27 posts tagged “llama-cpp”
llama.cpp is an LLM inference library written in C/C++.
2026
ggml.ai joins Hugging Face to ensure the long-term progress of Local AI (via) I don't normally cover acquisition news like this, but I have some thoughts.
It's hard to overstate the impact Georgi Gerganov has had on the local model space. Back in March 2023 his release of llama.cpp made it possible to run a local LLM on consumer hardware. The original README said:
The main goal is to run the model using 4-bit quantization on a MacBook. [...] This was hacked in an evening - I have no idea if it works correctly.
I wrote about trying llama.cpp out at the time in Large language models are having their Stable Diffusion moment:
I used it to run the 7B LLaMA model on my laptop last night, and then this morning upgraded to the 13B model—the one that Facebook claim is competitive with GPT-3.
Meta's original LLaMA release depended on PyTorch and their FairScale PyTorch extension for running on multiple GPUs, and required CUDA and NVIDIA hardware. Georgi's work opened that up to a much wider range of hardware and kicked off the local model movement that has continued to grow since then.
Hugging Face are already responsible for the incredibly influential Transformers library used by the majority of LLM releases today. They've proven themselves a good steward for that open source project, which makes me optimistic for the future of llama.cpp and related projects.
This section from the announcement looks particularly promising:
Going forward, our joint efforts will be geared towards the following objectives:
- Towards seamless "single-click" integration with the transformers library. The
transformersframework has established itself as the 'source of truth' for AI model definitions. Improving the compatibility between the transformers and the ggml ecosystems is essential for wider model support and quality control.- Better packaging and user experience of ggml-based software. As we enter the phase in which local inference becomes a meaningful and competitive alternative to cloud inference, it is crucial to improve and simplify the way in which casual users deploy and access local models. We will work towards making llama.cpp ubiquitous and readily available everywhere, and continue partnering with great downstream projects.
Given the influence of Transformers, this closer integration could lead to model releases that are compatible with the GGML ecosystem out of the box. That would be a big win for the local model ecosystem.
I'm also excited to see investment in "packaging and user experience of ggml-based software". This has mostly been left to tools like Ollama and LM Studio. ggml-org released LlamaBarn last year - "a macOS menu bar app for running local LLMs" - and I'm hopeful that further investment in this area will result in more high quality open source tools for running local models from the team best placed to deliver them.
2025
NVIDIA DGX Spark: great hardware, early days for the ecosystem

NVIDIA sent me a preview unit of their new DGX Spark desktop “AI supercomputer”. I’ve never had hardware to review before! You can consider this my first ever sponsored post if you like, but they did not pay me any cash and aside from an embargo date they did not request (nor would I grant) any editorial input into what I write about the device.
[... 1,846 words]llama.cpp guide: running gpt-oss with llama.cpp
(via)
Really useful official guide to running the OpenAI gpt-oss models using llama-server from llama.cpp - which provides an OpenAI-compatible localhost API and a neat web interface for interacting with the models.
TLDR version for macOS to run the smaller gpt-oss-20b model:
brew install llama.cpp
llama-server -hf ggml-org/gpt-oss-20b-GGUF \
--ctx-size 0 --jinja -ub 2048 -b 2048 -ngl 99 -fa
This downloads a 12GB model file from ggml-org/gpt-oss-20b-GGUF on Hugging Face, stores it in ~/Library/Caches/llama.cpp/ and starts it running on port 8080.
You can then visit this URL to start interacting with the model:
http://localhost:8080/
On my 64GB M2 MacBook Pro it runs at around 82 tokens/second.
The guide also includes notes for running on NVIDIA and AMD hardware.
llm-llama-server 0.2. Here's a second option for using LLM's new tool support against local models (the first was via llm-ollama).
It turns out the llama.cpp ecosystem has pretty robust OpenAI-compatible tool support already, so my llm-llama-server plugin only needed a quick upgrade to get those working there.
Unfortunately it looks like streaming support doesn't work with tools in llama-server at the moment, so I added a new model ID called llama-server-tools which disables streaming and enables tools.
Here's how to try it out. First, ensure you have llama-server - the easiest way to get that on macOS is via Homebrew:
brew install llama.cpp
Start the server running like this. This command will download and cache the 3.2GB unsloth/gemma-3-4b-it-GGUF:Q4_K_XL if you don't yet have it:
llama-server --jinja -hf unsloth/gemma-3-4b-it-GGUF:Q4_K_XL
Then in another window:
llm install llm-llama-server
llm -m llama-server-tools -T llm_time 'what time is it?' --td
And since you don't even need an API key for this, even if you've never used LLM before you can try it out with this uvx one-liner:
uvx --with llm-llama-server llm -m llama-server-tools -T llm_time 'what time is it?' --td
For more notes on using llama.cpp with LLM see Trying out llama.cpp’s new vision support from a couple of weeks ago.
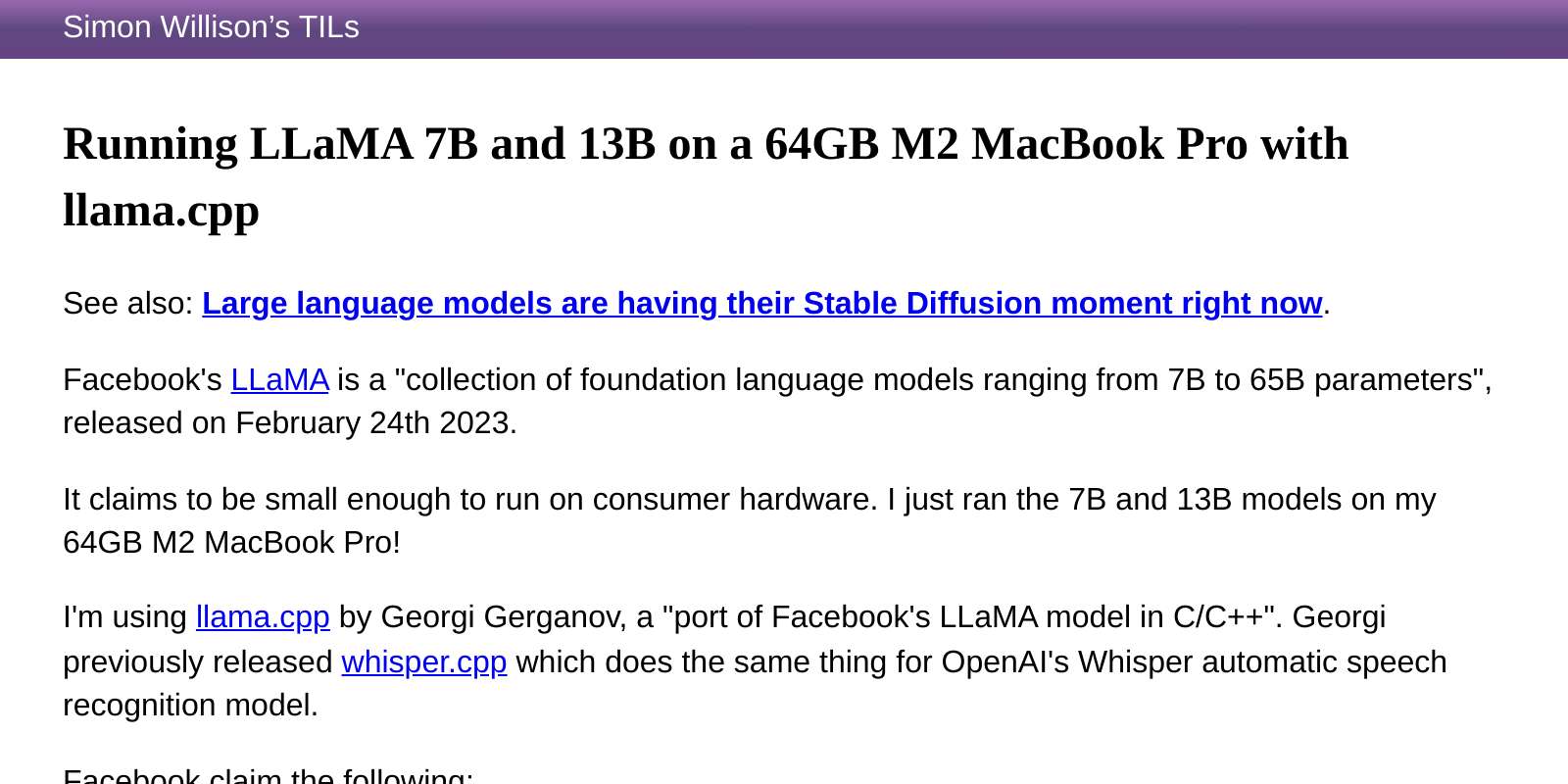
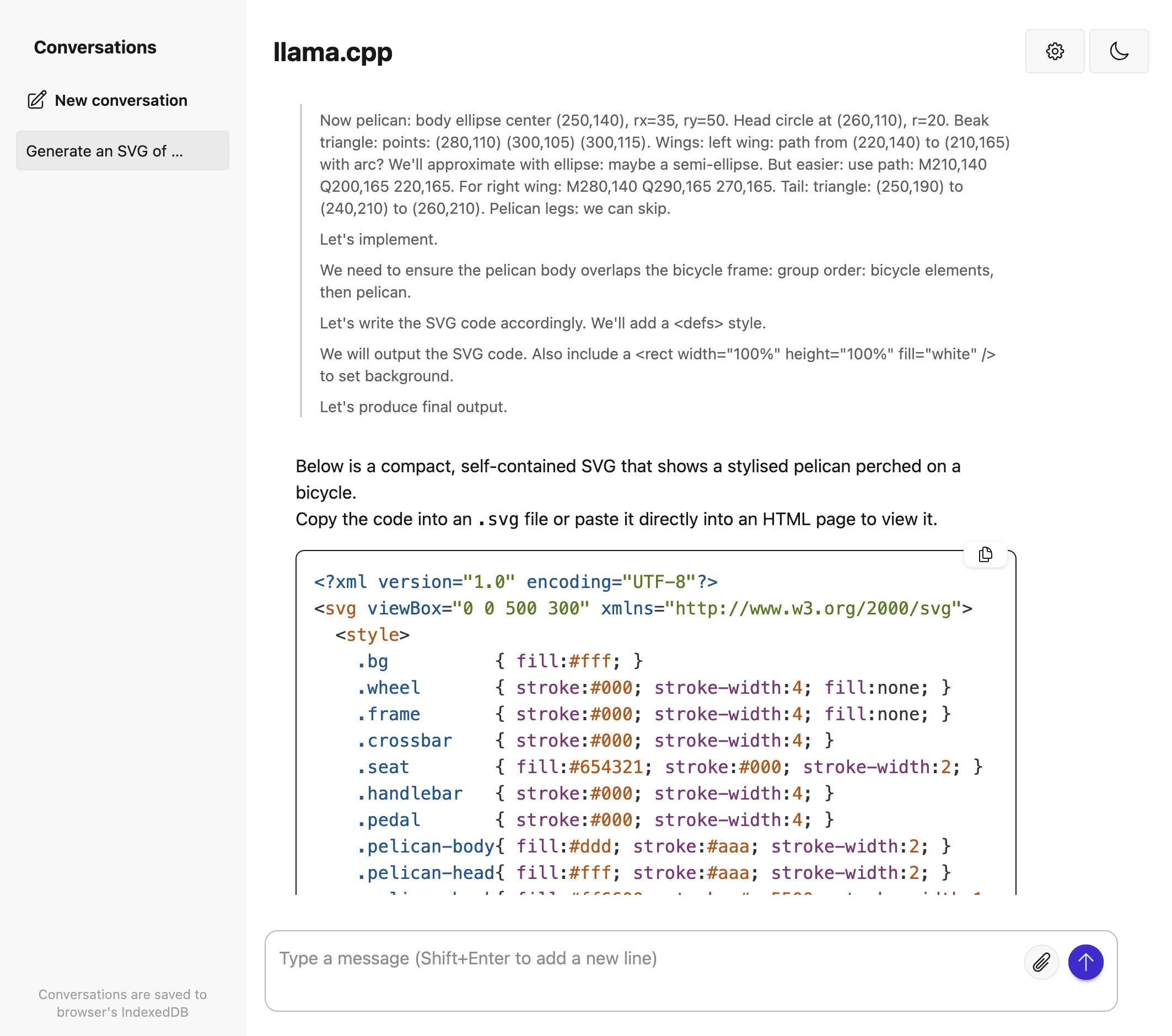
Trying out llama.cpp’s new vision support
This llama.cpp server vision support via libmtmd pull request—via Hacker News—was merged earlier today. The PR finally adds full support for vision models to the excellent llama.cpp project. It’s documented on this page, but the more detailed technical details are covered here. Here are my notes on getting it working on a Mac.
[... 1,693 words]Using pip to install a Large Language Model that’s under 100MB
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]ggml : x2 speed for WASM by optimizing SIMD
(via)
PR by Xuan-Son Nguyen for llama.cpp:
This PR provides a big jump in speed for WASM by leveraging SIMD instructions for
qX_K_q8_KandqX_0_q8_0dot product functions.Surprisingly, 99% of the code in this PR is written by DeekSeek-R1. The only thing I do is to develop tests and write prompts (with some trails and errors)
They shared their prompts here, which they ran directly through R1 on chat.deepseek.com - it spent 3-5 minutes "thinking" about each prompt.
I've been seeing some very promising results from DeepSeek R1 for code as well. Here's a recent transcript where I used it to rewrite the llm_groq.py plugin to imitate the cached model JSON pattern used by llm_mistral.py, resulting in this PR.
I tried the same thing against o1, but I think DeepSeek R1 did it better. In particular, from the R1 chain of thought:
Wait, but in the model_map, "groq-gemma" maps to "gemma-7b-it". So, perhaps the model_map is needed to map the local model IDs to the actual Groq model names.
But since the model_map is hardcoded, and the API returns available models, perhaps the model_map should be built dynamically from the API response.
Alternatively, perhaps the model_map can be eliminated, and the models are registered based on the fetched models.
Wait, perhaps the model_map is no longer necessary. Instead, when the models are fetched from the API, each model's "id" is the actual model name used in the Groq API. So, when registering the models, the local model ID is "groq-{id}", and the groq_model_id is "id".
(It thought about model_map a lot before finally deciding to eliminate it, which was also my preferred resolution.)
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra
2024
llm-gguf 0.2, now with embeddings. This new release of my llm-gguf plugin - which provides support for locally hosted GGUF LLMs - adds a new feature: it now supports embedding models distributed as GGUFs as well.
This means you can use models like the bafflingly small (30.8MB in its smallest quantization) mxbai-embed-xsmall-v1 with LLM like this:
llm install llm-gguf
llm gguf download-embed-model \
'https://huggingface.co/mixedbread-ai/mxbai-embed-xsmall-v1/resolve/main/gguf/mxbai-embed-xsmall-v1-q8_0.gguf'
Then to embed a string:
llm embed -m gguf/mxbai-embed-xsmall-v1-q8_0 -c 'hello'
The LLM docs have extensive coverage of things you can then do with this model, like embedding every row in a CSV file / file in a directory / record in a SQLite database table and running similarity and semantic search against them.
Under the hood this takes advantage of the create_embedding() method provided by the llama-cpp-python wrapper around llama.cpp.
Everything I’ve learned so far about running local LLMs (via) Chris Wellons shares detailed notes on his experience running local LLMs on Windows - though most of these tips apply to other operating systems as well.
This is great, there's a ton of detail here and the root recommendations are very solid: Use llama-server from llama.cpp and try ~8B models first (Chris likes Llama 3.1 8B Instruct at Q4_K_M as a first model), anything over 10B probably won't run well on a CPU so you'll need to consider your available GPU VRAM.
This is neat:
Just for fun, I ported llama.cpp to Windows XP and ran a 360M model on a 2008-era laptop. It was magical to load that old laptop with technology that, at the time it was new, would have been worth billions of dollars.
I need to spend more time with Chris's favourite models, Mistral-Nemo-2407 (12B) and Qwen2.5-14B/72B.
Chris also built illume, a Go CLI tool for interacting with models that looks similar to my own LLM project.
Introducing sqlite-lembed: A SQLite extension for generating text embeddings locally (via) Alex Garcia's latest SQLite extension is a C wrapper around the llama.cpp that exposes just its embedding support, allowing you to register a GGUF file containing an embedding model:
INSERT INTO temp.lembed_models(name, model)
select 'all-MiniLM-L6-v2',
lembed_model_from_file('all-MiniLM-L6-v2.e4ce9877.q8_0.gguf');
And then use it to calculate embeddings as part of a SQL query:
select lembed(
'all-MiniLM-L6-v2',
'The United States Postal Service is an independent agency...'
); -- X'A402...09C3' (1536 bytes)
all-MiniLM-L6-v2.e4ce9877.q8_0.gguf here is a 24MB file, so this should run quite happily even on machines without much available RAM.
What if you don't want to run the models locally at all? Alex has another new extension for that, described in Introducing sqlite-rembed: A SQLite extension for generating text embeddings from remote APIs. The rembed is for remote embeddings, and this extension uses Rust to call multiple remotely-hosted embeddings APIs, registered like this:
INSERT INTO temp.rembed_clients(name, options)
VALUES ('text-embedding-3-small', 'openai');
select rembed(
'text-embedding-3-small',
'The United States Postal Service is an independent agency...'
); -- X'A452...01FC', Blob<6144 bytes>
Here's the Rust code that implements Rust wrapper functions for HTTP JSON APIs from OpenAI, Nomic, Cohere, Jina, Mixedbread and localhost servers provided by Ollama and Llamafile.
Both of these extensions are designed to complement Alex's sqlite-vec extension, which is nearing a first stable release.
gemma-2-27b-it-llamafile (via) Justine Tunney shipped llamafile packages of Google's new openly licensed (though definitely not open source) Gemma 2 27b model this morning.
I downloaded the gemma-2-27b-it.Q5_1.llamafile version (20.5GB) to my Mac, ran chmod 755 gemma-2-27b-it.Q5_1.llamafile and then ./gemma-2-27b-it.Q5_1.llamafile and now I'm trying it out through the llama.cpp default web UI in my browser. It works great.
It's a very capable model - currently sitting at position 12 on the LMSYS Arena making it the highest ranked open weights model - one position ahead of Llama-3-70b-Instruct and within striking distance of the GPT-4 class models.
GGML GGUF File Format Vulnerabilities. The GGML and GGUF formats are used by llama.cpp to package and distribute model weights.
Neil Archibald: “The GGML library performs insufficient validation on the input file and, therefore, contains a selection of potentially exploitable memory corruption vulnerabilities during parsing.”
These vulnerabilities were shared with the library authors on 23rd January and patches landed on the 29th.
If you have a llama.cpp or llama-cpp-python installation that’s more than a month old you should upgrade ASAP.
GGUF, the long way around (via) Vicki Boykis dives deep into the GGUF format used by llama.cpp, after starting with a detailed description of how PyTorch models work and how they are traditionally persisted using Python pickle.
Pickle lead to safetensors, a format that avoided the security problems with downloading and running untrusted pickle files.
Llama.cpp introduced GGML, which popularized 16-bit (as opposed to 32-bit) quantization and bundled metadata and tensor data in a single file.
GGUF fixed some design flaws in GGML and is the default format used by Llama.cpp today.
2023
Many options for running Mistral models in your terminal using LLM
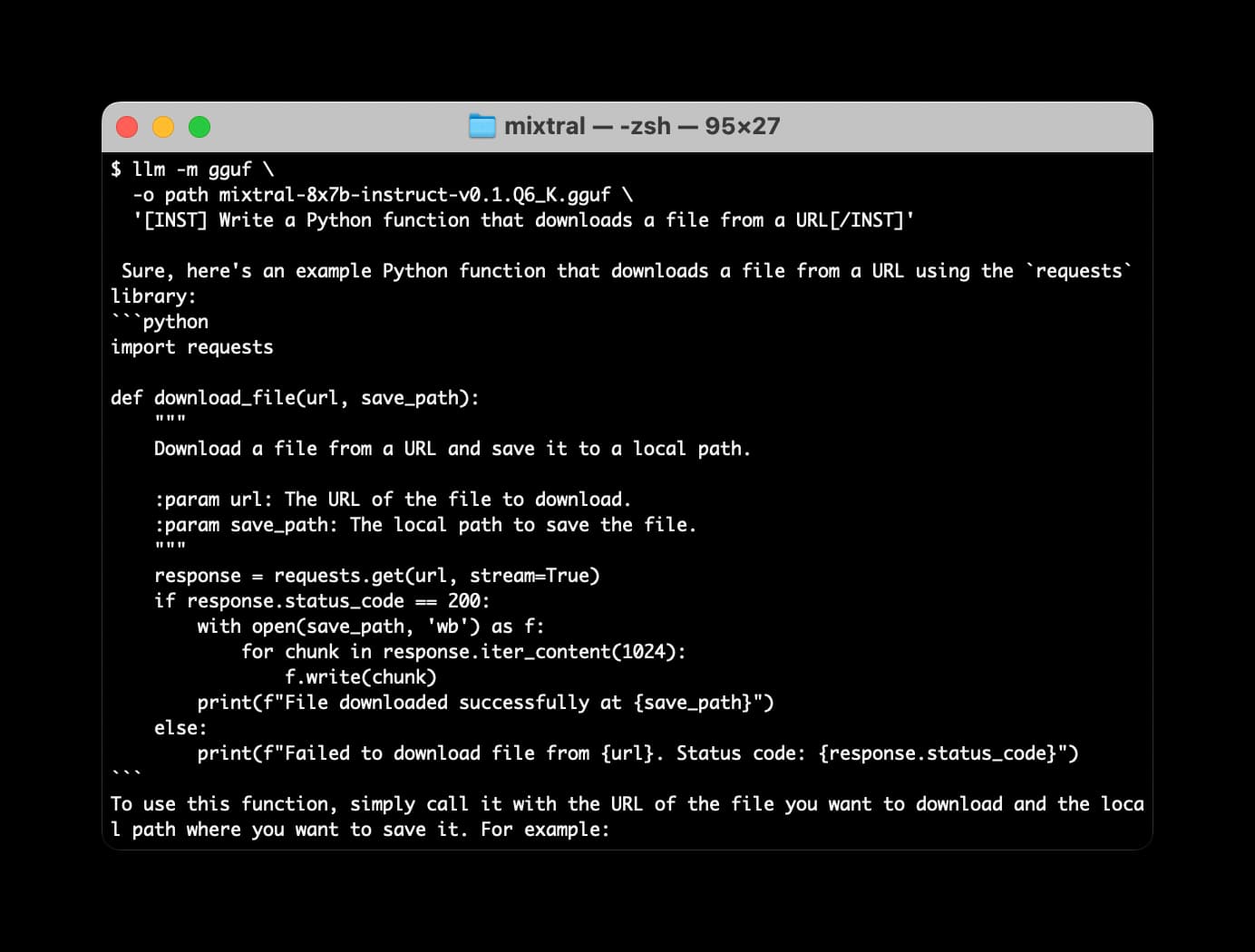
Mistral AI is the most exciting AI research lab at the moment. They’ve now released two extremely powerful smaller Large Language Models under an Apache 2 license, and have a third much larger one that’s available via their API.
[... 2,063 words]llamafile is the new best way to run an LLM on your own computer
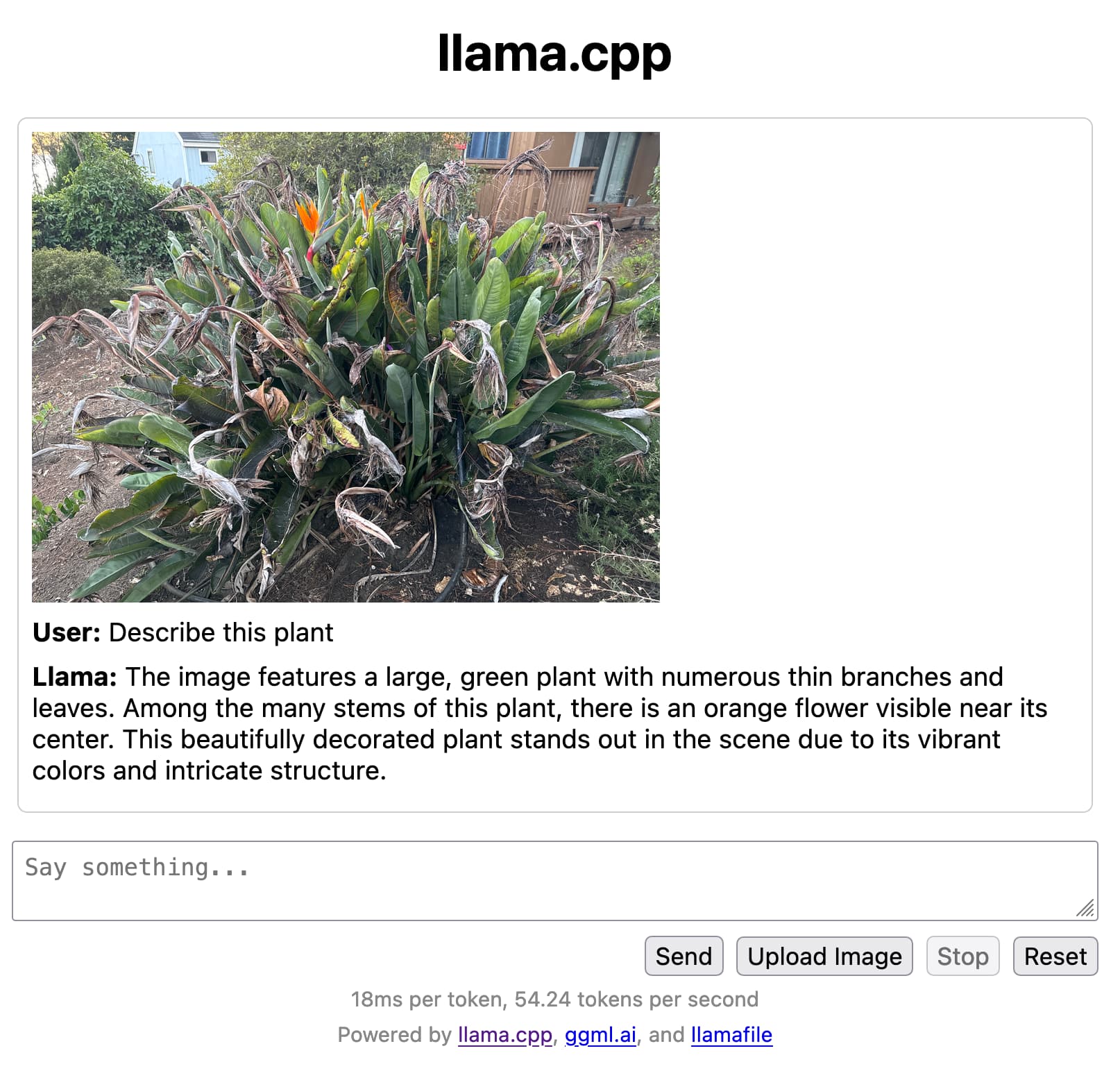
Mozilla’s innovation group and Justine Tunney just released llamafile, and I think it’s now the single best way to get started running Large Language Models (think your own local copy of ChatGPT) on your own computer.
[... 650 words]llama.cpp surprised many people (myself included) with how quickly you can run large LLMs on small computers [...] TLDR at batch_size=1 (i.e. just generating a single stream of prediction on your computer), the inference is super duper memory-bound. The on-chip compute units are twiddling their thumbs while sucking model weights through a straw from DRAM. [...] A100: 1935 GB/s memory bandwidth, 1248 TOPS. MacBook M2: 100 GB/s, 7 TFLOPS. The compute is ~200X but the memory bandwidth only ~20X. So the little M2 chip that could will only be about ~20X slower than a mighty A100.
Run Llama 2 on your own Mac using LLM and Homebrew
Llama 2 is the latest commercially usable openly licensed Large Language Model, released by Meta AI a few weeks ago. I just released a new plugin for my LLM utility that adds support for Llama 2 and many other llama-cpp compatible models.
[... 1,423 words]llama2-mac-gpu.sh (via) Adrien Brault provided this recipe for compiling llama.cpp on macOS with GPU support enabled (“LLAMA_METAL=1 make”) and then downloading and running a GGML build of Llama 2 13B.
Downloading and converting the original models (Cerebras-GPT) (via) Georgi Gerganov added support for the Apache 2 licensed Cerebras-GPT language model to his ggml C++ inference library, as used by llama.cpp.
LLaMA voice chat, with Whisper and Siri TTS. llama.cpp author Georgi Gerganov has stitched together the LLaMA language model, the Whisper voice to text model (with his whisper.cpp library) and the macOS “say” command to create an entirely offline AI agent that he can talk to with his voice and that can speak replies straight back to him.
Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
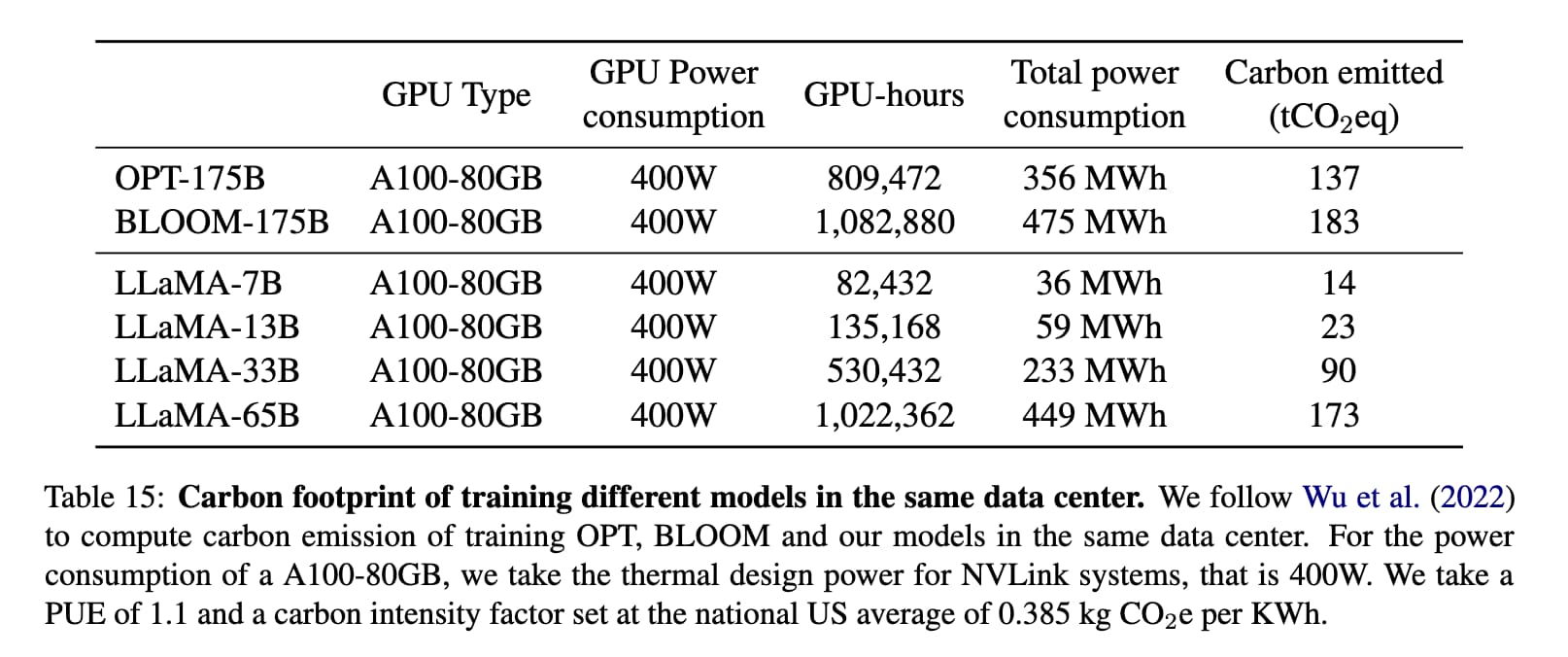
I think it’s now possible to train a large language model with similar functionality to GPT-3 for $85,000. And I think we might soon be able to run the resulting model entirely in the browser, and give it capabilities that leapfrog it ahead of ChatGPT.
[... 1,751 words]bloomz.cpp (via) Nouamane Tazi Adapted the llama.cpp project to run against the BLOOM family of language models, which were released in July 2022 and trained in France on 45 natural languages and 12 programming languages using the Jean Zay Public Supercomputer, provided by the French government and powered using mostly nuclear energy.
It’s under the RAIL license which allows (limited) commercial use, unlike LLaMA.
Nouamane reports getting 16 tokens/second from BLOOMZ-7B1 running on an M1 Pro laptop.
Stanford Alpaca, and the acceleration of on-device large language model development
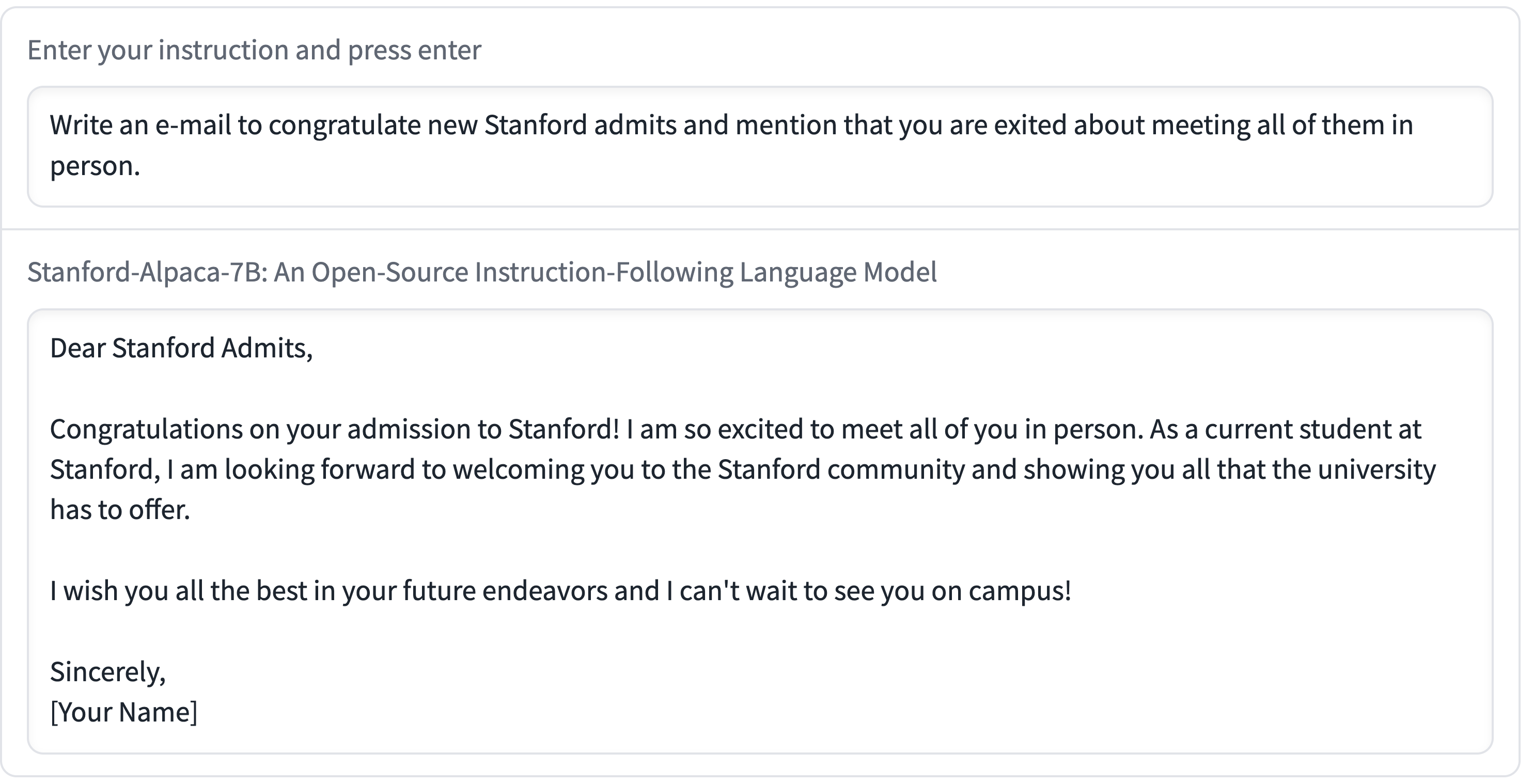
On Saturday 11th March I wrote about how Large language models are having their Stable Diffusion moment. Today is Monday. Let’s look at what’s happened in the past three days.
[... 2,055 words]Large language models are having their Stable Diffusion moment
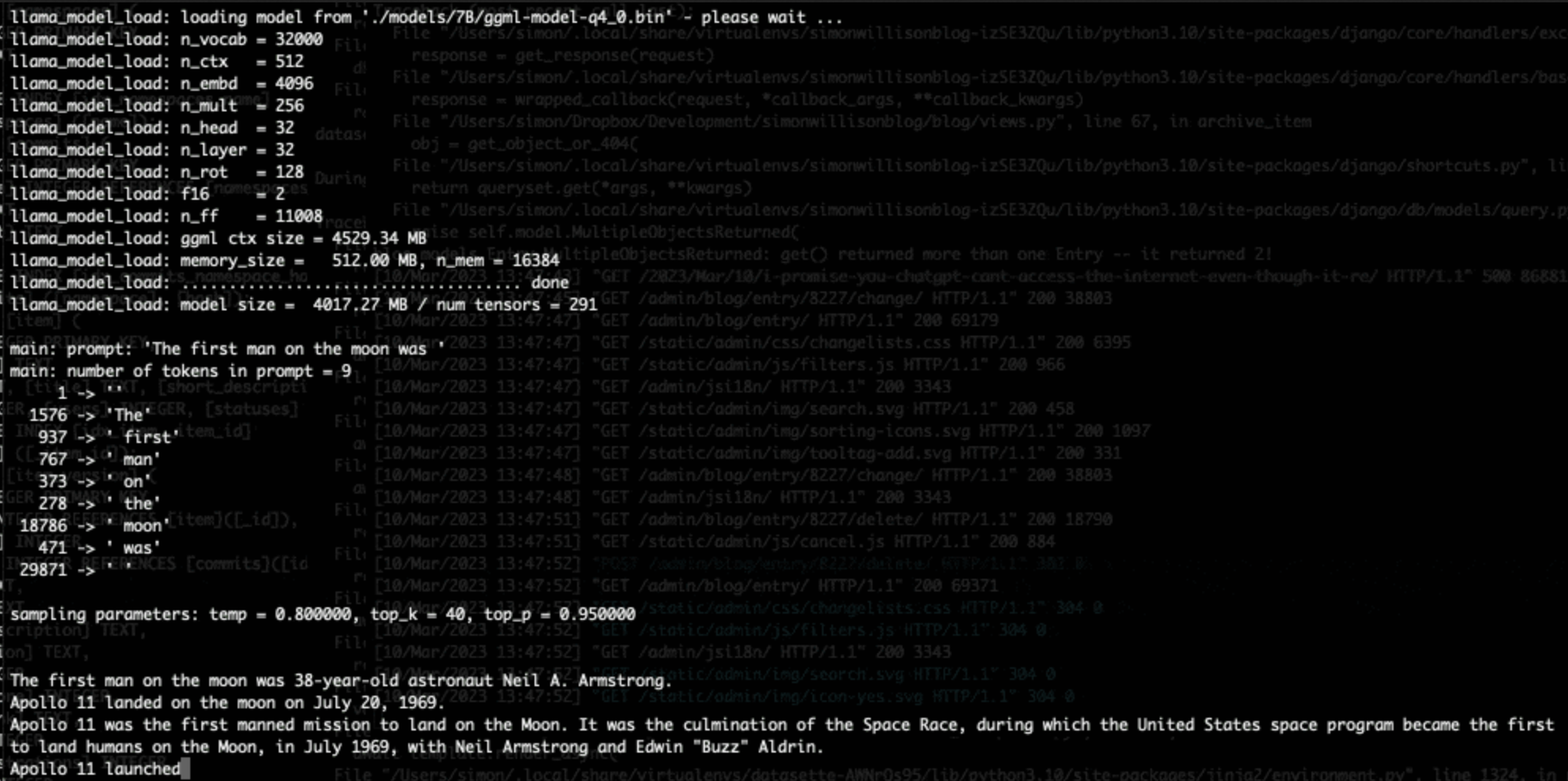
The open release of the Stable Diffusion image generation model back in August 2022 was a key moment. I wrote how Stable Diffusion is a really big deal at the time.
[... 1,815 words]Running LLaMA 7B on a 64GB M2 MacBook Pro with llama.cpp. I got Facebook’s LLaMA 7B to run on my MacBook Pro using llama.cpp (a “port of Facebook’s LLaMA model in C/C++”) by Georgi Gerganov. It works! I’ve been hoping to run a GPT-3 class language model on my own hardware for ages, and now it’s possible to do exactly that. The model itself ends up being just 4GB after applying Georgi’s script to “quantize the model to 4-bits”.