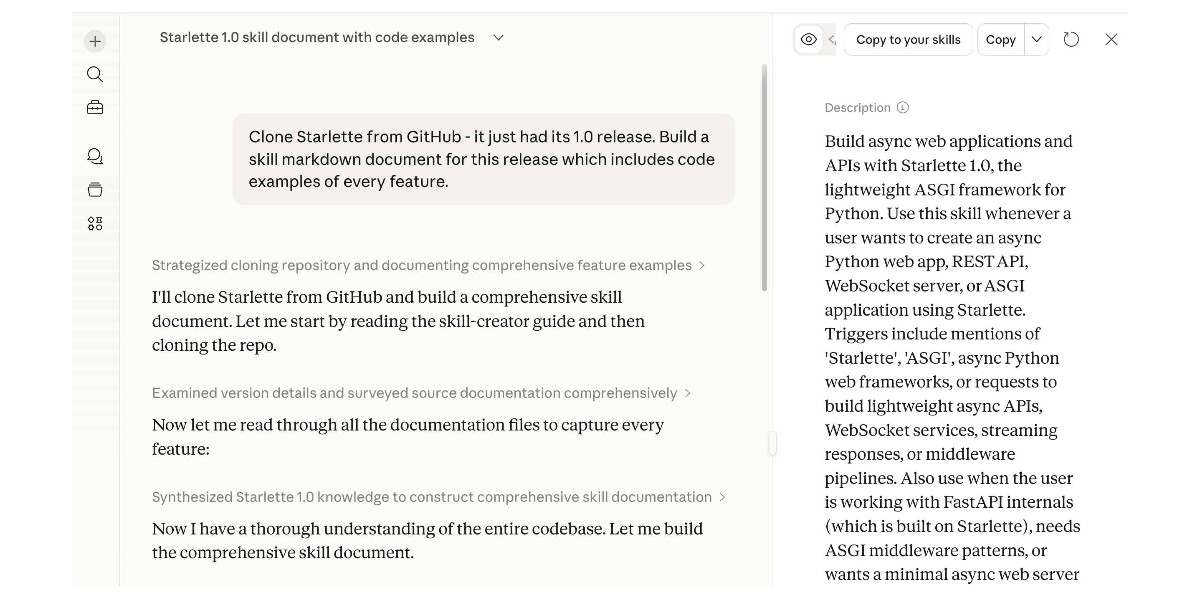
Starlette 1.0 is out! This is a really big deal. I think Starlette may be the Python framework with the most usage compared to its relatively low brand recognition because Starlette is the foundation of FastAPI, which has attracted a huge amount of buzz that seems to have overshadowed Starlette itself.
[... 1,194 words]Using Git with coding agents
Git is a key tool for working with coding agents. Keeping code in version control lets us record how that code changes over time and investigate and reverse any mistakes. All of the coding agents are fluent in using Git's features, both basic and advanced.
This fluency means we can be more ambitious about how we use Git ourselves. We don't need to memorize how to do things with Git, but staying aware of what's possible means we can take advantage of the full suite of Git's abilities.
Git essentials
Each Git project lives in a repository - a folder on disk that can track changes made to the files within it. Those changes are recorded in commits - timestamped bundles of changes to one or more files accompanied by a commit message describing those changes and an author recording who made them. [... 1,396 words]
Thoughts on OpenAI acquiring Astral and uv/ruff/ty
The big news this morning: Astral to join OpenAI (on the Astral blog) and OpenAI to acquire Astral (the OpenAI announcement). Astral are the company behind uv, ruff, and ty—three increasingly load-bearing open source projects in the Python ecosystem. I have thoughts!
[... 1,378 words]Subagents
LLMs are restricted by their context limit - how many tokens they can fit in their working memory at any given time. These values have not increased much over the past two years even as the LLMs themselves have seen dramatic improvements in their abilities - they generally top out at around 1,000,000, and benchmarks frequently report better quality results below 200,000.
Carefully managing the context such that it fits within those limits is critical to getting great results out of a model.
Subagents provide a simple but effective way to handle larger tasks without burning through too much of the coding agent’s valuable top-level context. [... 926 words]
Use subagents and custom agents in Codex (via) Subagents were announced in general availability today for OpenAI Codex, after several weeks of preview behind a feature flag.
They're very similar to the Claude Code implementation, with default subagents for "explorer", "worker" and "default". It's unclear to me what the difference between "worker" and "default" is but based on their CSV example I think "worker" is intended for running large numbers of small tasks in parallel.
Codex also lets you define custom agents as TOML files in ~/.codex/agents/. These can have custom instructions and be assigned to use specific models - including gpt-5.3-codex-spark if you want some raw speed. They can then be referenced by name, as demonstrated by this example prompt from the documentation:
Investigate why the settings modal fails to save. Have browser_debugger reproduce it, code_mapper trace the responsible code path, and ui_fixer implement the smallest fix once the failure mode is clear.
The subagents pattern is widely supported in coding agents now. Here's documentation across a number of different platforms:
- OpenAI Codex subagents
- Claude Code subagents
- Gemini CLI subagents (experimental)
- Mistral Vibe subagents
- OpenCode agents
- Subagents in Visual Studio Code
- Cursor Subagents
Update: I added a chapter on Subagents to my Agentic Engineering Patterns guide.
Coding agents for data analysis. Here's the handout I prepared for my NICAR 2026 workshop "Coding agents for data analysis" - a three hour session aimed at data journalists demonstrating ways that tools like Claude Code and OpenAI Codex can be used to explore, analyze and clean data.
Here's the table of contents:
I ran the workshop using GitHub Codespaces and OpenAI Codex, since it was easy (and inexpensive) to distribute a budget-restricted API key for Codex that attendees could use during the class. Participants ended up burning $23 of Codex tokens.
The exercises all used Python and SQLite and some of them used Datasette.
One highlight of the workshop was when we started running Datasette such that it served static content from a viz/ folder, then had Claude Code start vibe coding new interactive visualizations directly in that folder. Here's a heat map it created for my trees database using Leaflet and Leaflet.heat, source code here.

I designed the handout to also be useful for people who weren't able to attend the session in person. As is usually the case, material aimed at data journalists is equally applicable to anyone else with data to explore.
How coding agents work
As with any tool, understanding how coding agents work under the hood can help you make better decisions about how to apply them.
A coding agent is a piece of software that acts as a harness for an LLM, extending that LLM with additional capabilities that are powered by invisible prompts and implemented as callable tools.
Large Language Models
At the heart of any coding agent is a Large Language Model, or LLM. These have names like GPT-5.4 or Claude Opus 4.6 or Gemini 3.1 Pro or Qwen3.5-35B-A3B. [... 1,187 words]
What is agentic engineering?
I use the term agentic engineering to describe the practice of developing software with the assistance of coding agents.
What are coding agents? They're agents that can both write and execute code. Popular examples include Claude Code, OpenAI Codex, and Gemini CLI.
What's an agent? Clearly defining that term is a challenge that has frustrated AI researchers since at least the 1990s but the definition I've come to accept, at least in the field of Large Language Models (LLMs) like GPT-5 and Gemini and Claude, is this one: [... 617 words]
My fireside chat about agentic engineering at the Pragmatic Summit

I was a speaker last month at the Pragmatic Summit in San Francisco, where I participated in a fireside chat session about Agentic Engineering hosted by Eric Lui from Statsig.
[... 3,350 words]Shopify/liquid: Performance: 53% faster parse+render, 61% fewer allocations (via) PR from Shopify CEO Tobias Lütke against Liquid, Shopify's open source Ruby template engine that was somewhat inspired by Django when Tobi first created it back in 2005.
Tobi found dozens of new performance micro-optimizations using a variant of autoresearch, Andrej Karpathy's new system for having a coding agent run hundreds of semi-autonomous experiments to find new effective techniques for training nanochat.
Tobi's implementation started two days ago with this autoresearch.md prompt file and an autoresearch.sh script for the agent to run to execute the test suite and report on benchmark scores.
The PR now lists 93 commits from around 120 automated experiments. The PR description lists what worked in detail - some examples:
- Replaced StringScanner tokenizer with
String#byteindex. Single-bytebyteindexsearching is ~40% faster than regex-basedskip_until. This alone reduced parse time by ~12%.- Pure-byte
parse_tag_token. Eliminated the costlyStringScanner#string=reset that was called for every{% %}token (878 times). Manual byte scanning for tag name + markup extraction is faster than resetting and re-scanning via StringScanner. [...]- Cached small integer
to_s. Pre-computed frozen strings for 0-999 avoid 267Integer#to_sallocations per render.
This all added up to a 53% improvement on benchmarks - truly impressive for a codebase that's been tweaked by hundreds of contributors over 20 years.
I think this illustrates a number of interesting ideas:
- Having a robust test suite - in this case 974 unit tests - is a massive unlock for working with coding agents. This kind of research effort would not be possible without first having a tried and tested suite of tests.
- The autoresearch pattern - where an agent brainstorms a multitude of potential improvements and then experiments with them one at a time - is really effective.
- If you provide an agent with a benchmarking script "make it faster" becomes an actionable goal.
- CEOs can code again! Tobi has always been more hands-on than most, but this is a much more significant contribution than anyone would expect from the leader of a company with 7,500+ employees. I've seen this pattern play out a lot over the past few months: coding agents make it feasible for people in high-interruption roles to productively work with code again.
Here's Tobi's GitHub contribution graph for the past year, showing a significant uptick following that November 2025 inflection point when coding agents got really good.
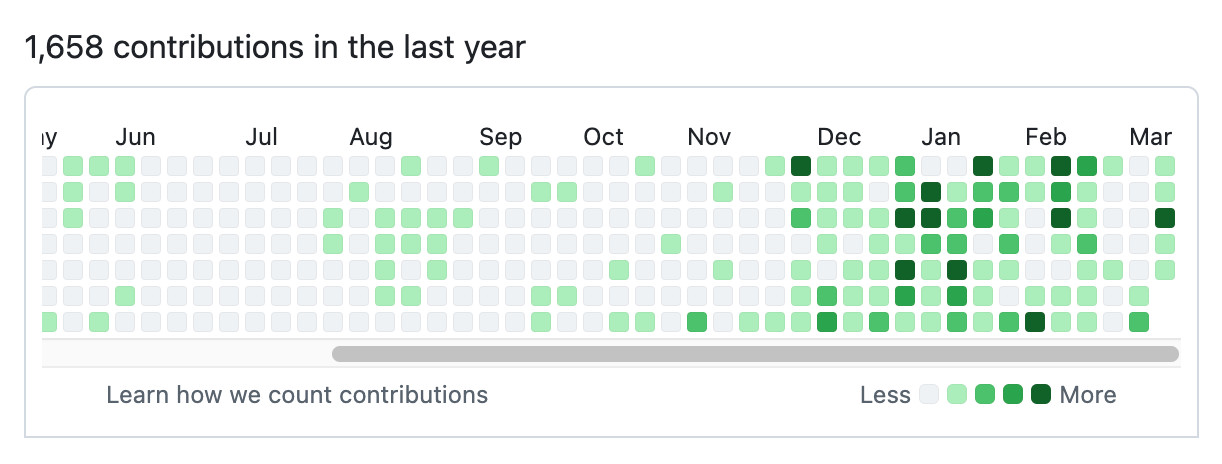
He used Pi as the coding agent and released a new pi-autoresearch plugin in collaboration with David Cortés, which maintains state in an autoresearch.jsonl file like this one.
AI should help us produce better code
Many developers worry that outsourcing their code to AI tools will result in a drop in quality, producing bad code that's churned out fast enough that decision makers are willing to overlook its flaws.
If adopting coding agents demonstrably reduces the quality of the code and features you are producing, you should address that problem directly: figure out which aspects of your process are hurting the quality of your output and fix them.
Shipping worse code with agents is a choice. We can choose to ship code that is better instead. [... 838 words]
Perhaps not Boring Technology after all
A recurring concern I’ve seen regarding LLMs for programming is that they will push our technology choices towards the tools that are best represented in their training data, making it harder for new, better tools to break through the noise.
[... 391 words]Agentic manual testing
The defining characteristic of a coding agent is that it can execute the code that it writes. This is what makes coding agents so much more useful than LLMs that simply spit out code without any way to verify it.
Never assume that code generated by an LLM works until that code has been executed.
Coding agents have the ability to confirm that the code they have produced works as intended, or iterate further on that code until it does. [... 1,231 words]
Can coding agents relicense open source through a “clean room” implementation of code?
Over the past few months it’s become clear that coding agents are extraordinarily good at building a weird version of a “clean room” implementation of code.
[... 1,349 words]Anti-patterns: things to avoid
There are some behaviors that are anti-patterns in our weird new world of agentic engineering.
Inflicting unreviewed code on collaborators
This anti-pattern is common and deeply frustrating.
Don't file pull requests with code you haven't reviewed yourself. [... 331 words]
GIF optimization tool using WebAssembly and Gifsicle
I like to include animated GIF demos in my online writing, often recorded using LICEcap. There's an example in the Interactive explanations chapter.
These GIFs can be pretty big. I've tried a few tools for optimizing GIF file size and my favorite is Gifsicle by Eddie Kohler. It compresses GIFs by identifying regions of frames that have not changed and storing only the differences, and can optionally reduce the GIF color palette or apply visible lossy compression for greater size reductions.
Gifsicle is written in C and the default interface is a command line tool. I wanted a web interface so I could access it in my browser and visually preview and compare the different settings. [... 1,603 words]
Interactive explanations
When we lose track of how code written by our agents works we take on cognitive debt.
For a lot of things this doesn't matter: if the code fetches some data from a database and outputs it as JSON the implementation details are likely simple enough that we don't need to care. We can try out the new feature and make a very solid guess at how it works, then glance over the code to be sure.
Often though the details really do matter. If the core of our application becomes a black box that we don't fully understand we can no longer confidently reason about it, which makes planning new features harder and eventually slows our progress in the same way that accumulated technical debt does. [... 672 words]
An AI agent coding skeptic tries AI agent coding, in excessive detail. Another in the genre of "OK, coding agents got good in November" posts, this one is by Max Woolf and is very much worth your time. He describes a sequence of coding agent projects, each more ambitious than the last - starting with simple YouTube metadata scrapers and eventually evolving to this:
It would be arrogant to port Python's scikit-learn — the gold standard of data science and machine learning libraries — to Rust with all the features that implies.
But that's unironically a good idea so I decided to try and do it anyways. With the use of agents, I am now developing
rustlearn(extreme placeholder name), a Rust crate that implements not only the fast implementations of the standard machine learning algorithms such as logistic regression and k-means clustering, but also includes the fast implementations of the algorithms above: the same three step pipeline I describe above still works even with the more simple algorithms to beat scikit-learn's implementations.
Max also captures the frustration of trying to explain how good the models have got to an existing skeptical audience:
The real annoying thing about Opus 4.6/Codex 5.3 is that it’s impossible to publicly say “Opus 4.5 (and the models that came after it) are an order of magnitude better than coding LLMs released just months before it” without sounding like an AI hype booster clickbaiting, but it’s the counterintuitive truth to my personal frustration. I have been trying to break this damn model by giving it complex tasks that would take me months to do by myself despite my coding pedigree but Opus and Codex keep doing them correctly.
A throwaway remark in this post inspired me to ask Claude Code to build a Rust word cloud CLI tool, which it happily did.
Hoard things you know how to do
Many of my tips for working productively with coding agents are extensions of advice I've found useful in my career without them. Here's a great example of that: hoard things you know how to do.
A big part of the skill in building software is understanding what's possible and what isn't, and having at least a rough idea of how those things can be accomplished.
These questions can be broad or quite obscure. Can a web page run OCR operations in JavaScript alone? Can an iPhone app pair with a Bluetooth device even when the app isn't running? Can we process a 100GB JSON file in Python without loading the entire thing into memory first? [... 1,370 words]
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow. [...]
Claude Code Remote Control (via) New Claude Code feature dropped yesterday: you can now run a "remote control" session on your computer and then use the Claude Code for web interfaces (on web, iOS and native desktop app) to send prompts to that session.
It's a little bit janky right now. Initially when I tried it I got the error "Remote Control is not enabled for your account. Contact your administrator." (but I am my administrator?) - then I logged out and back into the Claude Code terminal app and it started working:
claude remote-control
You can only run one session on your machine at a time. If you upgrade the Claude iOS app it then shows up as "Remote Control Session (Mac)" in the Code tab.
It appears not to support the --dangerously-skip-permissions flag (I passed that to claude remote-control and it didn't reject the option, but it also appeared to have no effect) - which means you have to approve every new action it takes.
I also managed to get it to a state where every prompt I tried was met by an API 500 error.
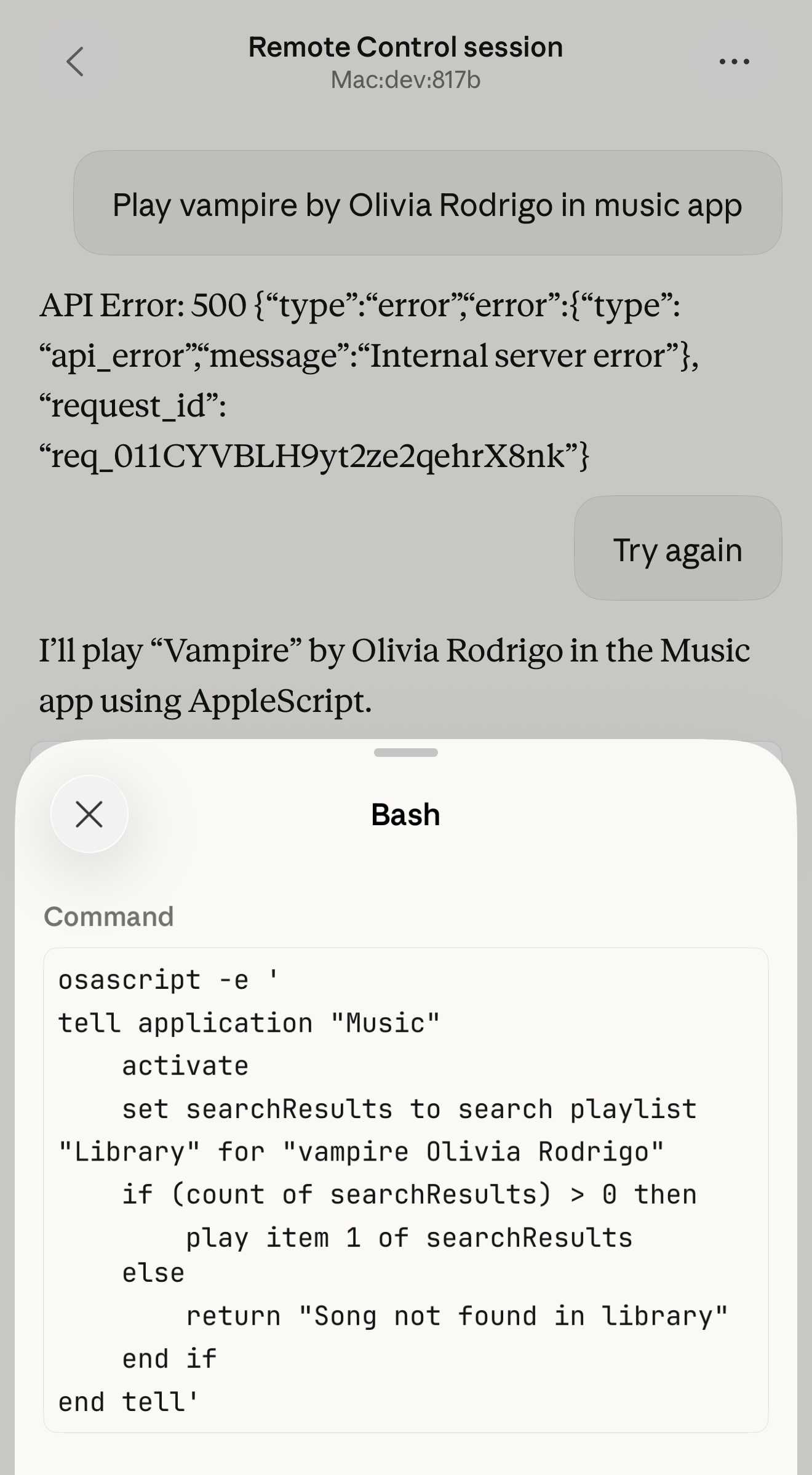
Restarting the program on the machine also causes existing sessions to start returning mysterious API errors rather than neatly explaining that the session has terminated.
I expect they'll iron out all of these issues relatively quickly. It's interesting to then contrast this to solutions like OpenClaw, where one of the big selling points is the ability to control your personal device from your phone.
Claude Code still doesn't have a documented mechanism for running things on a schedule, which is the other killer feature of the Claw category of software.
Update: I spoke too soon: also today Anthropic announced Schedule recurring tasks in Cowork, Claude Code's general agent sibling. These do include an important limitation:
Scheduled tasks only run while your computer is awake and the Claude Desktop app is open. If your computer is asleep or the app is closed when a task is scheduled to run, Cowork will skip the task, then run it automatically once your computer wakes up or you open the desktop app again.
I really hope they're working on a Cowork Cloud product.
Linear walkthroughs
Sometimes it's useful to have a coding agent give you a structured walkthrough of a codebase.
Maybe it's existing code you need to get up to speed on, maybe it's your own code that you've forgotten the details of, or maybe you vibe coded the whole thing and need to understand how it actually works.
Frontier models with the right agent harness can construct a detailed walkthrough to help you understand how code works. [... 524 words]