60 posts tagged “embeddings”
2024
My Twitter thread figuring out the AI features in Microsoft’s Recall. I posed this question on Twitter about why Microsoft Recall (previously) is being described as "AI":
Is it just that the OCR uses a machine learning model, or are there other AI components in the mix here?
I learned that Recall works by taking full desktop screenshots and then applying both OCR and some sort of CLIP-style embeddings model to their content. Both the OCRd text and the vector embeddings are stored in SQLite databases (schema here, thanks Daniel Feldman) which can then be used to search your past computer activity both by text but also by semantic vision terms - "blue dress" to find blue dresses in screenshots, for example. The si_diskann_graph table names hint at Microsoft's DiskANN vector indexing library
A Microsoft engineer confirmed on Hacker News that Recall uses on-disk vector databases to provide local semantic search for both text and images, and that they aren't using Microsoft's Phi-3 or Phi-3 Vision models. As far as I can tell there's no LLM used by the Recall system at all at the moment, just embeddings.
Exploring Hacker News by mapping and analyzing 40 million posts and comments for fun
(via)
A real tour de force of data engineering. Wilson Lin fetched 40 million posts and comments from the Hacker News API (using Node.js with a custom multi-process worker pool) and then ran them all through the BGE-M3 embedding model using RunPod, which let him fire up ~150 GPU instances to get the whole run done in a few hours, using a custom RocksDB and Rust queue he built to save on Amazon SQS costs.
Then he crawled 4 million linked pages, embedded that content using the faster and cheaper jina-embeddings-v2-small-en model, ran UMAP dimensionality reduction to render a 2D map and did a whole lot of follow-on work to identify topic areas and make the map look good.
That's not even half the project - Wilson built several interactive features on top of the resulting data, and experimented with custom rendering techniques on top of canvas to get everything to render quickly.
There's so much in here, and both the code and data (multiple GBs of arrow files) are available if you want to dig in and try some of this out for yourself.
In the Hacker News comments Wilson shares that the total cost of the project was a couple of hundred dollars.
One tiny detail I particularly enjoyed - unrelated to the embeddings - was this trick for testing which edge location is closest to a user using JavaScript:
const edge = await Promise.race(
EDGES.map(async (edge) => {
// Run a few times to avoid potential cold start biases.
for (let i = 0; i < 3; i++) {
await fetch(`https://${edge}.edge-hndr.wilsonl.in/healthz`);
}
return edge;
}),
);
I’m writing a new vector search SQLite Extension.
Alex Garcia is working on sqlite-vec, a spiritual successor to his sqlite-vss project. The new SQLite C extension will have zero other dependencies (sqlite-vss used some tricky C++ libraries) and will work using virtual tables, storing chunks of vectors in shadow tables to avoid needing to load everything into memory at once.
llm-nomic-api-embed. My new plugin for LLM which adds API access to the Nomic series of embedding models. Nomic models can be run locally too, which makes them a great long-term commitment as there’s no risk of the models being retired in a way that damages the value of your previously calculated embedding vectors.
Cohere int8 & binary Embeddings—Scale Your Vector Database to Large Datasets (via) Jo Kristian Bergum told me “The accuracy retention [of binary embedding vectors] is sensitive to whether the model has been using this binarization as part of the loss function.”
Cohere provide an API for embeddings, and last week added support for returning binary vectors specifically tuned in this way.
250M embeddings (Cohere provide a downloadable dataset of 250M embedded documents from Wikipedia) at float32 (4 bytes) is 954GB.
Cohere claim that reducing to 1 bit per dimension knocks that down to 30 GB (954/32) while keeping “90-98% of the original search quality”.
My binary vector search is better than your FP32 vectors. I’m still trying to get my head around this, but here’s what I understand so far.
Embedding vectors as calculated by models such as OpenAI text-embedding-3-small are arrays of floating point values, which look something like this:
[0.0051681744, 0.017187592, -0.018685209, -0.01855924, -0.04725188...]—1356 elements long
Different embedding models have different lengths, but they tend to be hundreds up to low thousands of numbers. If each float is 32 bits that’s 4 bytes per float, which can add up to a lot of memory if you have millions of embedding vectors to compare.
If you look at those numbers you’ll note that they are all pretty small positive or negative numbers, close to 0.
Binary vector search is a trick where you take that sequence of floating point numbers and turn it into a binary vector—just a list of 1s and 0s, where you store a 1 if the corresponding float was greater than 0 and a 0 otherwise.
For the above example, this would start [1, 1, 0, 0, 0...]
Incredibly, it looks like the cosine distance between these 0 and 1 vectors captures much of the semantic relevant meaning present in the distance between the much more accurate vectors. This means you can use 1/32nd of the space and still get useful results!
Ce Gao here suggests a further optimization: use the binary vectors for a fast brute-force lookup of the top 200 matches, then run a more expensive re-ranking against those filtered values using the full floating point vectors.
Adaptive Retrieval with Matryoshka Embeddings (via) Nomic Embed v1 only came out two weeks ago, but the same team just released Nomic Embed v1.5 trained using a new technique called Matryoshka Representation.
This means that unlike v1 the v1.5 embeddings are resizable - instead of a fixed 768 dimension embedding vector you can trade size for quality and drop that size all the way down to 64, while still maintaining strong semantically relevant results.
Joshua Lochner build this interactive demo on top of Transformers.js which illustrates quite how well this works: it lets you embed a query, embed a series of potentially matching text sentences and then adjust the number of dimensions and see what impact it has on the results.
Announcing DuckDB 0.10.0.
Somewhat buried in this announcement: DuckDB has Fixed-Length Arrays now, along with array_cross_product(a1, a2), array_cosine_similarity(a1, a2) and array_inner_product(a1, a2) functions.
This means you can now use DuckDB to find related content (and other tricks) using vector embeddings!
Also notable:
DuckDB can now attach MySQL, Postgres, and SQLite databases in addition to databases stored in its own format. This allows data to be read into DuckDB and moved between these systems in a convenient manner, as attached databases are fully functional, appear just as regular tables, and can be updated in a safe, transactional manner.
llm-sentence-transformers 0.2. I added a new --trust-remote-code option when registering an embedding model, which means LLM can now run embeddings through the new Nomic AI nomic-embed-text-v1 model.
Introducing Nomic Embed: A Truly Open Embedding Model. A new text embedding model from Nomic AI which supports 8192 length sequences, claims better scores than many other models (including OpenAI’s new text-embedding-3-small) and is available as both a hosted API and a run-yourself model. The model is Apache 2 licensed and Nomic have released the full set of training data and code.
From the accompanying paper: “Full training of nomic-embed-text-v1 can be conducted in a single week on one 8xH100 node.”
ChunkViz (via) Handy tool by Greg Kamradt to help understand how different text chunking mechanisms work by visualizing them. Chunking is an important part of preparing text to be embedded for semantic search, and thanks to this tool I’ve finally got a solid mental model of what recursive character text splitting does.
ColBERT query-passage scoring interpretability (via) Neat interactive visualization tool for understanding what the ColBERT embedding model does—this works by loading around 50MB of model files directly into your browser and running them with WebAssembly.
Text Embeddings Reveal (Almost) As Much As Text. Embeddings of text—where a text string is converted into a fixed-number length array of floating point numbers—are demonstrably reversible: “a multi-step method that iteratively corrects and re-embeds text is able to recover 92% of 32-token text inputs exactly”.
This means that if you’re using a vector database for embeddings of private data you need to treat those embedding vectors with the same level of protection as the original text.
2023
Fleet Context. This project took the source code and documentation for 1221 popular Python libraries and ran them through the OpenAI text-embedding-ada-002 embedding model, then made those pre-calculated embedding vectors available as Parquet files for download from S3 or via a custom Python CLI tool.
I haven’t seen many projects release pre-calculated embeddings like this, it’s an interesting initiative.
Execute Jina embeddings with a CLI using llm-embed-jina
Berlin-based Jina AI just released a new family of embedding models, boasting that they are the “world’s first open-source 8K text embedding model” and that they rival OpenAI’s text-embedding-ada-002 in quality.
Embeddings: What they are and why they matter
Embeddings are a really neat trick that often come wrapped in a pile of intimidating jargon.
[... 5,835 words]Bottleneck T5 Text Autoencoder (via) Colab notebook by Linus Lee demonstrating his Contra Bottleneck T5 embedding model, which can take up to 512 tokens of text, convert that into a 1024 floating point number embedding vector... and then then reconstruct the original text (or a close imitation) from the embedding again.
This allows for some fascinating tricks, where you can do things like generate embeddings for two completely different sentences and then reconstruct a new sentence that combines the weights from both.
Finding Bathroom Faucets with Embeddings. Absolutely the coolest thing I’ve seen someone build on top of my LLM tool so far: Drew Breunig is renovating a bathroom and needed a way to filter through literally thousands of options for facet taps. He scraped 20,000 images of fixtures from a plumbing supply site and used LLM to embed every one of them via CLIP... and now he can ask for “faucets that look like this one”, or even run searches for faucets that match “Gawdy” or “Bond Villain” or “Nintendo 64”. Live demo included!
Weeknotes: Embeddings, more embeddings and Datasette Cloud
Since my last weeknotes, a flurry of activity. LLM has embeddings support now, and Datasette Cloud has driven some major improvements to the wider Datasette ecosystem.
[... 2,427 words]Build an image search engine with llm-clip, chat with models with llm chat

LLM is my combination CLI tool and Python library for working with Large Language Models. I just released LLM 0.10 with two significant new features: embedding support for binary files and the llm chat command.
Symbex 1.4. New release of my Symbex tool for finding symbols (functions, methods and classes) in a Python codebase. Symbex can now output matching symbols in JSON, CSV or TSV in addition to plain text.
I designed this feature for compatibility with the new “llm embed-multi” command—so you can now use Symbex to find every Python function in a nested directory and then pipe them to LLM to calculate embeddings for every one of them.
I tried it on my projects directory and embedded over 13,000 functions in just a few minutes! Next step is to figure out what kind of interesting things I can do with all of those embeddings.
LLM now provides tools for working with embeddings

LLM is my Python library and command-line tool for working with language models. I just released LLM 0.9 with a new set of features that extend LLM to provide tools for working with embeddings.
[... 3,521 words]Getting creative with embeddings (via) Amelia Wattenberger describes a neat application of embeddings I haven’t seen before: she wanted to build a system that could classify individual sentences in terms of how “concrete” or “abstract” they are. So she generated several example sentences for each of those categories, embedded then and calculated the average of those embeddings.
And now she can get a score for how abstract vs concrete a new sentence is by calculating its embedding and seeing where it falls in the 1500 dimension space between those two other points.
Vector Search. Amjith Ramanujam provides a very thorough tutorial on implementing vector similarity search using SentenceTransformers embeddings (all-MiniLM-L6-v2) executed using sqlite-utils, then served via datasette-sqlite-vss and deployed using Fly.
ImageBind. New model release from Facebook/Meta AI research: “An approach to learn a joint embedding across six different modalities—images, text, audio, depth, thermal, and IMU (inertial measurement units) data”. The non-interactive demo shows searching audio starting with an image, searching images starting with audio, using text to retrieve images and audio, using image and audio to retrieve images (e.g. a barking sound and a photo of a beach to get dogs on a beach) and using audio as input to an image generator.
Language models can explain neurons in language models (via) Fascinating interactive paper by OpenAI, describing how they used GPT-4 to analyze the concepts tracked by individual neurons in their much older GPT-2 model. “We generated cluster labels by embedding each neuron explanation using the OpenAI Embeddings API, then clustering them and asking GPT-4 to label each cluster.”
Browse the BBC In Our Time archive by Dewey decimal code. Matt Webb built Braggoscope, an alternative interface for browsing the 1,000 episodes of the BBC's In Our Time dating back to 1998, organized by Dewey decimal system and with related episodes calculated using OpenAI embeddings and guests and reading lists extracted using GPT-3.
Using GitHub Copilot to write code and calling out to GPT-3 programmatically to dodge days of graft actually brought tears to my eyes.
How to implement Q&A against your documentation with GPT3, embeddings and Datasette
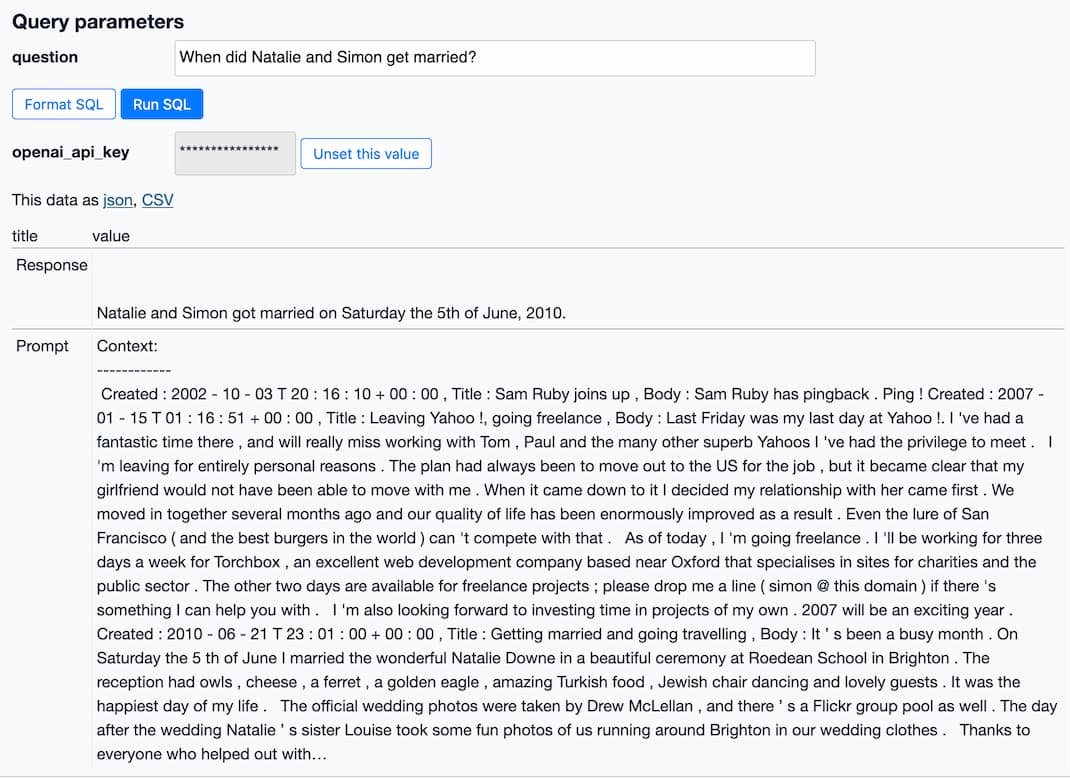
If you’ve spent any time with GPT-3 or ChatGPT, you’ve likely thought about how useful it would be if you could point them at a specific, current collection of text or documentation and have it use that as part of its input for answering questions.
[... 3,447 words]2022
Semantic text search using embeddings. Example Python notebook from OpenAI demonstrating how to build a search engine using embeddings rather than straight up token matching. This is a fascinating way of implementing search, providing results that match the intent of the search (“delicious beans” for example) even if none of the keywords are actually present in the text.
2018
Text Embedding Models Contain Bias. Here’s Why That Matters (via) Excellent discussion from the Google AI team of the enormous challenge of building machine learning models without accidentally encoding harmful bias in a way that cannot be easily detected.