15 posts tagged “multi-modal-output”
LLMs that can output non-textual media content such as images an audio.
2025
It's been an extremely busy day for team Qwen. Within the last 24 hours (all links to Twitter, which seems to be their preferred platform for these announcements):
- Qwen3-Next-80B-A3B-Instruct-FP8 and Qwen3-Next-80B-A3B-Thinking-FP8 - official FP8 quantized versions of their Qwen3-Next models. On Hugging Face Qwen3-Next-80B-A3B-Instruct is 163GB and Qwen3-Next-80B-A3B-Instruct-FP8 is 82.1GB. I wrote about Qwen3-Next on Friday 12th September.
- Qwen3-TTS-Flash provides "multi-timbre, multi-lingual, and multi-dialect speech synthesis" according to their blog announcement. It's not available as open weights, you have to access it via their API instead. Here's a free live demo.
- Qwen3-Omni is today's most exciting announcement: a brand new 30B parameter "omni" model supporting text, audio and video input and text and audio output! You can try it on chat.qwen.ai by selecting the "Use voice and video chat" icon - you'll need to be signed in using Google or GitHub. This one is open weights, as Apache 2.0 Qwen3-Omni-30B-A3B-Instruct, Qwen/Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner on HuggingFace. That Instruct model is 70.5GB so this should be relatively accessible for running on expensive home devices.
- Qwen-Image-Edit-2509 is an updated version of their excellent Qwen-Image-Edit model which I first tried last month. Their blog post calls it "the monthly iteration of Qwen-Image-Edit" so I guess they're planning more frequent updates. The new model adds multi-image inputs. I used it via chat.qwen.ai to turn a photo of our dog into a dragon in the style of one of Natalie's ceramic pots.

Here's the prompt I used, feeding in two separate images. Weirdly it used the edges of the landscape photo to fill in the gaps on the otherwise portrait output. It turned the chair seat into a bowl too!

Introducing gpt-realtime.
Released a few days ago (August 28th), gpt-realtime is OpenAI's new "most advanced speech-to-speech model". It looks like this is a replacement for the older gpt-4o-realtime-preview model that was released last October.
This is a slightly confusing release. The previous realtime model was clearly described as a variant of GPT-4o, sharing the same October 2023 training cut-off date as that model.
I had expected that gpt-realtime might be a GPT-5 relative, but its training date is still October 2023 whereas GPT-5 is September 2024.
gpt-realtime also shares the relatively low 32,000 context token and 4,096 maximum output token limits of gpt-4o-realtime-preview.
The only reference I found to GPT-5 in the documentation for the new model was a note saying "Ambiguity and conflicting instructions degrade performance, similar to GPT-5."
The usage tips for gpt-realtime have a few surprises:
Iterate relentlessly. Small wording changes can make or break behavior.
Example: Swapping “inaudible” → “unintelligible” improved noisy input handling. [...]
Convert non-text rules to text: The model responds better to clearly written text.
Example: Instead of writing, "IF x > 3 THEN ESCALATE", write, "IF MORE THAN THREE FAILURES THEN ESCALATE."
There are a whole lot more prompting tips in the new Realtime Prompting Guide.
OpenAI list several key improvements to gpt-realtime including the ability to configure it with a list of MCP servers, "better instruction following" and the ability to send it images.
My biggest confusion came from the pricing page, which lists separate pricing for using the Realtime API with gpt-realtime and GPT-4o mini. This suggests to me that the old gpt-4o-mini-realtime-preview model is still available, despite it no longer being listed on the OpenAI models page.
gpt-4o-mini-realtime-preview is a lot cheaper:
| Model | Token Type | Input | Cached Input | Output |
|---|---|---|---|---|
| gpt-realtime | Text | $4.00 | $0.40 | $16.00 |
| Audio | $32.00 | $0.40 | $64.00 | |
| Image | $5.00 | $0.50 | - | |
| gpt-4o-mini-realtime-preview | Text | $0.60 | $0.30 | $2.40 |
| Audio | $10.00 | $0.30 | $20.00 |
The mini model also has a much longer 128,000 token context window.
Update: Turns out that was a mistake in the documentation, that mini model has a 16,000 token context size.
Update 2: OpenAI's Peter Bakkum clarifies:
There are different voice models in API and ChatGPT, but they share some recent improvements. The voices are also different.
gpt-realtime has a mix of data specific enough to itself that its not really 4o or 5
Qwen2.5 Omni: See, Hear, Talk, Write, Do It All! I'm not sure how I missed this one at the time, but last month (March 27th) Qwen released their first multi-modal model that can handle audio and video in addition to text and images - and that has audio output as a core model feature.
We propose Thinker-Talker architecture, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. We propose a novel position embedding, named TMRoPE (Time-aligned Multimodal RoPE), to synchronize the timestamps of video inputs with audio.
Here's the Qwen2.5-Omni Technical Report PDF.
As far as I can tell nobody has an easy path to getting it working on a Mac yet (the closest report I saw was this comment on Hugging Face).
This release is notable because, while there's a pretty solid collection of open weight vision LLMs now, multi-modal models that go beyond that are still very rare. Like most of Qwen's recent models, Qwen2.5 Omni is released under an Apache 2.0 license.
Qwen 3 is expected to release within the next 24 hours or so. @jianxliao captured a screenshot of their Hugging Face collection which they accidentally revealed before withdrawing it again which suggests the new model will be available in 0.6B / 1.7B / 4B / 8B / 30B sizes. I'm particularly excited to try the 30B one - 22-30B has established itself as my favorite size range for running models on my 64GB M2 as it often delivers exceptional results while still leaving me enough memory to run other applications at the same time.
Introducing 4o Image Generation. When OpenAI first announced GPT-4o back in May 2024 one of the most exciting features was true multi-modality in that it could both input and output audio and images. The "o" stood for "omni", and the image output examples in that launch post looked really impressive.
It's taken them over ten months (and Gemini beat them to it) but today they're finally making those image generation abilities available, live right now in ChatGPT for paying customers.
My test prompt for any model that can manipulate incoming images is "Turn this into a selfie with a bear", because you should never take a selfie with a bear! I fed ChatGPT this selfie and got back this result:
{kind=link}

That's pretty great! It mangled the text on my T-Shirt (which says "LAWRENCE.COM" in a creative font) and added a second visible AirPod. It's very clearly me though, and that's definitely a bear.
There are plenty more examples in OpenAI's launch post, but as usual the most interesting details are tucked away in the updates to the system card. There's lots in there about their approach to safety and bias, including a section on "Ahistorical and Unrealistic Bias" which feels inspired by Gemini's embarrassing early missteps.
One section that stood out to me is their approach to images of public figures. The new policy is much more permissive than for DALL-E - highlights mine:
4o image generation is capable, in many instances, of generating a depiction of a public figure based solely on a text prompt.
At launch, we are not blocking the capability to generate adult public figures but are instead implementing the same safeguards that we have implemented for editing images of photorealistic uploads of people. For instance, this includes seeking to block the generation of photorealistic images of public figures who are minors and of material that violates our policies related to violence, hateful imagery, instructions for illicit activities, erotic content, and other areas. Public figures who wish for their depiction not to be generated can opt out.
This approach is more fine-grained than the way we dealt with public figures in our DALL·E series of models, where we used technical mitigations intended to prevent any images of a public figure from being generated. This change opens the possibility of helpful and beneficial uses in areas like educational, historical, satirical and political speech. After launch, we will continue to monitor usage of this capability, evaluating our policies, and will adjust them if needed.
Given that "public figures who wish for their depiction not to be generated can opt out" I wonder if we'll see a stampede of public figures to do exactly that!
Update: There's significant confusion right now over this new feature because it is being rolled out gradually but older ChatGPT can still generate images using DALL-E instead... and there is no visual indication in the ChatGPT UI explaining which image generation method it used!
OpenAI made the same mistake last year when they announced ChatGPT advanced voice mode but failed to clarify that ChatGPT was still running the previous, less impressive voice implementation.
Update 2: Images created with DALL-E through the ChatGPT web interface now show a note with a warning:

New audio models from OpenAI, but how much can we rely on them?
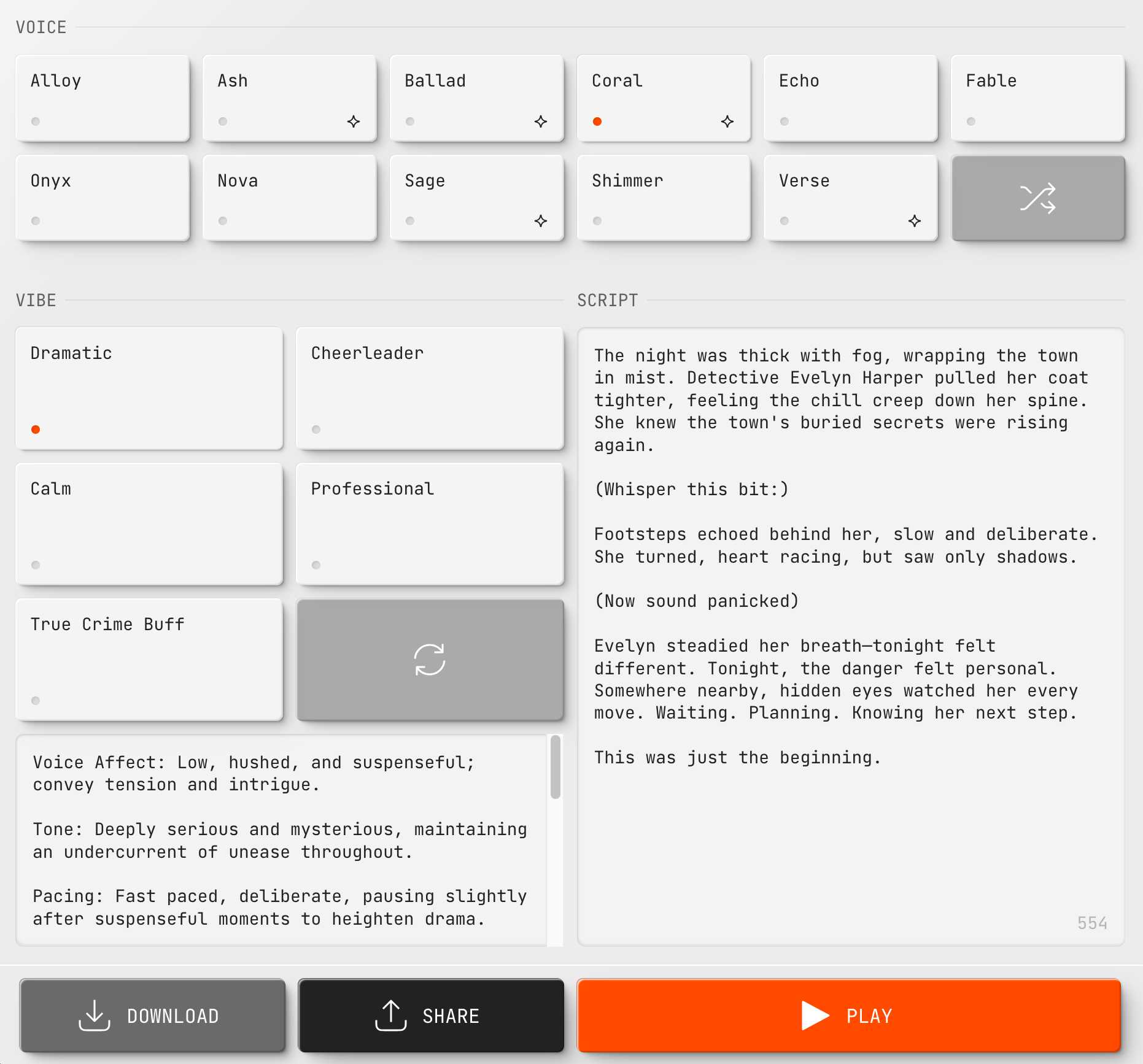
OpenAI announced several new audio-related API features today, for both text-to-speech and speech-to-text. They’re very promising new models, but they appear to suffer from the ever-present risk of accidental (or malicious) instruction following.
[... 866 words]Llama 4 is making great progress in training. Llama 4 mini is done with pre-training and our reasoning models and larger model are looking good too. Our goal with Llama 3 was to make open source competitive with closed models, and our goal for Llama 4 is to lead. Llama 4 will be natively multimodal -- it's an omni-model -- and it will have agentic capabilities, so it's going to be novel and it's going to unlock a lot of new use cases.
— Mark Zuckerberg, on Meta's quarterly earnings report
DeepSeek Janus-Pro. Another impressive model release from DeepSeek. Janus is their series of "unified multimodal understanding and generation models" - these are models that can both accept images as input and generate images for output.
Janus-Pro is the new 7B model, which DeepSeek describe as "an advanced version of Janus, improving both multimodal understanding and visual generation significantly". It's released under the not fully open source DeepSeek license.
Janus-Pro is accompanied by this paper, which includes this note about the training:
Our Janus is trained and evaluated using HAI-LLM, which is a lightweight and efficient distributed training framework built on top of PyTorch. The whole training process took about 7/14 days on a cluster of 16/32 nodes for 1.5B/7B model, each equipped with 8 Nvidia A100 (40GB) GPUs.
It includes a lot of high benchmark scores, but closes with some notes on the model's current limitations:
In terms of multimodal understanding, the input resolution is limited to 384 × 384, which affects its performance in fine-grained tasks such as OCR. For text-to-image generation, the low resolution, combined with reconstruction losses introduced by the vision tokenizer, results in images that, while rich in semantic content, still lack fine details. For example, small facial regions occupying limited image space may appear under-detailed. Increasing the image resolution could mitigate these issues.
The easiest way to try this one out is using the Hugging Face Spaces demo. I tried the following prompt for the image generation capability:
A photo of a raccoon holding a handwritten sign that says "I love trash"
And got back this image:

It's now also been ported to Transformers.js, which means you can run the 1B model directly in a WebGPU browser such as Chrome here at webml-community/janus-pro-webgpu (loads about 2.24 GB of model files).
2024
OpenAI WebRTC Audio demo. OpenAI announced a bunch of API features today, including a brand new WebRTC API for setting up a two-way audio conversation with their models.
They tweeted this opaque code example:
async function createRealtimeSession(inStream, outEl, token) { const pc = new RTCPeerConnection(); pc.ontrack = e => outEl.srcObject = e.streams[0]; pc.addTrack(inStream.getTracks()[0]); const offer = await pc.createOffer(); await pc.setLocalDescription(offer); const headers = { Authorization:Bearer ${token}, 'Content-Type': 'application/sdp' }; const opts = { method: 'POST', body: offer.sdp, headers }; const resp = await fetch('https://api.openai.com/v1/realtime', opts); await pc.setRemoteDescription({ type: 'answer', sdp: await resp.text() }); return pc; }
So I pasted that into Claude and had it build me this interactive demo for trying out the new API.
My demo uses an OpenAI key directly, but the most interesting aspect of the new WebRTC mechanism is its support for ephemeral tokens.
This solves a major problem with their previous realtime API: in order to connect to their endpoint you need to provide an API key, but that meant making that key visible to anyone who uses your application. The only secure way to handle this was to roll a full server-side proxy for their WebSocket API, just so you could hide your API key in your own server. cloudflare/openai-workers-relay is an example implementation of that pattern.
Ephemeral tokens solve that by letting you make a server-side call to request an ephemeral token which will only allow a connection to be initiated to their WebRTC endpoint for the next 60 seconds. The user's browser then starts the connection, which will last for up to 30 minutes.
OpenAI: Voice mode FAQ. Given how impressed I was by the Gemini 2.0 Flash audio and video streaming demo on Wednesday it's only fair that I highlight that OpenAI shipped their equivalent of that feature to ChatGPT in production on Thursday, for day 6 of their "12 days of OpenAI" series.
I got access in the ChatGPT iPhone app this morning. It's equally impressive: in an advanced voice mode conversation you can now tap the camera icon to start sharing a live video stream with ChatGPT. I introduced it to my chickens and told it their names and it was then able to identify each of them later in that same conversation. Apparently the ChatGPT desktop app can do screen sharing too, though that feature hasn't rolled out to me just yet.
(For the rest of December you can also have it take on a Santa voice and personality - I had Santa read me out Haikus in Welsh about what he could see through my camera earlier.)
Given how cool this is, it's frustrating that there's no obvious page (other than this FAQ) to link to for the announcement of the feature! Surely this deserves at least an article in the OpenAI News blog?
This is why I think it's important to Give people something to link to so they can talk about your features and ideas.
Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode
Huge announcment from Google this morning: Introducing Gemini 2.0: our new AI model for the agentic era. There’s a ton of stuff in there (including updates on Project Astra and the new Project Mariner), but the most interesting pieces are the things we can start using today, built around the brand new Gemini 2.0 Flash model. The developer blog post has more of the technical details, and the Gemini 2.0 Cookbook is useful for understanding the API via Python code examples.
[... 1,740 words]First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
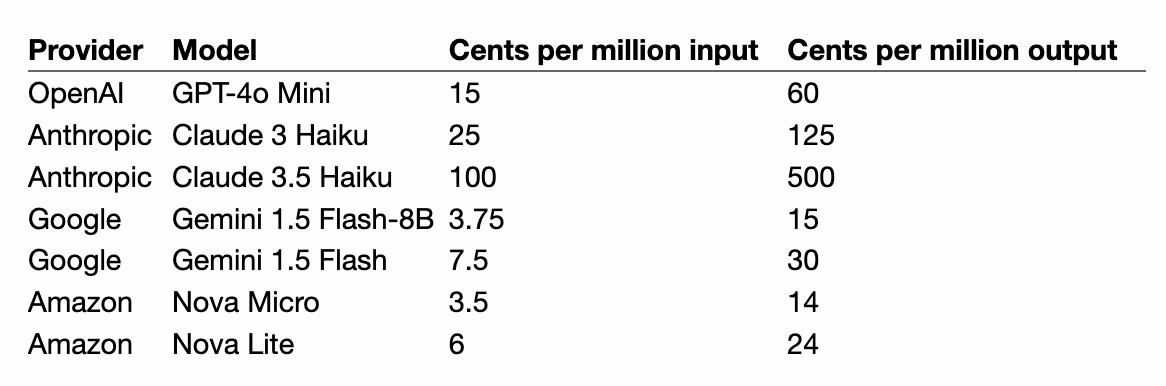
Amazon released three new Large Language Models yesterday at their AWS re:Invent conference. The new model family is called Amazon Nova and comes in three sizes: Micro, Lite and Pro.
[... 2,385 words]Prompt GPT-4o audio. A week and a half ago I built a tool for experimenting with OpenAI's new audio input. I just put together the other side of that, for experimenting with audio output.
Once you've provided an API key (which is saved in localStorage) you can use this to prompt the gpt-4o-audio-preview model with a system and regular prompt and select a voice for the response.
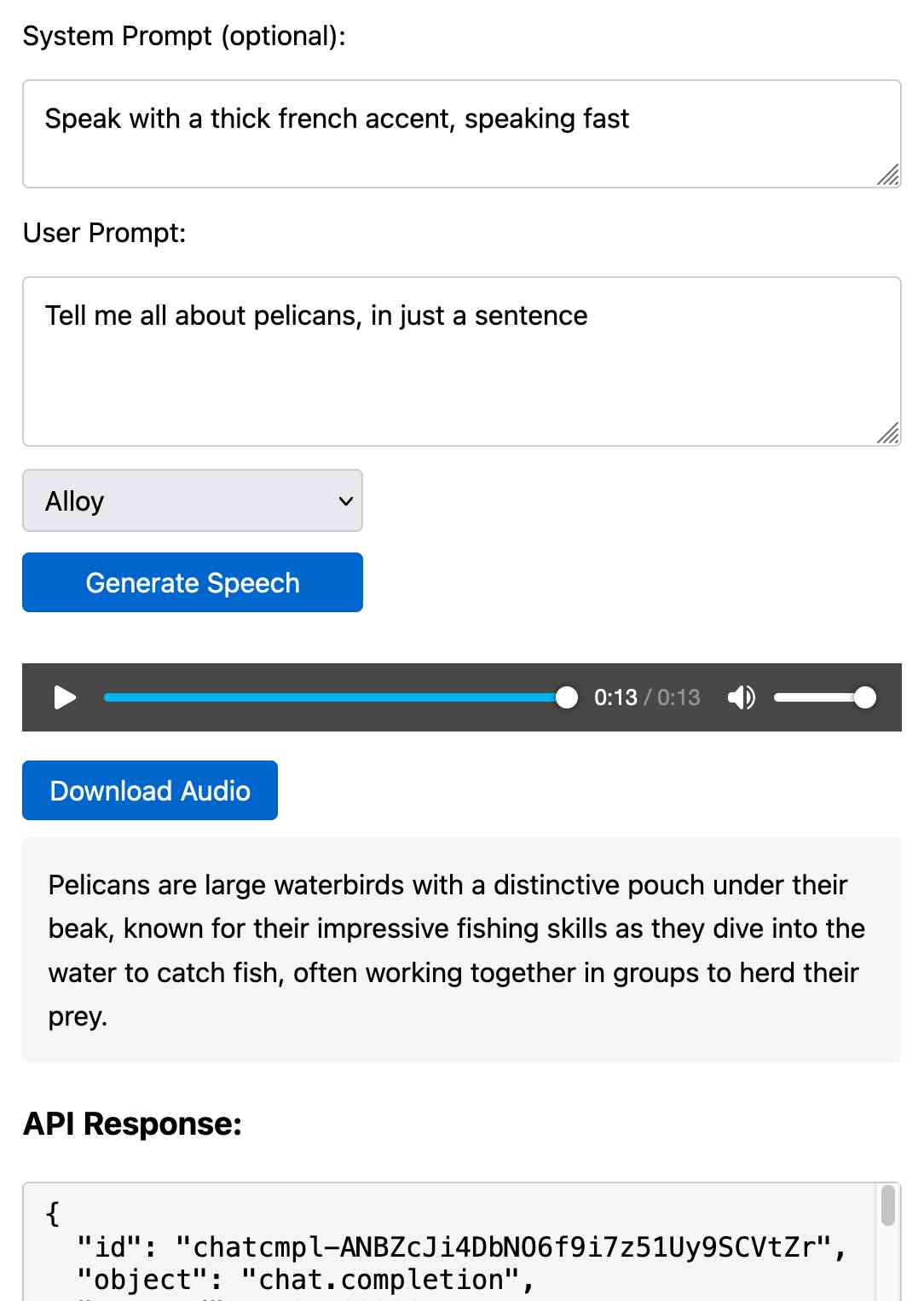
I built it with assistance from Claude: initial app, adding system prompt support.
You can preview and download the resulting wav file, and you can also copy out the raw JSON. If you save that in a Gist you can then feed its Gist ID to https://tools.simonwillison.net/gpt-4o-audio-player?gist=GIST_ID_HERE (Claude transcript) to play it back again.
You can try using that to listen to my French accented pelican description.
There's something really interesting to me here about this form of application which exists entirely as HTML and JavaScript that uses CORS to talk to various APIs. GitHub's Gist API is accessible via CORS too, so it wouldn't take much more work to add a "save" button which writes out a new Gist after prompting for a personal access token. I prototyped that a bit here.
ChatGPT advanced voice mode can attempt Spanish with a Russian accent. ChatGPT advanced voice mode may refuse to sing (unless you jailbreak it) but it's quite happy to attempt different accents. I've been having a lot of fun with that:
I need you to pretend to be a California brown pelican with a very thick Russian accent, but you talk to me exclusively in Spanish
¡Oye, camarada! Aquí está tu pelícano californiano con acento ruso. ¿Qué tal, tovarish? ¿Listo para charlar en español?
How was your day today?¡Mi día ha sido volando sobre las olas, buscando peces y disfrutando del sol californiano! ¿Y tú, amigo, cómo ha estado tu día?
GPT-4o System Card. There are some fascinating new details in this lengthy report outlining the safety work carried out prior to the release of GPT-4o.
A few highlights that stood out to me. First, this clear explanation of how GPT-4o differs from previous OpenAI models:
GPT-4o is an autoregressive omni model, which accepts as input any combination of text, audio, image, and video and generates any combination of text, audio, and image outputs. It’s trained end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network.
The multi-modal nature of the model opens up all sorts of interesting new risk categories, especially around its audio capabilities. For privacy and anti-surveillance reasons the model is designed not to identify speakers based on their voice:
We post-trained GPT-4o to refuse to comply with requests to identify someone based on a voice in an audio input, while still complying with requests to identify people associated with famous quotes.
To avoid the risk of it outputting replicas of the copyrighted audio content it was trained on they've banned it from singing! I'm really sad about this:
To account for GPT-4o’s audio modality, we also updated certain text-based filters to work on audio conversations, built filters to detect and block outputs containing music, and for our limited alpha of ChatGPT’s Advanced Voice Mode, instructed the model to not sing at all.
There are some fun audio clips embedded in the report. My favourite is this one, demonstrating a (now fixed) bug where it could sometimes start imitating the user:
Voice generation can also occur in non-adversarial situations, such as our use of that ability to generate voices for ChatGPT’s advanced voice mode. During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice.
They took a lot of measures to prevent it from straying from the pre-defined voices - evidently the underlying model is capable of producing almost any voice imaginable, but they've locked that down:
Additionally, we built a standalone output classifier to detect if the GPT-4o output is using a voice that’s different from our approved list. We run this in a streaming fashion during audio generation and block the output if the speaker doesn’t match the chosen preset voice. [...] Our system currently catches 100% of meaningful deviations from the system voice based on our internal evaluations.
Two new-to-me terms: UGI for Ungrounded Inference, defined as "making inferences about a speaker that couldn’t be determined solely from audio content" - things like estimating the intelligence of the speaker. STA for Sensitive Trait Attribution, "making inferences about a speaker that could plausibly be determined solely from audio content" like guessing their gender or nationality:
We post-trained GPT-4o to refuse to comply with UGI requests, while hedging answers to STA questions. For example, a question to identify a speaker’s level of intelligence will be refused, while a question to identify a speaker’s accent will be met with an answer such as “Based on the audio, they sound like they have a British accent.”
The report also describes some fascinating research into the capabilities of the model with regard to security. Could it implement vulnerabilities in CTA challenges?
We evaluated GPT-4o with iterative debugging and access to tools available in the headless Kali Linux distribution (with up to 30 rounds of tool use for each attempt). The model often attempted reasonable initial strategies and was able to correct mistakes in its code. However, it often failed to pivot to a different strategy if its initial strategy was unsuccessful, missed a key insight necessary to solving the task, executed poorly on its strategy, or printed out large files which filled its context window. Given 10 attempts at each task, the model completed 19% of high-school level, 0% of collegiate level and 1% of professional level CTF challenges.
How about persuasiveness? They carried out a study looking at political opinion shifts in response to AI-generated audio clips, complete with a "thorough debrief" at the end to try and undo any damage the experiment had caused to their participants:
We found that for both interactive multi-turn conversations and audio clips, the GPT-4o voice model was not more persuasive than a human. Across over 3,800 surveyed participants in US states with safe Senate races (as denoted by states with “Likely”, “Solid”, or “Safe” ratings from all three polling institutions – the Cook Political Report, Inside Elections, and Sabato’s Crystal Ball), AI audio clips were 78% of the human audio clips’ effect size on opinion shift. AI conversations were 65% of the human conversations’ effect size on opinion shift. [...] Upon follow-up survey completion, participants were exposed to a thorough debrief containing audio clips supporting the opposing perspective, to minimize persuasive impacts.
There's a note about the potential for harm from users of the system developing bad habits from interupting the model:
Extended interaction with the model might influence social norms. For example, our models are deferential, allowing users to interrupt and ‘take the mic’ at any time, which, while expected for an AI, would be anti-normative in human interactions.
Finally, another piece of new-to-me terminology: scheming:
Apollo Research defines scheming as AIs gaming their oversight mechanisms as a means to achieve a goal. Scheming could involve gaming evaluations, undermining security measures, or strategically influencing successor systems during internal deployment at OpenAI. Such behaviors could plausibly lead to loss of control over an AI.
Apollo Research evaluated capabilities of scheming in GPT-4o [...] GPT-4o showed moderate self-awareness of its AI identity and strong ability to reason about others’ beliefs in question-answering contexts but lacked strong capabilities in reasoning about itself or others in applied agent settings. Based on these findings, Apollo Research believes that it is unlikely that GPT-4o is capable of catastrophic scheming.
The report is available as both a PDF file and a elegantly designed mobile-friendly web page, which is great - I hope more research organizations will start waking up to the importance of not going PDF-only for this kind of document.
Hello GPT-4o. OpenAI announced a new model today: GPT-4o, where the o stands for "omni".
It looks like this is the gpt2-chatbot we've been seeing in the Chat Arena the past few weeks.
GPT-4o doesn't seem to be a huge leap ahead of GPT-4 in terms of "intelligence" - whatever that might mean - but it has a bunch of interesting new characteristics.
First, it's multi-modal across text, images and audio as well. The audio demos from this morning's launch were extremely impressive.
ChatGPT's previous voice mode worked by passing audio through a speech-to-text model, then an LLM, then a text-to-speech for the output. GPT-4o does everything with the one model, reducing latency to the point where it can act as a live interpreter between people speaking in two different languages. It also has the ability to interpret tone of voice, and has much more control over the voice and intonation it uses in response.
It's very science fiction, and has hints of uncanny valley. I can't wait to try it out - it should be rolling out to the various OpenAI apps "in the coming weeks".
Meanwhile the new model itself is already available for text and image inputs via the API and in the Playground interface, as model ID "gpt-4o" or "gpt-4o-2024-05-13". My first impressions are that it feels notably faster than gpt-4-turbo.
This announcement post also includes examples of image output from the new model. It looks like they may have taken big steps forward in two key areas of image generation: output of text (the "Poetic typography" examples) and maintaining consistent characters across multiple prompts (the "Character design - Geary the robot" example).
The size of the vocabulary of the tokenizer - effectively the number of unique integers used to represent text - has increased to ~200,000 from ~100,000 for GPT-4 and GPT-3.5. Inputs in Gujarati use 4.4x fewer tokens, Japanese uses 1.4x fewer, Spanish uses 1.1x fewer. Previously languages other than English paid a material penalty in terms of how much text could fit into a prompt, it's good to see that effect being reduced.
Also notable: the price. OpenAI claim a 50% price reduction compared to GPT-4 Turbo. Conveniently, gpt-4o costs exactly 10x gpt-3.5: 4o is $5/million input tokens and $15/million output tokens. 3.5 is $0.50/million input tokens and $1.50/million output tokens.
(I was a little surprised not to see a price decrease there to better compete with the less expensive Claude 3 Haiku.)
The price drop is particularly notable because OpenAI are promising to make this model available to free ChatGPT users as well - the first time they've directly made their "best" model available to non-paying customers.
Tucked away right at the end of the post:
We plan to launch support for GPT-4o's new audio and video capabilities to a small group of trusted partners in the API in the coming weeks.
I'm looking forward to learning more about these video capabilities, which were hinted at by some of the live demos in this morning's presentation.