12 posts tagged “litestream”
2026
The Design & Implementation of Sprites (via) I wrote about Sprites last week. Here's Thomas Ptacek from Fly with the insider details on how they work under the hood.
I like this framing of them as "disposable computers":
Sprites are ball-point disposable computers. Whatever mark you mean to make, we’ve rigged it so you’re never more than a second or two away from having a Sprite to do it with.
I've noticed that new Fly Machines can take a while (up to around a minute) to provision. Sprites solve that by keeping warm pools of unused machines in multiple regions, which is enabled by them all using the same container:
Now, today, under the hood, Sprites are still Fly Machines. But they all run from a standard container. Every physical worker knows exactly what container the next Sprite is going to start with, so it’s easy for us to keep pools of “empty” Sprites standing by. The result: a Sprite create doesn’t have any heavy lifting to do; it’s basically just doing the stuff we do when we start a Fly Machine.
The most interesting detail is how the persistence layer works. Sprites only charge you for data you have written that differs from the base image and provide ~300ms checkpointing and restores - it turns out that's power by a custom filesystem on top of S3-compatible storage coordinated by Litestream-replicated local SQLite metadata:
We still exploit NVMe, but not as the root of storage. Instead, it’s a read-through cache for a blob on object storage. S3-compatible object stores are the most trustworthy storage technology we have. I can feel my blood pressure dropping just typing the words “Sprites are backed by object storage.” [...]
The Sprite storage stack is organized around the JuiceFS model (in fact, we currently use a very hacked-up JuiceFS, with a rewritten SQLite metadata backend). It works by splitting storage into data (“chunks”) and metadata (a map of where the “chunks” are). Data chunks live on object stores; metadata lives in fast local storage. In our case, that metadata store is kept durable with Litestream. Nothing depends on local storage.
2025
Litestream v0.5.0 is Here (via) I've been running Litestream to backup SQLite databases in production for a couple of years now without incident. The new version has been a long time coming - Ben Johnson took a detour into the FUSE-based LiteFS before deciding that the single binary Litestream approach is more popular - and Litestream 0.5 just landed with this very detailed blog posts describing the improved architecture.
SQLite stores data in pages - 4096 (by default) byte blocks of data. Litestream replicates modified pages to a backup location - usually object storage like S3.
Most SQLite tables have an auto-incrementing primary key, which is used to decide which page the row's data should be stored in. This means sequential inserts to a small table are sent to the same page, which caused previous Litestream to replicate many slightly different copies of that page block in succession.
The new LTX format - borrowed from LiteFS - addresses that by adding compaction, which Ben describes as follows:
We can use LTX compaction to compress a bunch of LTX files into a single file with no duplicated pages. And Litestream now uses this capability to create a hierarchy of compactions:
- at Level 1, we compact all the changes in a 30-second time window
- at Level 2, all the Level 1 files in a 5-minute window
- at Level 3, all the Level 2’s over an hour.
Net result: we can restore a SQLite database to any point in time, using only a dozen or so files on average.
I'm most looking forward to trying out the feature that isn't quite landed yet: read-replicas, implemented using a SQLite VFS extension:
The next major feature we’re building out is a Litestream VFS for read replicas. This will let you instantly spin up a copy of the database and immediately read pages from S3 while the rest of the database is hydrating in the background.
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
2024
Zero-latency SQLite storage in every Durable Object (via) Kenton Varda introduces the next iteration of Cloudflare's Durable Object platform, which recently upgraded from a key/value store to a full relational system based on SQLite.
For useful background on the first version of Durable Objects take a look at Cloudflare's durable multiplayer moat by Paul Butler, who digs into its popularity for building WebSocket-based realtime collaborative applications.
The new SQLite-backed Durable Objects is a fascinating piece of distributed system design, which advocates for a really interesting way to architect a large scale application.
The key idea behind Durable Objects is to colocate application logic with the data it operates on. A Durable Object comprises code that executes on the same physical host as the SQLite database that it uses, resulting in blazingly fast read and write performance.
How could this work at scale?
A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different "shards" of a database), where each unit of state has low enough traffic to be handled by a single object
Kenton presents the example of a flight booking system, where each flight can map to a dedicated Durable Object with its own SQLite database - thousands of fresh databases per airline per day.
Each DO has a unique name, and Cloudflare's network then handles routing requests to that object wherever it might live on their global network.
The technical details are fascinating. Inspired by Litestream, each DO constantly streams a sequence of WAL entries to object storage - batched every 16MB or every ten seconds. This also enables point-in-time recovery for up to 30 days through replaying those logged transactions.
To ensure durability within that ten second window, writes are also forwarded to five replicas in separate nearby data centers as soon as they commit, and the write is only acknowledged once three of them have confirmed it.
The JavaScript API design is interesting too: it's blocking rather than async, because the whole point of the design is to provide fast single threaded persistence operations:
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?",
doc.authorId).one().name;
}This one of their examples deliberately exhibits the N+1 query pattern, because that's something SQLite is uniquely well suited to handling.
The system underlying Durable Objects is called Storage Relay Service, and it's been powering Cloudflare's existing-but-different D1 SQLite system for over a year.
I was curious as to where the objects are created. According to this (via Hacker News):
Durable Objects do not currently change locations after they are created. By default, a Durable Object is instantiated in a data center close to where the initial
get()request is made. [...] To manually create Durable Objects in another location, provide an optionallocationHintparameter toget().
And in a footnote:
Dynamic relocation of existing Durable Objects is planned for the future.
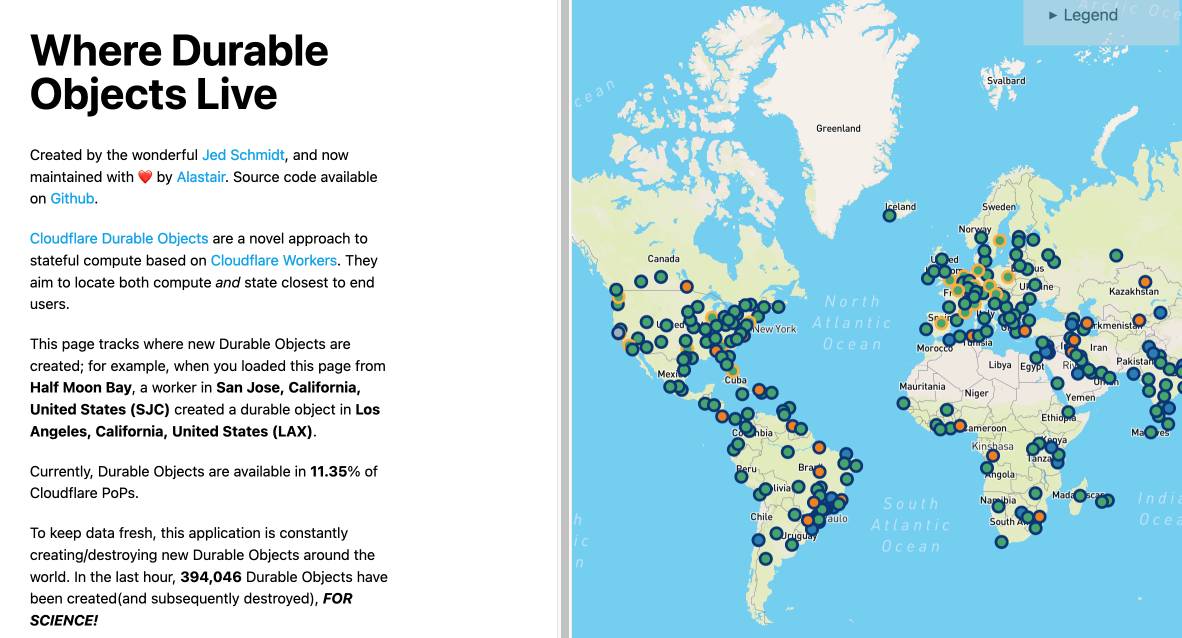
where.durableobjects.live is a neat site that tracks where in the Cloudflare network DOs are created - I just visited it and it said:
This page tracks where new Durable Objects are created; for example, when you loaded this page from Half Moon Bay, a worker in San Jose, California, United States (SJC) created a durable object in San Jose, California, United States (SJC).
2023
Introducing datasette-litestream: easy replication for SQLite databases in Datasette. We use Litestream on Datasette Cloud for streaming backups of user data to S3. Alex Garcia extracted out our implementation into a standalone Datasette plugin, which bundles the Litestream Go binary (for the relevant platform) in the package you get when you run “datasette install datasette-litestream”—so now Datasette has a very robust answer to questions about SQLite disaster recovery beyond just the Datasette Cloud platform.
2022
Stringing together several free tiers to host an application with zero cost using fly.io, Litestream and Cloudflare. Alexander Dahl provides a detailed description (and code) for his current preferred free hosting solution for small sites: SQLite (and a Go application) running on Fly’s free tier, with the database replicated up to Cloudflare’s R2 object storage (again on a free tier) by Litestream.
Introducing LiteFS (via) LiteFS is the new SQLite replication solution from Fly, now ready for beta testing. It’s from the same author as Litestream but has a very different architecture; LiteFS works by implementing a custom FUSE filesystem which spies on SQLite transactions being written to the journal file and forwards them on to other nodes in the cluster, providing full read-replication. The signature Litestream feature of streaming a backup to S3 should be coming within the next few months.
Litestream backups for Datasette Cloud (and weeknotes)
My main focus this week has been adding robust backups to the forthcoming Datasette Cloud.
[... 1,604 words]Litestream: Live Read Replication (via) The documentation for the read replication implemented in the latest Litestream beta (v0.4.0-beta.2). The design is really simple and clever: the primary runs a web server on a port, and replica instances can then be started with a configured URL pointing to the IP and port of the primary. That’s all it takes to have a SQLite database replicated to multiple hosts, each of which can then conduct read queries against their local copies.
SQLite Happy Hour—a Twitter Spaces conversation about three interesting projects building on SQLite
Yesterday I hosted SQLite Happy Hour. my first conversation using Twitter Spaces. The idea was to dig into three different projects that were doing interesting things on top of SQLite. I think it worked pretty well, and I’m curious to explore this format more in the future.
[... 1,998 words]2021
logpaste (via) Useful example of how to use the Litestream SQLite replication tool in a Dockerized application: S3 credentials are passed to the container on startup, it then attempts to restore the SQLite database from S3 and starts a Litestream process in the same container to periodically synchronize changes back up to the S3 bucket.
Litestream runs continuously on a test server with generated load and streams backups to S3. It uses physical replication so it'll actually restore the data from S3 periodically and compare the checksum byte-for-byte with the current database.