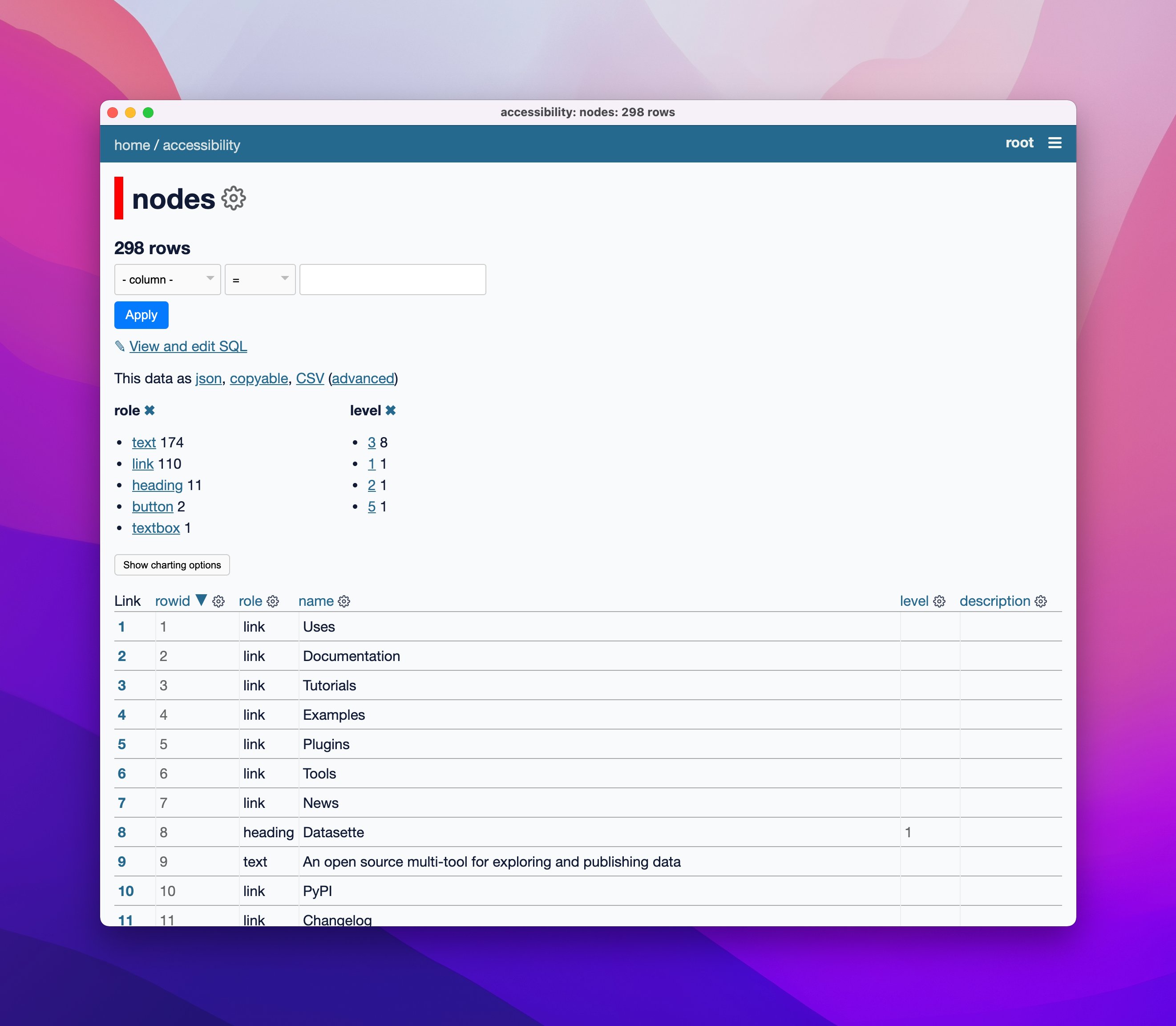
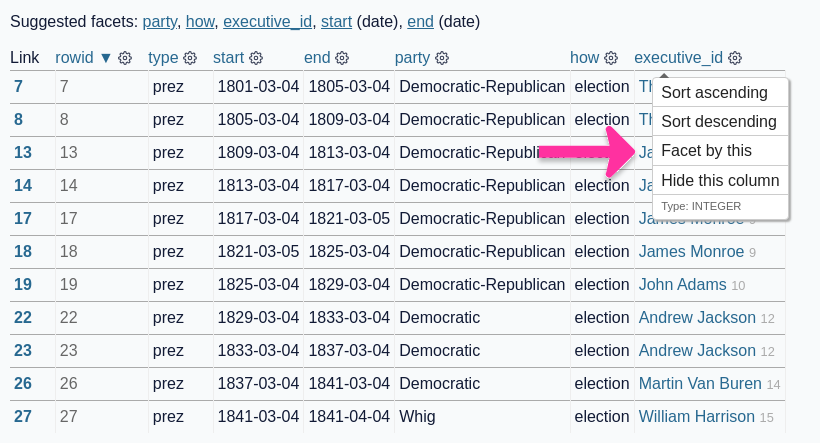
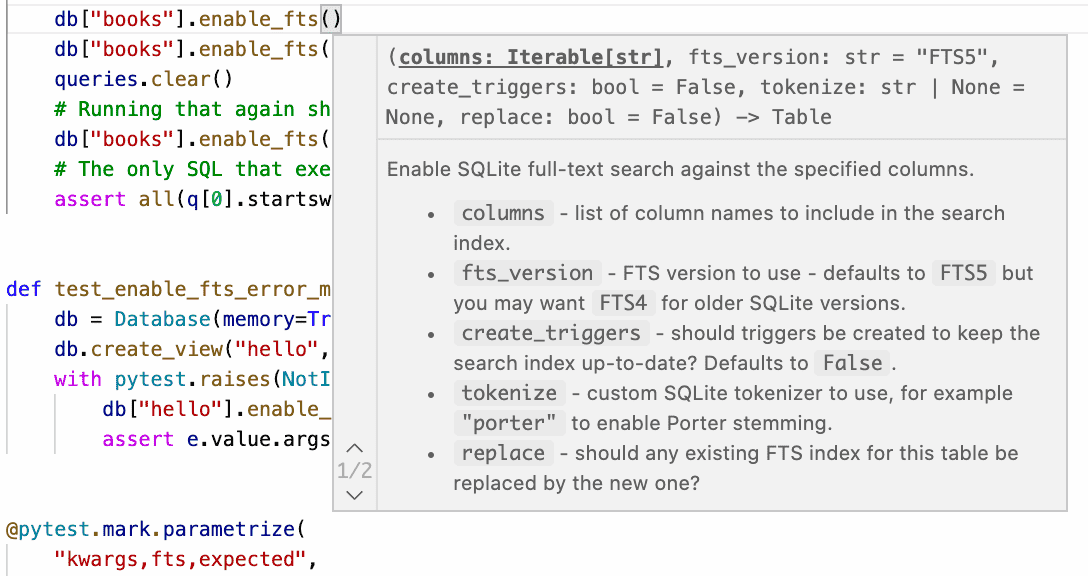
55 posts tagged “documentation”
2025
Documenting what you’re willing to support (and not) (via) Devious company culture hack from Rachel Kroll:
At some point, I realized that if I wrote a wiki page and documented the things that we were willing to support, I could wait about six months and then it would be like it had always been there. Enough people went through the revolving doors of that place such that six months' worth of employee turnover was sufficient to make it look like a whole other company. All I had to do was write it, wait a bit, then start citing it when needed.
You can have an unreasonable amount of influence by being the person who writes stuff down.
This reminded me of Charity Majors' Golden Path process.
If your library doesn't have any documentation, it can't have any bugs.
Documentation specifies what your code is supposed to do. Your tests specify what it actually does.
Bugs exist when your test-enforced implementation fails to match the behavior described in your documentation. Without documentation a bug is just undefined behavior.
If you aim to follow semantic versioning you bump your major version when you release a backwards incompatible change. Such changes cannot exist if your code is not comprehensively documented!
Inspired by a half-remembered conversation I had with Tom Insam many years ago.
o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.
OpenAI reasoning models: Advice on prompting (via) OpenAI's documentation for their o1 and o3 "reasoning models" includes some interesting tips on how to best prompt them:
- Developer messages are the new system messages: Starting with
o1-2024-12-17, reasoning models supportdevelopermessages rather thansystemmessages, to align with the chain of command behavior described in the model spec.
This appears to be a purely aesthetic change made for consistency with their instruction hierarchy concept. As far as I can tell the old system prompts continue to work exactly as before - you're encouraged to use the new developer message type but it has no impact on what actually happens.
Since my LLM tool already bakes in a llm --system "system prompt" option which works across multiple different models from different providers I'm not going to rush to adopt this new language!
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
Anthropic have been encouraging XML-ish delimiters for a while (I say -ish because there's no requirement that the resulting prompt is valid XML). My files-to-prompt tool has a -c option which outputs Claude-style XML, and in my experiments this same option works great with o1 and o3 too:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.
This makes me thing that o1/o3 are not good models to implement RAG on at all - with RAG I like to be able to dump as much extra context into the prompt as possible and leave it to the models to figure out what's relevant.
- Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
Providing examples remains the single most powerful prompting tip I know, so it's interesting to see advice here to only switch to examples if zero-shot doesn't work out.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
This makes sense: reasoning models "think" until they reach a conclusion, so making the goal as unambiguous as possible leads to better results.
- Markdown formatting: Starting with
o1-2024-12-17, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the stringFormatting re-enabledon the first line of yourdevelopermessage.
This one was a real shock to me! I noticed that o3-mini was outputting • characters instead of Markdown * bullets and initially thought that was a bug.
I first saw this while running this prompt against limbo/bindings/python using files-to-prompt:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'Here's the full result, which includes text like this (note the weird bullets):
Features
--------
• High‑performance, in‑process database engine written in Rust
• SQLite‑compatible SQL interface
• Standard Python DB‑API 2.0–style connection and cursor objects
I ran it again with this modified prompt:
Formatting re-enabled. Write a detailed README with extensive usage examples.
And this time got back proper Markdown, rendered in this Gist. That did a really good job, and included bulleted lists using this valid Markdown syntax instead:
- **`make test`**: Run tests using pytest.
- **`make lint`**: Run linters (via [ruff](https://github.com/astral-sh/ruff)).
- **`make check-requirements`**: Validate that the `requirements.txt` files are in sync with `pyproject.toml`.
- **`make compile-requirements`**: Compile the `requirements.txt` files using pip-tools.
(Using LLMs like this to get me off the ground with under-documented libraries is a trick I use several times a month.)
Update: OpenAI's Nikunj Handa:
we agree this is weird! fwiw, it’s a temporary thing we had to do for the existing o-series models. we’ll fix this in future releases so that you can go back to naturally prompting for markdown or no-markdown.
2024
Introducing Limbo: A complete rewrite of SQLite in Rust (via) This looks absurdly ambitious:
Our goal is to build a reimplementation of SQLite from scratch, fully compatible at the language and file format level, with the same or higher reliability SQLite is known for, but with full memory safety and on a new, modern architecture.
The Turso team behind it have been maintaining their libSQL fork for two years now, so they're well equipped to take on a challenge of this magnitude.
SQLite is justifiably famous for its meticulous approach to testing. Limbo plans to take an entirely different approach based on "Deterministic Simulation Testing" - a modern technique pioneered by FoundationDB and now spearheaded by Antithesis, the company Turso have been working with on their previous testing projects.
Another bold claim (emphasis mine):
We have both added DST facilities to the core of the database, and partnered with Antithesis to achieve a level of reliability in the database that lives up to SQLite’s reputation.
[...] With DST, we believe we can achieve an even higher degree of robustness than SQLite, since it is easier to simulate unlikely scenarios in a simulator, test years of execution with different event orderings, and upon finding issues, reproduce them 100% reliably.
The two most interesting features that Limbo is planning to offer are first-party WASM support and fully asynchronous I/O:
SQLite itself has a synchronous interface, meaning driver authors who want asynchronous behavior need to have the extra complication of using helper threads. Because SQLite queries tend to be fast, since no network round trips are involved, a lot of those drivers just settle for a synchronous interface. [...]
Limbo is designed to be asynchronous from the ground up. It extends
sqlite3_step, the main entry point API to SQLite, to be asynchronous, allowing it to return to the caller if data is not ready to consume immediately.
Datasette provides an async API for executing SQLite queries which is backed by all manner of complex thread management - I would be very interested in a native asyncio Python library for talking to SQLite database files.
I successfully tried out Limbo's Python bindings against a demo SQLite test database using uv like this:
uv run --with pylimbo python
>>> import limbo
>>> conn = limbo.connect("/tmp/demo.db")
>>> cursor = conn.cursor()
>>> print(cursor.execute("select * from foo").fetchall())
It crashed when I tried against a more complex SQLite database that included SQLite FTS tables.
The Python bindings aren't yet documented, so I piped them through LLM and had the new google-exp-1206 model write this initial documentation for me:
files-to-prompt limbo/bindings/python -c | llm -m gemini-exp-1206 -s 'write extensive usage documentation in markdown, including realistic usage examples'
Generating documentation from tests using files-to-prompt and LLM. I was experimenting with the wasmtime-py Python library today (for executing WebAssembly programs from inside CPython) and I found the existing API docs didn't quite show me what I wanted to know.
The project has a comprehensive test suite so I tried seeing if I could generate documentation using that:
cd /tmp
git clone https://github.com/bytecodealliance/wasmtime-py
files-to-prompt -e py wasmtime-py/tests -c | \
llm -m claude-3.5-sonnet -s \
'write detailed usage documentation including realistic examples'
More notes in my TIL. You can see the full Claude transcript here - I think this worked really well!
docs.jina.ai—the Jina meta-prompt. From Jina AI on Twitter:
curl docs.jina.ai- This is our Meta-Prompt. It allows LLMs to understand our Reader, Embeddings, Reranker, and Classifier APIs for improved codegen. Using the meta-prompt is straightforward. Just copy the prompt into your preferred LLM interface like ChatGPT, Claude, or whatever works for you, add your instructions, and you're set.
The page is served using content negotiation. If you hit it with curl you get plain text, but a browser with text/html in the accept: header gets an explanation along with a convenient copy to clipboard button.
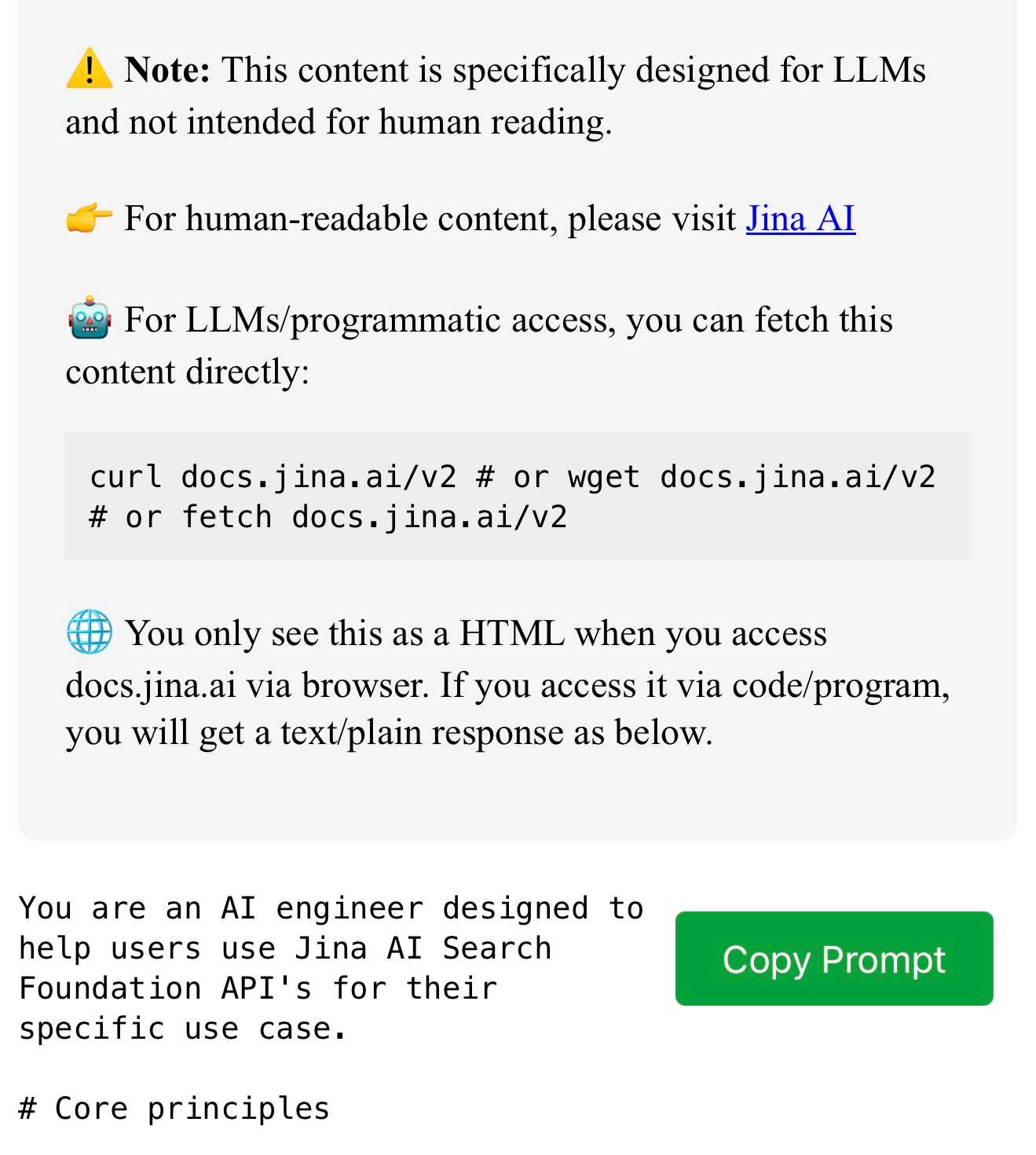
simonw/docs cookiecutter template. Over the last few years I’ve settled on the combination of Sphinx, the Furo theme and the myst-parser extension (enabling Markdown in place of reStructuredText) as my documentation toolkit of choice, maintained in GitHub and hosted using ReadTheDocs.
My LLM and shot-scraper projects are two examples of that stack in action.
Today I wanted to spin up a new documentation site so I finally took the time to construct a cookiecutter template for my preferred configuration. You can use it like this:
pipx install cookiecutter
cookiecutter gh:simonw/docs
Or with uv:
uv tool run cookiecutter gh:simonw/docs
Answer a few questions:
[1/3] project (): shot-scraper
[2/3] author (): Simon Willison
[3/3] docs_directory (docs):
And it creates a docs/ directory ready for you to start editing docs:
cd docs
pip install -r requirements.txt
make livehtml
If you learn something the hard way, share your findings with others. You have blazed a new trail; now you must mark it for your fellow travellers. Sharing knowledge is an unreasonably effective way of helping others.
2023
PostgreSQL Lock Conflicts (via) I absolutely love how extremely specific and niche this documentation site is. It details every single lock that PostgreSQL implements, and shows exactly which commands acquire that lock. That’s everything. I can imagine this becoming absurdly useful at extremely infrequent intervals for advanced PostgreSQL work.
2022
Coping strategies for the serial project hoarder

I gave a talk at DjangoCon US 2022 in San Diego last month about productivity on personal projects, titled “Massively increase your productivity on personal projects with comprehensive documentation and automated tests”.
[... 3,865 words]The Perfect Commit
For the last few years I’ve been trying to center my work around creating what I consider to be the Perfect Commit. This is a single commit that contains all of the following:
[... 2,061 words]Automating screenshots for the Datasette documentation using shot-scraper
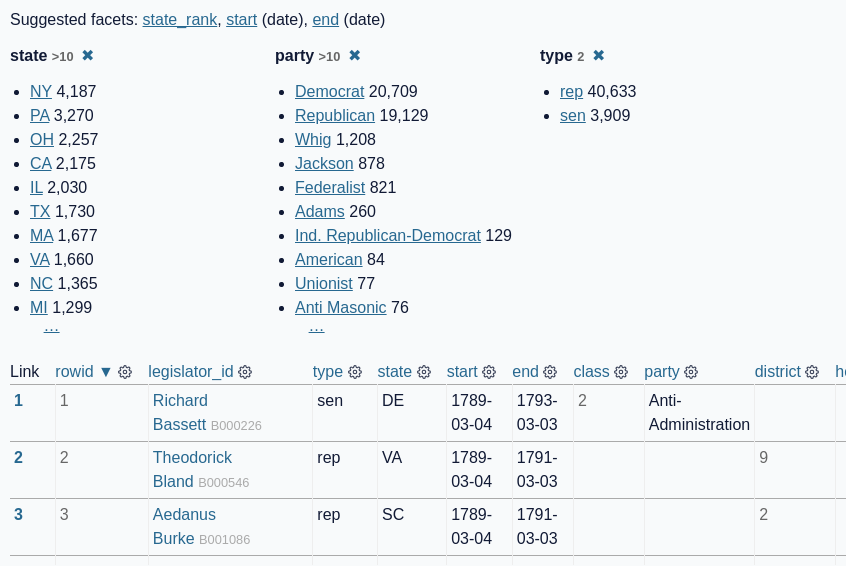
I released shot-scraper back in March as a tool for keeping screenshots in documentation up-to-date.
[... 1,810 words]Software engineering practices
Gergely Orosz started a Twitter conversation asking about recommended “software engineering practices” for development teams.
[... 1,557 words]How I’m a Productive Programmer With a Memory of a Fruit Fly (via) Hynek Schlawack describes the value he gets from searchable offline developer documentation, and advocates for the Documentation Sets format which bundles docs, metadata and a SQLite search index. Hynek’s doc2dash command can convert documentation generated by tools like Sphinx into a docset that’s compatible with several offline documentation browser applications.
Your documentation is complete when someone can use your module without ever having to look at its code. This is very important. This makes it possible for you to separate your module's documented interface from its internal implementation (guts). This is good because it means that you are free to change the module's internals as long as the interface remains the same.
Remember: the documentation, not the code, defines what a module does.
Cleaning data with sqlite-utils and Datasette (via) I wrote a new tutorial for the Datasette website, showing how to use sqlite-utils to import a CSV file, clean up the resulting schema, fix date formats and extract some of the columns into a separate table. It’s accompanied by a ten minute video originally recorded for the HYTRADBOI conference.
Weeknotes: Building Datasette Cloud on Fly Machines, Furo for documentation
Hosting provider Fly released Fly Machines this week. I got an early preview and I’ve been working with it for a few days—it’s a fascinating new piece of technology. I’m using it to get my hosting service for Datasette ready for wider release.
[... 1,005 words]GOV.UK Guidance: Documenting APIs (via) Characteristically excellent guide from GOV.UK on writing great API documentation. “Task-based guidance helps users complete the most common integration tasks, based on the user needs from your research.”
jq language description (via) I love jq but I’ve always found it difficult to remember how to use it, and the manual hasn’t helped me as much as I would hope. It turns out the jq wiki on GitHub offers an alternative, more detailed description of the language which fits the way my brain works a lot better.
Deno by example (via) Interesting approach to documentation: a big list of annotated examples illustrating the Deno way of solving a bunch of common problems.
Instantly create a GitHub repository to take screenshots of a web page
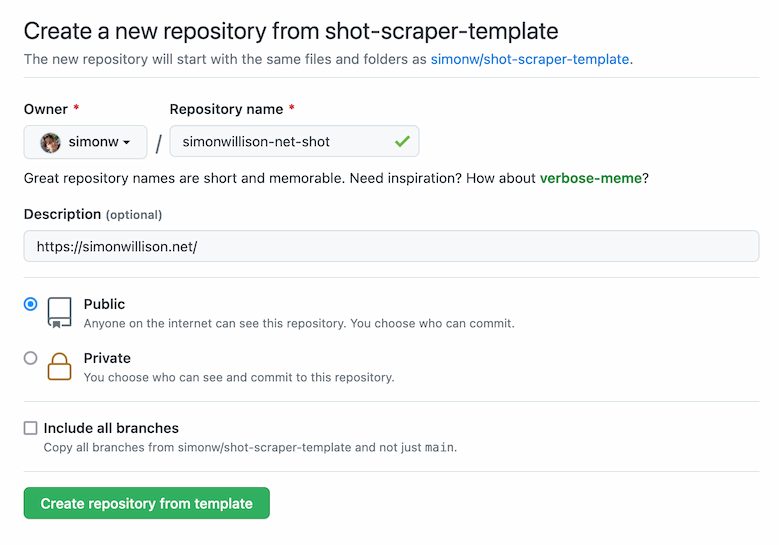
I just released shot-scraper-template, a GitHub repository template that helps you start taking automated screenshots of a web page by filling out a form.
[... 1,177 words]Weeknotes: Distracted by Playwright
My goal for this week was to unblock progress on Datasette by finally finishing the dash encoding implementation I described last week. I was getting close, and then I got very distracted by Playwright.
[... 892 words]shot-scraper: automated screenshots for documentation, built on Playwright
shot-scraper is a new tool that I’ve built to help automate the process of keeping screenshots up-to-date in my documentation. It also doubles as a scraping tool—hence the name—which I picked as a complement to my git scraping and help scraping techniques.
[... 1,802 words]Weeknotes: Datasette Tutorials
I published two new tutorials for Datasette this week, both focused at end-users of the web application.
[... 479 words]2021
Making world-class docs takes effort (via) Curl maintainer Daniel Stenberg writes about his principles for good documentation. I agree with all of these: he emphasizes keeping docs in the repo, avoiding the temptation to exclusively generate them from code, featuring examples and ensuring every API you provide has documentation. Daniel describes an approach similar to the documentation unit tests I’ve been using for my own projects: he has scripts which scan the curl documentation to ensure not only that everything is documented but that each documentation area contains the same sections in the same order.
The Diátaxis documentation framework. Daniele Procida’s model of four types of technical documentation—tutorials, how-to guides, technical reference and explanation—now has a name: Diátaxis.
Datasette on Codespaces, sqlite-utils API reference documentation and other weeknotes
This week I broke my streak of not sending out the Datasette newsletter, figured out how to use Sphinx for Python class documentation, worked out how to run Datasette on GitHub Codespaces, implemented Datasette column metadata and got tantalizingly close to a solution for an elusive Datasette feature.
[... 2,164 words]Adding Sphinx autodoc to a project, and configuring Read The Docs to build it. My TIL notes from figuring out how to use sphinx-autodoc for the sqlite-utils reference documentation today.
sqlite-utils API reference (via) I released sqlite-utils 3.15.1 today with just one change, but it’s a big one: I’ve added docstrings and type annotations to nearly every method in the library, and I’ve started using sphinx-autodoc to generate an API reference page in the documentation directly from those docstrings. I’ve deliberately avoided building this kind of documentation in the past because I so often see projects where the class reference is the ONLY documentation, which I find makes it really hard to figure out how to actually use it. sqlite-utils already has extensive narrative prose documentation so in this case I think it’s a useful enhancement—especially since the docstrings and type hints can help improve the usability of the library in IDEs and Jupyter notebooks.