21 posts tagged “graphql”
2025
GitHub issues is almost the best notebook in the world.
Free and unlimited, for both public and private notes.
Comprehensive Markdown support, including syntax highlighting for almost any language. Plus you can drag and drop images or videos directly onto a note.
It has fantastic inter-linking abilities. You can paste in URLs to other issues (in any other repository on GitHub) in a markdown list like this:
- https://github.com/simonw/llm/issues/1078
- https://github.com/simonw/llm/issues/1080
Your issue will pull in the title of the other issue, plus that other issue will get back a link to yours - taking issue visibility rules into account.
It has excellent search, both within a repo, across all of your repos or even across the whole of GitHub if you've completely forgotten where you put something.
It has a comprehensive API, both for exporting notes and creating and editing new ones. Add GitHub Actions, triggered by issue events, and you can automate it to do almost anything.
The one missing feature? Synchronized offline support. I still mostly default to Apple Notes on my phone purely because it works with or without the internet and syncs up with my laptop later on.
A few extra notes inspired by the discussion of this post on Hacker News:
- I'm not worried about privacy here. A lot of companies pay GitHub a lot of money to keep the source code and related assets safe. I do not think GitHub are going to sacrifice that trust to "train a model" or whatever.
- There is always the risk of bug that might expose my notes, across any note platform. That's why I keep things like passwords out of my notes!
- Not paying and not self-hosting is a very important feature. I don't want to risk losing my notes to a configuration or billing error!
- The thing where notes can include checklists using
- [ ] itemsyntax is really useful. You can even do- [ ] #refto reference another issue and the checkbox will be automatically checked when that other issue is closed. - I've experimented with a bunch of ways of backing up my notes locally, such as github-to-sqlite. I'm not running any of them on cron on a separate machine at the moment, but I really should!
- I'll go back to pen and paper as soon as my paper notes can be instantly automatically backed up to at least two different continents.
- GitHub issues also scales! microsoft/vscode has 195,376 issues. flutter/flutter has 106,572. I'm not going to run out of space.
- Having my notes in a format that's easy to pipe into an LLM is really fun. Here's a recent example where I summarized a 50+ comment, 1.5 year long issue thread into a new comment using llm-fragments-github.
I was curious how many issues and comments I've created on GitHub. With Claude's help I figured out you can get that using a GraphQL query:
{
viewer {
issueComments {
totalCount
}
issues {
totalCount
}
}
}
Running that with the GitHub GraphQL Explorer tool gave me this:
{
"data": {
"viewer": {
"issueComments": {
"totalCount": 39087
},
"issues": {
"totalCount": 9413
}
}
}
}
That's 48,500 combined issues and comments!
2024
The Super Effectiveness of Pokémon Embeddings Using Only Raw JSON and Images.
A deep dive into embeddings from Max Woolf, exploring 1,000 different Pokémon (loaded from PokéAPI using this epic GraphQL query) and then embedding the cleaned up JSON data using nomic-embed-text-v1.5 and the official Pokémon image representations using nomic-embed-vision-v1.5.
I hadn't seen nomic-embed-vision-v1.5 before: it brings multimodality to Nomic embeddings and operates in the same embedding space as nomic-embed-text-v1.5 which means you can use it to perform CLIP-style tricks comparing text and images. Here's their announcement from June 5th:
Together, Nomic Embed is the only unified embedding space that outperforms OpenAI CLIP and OpenAI Text Embedding 3 Small on multimodal and text tasks respectively.
Sadly the new vision weights are available under a non-commercial Creative Commons license (unlike the text weights which are Apache 2), so if you want to use the vision weights commercially you'll need to access them via Nomic's paid API.
Nomic do say this though:
As Nomic releases future models, we intend to re-license less recent models in our catalogue under the Apache-2.0 license.
Update 17th January 2025: Nomic Embed Vision 1.5 is now Apache 2.0 licensed.
Why, after 6 years, I’m over GraphQL (via) I've seen many of these criticisms of GraphQL before - N+1 queries, the difficulty of protecting against deeply nested queries - but Matt Bessey collects them all in one place and adds an issue I hadn't considered before: the complexity of authorization, where each field in the query might involve extra permission checks:
In my experience, this is actually the biggest source of performance issues. We would regularly find that our queries were spending more time authorising data than anything else.
The 600+ comment Hacker News thread is crammed with GraphQL war stories, mostly supporting the conclusions of the article.
2023
graphql-voyager. Neat tool for producing an interactive graph visualization of any GraphQL API. Click “Change schema” and then “Introspection” and it will give you a GraphQL query you can run against your own API—copy and paste back the JSON results and the visualizer will show you how your API fits together. I tested this against a datasette-graphql instance and it worked exactly as described.
2022
Retrospection and Learnings from Dgraph Labs (via) I was excited about Dgraph as an interesting option in the graph database space. It didn’t work out, and founder Manish Rai Jain provides a thoughtful retrospective as to why, full of useful insights for other startup founders considering projects in a similar space.
Help scraping: track changes to CLI tools by recording their --help using Git
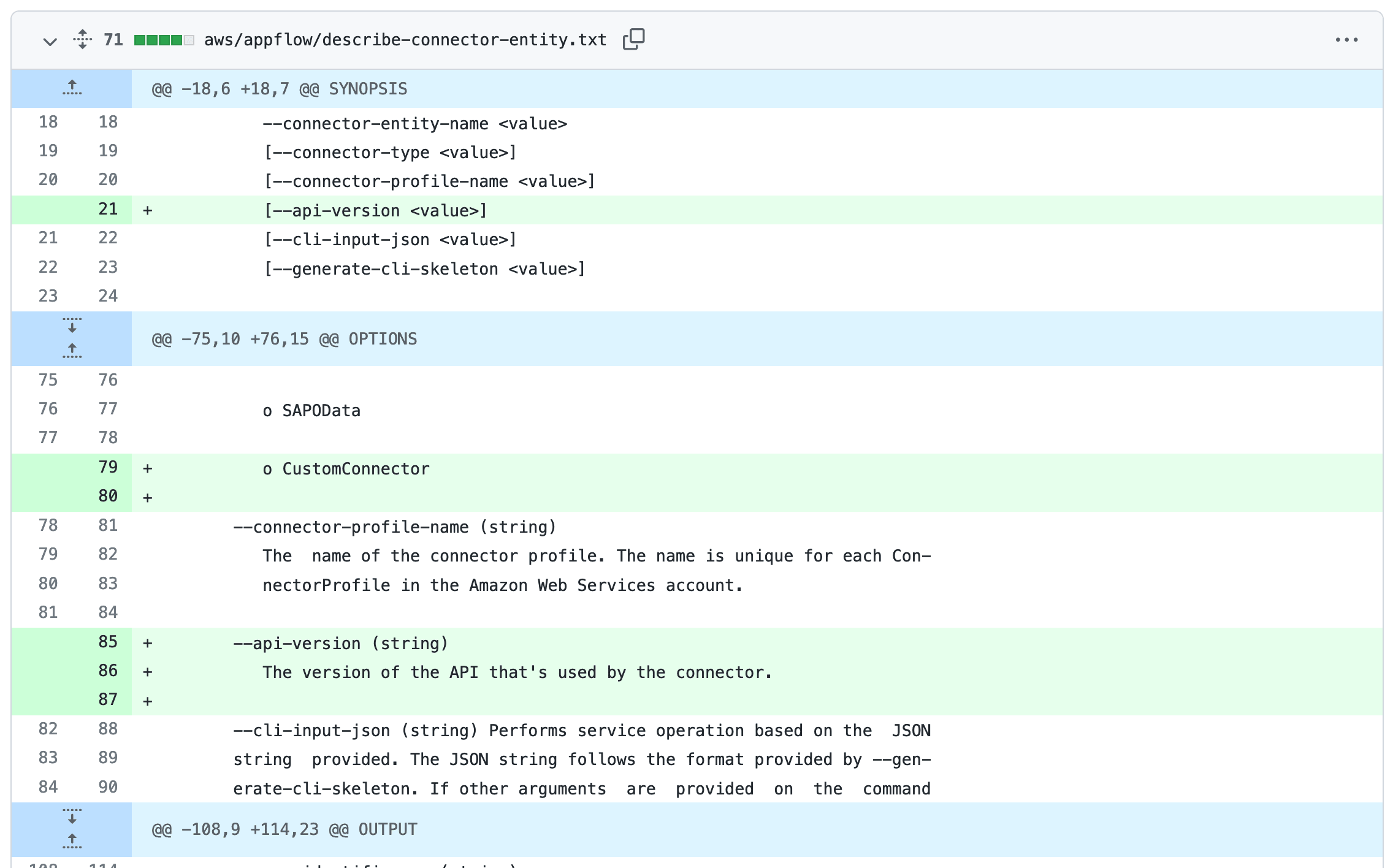
I’ve been experimenting with a new variant of Git scraping this week which I’m calling Help scraping. The key idea is to track changes made to CLI tools over time by recording the output of their --help commands in a Git repository.
2021
Weeknotes: sqlite-transform 1.1, Datasette 0.58.1, datasette-graphql 1.5
Work on Project Pelican inspires new features and improvements across a number of different projects.
[... 1,419 words]2020
Weeknotes: github-to-sqlite workflows, datasette-ripgrep enhancements, Datasette 0.52
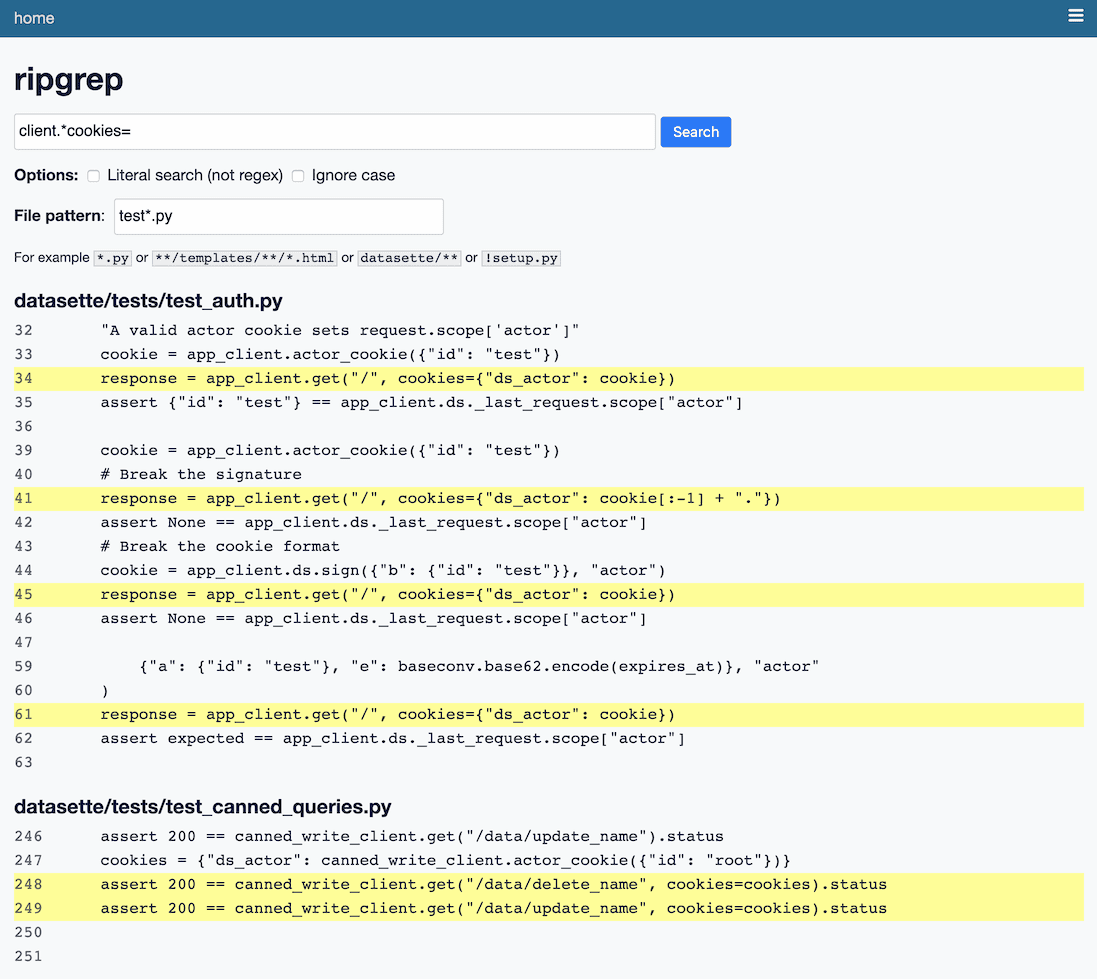
This week: Improvements to datasette-ripgrep, github-to-sqlite and datasette-graphql, plus Datasette 0.52 and a flurry of dot-releases.
Weeknotes: datasette-indieauth, datasette-graphql, PyCon Argentina

Last week’s weeknotes took the form of my Personal Data Warehouses: Reclaiming Your Data talk write-up, which represented most of what I got done that week. This week I mainly worked on datasette-indieauth, but I also gave a keynote at PyCon Argentina and released a version of datasette-graphql with a small security fix.
[... 724 words]datasette-graphql 1.2 (via) A new release of the datasette-graphql plugin, fixing a minor security flaw: previous versions of the plugin could expose the schema (but not the actual data) of tables in databases that were otherwise protected by Datasette’s permission system.
Datasette Weekly: Datasette 0.50, git scraping, extracting columns (via) The first edition of the new Datasette Weekly newsletter—covering Datasette 0.50, Git scraping, extracting columns with sqlite-utils and featuring datasette-graphql as the first “plugin of the week”
Refactoring databases with sqlite-utils extract

Yesterday I described the new sqlite-utils transform mechanism for applying SQLite table transformations that go beyond those supported by ALTER TABLE. The other new feature in sqlite-utils 2.20 builds on that capability to allow you to refactor a database table by extracting columns into separate tables. I’ve called it sqlite-utils extract.
Weeknotes: California Protected Areas in Datasette
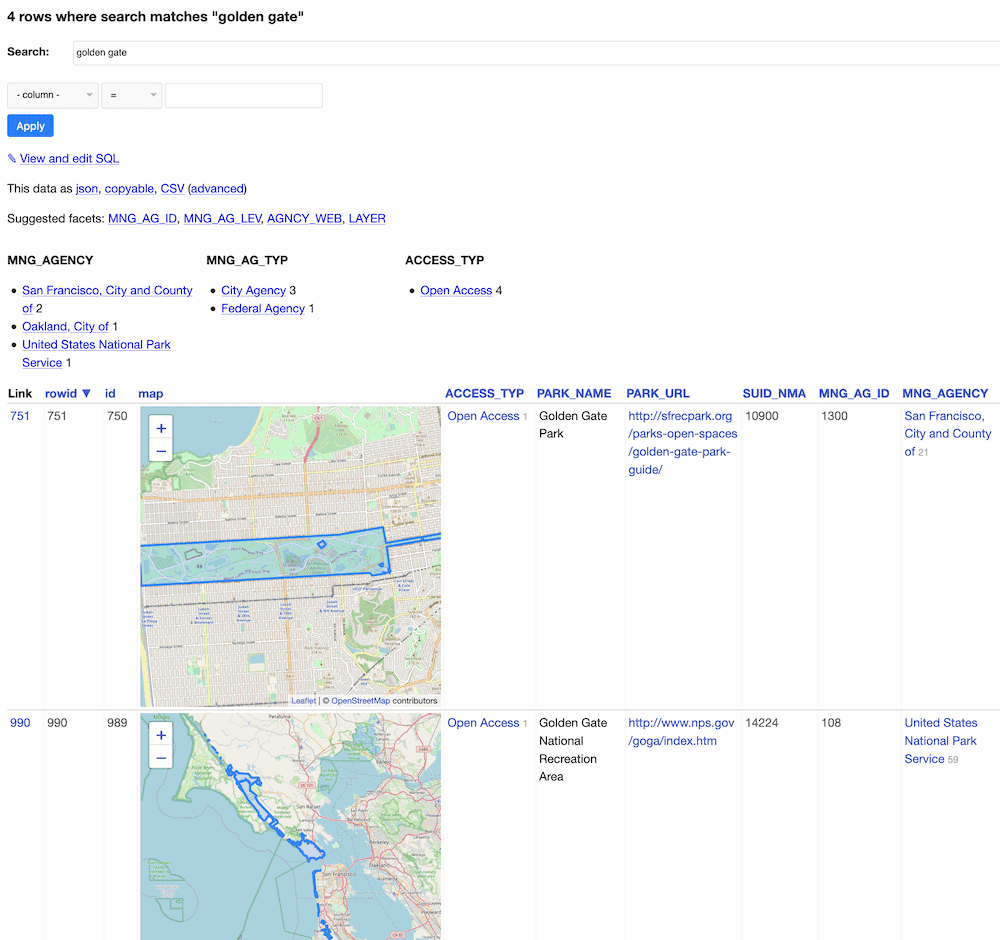
This week I built a geospatial search engine for protected areas in California, shipped datasette-graphql 1.0 and started working towards the next milestone for Datasette Cloud.
[... 1,099 words]Weeknotes: Rocky Beaches, Datasette 0.48, a commit history of my database
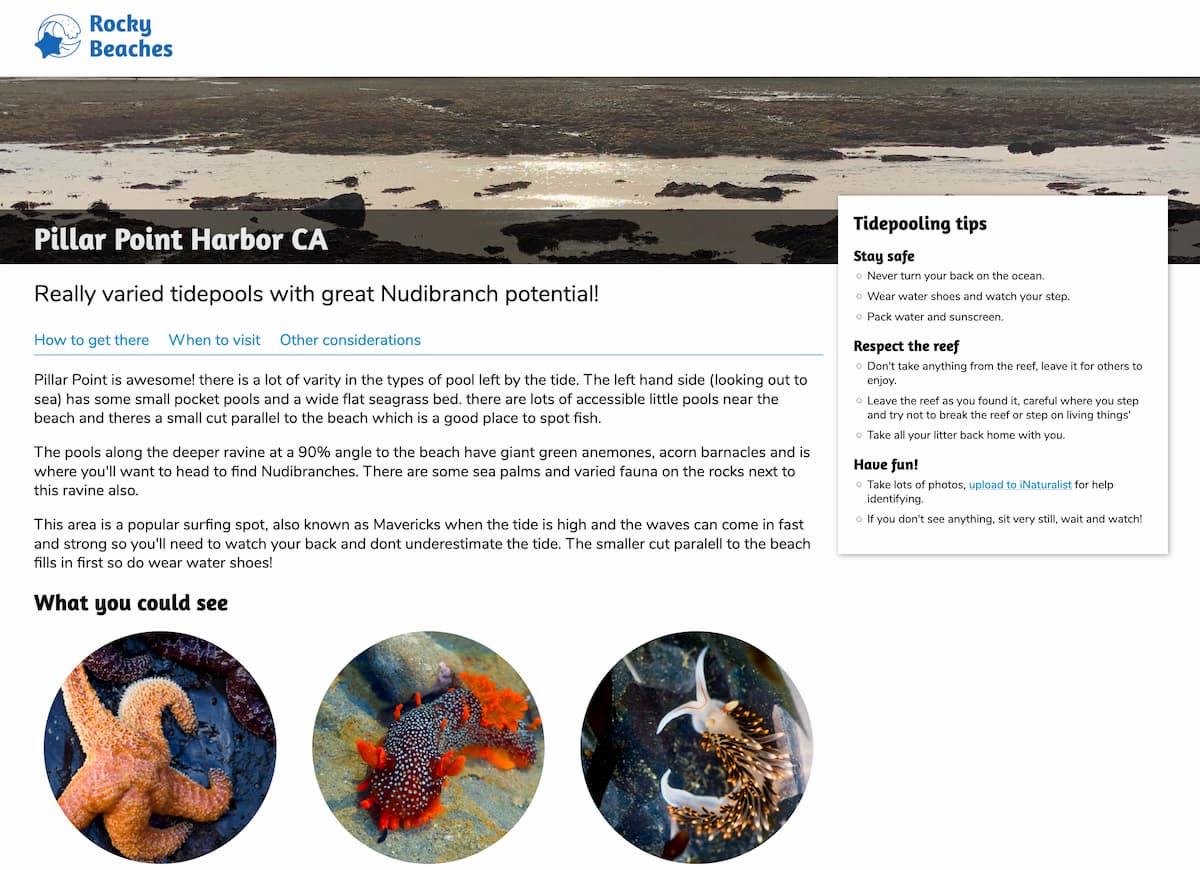
This week I helped Natalie launch Rocky Beaches, shipped Datasette 0.48 and several releases of datasette-graphql, upgraded the CSRF protection for datasette-upload-csvs and figured out how to get a commit log of changes to my blog by backing up its database to a GitHub repository.
Weeknotes: Installing Datasette with Homebrew, more GraphQL, WAL in SQLite
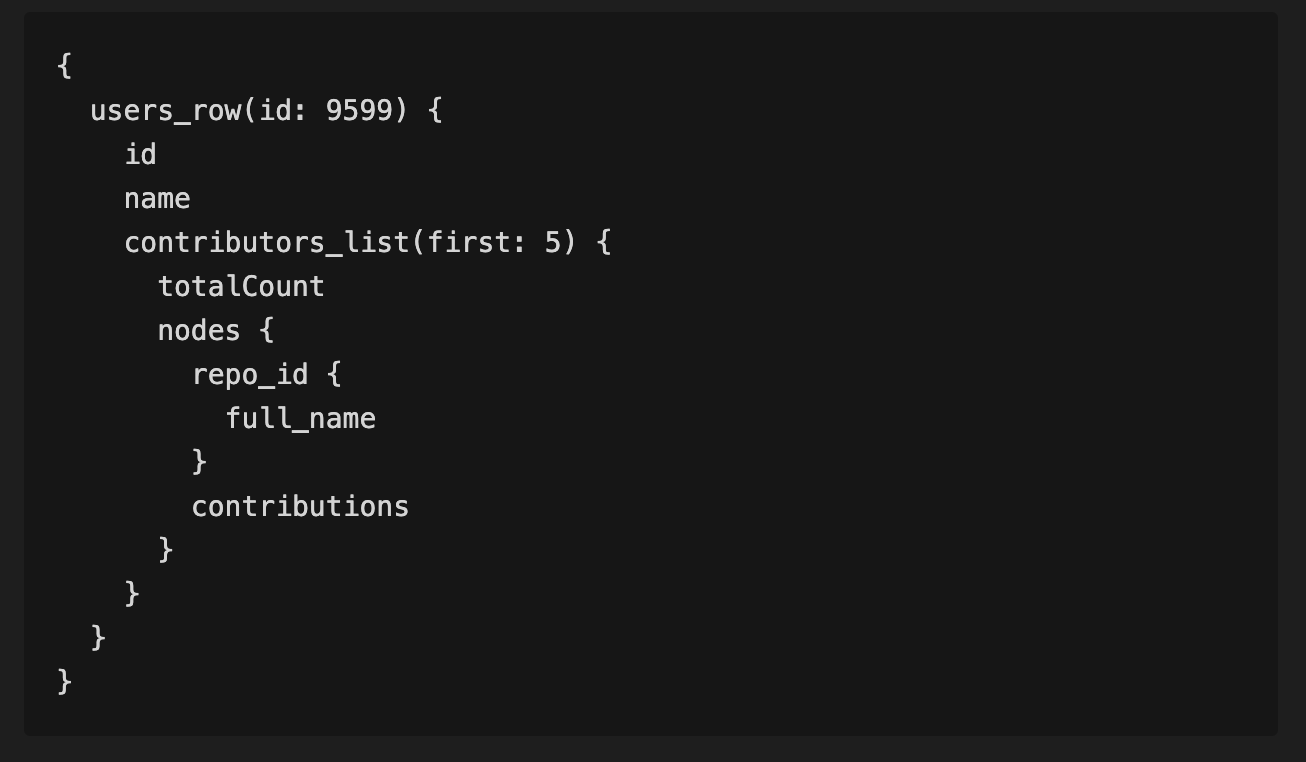
This week I’ve been working on making Datasette easier to install, plus wide-ranging improvements to the Datasette GraphQL plugin.
[... 1,009 words]GraphQL in Datasette with the new datasette-graphql plugin
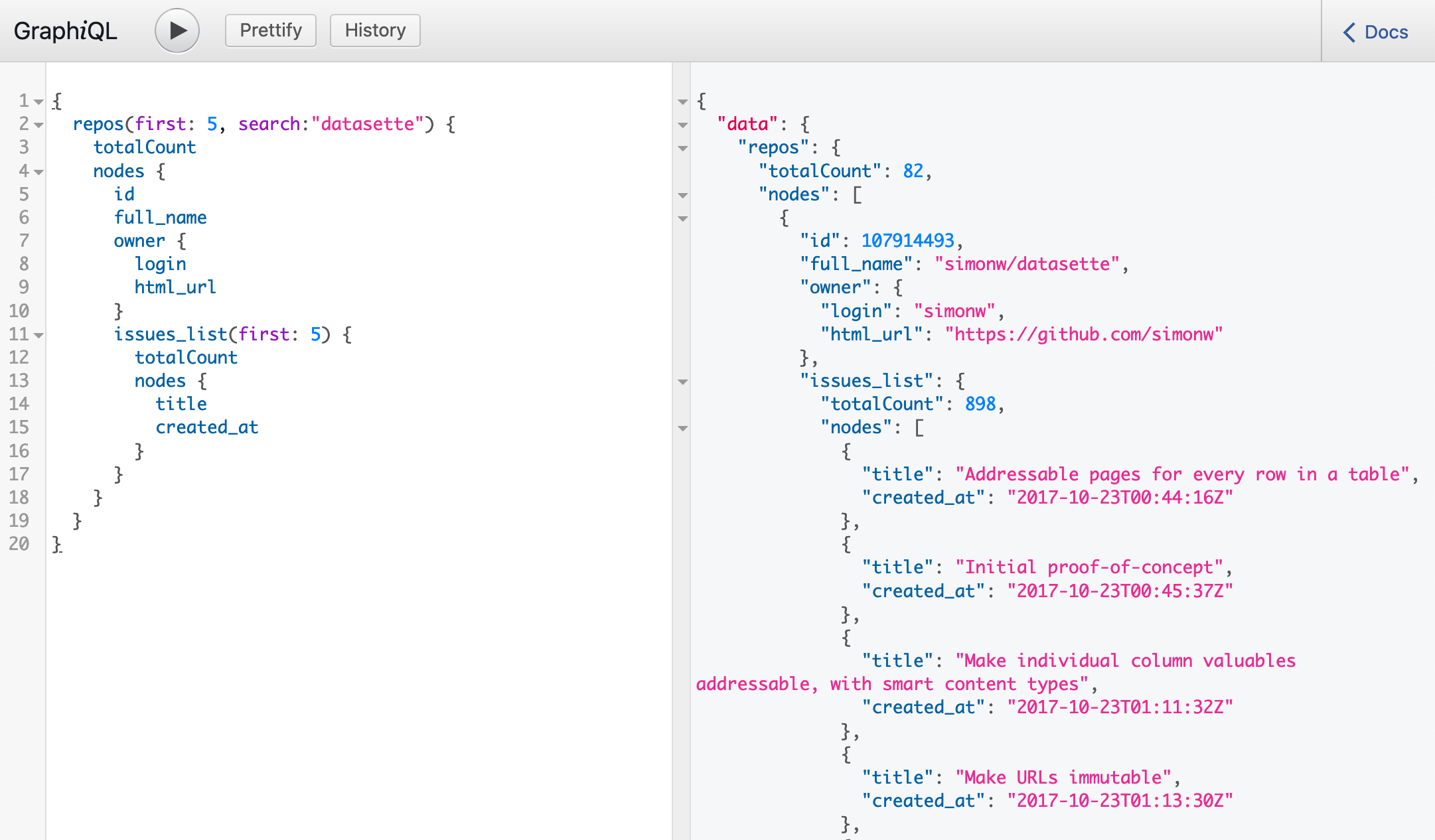
This week I’ve mostly been building datasette-graphql, a plugin that adds GraphQL query support to Datasette.
[... 1,249 words]Building a self-updating profile README for GitHub
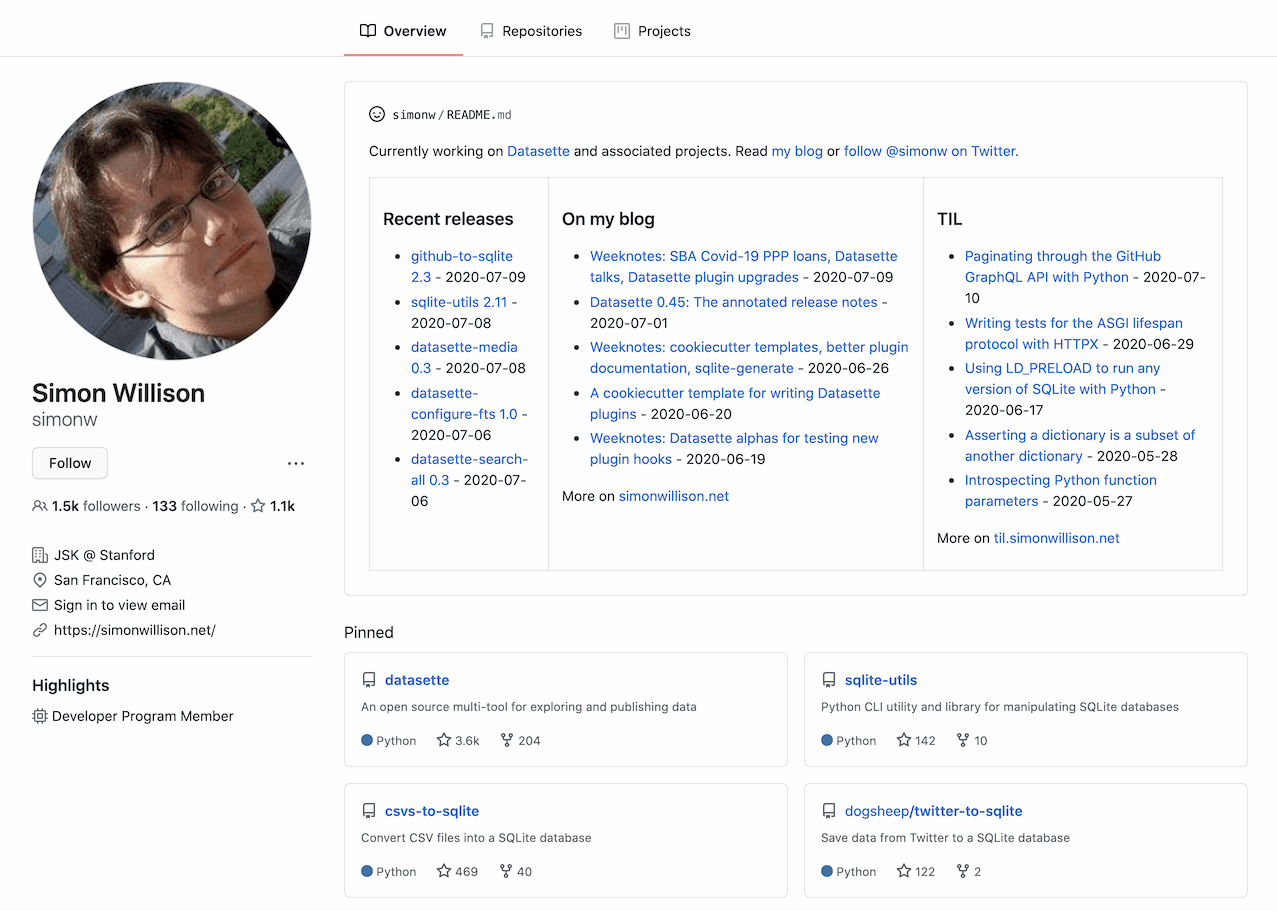
GitHub quietly released a new feature at some point in the past few days: profile READMEs. Create a repository with the same name as your GitHub account (in my case that’s github.com/simonw/simonw), add a README.md to it and GitHub will render the contents at the top of your personal profile page—for me that’s github.com/simonw
How Super Graph compiles GraphQL to a single SQL query. Super Graph is a GraphQL server that compiles arbitrarily nested GraphQL queries to “a single fast SQL query”. I’ve always wondered how that could possible work, so I asked author Vikram Rangnekar for an example of a compiled query—it turns out it uses a brilliant sequence of JSON aggregations to glue together results from nested subqueries and left outer joins.
SQL is a better API language than GraphQL – Convince me otherwise (via) A flippant tweet I posted this morning blew up today and ended up on the Hacker News homepage.
PostGraphile: Production Considerations. PostGraphile is a tool for building a GraphQL API on top of an existing PostgreSQL schema. Their “production considerations” documentation is particularly interesting because it directly addresses some of my biggest worries about GraphQL: the potential for someone to craft an expensive query that ties up server resources. PostGraphile suggests a number of techniques for avoiding this, including a statement timeout, a query allowlist, pagination caps and (in their “pro” version) a cost limit that uses a calculated cost score for the query.
2017
Select Transform: JSON Template over JSON (via) A barrage of interesting ideas here. Having clients transmit up a JSON template which is then executed against data on the server and used to return exactly the data the client needs is just one of them (significant overlap with GraphQL there).