13 posts tagged “crawling”
2025
Two of my public Datasette instances - for my TILs and my blog's backup mirror - were getting hammered with misbehaving bot traffic today. Scaling them up to more Fly instances got them running again but I'd rather not pay extra just so bots can crawl me harder.
The log files showed the main problem was facets: Datasette provides these by default on the table page, but they can be combined in ways that keep poorly written crawlers busy visiting different variants of the same page over and over again.
So I turned those off. I'm now running those instances with --setting allow_facet off (described here), and my logs are full of lines that look like this. The "400 Bad Request" means a bot was blocked from loading the page:
GET /simonwillisonblog/blog_entry?_facet_date=created&_facet=series_id&_facet_size=max&_facet=extra_head_html&_sort=is_draft&created__date=2012-01-30 HTTP/1.1" 400 Bad Request
Cloudflare Radar: AI Insights (via) Cloudflare launched this dashboard back in February, incorporating traffic analysis from Cloudflare's network along with insights from their popular 1.1.1.1 DNS service.
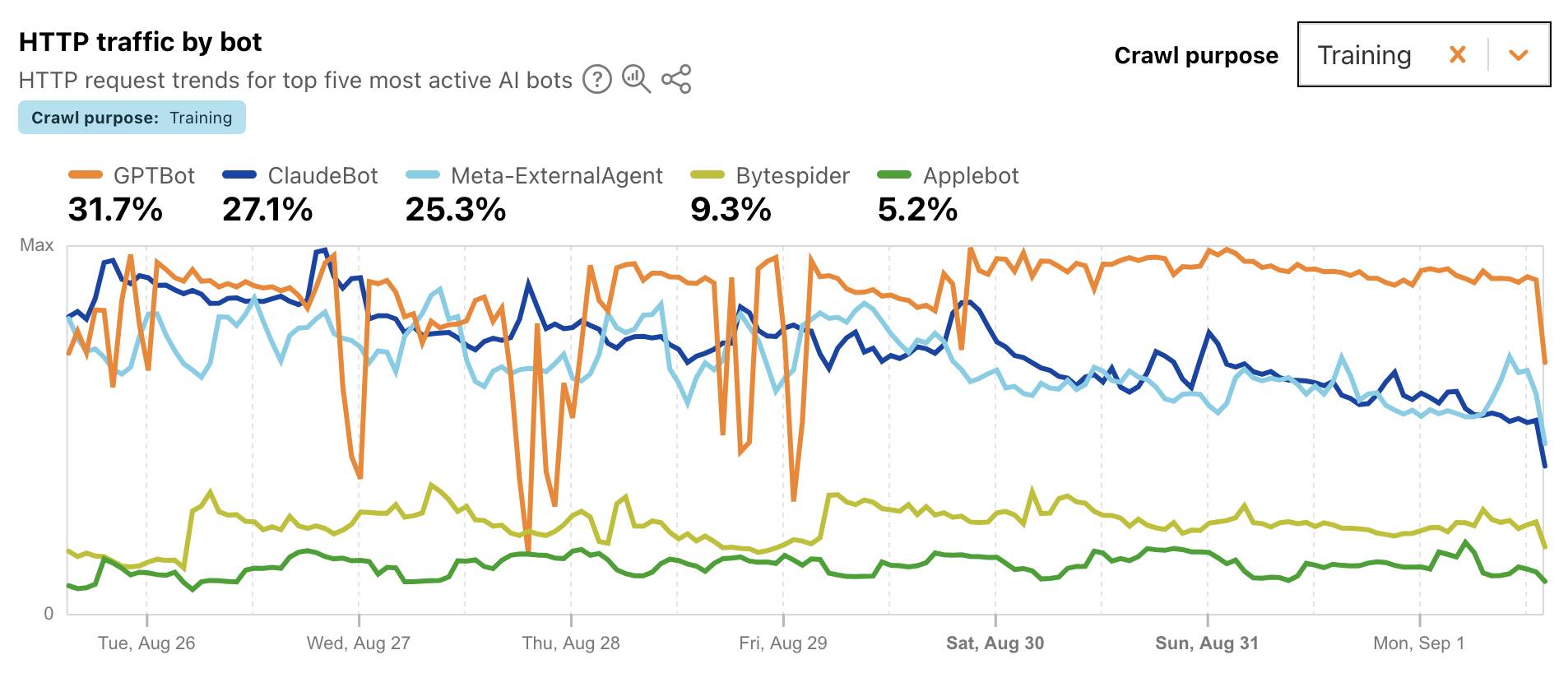
I found this chart particularly interesting, showing which documented AI crawlers are most active collecting training data - lead by GPTBot, ClaudeBot and Meta-ExternalAgent:
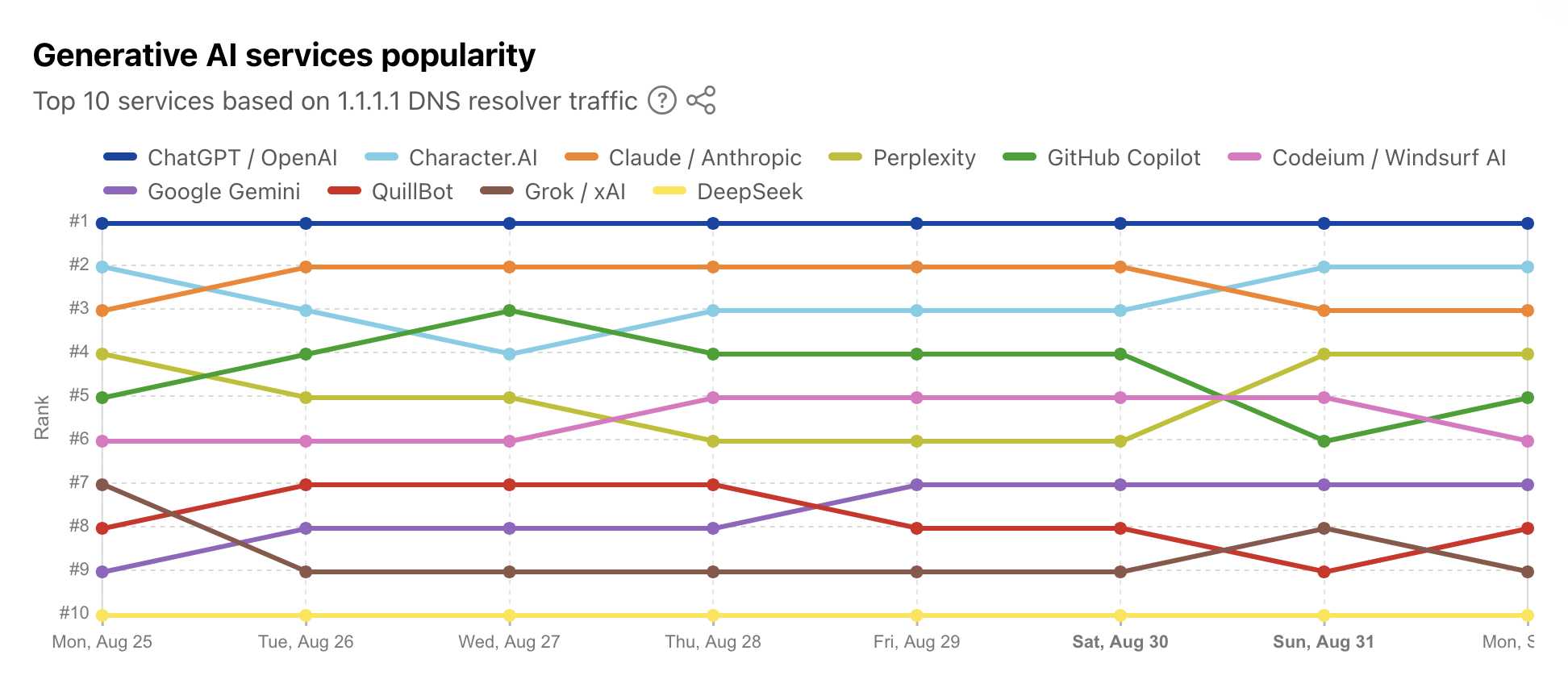
Cloudflare's DNS data also hints at the popularity of different services. ChatGPT holds the first place, which is unsurprising - but second place is a hotly contested race between Claude and Perplexity and #4/#5/#6 is contested by GitHub Copilot, Perplexity, and Codeium/Windsurf.
Google Gemini comes in 7th, though since this is DNS based I imagine this is undercounting instances of Gemini on google.com as opposed to gemini.google.com.
If you're a startup running your own crawlers to gather data for whatever purpose, you should try really hard not to make the world a worse place by driving up costs for the sites you are scraping.
There's really no excuse for crawling Wikipedia ("65% of our most expensive traffic comes from bots") when they offer a comprehensive collection of bulk download options.
Do better!
2024
AI crawlers need to be more respectful (via) Eric Holscher:
At Read the Docs, we host documentation for many projects and are generally bot friendly, but the behavior of AI crawlers is currently causing us problems. We have noticed AI crawlers aggressively pulling content, seemingly without basic checks against abuse.
One crawler downloaded 73 TB of zipped HTML files just in Month, racking up $5,000 in bandwidth charges!
More than an OpenAI Wrapper: Perplexity Pivots to Open Source. I’m increasingly impressed with Perplexity.ai—I’m using it on a daily basis now. It’s by far the best implementation I’ve seen of LLM-assisted search—beating Microsoft Bing and Google Bard at their own game.
A year ago it was implemented as a GPT 3.5 powered wrapper around Microsoft Bing. To my surprise they’ve now evolved way beyond that: Perplexity has their own search index now and is running their own crawlers, and they’re using variants of Mistral 7B and Llama 70B as their models rather than continuing to depend on OpenAI.
2023
Google was accidentally leaking its Bard AI chats into public search results. I’m quoted in this piece about yesterday’s Bard privacy bug: it turned out the share URL and “Let anyone with the link see what you’ve selected” feature wasn’t correctly setting a noindex parameter, and so some shared conversations were being swept up by the Google search crawlers. Thankfully this was a mistake, not a deliberate design decision, and it should be fixed by now.
2022
curl-impersonate (via) “A special build of curl that can impersonate the four major browsers: Chrome, Edge, Safari & Firefox. curl-impersonate is able to perform TLS and HTTP handshakes that are identical to that of a real browser.”
I hadn’t realized that it’s become increasingly common for sites to use fingerprinting of TLS and HTTP handshakes to block crawlers. curl-impersonate attempts to impersonate browsers much more accurately, using tricks like compiling with Firefox’s nss TLS library and Chrome’s BoringSSL.
2020
datasette-block-robots.
Another little Datasette plugin: this one adds a /robots.txt page with Disallow: / to block all indexing of a Datasette instance from respectable search engine crawlers. I built this in less than ten minutes from idea to deploy to PyPI thanks to the datasette-plugin cookiecutter template.
2018
Googlebot’s Javascript random() function is deterministic. random() as executed by Googlebot returns the same predicable sequence. More interestingly, Googlebot runs a much faster timer for setTimeout and setInterval—as Tom Anthony points out, “Why actually wait 5 seconds when you are a bot?”
2012
Why does Google use “Allow” in robots.txt, when the standard seems to be “Disallow?”
The Disallow command prevents search engines from crawling your site.
[... 59 words]2009
Official Google Webmaster Blog: A proposal for making AJAX crawlable.
It's horrible! The Google crawler would map url#!state to url?_escaped_fragment_=state, then expect your site to provide rendered HTML that reflects that state (they even go as far as to suggest running a headless browser within your web server to do this). Just stick to progressive enhancement instead, it's far less hideous. It looks like the proposal may have originated with the GWT team.
2007
robots.txt Adventure. Interesting notes from crawling 4.6 million robots.txt, including 69 different ways in which the word “disallow” can be mis-spelled.
2003
Calendars and crawlers
Douglas Bowman has been having some amusing problems with robots and his calendar. The calendar, visible on every page of the site, automatically adds a “next month” and “previous month” link to allow surfers to browser through the archive in both directions. Unfortunately, Doug ommitted the logic to stop showing a “previous month” link when there were no earlier entries. An enterprising crawler started following the links, and didn’t stop until it had reached 1542!
[... 113 words]