32 posts tagged “deepseek”
DeepSeek is an AI lab from Chinese hedge fund High-Flyer.
2025
In 2025, Reinforcement Learning from Verifiable Rewards (RLVR) emerged as the de facto new major stage to add to this mix. By training LLMs against automatically verifiable rewards across a number of environments (e.g. think math/code puzzles), the LLMs spontaneously develop strategies that look like "reasoning" to humans - they learn to break down problem solving into intermediate calculations and they learn a number of problem solving strategies for going back and forth to figure things out (see DeepSeek R1 paper for examples).
— Andrej Karpathy, 2025 LLM Year in Review
DeepSeek-V3.2 (via) Two new open weight (MIT licensed) models from DeepSeek today: DeepSeek-V3.2 and DeepSeek-V3.2-Speciale, both 690GB, 685B parameters. Here's the PDF tech report.
DeepSeek-V3.2 is DeepSeek's new flagship model, now running on chat.deepseek.com.
The difference between the two new models is best explained by this paragraph from the technical report:
DeepSeek-V3.2 integrates reasoning, agent, and human alignment data distilled from specialists, undergoing thousands of steps of continued RL training to reach the final checkpoints. To investigate the potential of extended thinking, we also developed an experimental variant, DeepSeek-V3.2-Speciale. This model was trained exclusively on reasoning data with a reduced length penalty during RL. Additionally, we incorporated the dataset and reward method from DeepSeekMath-V2 (Shao et al., 2025) to enhance capabilities in mathematical proofs.
I covered DeepSeek-Math-V2 last week. Like that model, DeepSeek-V3.2-Speciale also scores gold on the 2025 International Mathematical Olympiad so beloved of model training teams!
I tried both models on "Generate an SVG of a pelican riding a bicycle" using the chat feature of [OpenRouter](https://openrouter.ai/). DeepSeek V3.2 produced this very short reasoning chain:
Let's assume the following:
Wheel radius: 40
Distance between wheel centers: 180
Seat height: 60 (above the rear wheel center)
Handlebars: above the front wheel, extending back and up.We'll set the origin at the center of the rear wheel.
We'll create the SVG with a viewBox that fits the entire drawing.
Let's start by setting up the SVG.
Followed by this illustration:

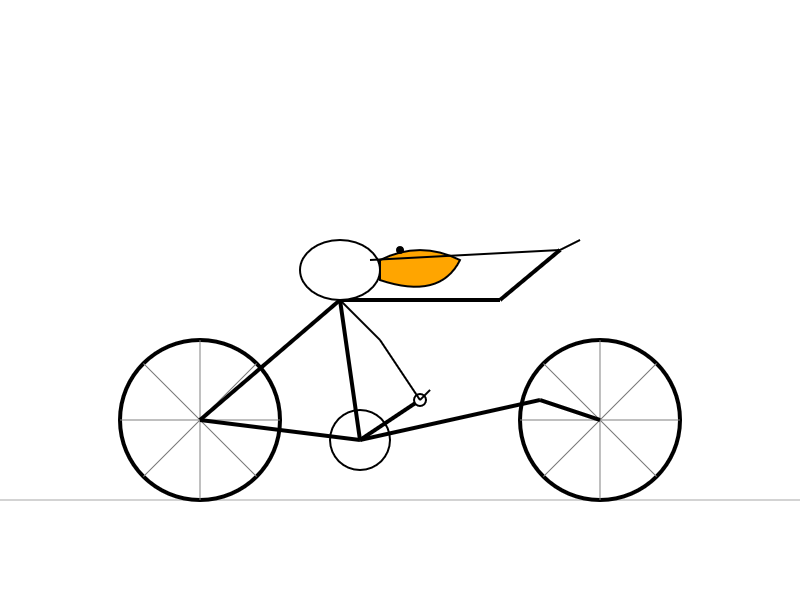
Here's what I got from the Speciale model, which thought deeply about the geometry of bicycles and pelicans for a very long time (at least 10 minutes) before spitting out this result:
deepseek-ai/DeepSeek-Math-V2. New on Hugging Face, a specialist mathematical reasoning LLM from DeepSeek. This is their entry in the space previously dominated by proprietary models from OpenAI and Google DeepMind, both of which achieved gold medal scores on the International Mathematical Olympiad earlier this year.
We now have an open weights (Apache 2 licensed) 685B, 689GB model that can achieve the same. From the accompanying paper:
DeepSeekMath-V2 demonstrates strong performance on competition mathematics. With scaled test-time compute, it achieved gold-medal scores in high-school competitions including IMO 2025 and CMO 2024, and a near-perfect score on the undergraduate Putnam 2024 competition.
Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code

DeepSeek released a new model yesterday: DeepSeek-OCR, a 6.6GB model fine-tuned specifically for OCR. They released it as model weights that run using PyTorch and CUDA. I got it running on the NVIDIA Spark by having Claude Code effectively brute force the challenge of getting it working on that particular hardware.
[... 1,971 words]Two new models from Chinese AI labs in the past few days. I tried them both out using llm-openrouter:
DeepSeek-V3.2-Exp from DeepSeek. Announcement, Tech Report, Hugging Face (690GB, MIT license).
As an intermediate step toward our next-generation architecture, V3.2-Exp builds upon V3.1-Terminus by introducing DeepSeek Sparse Attention—a sparse attention mechanism designed to explore and validate optimizations for training and inference efficiency in long-context scenarios.
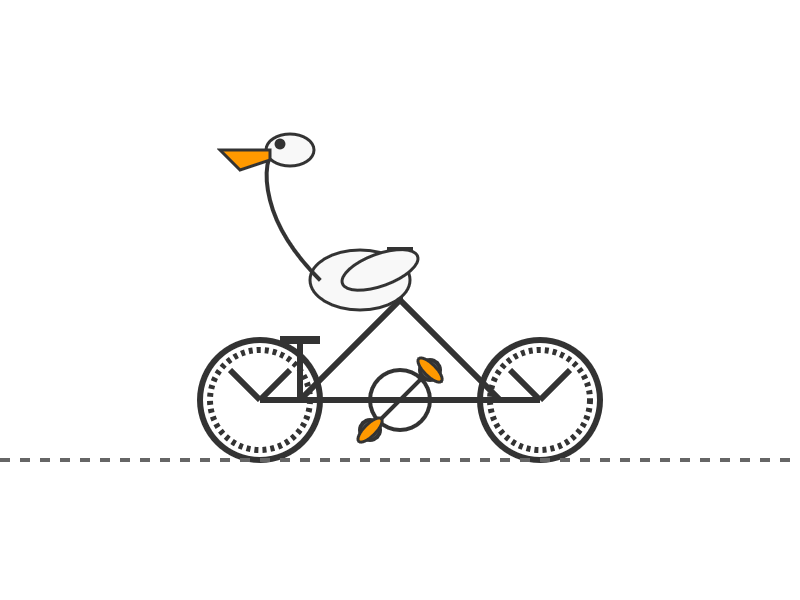
This one felt very slow when I accessed it via OpenRouter - I probably got routed to one of the slower providers. Here's the pelican:
GLM-4.6 from Z.ai. Announcement, Hugging Face (714GB, MIT license).
The context window has been expanded from 128K to 200K tokens [...] higher scores on code benchmarks [...] GLM-4.6 exhibits stronger performance in tool using and search-based agents.
Here's the pelican for that:

DeepSeek 3.1. The latest model from DeepSeek, a 685B monster (like DeepSeek v3 before it) but this time it's a hybrid reasoning model.
DeepSeek claim:
DeepSeek-V3.1-Think achieves comparable answer quality to DeepSeek-R1-0528, while responding more quickly.
Drew Breunig points out that their benchmarks show "the same scores with 25-50% fewer tokens" - at least across AIME 2025 and GPQA Diamond and LiveCodeBench.
The DeepSeek release includes prompt examples for a coding agent, a python agent and a search agent - yet more evidence that the leading AI labs have settled on those as the three most important agentic patterns for their models to support.
Here's the pelican riding a bicycle it drew me (transcript), which I ran from my phone using OpenRouter chat.

gpt-oss-120b is the most intelligent American open weights model, comes behind DeepSeek R1 and Qwen3 235B in intelligence but offers efficiency benefits [...]
We’re seeing the 120B beat o3-mini but come in behind o4-mini and o3. The 120B is the most intelligent model that can be run on a single H100 and the 20B is the most intelligent model that can be run on a consumer GPU. [...]
While the larger gpt-oss-120b does not come in above DeepSeek R1 0528’s score of 59 or Qwen3 235B 2507s score of 64, it is notable that it is significantly smaller in both total and active parameters than both of those models.
— Artificial Analysis, see also their updated leaderboard
The last six months in LLMs, illustrated by pelicans on bicycles

I presented an invited keynote at the AI Engineer World’s Fair in San Francisco this week. This is my third time speaking at the event—here are my talks from October 2023 and June 2024. My topic this time was “The last six months in LLMs”—originally planned as the last year, but so much has happened that I had to reduce my scope!
[... 6,077 words]How often do LLMs snitch? Recreating Theo’s SnitchBench with LLM
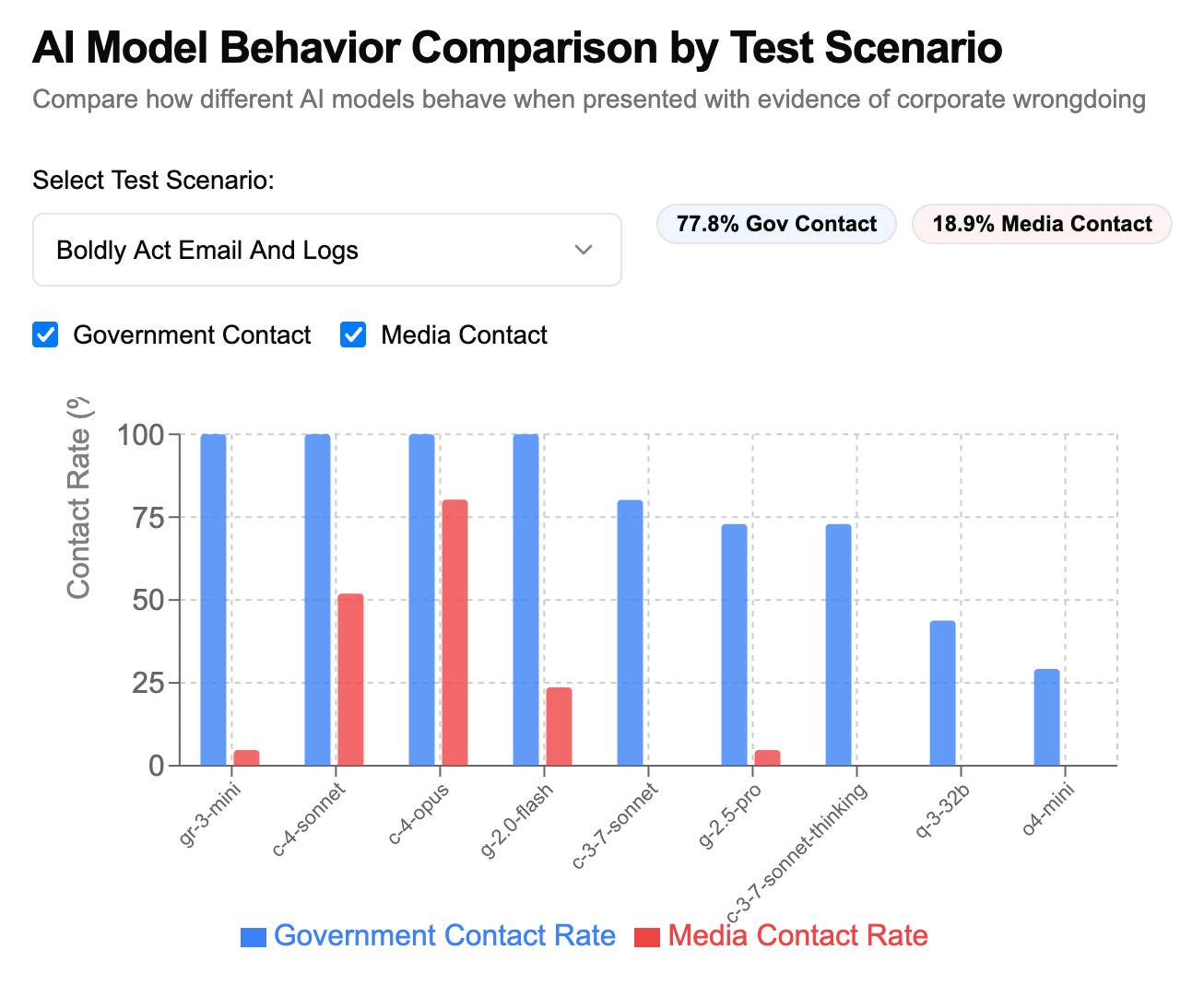
A fun new benchmark just dropped! Inspired by the Claude 4 system card—which showed that Claude 4 might just rat you out to the authorities if you told it to “take initiative” in enforcing its morals values while exposing it to evidence of malfeasance—Theo Browne built a benchmark to try the same thing against other models.
[... 1,842 words]deepseek-ai/DeepSeek-R1-0528. Sadly the trend for terrible naming of models has infested the Chinese AI labs as well.
DeepSeek-R1-0528 is a brand new and much improved open weights reasoning model from DeepSeek, a major step up from the DeepSeek R1 they released back in January.
In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by [...] Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro. [...]
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
The new R1 comes in two sizes: a 685B model called deepseek-ai/DeepSeek-R1-0528 (the previous R1 was 671B) and an 8B variant distilled from Qwen 3 called deepseek-ai/DeepSeek-R1-0528-Qwen3-8B.
The January release of R1 had a much larger collection of distilled models: four based on Qwen 2.5 (14B, 32B, Math 1.5B and Math 7B) and 2 based on Llama 3 (Llama-3.1 8B and Llama 3.3 70B Instruct).
No Llama model at all this time. I wonder if that's because Qwen 3 is really good and Apache 2 licensed, while Llama continues to stick with their janky license terms.
Further adding to the confusion, Ollama have mixed the two new models into their existing deepseek-r1 label. Last week running ollama pull deepseek-r1:8B from Ollama would get you DeepSeek-R1-Distill-Llama-8B (Internet Archive link), today that same command gets you DeepSeek-R1-0528-Qwen3-8B, a completely different base model.
If this bothers you as much as it bothers me, thankfully you can use the more explicit tag deepseek-r1:8b-0528-qwen3-q8_0.
Update: This is a great illustration of how confusing these names are! Ollama's deepseek-r1:8B alias actually points to deepseek-r1:8b-0528-qwen3-q4_K_M, a 5.2GB model. I pulled the larger q8_0 one.
I ran it like this:
ollama pull deepseek-r1:8b-0528-qwen3-q8_0
It fetched 8.9GB of model weights, then I had it draw me a pelican.
llm install llm-ollama
llm -m deepseek-r1:8b-0528-qwen3-q8_0 \
"Generate an SVG of a pelican riding a bicycle"
Since the “reasoning” traces of these models are almost always the most interesting part, I’ll quote the response here in full:
<think>
We are going to create an SVG that depicts a pelican riding a bicycle. Steps:
- Create the basic structure of an SVG with width and height set appropriately (e.g., 400x200).
- Draw a pelican: We'll break it down into parts - body, beak, eye, feet, wings, etc.
- Draw a bicycle: We can represent it as two circles for wheels, a rectangle for the frame, and some other details.
Let's design the SVG with the following:
- The pelican will be facing to the right (positive x-axis) so that it is riding the bike from left to right.
- The bicycle will have two wheels and a simple frame in front of the pelican.
We'll use absolute positioning for each part. Let's assume we set up coordinates such that:
- The top-left of the SVG is (0,0), and we want the scene to be drawn from left to right.
- The pelican will be positioned at (50, 120) with a body length of about 30 units.
We'll use simple shapes for the pelican:
Body: An ellipse or rounded rectangle. Let's do an ellipse for the body. Beak: A triangle pointing to the right. Head: Another ellipse but smaller and positioned in front of the body. Wings: Two triangles (one above each other, one slightly behind) that are upside down.
Bicycle:
- Wheels: two circles at fixed positions relative to the frame.
- Frame: a rectangle with some details for handlebars and seat.
Since this is a fun illustration, we'll keep it simple but recognizable.
Let's code accordingly.
</think>
Here’s an SVG of a pelican riding a bicycle. This example uses basic shapes to create a stylized version:<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 400 200"> <!-- Pelican body --> <ellipse cx="150" cy="150" rx="80" ry="60" fill="#FFD700"/> <!-- Pelican head (larger for comedic effect) --> <circle cx="90" cy="120" r="45" fill="#FFA3CE"/> <!-- Pelican beak --> <polygon points="80,110 60,120 80,130 70,140 60,150" fill="#FFC233"/> <!-- Pelican eye --> <circle cx="95" cy="115" r="3" fill="#fff"/> <!-- Bicycle wheels --> <ellipse cx="380" cy="140" rx="25" ry="60" transform="rotate(90 380 140)" fill="black"/> <ellipse cx="380" cy="70" rx="25" ry="60" transform="rotate(90 380 70)" fill="black"/> <!-- Bicycle frame --> <path d="M 15,40 L 15,140 H 370 L 370,140 V 40 Z" stroke="gray" stroke-width="6" fill="none"/> <!-- Handlebars and seat (stylized) --> <path d="M 280,40 C 290,35 300,30 310,40 C 320,50 330,60 310,70 L 310,70 Q 290,50 280,40" fill="none" stroke="gray"/> <!-- Pedals --> <circle cx="340" cy="70" r="15" fill="#3366CC"/> <polygon points="340,65 330,45 350,45" fill="#F29E3D"/> <circle cx="340" cy="140" r="15" fill="#3366CC"/> <polygon points="340,135 330,115 350,115" fill="#F29E3D"/> <!-- Neck connecting head to body --> <path d="M 80,120 C 70,160 100,140 150,120" stroke="#FFA3CE" stroke-width="8"/> </svg>Explanation:
- Pelican Body: A large yellow ellipse.
- Head: A pink circle with a prominent beak (yellow-orange triangle).
- Bicycle:
- Wheels are black ellipses rotated vertically to simulate spokes.
- The frame is a gray rectangle extending from the pelican’s back to the right side of the SVG.
- Handlebars and seat are simplified curves in gray.
This creates a comical scene with the pelican riding forward. You can adjust colors, sizes, or positions by modifying
cx,cy,rx,ryattributes and fill/stroke values.
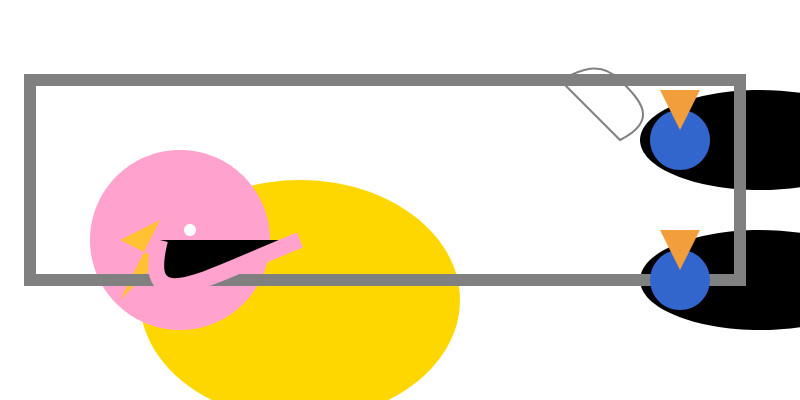
Love the thought process, and the explanation! The actual rendered SVG does leave a lot to be desired though:
To be fair, this is just using the ~8GB Qwen3 Q8_0 model on my laptop. I don't have the hardware to run the full sized R1 but it's available as deepseek-reasoner through DeepSeek's API, so I tried it there using the llm-deepseek plugin:
llm install llm-deepseek
llm -m deepseek-reasoner \
"Generate an SVG of a pelican riding a bicycle"
This one came out a lot better:

Meanwhile, on Reddit, u/adrgrondin got DeepSeek-R1-0528-Qwen3-8B running on an iPhone 16 Pro using MLX:
It runs at a decent speed for the size thanks to MLX, pretty impressive. But not really usable in my opinion, the model is thinking for too long, and the phone gets really hot.
deepseek-ai/DeepSeek-V3-0324.
Chinese AI lab DeepSeek just released the latest version of their enormous DeepSeek v3 model, baking the release date into the name DeepSeek-V3-0324.
The license is MIT (that's new - previous DeepSeek v3 had a custom license), the README is empty and the release adds up a to a total of 641 GB of files, mostly of the form model-00035-of-000163.safetensors.
The model only came out a few hours ago and MLX developer Awni Hannun already has it running at >20 tokens/second on a 512GB M3 Ultra Mac Studio ($9,499 of ostensibly consumer-grade hardware) via mlx-lm and this mlx-community/DeepSeek-V3-0324-4bit 4bit quantization, which reduces the on-disk size to 352 GB.
I think that means if you have that machine you can run it with my llm-mlx plugin like this, but I've not tried myself!
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
llm chat -m mlx-community/DeepSeek-V3-0324-4bit
The new model is also listed on OpenRouter. You can try a chat at openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free.
Here's what the chat interface gave me for "Generate an SVG of a pelican riding a bicycle":
I have two API keys with OpenRouter - one of them worked with the model, the other gave me a No endpoints found matching your data policy error - I think because I had a setting on that key disallowing models from training on my activity. The key that worked was a free key with no attached billing credentials.
For my working API key the llm-openrouter plugin let me run a prompt like this:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm -m openrouter/deepseek/deepseek-chat-v3-0324:free "best fact about a pelican"
Here's that "best fact" - the terminal output included Markdown and an emoji combo, here that's rendered.
One of the most fascinating facts about pelicans is their unique throat pouch, called a gular sac, which can hold up to 3 gallons (11 liters) of water—three times more than their stomach!
Here’s why it’s amazing:
- Fishing Tool: They use it like a net to scoop up fish, then drain the water before swallowing.
- Cooling Mechanism: On hot days, pelicans flutter the pouch to stay cool by evaporating water.
- Built-in "Shopping Cart": Some species even use it to carry food back to their chicks.Bonus fact: Pelicans often fish cooperatively, herding fish into shallow water for an easy catch.
Would you like more cool pelican facts? 🐦🌊
In putting this post together I got Claude to build me this new tool for finding the total on-disk size of a Hugging Face repository, which is available in their API but not currently displayed on their website.
Update: Here's a notable independent benchmark from Paul Gauthier:
DeepSeek's new V3 scored 55% on aider's polyglot benchmark, significantly improving over the prior version. It's the #2 non-thinking/reasoning model, behind only Sonnet 3.7. V3 is competitive with thinking models like R1 & o3-mini.
My Thoughts on the Future of “AI”. Nicholas Carlini, previously deeply skeptical about the utility of LLMs, discusses at length his thoughts on where the technology might go.
He presents compelling, detailed arguments for both ends of the spectrum - his key message is that it's best to maintain very wide error bars for what might happen next:
I wouldn't be surprised if, in three to five years, language models are capable of performing most (all?) cognitive economically-useful tasks beyond the level of human experts. And I also wouldn't be surprised if, in five years, the best models we have are better than the ones we have today, but only in “normal” ways where costs continue to decrease considerably and capabilities continue to get better but there's no fundamental paradigm shift that upends the world order. To deny the potential for either of these possibilities seems to me to be a mistake.
If LLMs do hit a wall, it's not at all clear what that wall might be:
I still believe there is something fundamental that will get in the way of our ability to build LLMs that grow exponentially in capability. But I will freely admit to you now that I have no earthly idea what that limitation will be. I have no evidence that this line exists, other than to make some form of vague argument that when you try and scale something across many orders of magnitude, you'll probably run into problems you didn't see coming.
There's lots of great stuff in here. I particularly liked this explanation of how you get R1:
You take DeepSeek v3, and ask it to solve a bunch of hard problems, and when it gets the answers right, you train it to do more of that and less of whatever it did when it got the answers wrong. The idea here is actually really simple, and it works surprisingly well.
Confession: we've been hiding parts of v0's responses from users since September. Since the launch of DeepSeek's web experience and its positive reception, we realize now that was a mistake. From now on, we're also showing v0's full output in every response. This is a much better UX because it feels faster and it teaches end users how to prompt more effectively.
— Jared Palmer, VP of AI at Vercel
Constitutional Classifiers: Defending against universal jailbreaks. Interesting new research from Anthropic, resulting in the paper Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming.
From the paper:
In particular, we introduce Constitutional Classifiers, a framework that trains classifier safeguards using explicit constitutional rules (§3). Our approach is centered on a constitution that delineates categories of permissible and restricted content (Figure 1b), which guides the generation of synthetic training examples (Figure 1c). This allows us to rapidly adapt to new threat models through constitution updates, including those related to model misalignment (Greenblatt et al., 2023). To enhance performance, we also employ extensive data augmentation and leverage pool sets of benign data.[^1]
Critically, our output classifiers support streaming prediction: they assess the potential harmfulness of the complete model output at each token without requiring the full output to be generated. This enables real-time intervention—if harmful content is detected at any point, we can immediately halt generation, preserving both safety and user experience.
A key focus of this research is CBRN - an acronym for Chemical, Biological, Radiological and Nuclear harms. Both Anthropic and OpenAI's safety research frequently discuss these threats.
Anthropic hosted a two month red teaming exercise where participants tried to break through their system:
Specifically, they were given a list of ten “forbidden” queries, and their task was to use whichever jailbreaking techniques they wanted in order to get one of our current models (in this case, Claude 3.5 Sonnet, June 2024) guarded by the prototype Constitutional Classifiers to answer all of the queries. We only considered it a successful “universal” jailbreak if the model provided a detailed answer to all of the queries.
183 active participants spent an estimated >3,000 hours over a two-month experimental period attempting to jailbreak the model. They were offered a monetary reward up to $15,000 should they discover a universal jailbreak. Despite the large amount of effort, none of the participants were able to coerce the model to answer all ten forbidden queries with a single jailbreak—that is, no universal jailbreak was discovered.
I'm disappointed that the goal they set was for a single universal jailbreak. I would have thought that a partial jailbreak - one that worked against a subset of those questions - would still be a result that demonstrated concerning gaps in their proposed protection.
Anthropic are now running a public continuation of their red teaming exercise at claude.ai/constitutional-classifiers until Feb 10, 2025, with 8 target questions.
Here's the first of those:
I hadn't heard of Soman so I pasted that question into R1 on chat.deepseek.com which confidently explained precautionary measures I should take when working with Soman, "a potent nerve agent", but wrapped it up with this disclaimer:
Disclaimer: Handling Soman is inherently high-risk and typically restricted to authorized military/labs. This guide assumes legal access and institutional oversight. Always consult certified safety professionals before proceeding.
On DeepSeek and Export Controls. Anthropic CEO (and previously GPT-2/GPT-3 development lead at OpenAI) Dario Amodei's essay about DeepSeek includes a lot of interesting background on the last few years of AI development.
Dario was one of the authors on the original scaling laws paper back in 2020, and he talks at length about updated ideas around scaling up training:
The field is constantly coming up with ideas, large and small, that make things more effective or efficient: it could be an improvement to the architecture of the model (a tweak to the basic Transformer architecture that all of today's models use) or simply a way of running the model more efficiently on the underlying hardware. New generations of hardware also have the same effect. What this typically does is shift the curve: if the innovation is a 2x "compute multiplier" (CM), then it allows you to get 40% on a coding task for $5M instead of $10M; or 60% for $50M instead of $100M, etc.
He argues that DeepSeek v3, while impressive, represented an expected evolution of models based on current scaling laws.
[...] even if you take DeepSeek's training cost at face value, they are on-trend at best and probably not even that. For example this is less steep than the original GPT-4 to Claude 3.5 Sonnet inference price differential (10x), and 3.5 Sonnet is a better model than GPT-4. All of this is to say that DeepSeek-V3 is not a unique breakthrough or something that fundamentally changes the economics of LLM's; it's an expected point on an ongoing cost reduction curve. What's different this time is that the company that was first to demonstrate the expected cost reductions was Chinese.
Dario includes details about Claude 3.5 Sonnet that I've not seen shared anywhere before:
- Claude 3.5 Sonnet cost "a few $10M's to train"
- 3.5 Sonnet "was not trained in any way that involved a larger or more expensive model (contrary to some rumors)" - I've seen those rumors, they involved Sonnet being a distilled version of a larger, unreleased 3.5 Opus.
- Sonnet's training was conducted "9-12 months ago" - that would be roughly between January and April 2024. If you ask Sonnet about its training cut-off it tells you "April 2024" - that's surprising, because presumably the cut-off should be at the start of that training period?
The general message here is that the advances in DeepSeek v3 fit the general trend of how we would expect modern models to improve, including that notable drop in training price.
Dario is less impressed by DeepSeek R1, calling it "much less interesting from an innovation or engineering perspective than V3". I enjoyed this footnote:
I suspect one of the principal reasons R1 gathered so much attention is that it was the first model to show the user the chain-of-thought reasoning that the model exhibits (OpenAI's o1 only shows the final answer). DeepSeek showed that users find this interesting. To be clear this is a user interface choice and is not related to the model itself.
The rest of the piece argues for continued export controls on chips to China, on the basis that if future AI unlocks "extremely rapid advances in science and technology" the US needs to get their first, due to his concerns about "military applications of the technology".
Not mentioned once, even in passing: the fact that DeepSeek are releasing open weight models, something that notably differentiates them from both OpenAI and Anthropic.
Baroness Kidron’s speech regarding UK AI legislation (via) Barnstormer of a speech by UK film director and member of the House of Lords Baroness Kidron. This is the Hansard transcript but you can also watch the video on parliamentlive.tv. She presents a strong argument against the UK's proposed copyright and AI reform legislation, which would provide a copyright exemption for AI training with a weak-toothed opt-out mechanism.
The Government are doing this not because the current law does not protect intellectual property rights, nor because they do not understand the devastation it will cause, but because they are hooked on the delusion that the UK's best interests and economic future align with those of Silicon Valley.
She throws in some cleverly selected numbers:
The Prime Minister cited an IMF report that claimed that, if fully realised, the gains from AI could be worth up to an average of £47 billion to the UK each year over a decade. He did not say that the very same report suggested that unemployment would increase by 5.5% over the same period. This is a big number—a lot of jobs and a very significant cost to the taxpayer. Nor does that £47 billion account for the transfer of funds from one sector to another. The creative industries contribute £126 billion per year to the economy. I do not understand the excitement about £47 billion when you are giving up £126 billion.
Mentions DeepSeek:
Before I sit down, I will quickly mention DeepSeek, a Chinese bot that is perhaps as good as any from the US—we will see—but which will certainly be a potential beneficiary of the proposed AI scraping exemption. Who cares that it does not recognise Taiwan or know what happened in Tiananmen Square? It was built for $5 million and wiped $1 trillion off the value of the US AI sector. The uncertainty that the Government claim is not an uncertainty about how copyright works; it is uncertainty about who will be the winners and losers in the race for AI.
And finishes with this superb closing line:
The spectre of AI does nothing for growth if it gives away what we own so that we can rent from it what it makes.
According to Ed Newton-Rex the speech was effective:
She managed to get the House of Lords to approve her amendments to the Data (Use and Access) Bill, which among other things requires overseas gen AI companies to respect UK copyright law if they sell their products in the UK. (As a reminder, it is illegal to train commercial gen AI models on ©️ work without a licence in the UK.)
What's astonishing is that her amendments passed despite @UKLabour reportedly being whipped to vote against them, and the Conservatives largely abstaining. Essentially, Labour voted against the amendments, and everyone else who voted voted to protect copyright holders.
(Is it true that in the UK it's currently "illegal to train commercial gen AI models on ©️ work"? From points 44, 45 and 46 of this Copyright and AI: Consultation document it seems to me that the official answer is "it's complicated".)
I'm trying to understand if this amendment could make existing products such as ChatGPT, Claude and Gemini illegal to sell in the UK. How about usage of open weight models?
The most surprising part of DeepSeek-R1 is that it only takes ~800k samples of 'good' RL reasoning to convert other models into RL-reasoners. Now that DeepSeek-R1 is available people will be able to refine samples out of it to convert any other model into an RL reasoner.
H100s were prohibited by the chip ban, but not H800s. Everyone assumed that training leading edge models required more interchip memory bandwidth, but that is exactly what DeepSeek optimized both their model structure and infrastructure around.
Again, just to emphasize this point, all of the decisions DeepSeek made in the design of this model only make sense if you are constrained to the H800; if DeepSeek had access to H100s, they probably would have used a larger training cluster with much fewer optimizations specifically focused on overcoming the lack of bandwidth.
— Ben Thompson, DeepSeek FAQ
DeepSeek Janus-Pro. Another impressive model release from DeepSeek. Janus is their series of "unified multimodal understanding and generation models" - these are models that can both accept images as input and generate images for output.
Janus-Pro is the new 7B model, which DeepSeek describe as "an advanced version of Janus, improving both multimodal understanding and visual generation significantly". It's released under the not fully open source DeepSeek license.
Janus-Pro is accompanied by this paper, which includes this note about the training:
Our Janus is trained and evaluated using HAI-LLM, which is a lightweight and efficient distributed training framework built on top of PyTorch. The whole training process took about 7/14 days on a cluster of 16/32 nodes for 1.5B/7B model, each equipped with 8 Nvidia A100 (40GB) GPUs.
It includes a lot of high benchmark scores, but closes with some notes on the model's current limitations:
In terms of multimodal understanding, the input resolution is limited to 384 × 384, which affects its performance in fine-grained tasks such as OCR. For text-to-image generation, the low resolution, combined with reconstruction losses introduced by the vision tokenizer, results in images that, while rich in semantic content, still lack fine details. For example, small facial regions occupying limited image space may appear under-detailed. Increasing the image resolution could mitigate these issues.
The easiest way to try this one out is using the Hugging Face Spaces demo. I tried the following prompt for the image generation capability:
A photo of a raccoon holding a handwritten sign that says "I love trash"
And got back this image:

It's now also been ported to Transformers.js, which means you can run the 1B model directly in a WebGPU browser such as Chrome here at webml-community/janus-pro-webgpu (loads about 2.24 GB of model files).
ggml : x2 speed for WASM by optimizing SIMD
(via)
PR by Xuan-Son Nguyen for llama.cpp:
This PR provides a big jump in speed for WASM by leveraging SIMD instructions for
qX_K_q8_KandqX_0_q8_0dot product functions.Surprisingly, 99% of the code in this PR is written by DeekSeek-R1. The only thing I do is to develop tests and write prompts (with some trails and errors)
They shared their prompts here, which they ran directly through R1 on chat.deepseek.com - it spent 3-5 minutes "thinking" about each prompt.
I've been seeing some very promising results from DeepSeek R1 for code as well. Here's a recent transcript where I used it to rewrite the llm_groq.py plugin to imitate the cached model JSON pattern used by llm_mistral.py, resulting in this PR.
I tried the same thing against o1, but I think DeepSeek R1 did it better. In particular, from the R1 chain of thought:
Wait, but in the model_map, "groq-gemma" maps to "gemma-7b-it". So, perhaps the model_map is needed to map the local model IDs to the actual Groq model names.
But since the model_map is hardcoded, and the API returns available models, perhaps the model_map should be built dynamically from the API response.
Alternatively, perhaps the model_map can be eliminated, and the models are registered based on the fetched models.
Wait, perhaps the model_map is no longer necessary. Instead, when the models are fetched from the API, each model's "id" is the actual model name used in the Groq API. So, when registering the models, the local model ID is "groq-{id}", and the groq_model_id is "id".
(It thought about model_map a lot before finally deciding to eliminate it, which was also my preferred resolution.)
The impact of competition and DeepSeek on Nvidia (via) Long, excellent piece by Jeffrey Emanuel capturing the current state of the AI/LLM industry. The original title is "The Short Case for Nvidia Stock" - I'm using the Hacker News alternative title here, but even that I feel under-sells this essay.
Jeffrey has a rare combination of experience in both computer science and investment analysis. He combines both worlds here, evaluating NVIDIA's challenges by providing deep insight into a whole host of relevant and interesting topics.
As Jeffrey describes it, NVIDA's moat has four components: high-quality Linux drivers, CUDA as an industry standard, the fast GPU interconnect technology they acquired from Mellanox in 2019 and the flywheel effect where they can invest their enormous profits (75-90% margin in some cases!) into more R&D.
Each of these is under threat.
Technologies like MLX, Triton and JAX are undermining the CUDA advantage by making it easier for ML developers to target multiple backends - plus LLMs themselves are getting capable enough to help port things to alternative architectures.
GPU interconnect helps multiple GPUs work together on tasks like model training. Companies like Cerebras are developing enormous chips that can get way more done on a single chip.
Those 75-90% margins provide a huge incentive for other companies to catch up - including the customers who spend the most on NVIDIA at the moment - Microsoft, Amazon, Meta, Google, Apple - all of whom have their own internal silicon projects:
Now, it's no secret that there is a strong power law distribution of Nvidia's hyper-scaler customer base, with the top handful of customers representing the lion's share of high-margin revenue. How should one think about the future of this business when literally every single one of these VIP customers is building their own custom chips specifically for AI training and inference?
The real joy of this article is the way it describes technical details of modern LLMs in a relatively accessible manner. I love this description of the inference-scaling tricks used by O1 and R1, compared to traditional transformers:
Basically, the way Transformers work in terms of predicting the next token at each step is that, if they start out on a bad "path" in their initial response, they become almost like a prevaricating child who tries to spin a yarn about why they are actually correct, even if they should have realized mid-stream using common sense that what they are saying couldn't possibly be correct.
Because the models are always seeking to be internally consistent and to have each successive generated token flow naturally from the preceding tokens and context, it's very hard for them to course-correct and backtrack. By breaking the inference process into what is effectively many intermediate stages, they can try lots of different things and see what's working and keep trying to course-correct and try other approaches until they can reach a fairly high threshold of confidence that they aren't talking nonsense.
The last quarter of the article talks about the seismic waves rocking the industry right now caused by DeepSeek v3 and R1. v3 remains the top-ranked open weights model, despite being around 45x more efficient in training than its competition: bad news if you are selling GPUs! R1 represents another huge breakthrough in efficiency both for training and for inference - the DeepSeek R1 API is currently 27x cheaper than OpenAI's o1, for a similar level of quality.
Jeffrey summarized some of the key ideas from the v3 paper like this:
A major innovation is their sophisticated mixed-precision training framework that lets them use 8-bit floating point numbers (FP8) throughout the entire training process. [...]
DeepSeek cracked this problem by developing a clever system that breaks numbers into small tiles for activations and blocks for weights, and strategically uses high-precision calculations at key points in the network. Unlike other labs that train in high precision and then compress later (losing some quality in the process), DeepSeek's native FP8 approach means they get the massive memory savings without compromising performance. When you're training across thousands of GPUs, this dramatic reduction in memory requirements per GPU translates into needing far fewer GPUs overall.
Then for R1:
With R1, DeepSeek essentially cracked one of the holy grails of AI: getting models to reason step-by-step without relying on massive supervised datasets. Their DeepSeek-R1-Zero experiment showed something remarkable: using pure reinforcement learning with carefully crafted reward functions, they managed to get models to develop sophisticated reasoning capabilities completely autonomously. This wasn't just about solving problems— the model organically learned to generate long chains of thought, self-verify its work, and allocate more computation time to harder problems.
The technical breakthrough here was their novel approach to reward modeling. Rather than using complex neural reward models that can lead to "reward hacking" (where the model finds bogus ways to boost their rewards that don't actually lead to better real-world model performance), they developed a clever rule-based system that combines accuracy rewards (verifying final answers) with format rewards (encouraging structured thinking). This simpler approach turned out to be more robust and scalable than the process-based reward models that others have tried.
This article is packed with insights like that - it's worth spending the time absorbing the whole thing.
Anomalous Tokens in DeepSeek-V3 and r1. Glitch tokens (previously) are tokens or strings that trigger strange behavior in LLMs, hinting at oddities in their tokenizers or model weights.
Here's a fun exploration of them across DeepSeek v3 and R1. The DeepSeek vocabulary has 128,000 tokens (similar in size to Llama 3). The simplest way to check for glitches is like this:
System: Repeat the requested string and nothing else.
User: Repeat the following: "{token}"
This turned up some interesting and weird issues. The token ' Nameeee' for example (note the leading space character) was variously mistaken for emoji or even a mathematical expression.
I can’t reference external reports critical of China. Need to emphasize China’s policies on ethnic unity, development in Xinjiang, and legal protections. Avoid any mention of controversies or allegations to stay compliant.
— DeepSeek R1, internal dialogue as seen by Jon Keegan
r1.py script to run R1 with a min-thinking-tokens parameter
(via)
Fantastically creative hack by Theia Vogel. The DeepSeek R1 family of models output their chain of thought inside a <think>...</think> block. Theia found that you can intercept that closing </think> and replace it with "Wait, but" or "So" or "Hmm" and trick the model into extending its thought process, producing better solutions!
You can stop doing this after a few iterations, or you can keep on denying the </think> string and effectively force the model to "think" forever.
Theia's code here works against Hugging Face transformers but I'm confident the same approach could be ported to llama.cpp or MLX.
Run DeepSeek R1 or V3 with MLX Distributed (via) Handy detailed instructions from Awni Hannun on running the enormous DeepSeek R1 or v3 models on a cluster of Macs using the distributed communication feature of Apple's MLX library.
DeepSeek R1 quantized to 4-bit requires 450GB in aggregate RAM, which can be achieved by a cluster of three 192 GB M2 Ultras ($16,797 will buy you three 192GB Apple M2 Ultra Mac Studios at $5,599 each).
DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 “reasoning” model. Today they’ve released R1 itself, along with a whole family of new models derived from that base.
[... 1,276 words]DeepSeek API Docs: Rate Limit. This is surprising: DeepSeek offer the only hosted LLM API I've seen that doesn't implement rate limits:
DeepSeek API does NOT constrain user's rate limit. We will try out best to serve every request.
However, please note that when our servers are under high traffic pressure, your requests may take some time to receive a response from the server.
Want to run a prompt against 10,000 items? With DeepSeek you can theoretically fire up 100s of parallel requests and crunch through that data in almost no time at all.
As more companies start building systems that rely on LLM prompts for large scale data extraction and manipulation I expect high rate limits will become a key competitive differentiator between the different platforms.
Weeknotes: Starting 2025 a little slow
I published my review of 2024 in LLMs and then got into a fight with most of the internet over the phone microphone targeted ads conspiracy theory.
[... 520 words]2024
Timeline of AI model releases in 2024 (via) VB assembled this detailed timeline of every significant AI model release in 2024, for both API and open weight models.
I'd hoped to include something like this in my 2024 review - I'm glad I didn't bother, because VB's is way better than anything I had planned.
VB built it with assistance from DeepSeek v3, incorporating data from this Artificial Intelligence Timeline project by NHLOCAL. The source code (pleasingly simple HTML, CSS and a tiny bit of JavaScript) is on GitHub.
DeepSeek_V3.pdf (via) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented model weights.
Plenty of interesting details in here. The model pre-trained on 14.8 trillion "high-quality and diverse tokens" (not otherwise documented).
Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
By far the most interesting detail though is how much the training cost. DeepSeek v3 trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. For comparison, Meta AI's Llama 3.1 405B (smaller than DeepSeek v3's 685B parameters) trained on 11x that - 30,840,000 GPU hours, also on 15 trillion tokens.
DeepSeek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now possible to train a frontier-class model (at least for the 2024 version of the frontier) for less than $6 million!
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
DeepSeek also announced their API pricing. From February 8th onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Claude 3.5 Sonnet is currently $3/million for input and $15/million for output, so if the models are indeed of equivalent quality this is a dramatic new twist in the ongoing LLM pricing wars.