7 posts tagged “gpt-oss”
OpenAI's family of open weight models.
2025
Video of GPT-OSS 20B running on a phone. GPT-OSS 20B is a very good model. At launch OpenAI claimed:
The gpt-oss-20b model delivers similar results to OpenAI o3‑mini on common benchmarks and can run on edge devices with just 16 GB of memory
Nexa AI just posted a video on Twitter demonstrating exactly that: the full GPT-OSS 20B running on a Snapdragon Gen 5 phone in their Nexa Studio Android app. It requires at least 16GB of RAM, and benefits from Snapdragon using a similar trick to Apple Silicon where the system RAM is available to both the CPU and the GPU.
The latest iPhone 17 Pro Max is still stuck at 12GB of RAM, presumably not enough to run this same model.
llama.cpp guide: running gpt-oss with llama.cpp
(via)
Really useful official guide to running the OpenAI gpt-oss models using llama-server from llama.cpp - which provides an OpenAI-compatible localhost API and a neat web interface for interacting with the models.
TLDR version for macOS to run the smaller gpt-oss-20b model:
brew install llama.cpp
llama-server -hf ggml-org/gpt-oss-20b-GGUF \
--ctx-size 0 --jinja -ub 2048 -b 2048 -ngl 99 -fa
This downloads a 12GB model file from ggml-org/gpt-oss-20b-GGUF on Hugging Face, stores it in ~/Library/Caches/llama.cpp/ and starts it running on port 8080.
You can then visit this URL to start interacting with the model:
http://localhost:8080/
On my 64GB M2 MacBook Pro it runs at around 82 tokens/second.
The guide also includes notes for running on NVIDIA and AMD hardware.
TIL: Running a gpt-oss eval suite against LM Studio on a Mac. The other day I learned that OpenAI published a set of evals as part of their gpt-oss model release, described in their cookbook on Verifying gpt-oss implementations.
I decided to try and run that eval suite on my own MacBook Pro, against gpt-oss-20b running inside of LM Studio.
TLDR: once I had the model running inside LM Studio with a longer than default context limit, the following incantation ran an eval suite in around 3.5 hours:
mkdir /tmp/aime25_openai
OPENAI_API_KEY=x \
uv run --python 3.13 --with 'gpt-oss[eval]' \
python -m gpt_oss.evals \
--base-url http://localhost:1234/v1 \
--eval aime25 \
--sampler chat_completions \
--model openai/gpt-oss-20b \
--reasoning-effort low \
--n-threads 2
My new TIL breaks that command down in detail and walks through the underlying eval - AIME 2025, which asks 30 questions (8 times each) that are defined using the following format:
{"question": "Find the sum of all integer bases $b>9$ for which $17_{b}$ is a divisor of $97_{b}$.", "answer": "70"}
Open weight LLMs exhibit inconsistent performance across providers
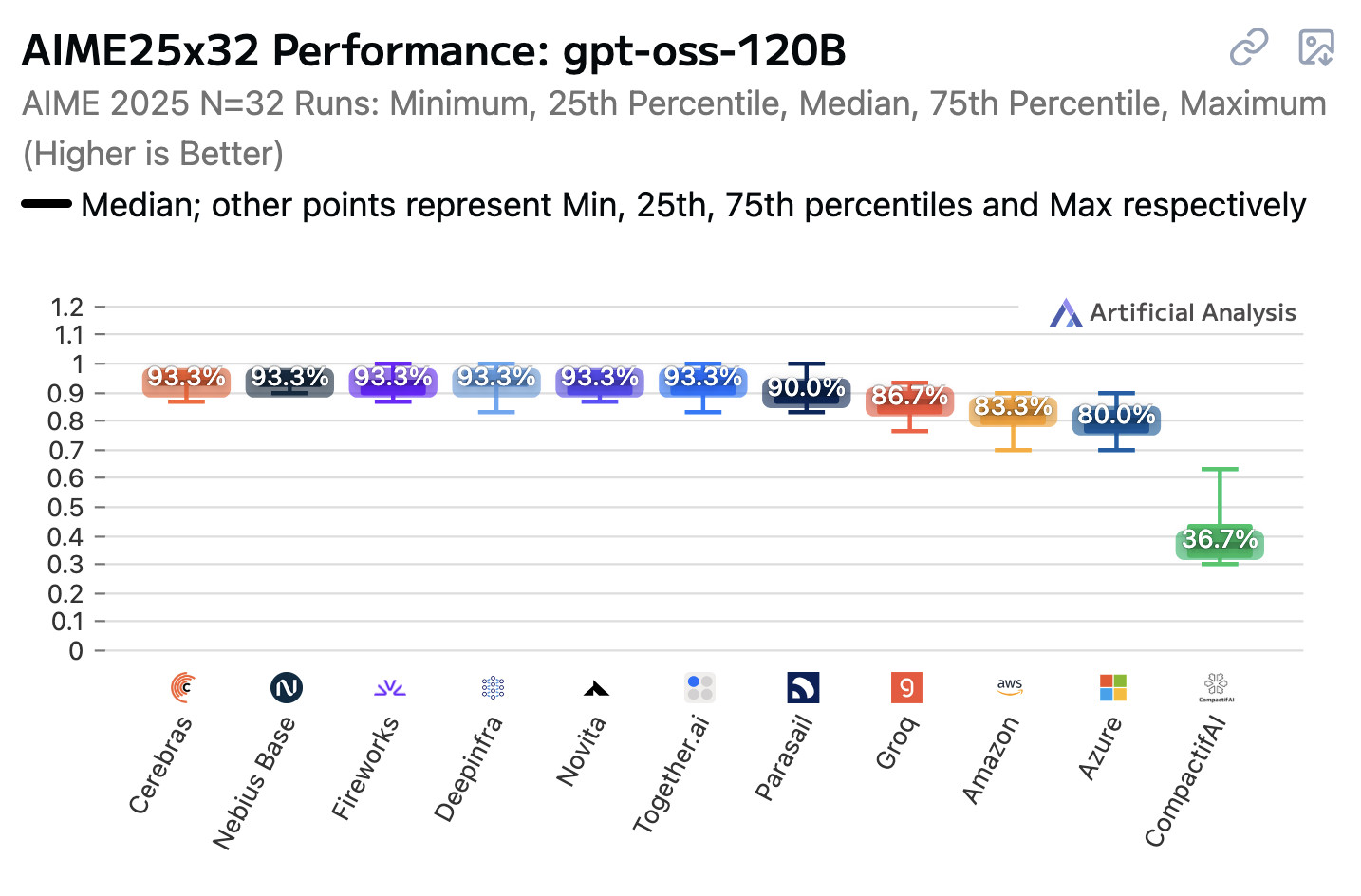
Artificial Analysis published a new benchmark the other day, this time focusing on how an individual model—OpenAI’s gpt-oss-120b—performs across different hosted providers.
[... 847 words]gpt-oss-120b is the most intelligent American open weights model, comes behind DeepSeek R1 and Qwen3 235B in intelligence but offers efficiency benefits [...]
We’re seeing the 120B beat o3-mini but come in behind o4-mini and o3. The 120B is the most intelligent model that can be run on a single H100 and the 20B is the most intelligent model that can be run on a consumer GPU. [...]
While the larger gpt-oss-120b does not come in above DeepSeek R1 0528’s score of 59 or Qwen3 235B 2507s score of 64, it is notable that it is significantly smaller in both total and active parameters than both of those models.
— Artificial Analysis, see also their updated leaderboard
OpenAI’s new open weight (Apache 2) models are really good
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]Something that has become undeniable this month is that the best available open weight models now come from the Chinese AI labs.
I continue to have a lot of love for Mistral, Gemma and Llama but my feeling is that Qwen, Moonshot and Z.ai have positively smoked them over the course of July.
Here's what came out this month, with links to my notes on each one:
- Moonshot Kimi-K2-Instruct - 11th July, 1 trillion parameters
- Qwen Qwen3-235B-A22B-Instruct-2507 - 21st July, 235 billion
- Qwen Qwen3-Coder-480B-A35B-Instruct - 22nd July, 480 billion
- Qwen Qwen3-235B-A22B-Thinking-2507 - 25th July, 235 billion
- Z.ai GLM-4.5 and GLM-4.5 Air - 28th July, 355 and 106 billion
- Qwen Qwen3-30B-A3B-Instruct-2507 - 29th July, 30 billion
- Qwen Qwen3-30B-A3B-Thinking-2507 - 30th July, 30 billion
- Qwen Qwen3-Coder-30B-A3B-Instruct - 31st July, 30 billion (released after I first posted this note)
Notably absent from this list is DeepSeek, but that's only because their last model release was DeepSeek-R1-0528 back in April.
The only janky license among them is Kimi K2, which uses a non-OSI-compliant modified MIT. Qwen's models are all Apache 2 and Z.ai's are MIT.
The larger Chinese models all offer their own APIs and are increasingly available from other providers. I've been able to run versions of the Qwen 30B and GLM-4.5 Air 106B models on my own laptop.
I can't help but wonder if part of the reason for the delay in release of OpenAI's open weights model comes from a desire to be notably better than this truly impressive lineup of Chinese models.
Update August 5th 2025: The OpenAI open weight models came out and they are very impressive.