522 posts tagged “projects”
Posts about projects I have worked on.
2026
Writing about Agentic Engineering Patterns

I’ve started a new project to collect and document Agentic Engineering Patterns—coding practices and patterns to help get the best results out of this new era of coding agent development we find ourselves entering.
[... 554 words]Rodney v0.4.0. My Rodney CLI tool for browser automation attracted quite the flurry of PRs since I announced it last week. Here are the release notes for the just-released v0.4.0:
- Errors now use exit code 2, which means exit code 1 is just for for check failures. #15
- New
rodney assertcommand for running JavaScript tests, exit code 1 if they fail. #19- New directory-scoped sessions with
--local/--globalflags. #14- New
reload --hardandclear-cachecommands. #17- New
rodney start --showoption to make the browser window visible. Thanks, Antonio Cuni. #13- New
rodney connect PORTcommand to debug an already-running Chrome instance. Thanks, Peter Fraenkel. #12- New
RODNEY_HOMEenvironment variable to support custom state directories. Thanks, Senko Rašić. #11- New
--insecureflag to ignore certificate errors. Thanks, Jakub Zgoliński. #10- Windows support: avoid
Setsidon Windows via build-tag helpers. Thanks, adm1neca. #18- Tests now run on
windows-latestandmacos-latestin addition to Linux.
I've been using Showboat to create demos of new features - here those are for rodney assert, rodney reload --hard, rodney exit codes, and rodney start --local.
The rodney assert command is pretty neat: you can now Rodney to test a web app through multiple steps in a shell script that looks something like this (adapted from the README):
#!/bin/bash
set -euo pipefail
FAIL=0
check() {
if ! "$@"; then
echo "FAIL: $*"
FAIL=1
fi
}
rodney start
rodney open "https://example.com"
rodney waitstable
# Assert elements exist
check rodney exists "h1"
# Assert key elements are visible
check rodney visible "h1"
check rodney visible "#main-content"
# Assert JS expressions
check rodney assert 'document.title' 'Example Domain'
check rodney assert 'document.querySelectorAll("p").length' '2'
# Assert accessibility requirements
check rodney ax-find --role navigation
rodney stop
if [ "$FAIL" -ne 0 ]; then
echo "Some checks failed"
exit 1
fi
echo "All checks passed"Two new Showboat tools: Chartroom and datasette-showboat
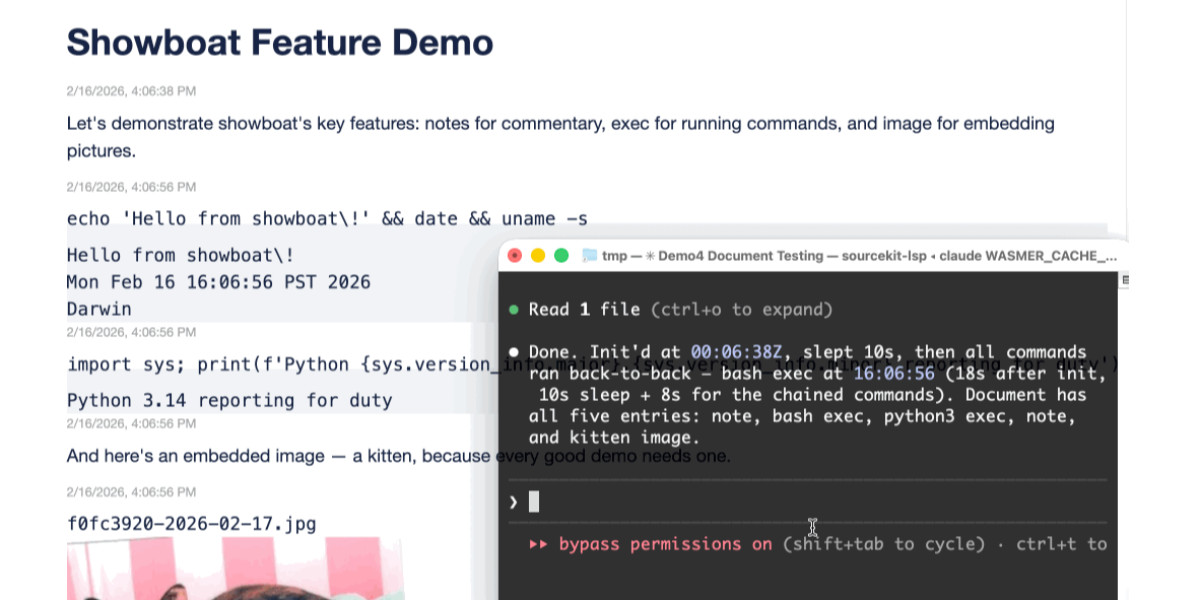
I introduced Showboat a week ago—my CLI tool that helps coding agents create Markdown documents that demonstrate the code that they have created. I’ve been finding new ways to use it on a daily basis, and I’ve just released two new tools to help get the best out of the Showboat pattern. Chartroom is a CLI charting tool that works well with Showboat, and datasette-showboat lets Showboat’s new remote publishing feature incrementally push documents to a Datasette instance.
[... 1,756 words]I'm a very heavy user of Claude Code on the web, Anthropic's excellent but poorly named cloud version of Claude Code where everything runs in a container environment managed by them, greatly reducing the risk of anything bad happening to a computer I care about.
I don't use the web interface at all (hence my dislike of the name) - I access it exclusively through their native iPhone and Mac desktop apps.
Something I particularly appreciate about the desktop app is that it lets you see images that Claude is "viewing" via its Read /path/to/image tool. Here's what that looks like:
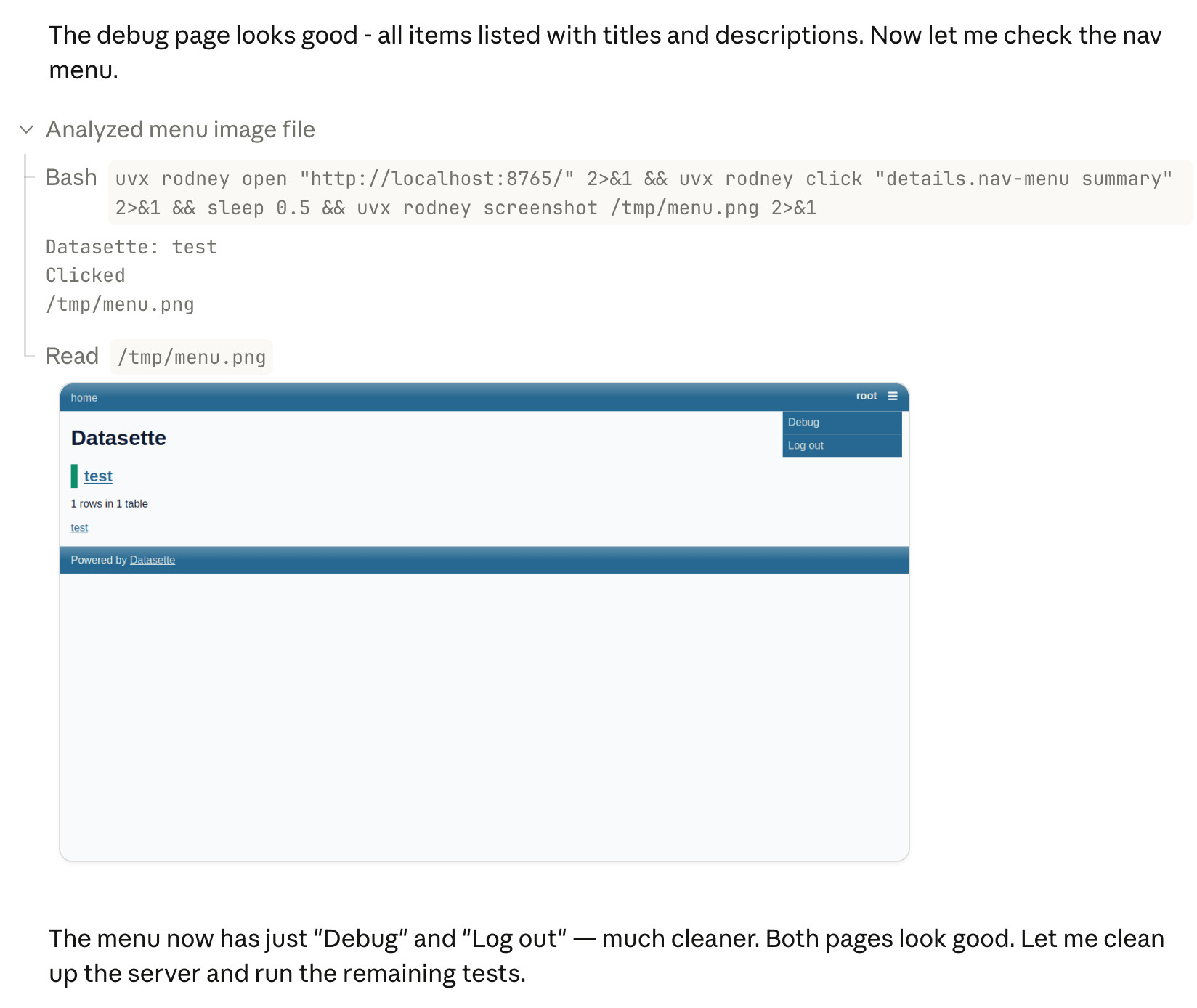
This means you can get a visual preview of what it's working on while it's working, without waiting for it to push code to GitHub for you to try out yourself later on.
The prompt I used to trigger the above screenshot was:
Run "uvx rodney --help" and then use Rodney to manually test the new pages and menu - look at screenshots from it and check you think they look OK
I designed Rodney to have --help output that provides everything a coding agent needs to know in order to use the tool.
The Claude iPhone app doesn't display opened images yet, so I requested it as a feature just now in a thread on Twitter.
Introducing Showboat and Rodney, so agents can demo what they’ve built
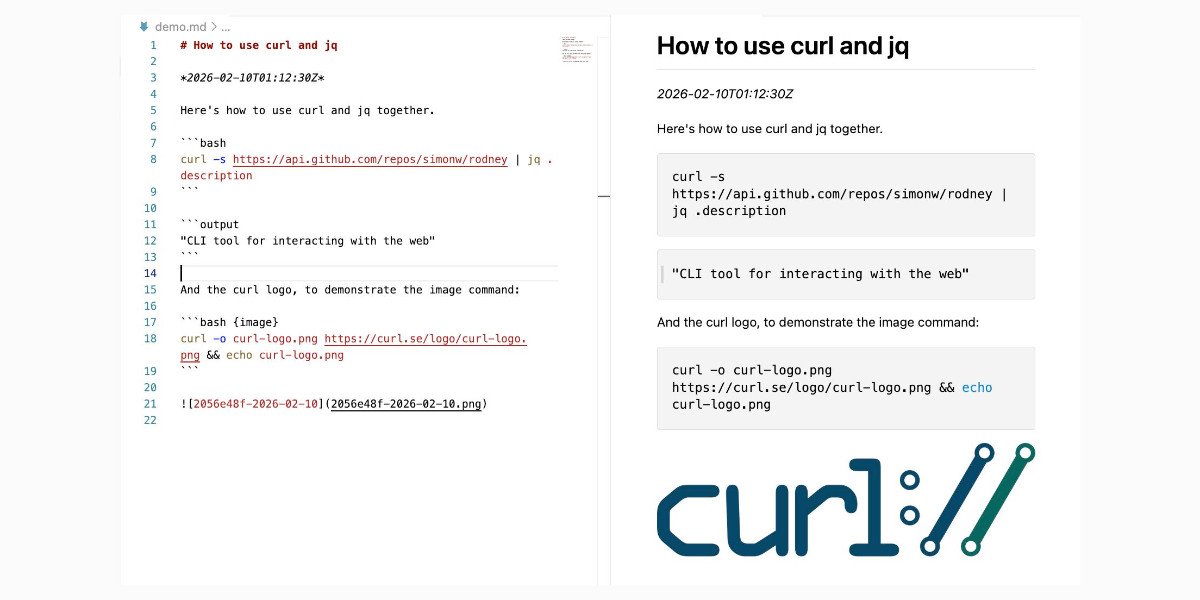
A key challenge working with coding agents is having them both test what they’ve built and demonstrate that software to you, their supervisor. This goes beyond automated tests—we need artifacts that show their progress and help us see exactly what the agent-produced software is able to do. I’ve just released two new tools aimed at this problem: Showboat and Rodney.
[... 2,023 words]Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel
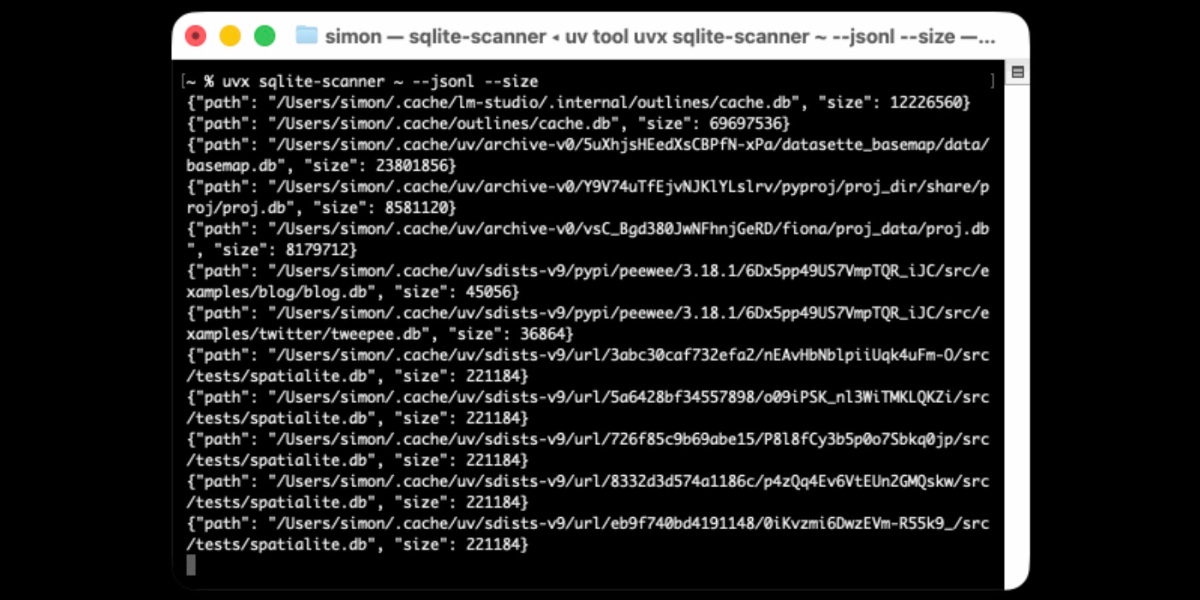
I’ve been exploring Go for building small, fast and self-contained binary applications recently. I’m enjoying how there’s generally one obvious way to do things and the resulting code is boring and readable—and something that LLMs are very competent at writing. The one catch is distribution, but it turns out publishing Go binaries to PyPI means any Go binary can be just a uvx package-name call away.
Datasette 1.0a24. New Datasette alpha this morning. Key new features:
- Datasette's
Requestobject can now handlemultipart/form-datafile uploads via the new await request.form(files=True) method. I plan to use this for adatasette-filesplugin to support attaching files to rows of data. - The recommended development environment for hacking on Datasette itself now uses uv. Crucially, you can clone Datasette and run
uv run pytestto run the tests without needing to manually create a virtual environment or install dependencies first, thanks to the dev dependency group pattern. - A new
?_extra=render_cellparameter for both table and row JSON pages to return the results of executing the render_cell() plugin hook. This should unlock new JavaScript UI features in the future.
More details in the release notes. I also invested a bunch of work in eliminating flaky tests that were intermittently failing in CI - I think those are all handled now.
Introducing gisthost.github.io
I am a huge fan of gistpreview.github.io, the site by Leon Huang that lets you append ?GIST_id to see a browser-rendered version of an HTML page that you have saved to a Gist. The last commit was ten years ago and I needed a couple of small changes so I’ve forked it and deployed an updated version at gisthost.github.io.
2025
shot-scraper 1.9. New release of my shot-scraper CLI tool for taking screenshots and scraping websites with JavaScript from the terminal.
The new shot-scraper har -x https://simonwillison.net/ command is really neat. The inspiration was the digital forensics expedition I went on to figure out why Rob Pike got spammed. You can now perform a version of that investigation like this:
cd /tmp
shot-scraper har --wait 10000 'https://theaidigest.org/village?day=265' -x
Then dig around in the resulting JSON files in the /tmp/theaidigest-org-village folder.
A new way to extract detailed transcripts from Claude Code
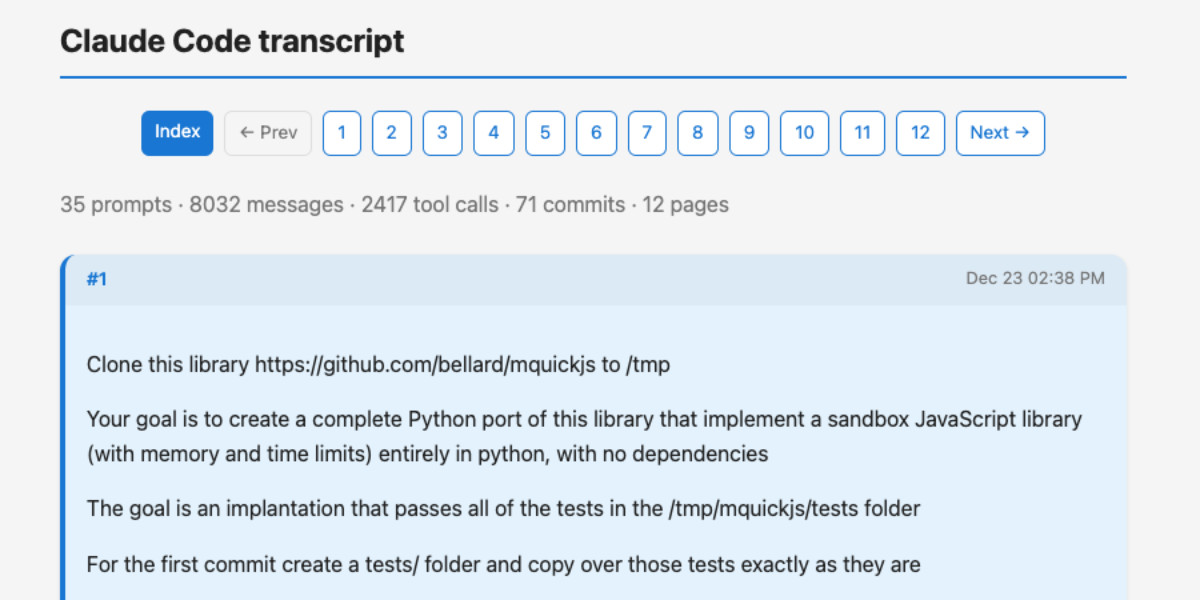
I’ve released claude-code-transcripts, a new Python CLI tool for converting Claude Code transcripts to detailed HTML pages that provide a better interface for understanding what Claude Code has done than even Claude Code itself. The resulting transcripts are also designed to be shared, using any static HTML hosting or even via GitHub Gists.
[... 1,082 words]uv-init-demos.
uv has a useful uv init command for setting up new Python projects, but it comes with a bunch of different options like --app and --package and --lib and I wasn't sure how they differed.
So I created this GitHub repository which demonstrates all of those options, generated using this update-projects.sh script (thanks, Claude) which will run on a schedule via GitHub Actions to capture any changes made by future releases of uv.
s3-credentials 0.17. New release of my s3-credentials CLI tool for managing credentials needed to access just one S3 bucket. Here are the release notes in full:
That s3-credentials localserver command (documented here) is a little obscure, but I found myself wanting something like that to help me test out a new feature I'm building to help create temporary Litestream credentials using Amazon STS.
Most of that new feature was built by Claude Code from the following starting prompt:
Add a feature s3-credentials localserver which starts a localhost weberver running (using the Python standard library stuff) on port 8094 by default but -p/--port can set a different port and otherwise takes an option that names a bucket and then takes the same options for read--write/read-only etc as other commands. It also takes a required --refresh-interval option which can be set as 5m or 10h or 30s. All this thing does is reply on / to a GET request with the IAM expiring credentials that allow access to that bucket with that policy for that specified amount of time. It caches internally the credentials it generates and will return the exact same data up until they expire (it also tracks expected expiry time) after which it will generate new credentials (avoiding dog pile effects if multiple requests ask at the same time) and return and cache those instead.
LLM 0.28. I released a new version of my LLM Python library and CLI tool for interacting with Large Language Models. Highlights from the release notes:
- New OpenAI models:
gpt-5.1,gpt-5.1-chat-latest,gpt-5.2andgpt-5.2-chat-latest. #1300, #1317- When fetching URLs as fragments using
llm -f URL, the request now includes a custom user-agent header:llm/VERSION (https://llm.datasette.io/). #1309- Fixed a bug where fragments were not correctly registered with their source when using
llm chat. Thanks, Giuseppe Rota. #1316- Fixed some file descriptor leak warnings. Thanks, Eric Bloch. #1313
- Type annotations for the OpenAI Chat, AsyncChat and Completion
execute()methods. Thanks, Arjan Mossel. #1315- The project now uses
uvand dependency groups for development. See the updated contributing documentation. #1318
That last bullet point about uv relates to the dependency groups pattern I wrote about in a recent TIL. I'm currently working through applying it to my other projects - the net result is that running the test suite is as simple as doing:
git clone https://github.com/simonw/llm
cd llm
uv run pytest
The new dev dependency group defined in pyproject.toml is automatically installed by uv run in a new virtual environment which means everything needed to run pytest is available without needing to add any extra commands.
Useful patterns for building HTML tools
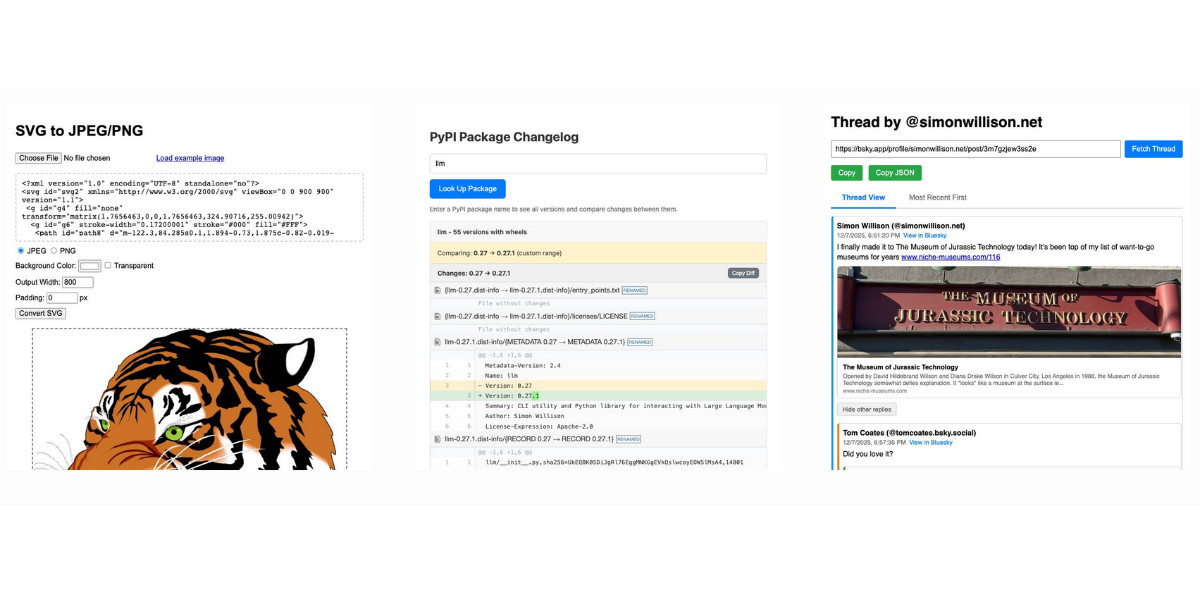
I’ve started using the term HTML tools to refer to HTML applications that I’ve been building which combine HTML, JavaScript, and CSS in a single file and use them to provide useful functionality. I have built over 150 of these in the past two years, almost all of them written by LLMs. This article presents a collection of useful patterns I’ve discovered along the way.
[... 4,231 words]Bluesky Thread Viewer thread by @simonwillison.net. I've been having a lot of fun hacking on my Bluesky Thread Viewer JavaScript tool with Claude Code recently. Here it renders a thread (complete with demo video) talking about the latest improvements to the tool itself.
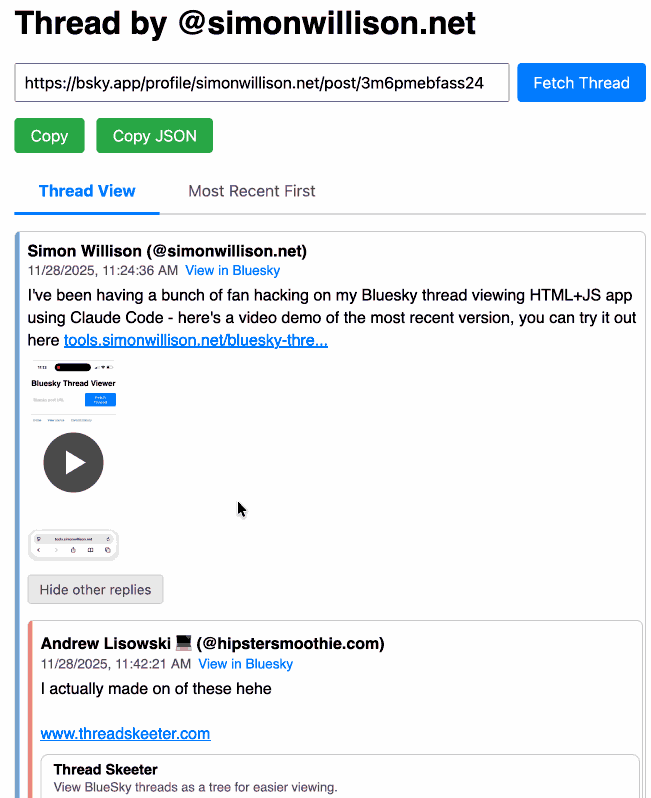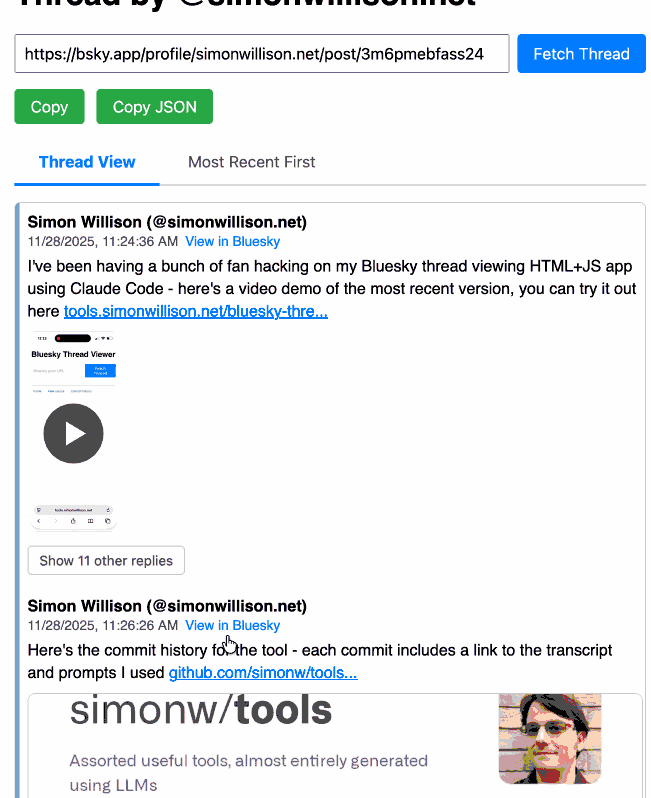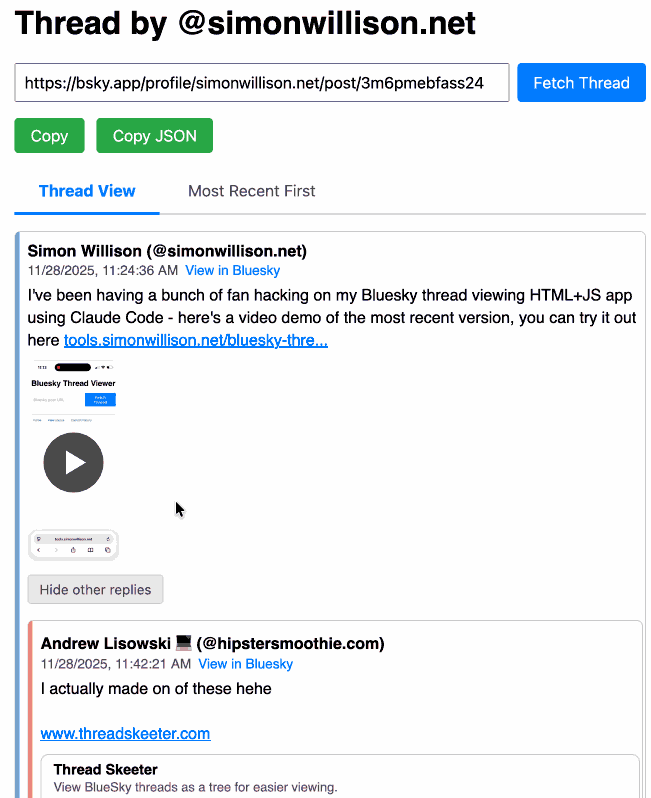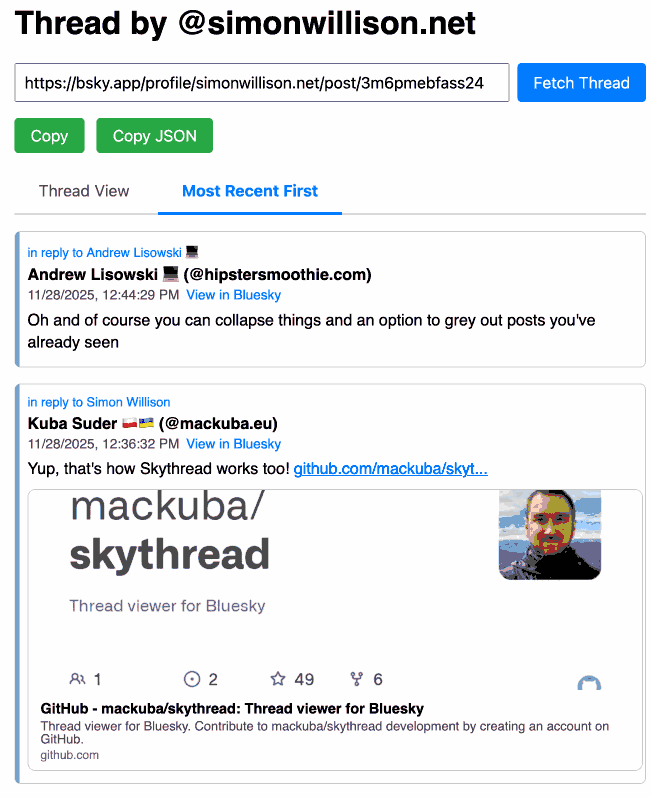
I've been mostly vibe-coding this thing since April, now spanning 15 commits with contributions from ChatGPT, Claude, Claude Code for Web and Claude Code on my laptop. Each of those commits links to the transcript that created the changes in the commit.
Bluesky is a lot of fun to build tools like this against because the API supports CORS (so you can talk to it from an HTML+JavaScript page hosted anywhere) and doesn't require authentication.
llm-anthropic 0.23.
New plugin release adding support for Claude Opus 4.5, including the new thinking_effort option:
llm install -U llm-anthropic
llm -m claude-opus-4.5 -o thinking_effort low 'muse on pelicans'
This took longer to release than I had hoped because it was blocked on Anthropic shipping 0.75.0 of their Python library with support for thinking effort.
sqlite-utils 3.39.
I got a report of a bug in sqlite-utils concerning plugin installation - if you installed the package using uv tool install further attempts to install plugins with sqlite-utils install X would fail, because uv doesn't bundle pip by default. I had the same bug with Datasette a while ago, turns out I forgot to apply the fix to sqlite-utils.
Since I was pushing a new dot-release I decided to integrate some of the non-breaking changes from the 4.0 alpha I released last night.
I tried to have Claude Code do the backporting for me:
create a new branch called 3.x starting with the 3.38 tag, then consult https://github.com/simonw/sqlite-utils/issues/688 and cherry-pick the commits it lists in the second comment, then review each of the links in the first comment and cherry-pick those as well. After each cherry-pick run the command "just test" to confirm the tests pass and fix them if they don't. Look through the commit history on main since the 3.38 tag to help you with this task.
This worked reasonably well - here's the terminal transcript. It successfully argued me out of two of the larger changes which would have added more complexity than I want in a small dot-release like this.
I still had to do a bunch of manual work to get everything up to scratch, which I carried out in this PR - including adding comments there and then telling Claude Code:
Apply changes from the review on this PR https://github.com/simonw/sqlite-utils/pull/689
Here's the transcript from that.
The release is now out with the following release notes:
- Fixed a bug with
sqlite-utils installwhen the tool had been installed usinguv. (#687)- The
--functionsargument now optionally accepts a path to a Python file as an alternative to a string full of code, and can be specified multiple times - see Defining custom SQL functions. (#659)sqlite-utilsnow requires on Python 3.10 or higher.
sqlite-utils 4.0a1 has several (minor) backwards incompatible changes
I released a new alpha version of sqlite-utils last night—the 128th release of that package since I started building it back in 2018.
[... 1,049 words]llm-gemini 0.27. New release of my LLM plugin for Google's Gemini models:
- Support for nested schemas in Pydantic, thanks Bill Pugh. #107
- Now tests against Python 3.14.
- Support for YouTube URLs as attachments and the
media_resolutionoption. Thanks, Duane Milne. #112- New model:
gemini-3-pro-preview. #113
The YouTube URL feature is particularly neat, taking advantage of this API feature. I used it against the Google Antigravity launch video:
llm -m gemini-3-pro-preview \
-a 'https://www.youtube.com/watch?v=nTOVIGsqCuY' \
'Summary, with detailed notes about what this thing is and how it differs from regular VS Code, then a complete detailed transcript with timestamps'
Here's the result. A spot-check of the timestamps against points in the video shows them to be exactly right.
llm-anthropic 0.22.
New release of my llm-anthropic plugin:
- Support for Claude's new structured outputs feature for Sonnet 4.5 and Opus 4.1. #54
- Support for the web search tool using
-o web_search 1- thanks Nick Powell and Ian Langworth. #30
The plugin previously powered LLM schemas using this tool-call based workaround. That code is still used for Anthropic's older models.
I also figured out uv recipes for running the plugin's test suite in an isolated environment, which are now baked into the new Justfile.
Datasette 1.0a22. New Datasette 1.0 alpha, adding some small features we needed to properly integrate the new permissions system with Datasette Cloud:
datasette serve --default-denyoption for running Datasette configured to deny all permissions by default. (#2592)datasette.is_client()method for detecting if code is executing inside a datasette.client request. (#2594)
Plus a developer experience improvement for plugin authors:
datasette.pmproperty can now be used to register and unregister plugins in tests. (#2595)
A new SQL-powered permissions system in Datasette 1.0a20
Datasette 1.0a20 is out with the biggest breaking API change on the road to 1.0, improving how Datasette’s permissions system works by migrating permission logic to SQL running in SQLite. This release involved 163 commits, with 10,660 additions and 1,825 deletions, most of which was written with the help of Claude Code.
[... 2,750 words]SLOCCount in WebAssembly. This project/side-quest got a little bit out of hand.
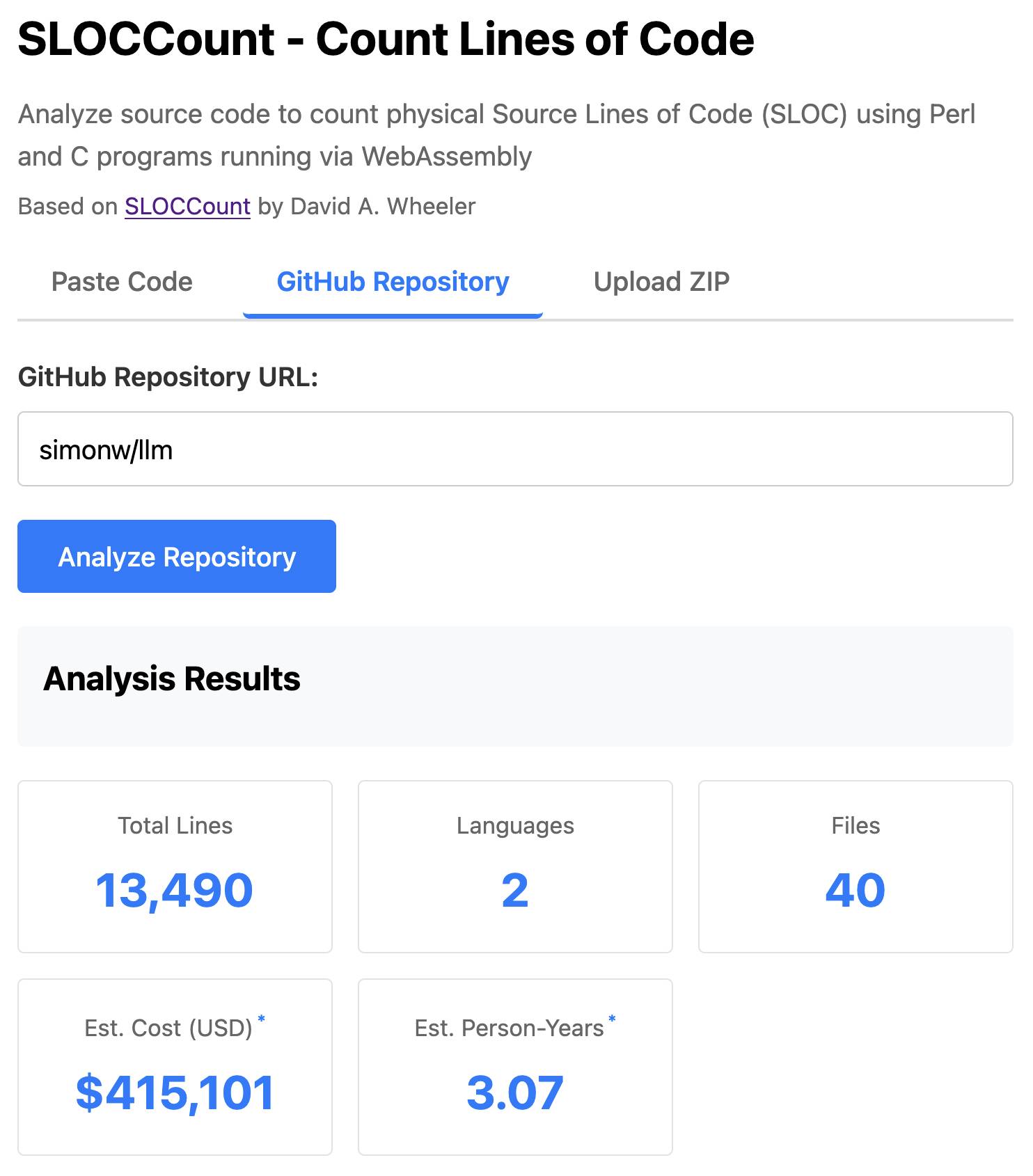
I remembered an old tool called SLOCCount which could count lines of code and produce an estimate for how much they would cost to develop. I thought it would be fun to play around with it again, especially given how cheap it is to generate code using LLMs these days.
Here's the homepage for SLOCCount by David A. Wheeler. It dates back to 2001!
I figured it might be fun to try and get it running on the web. Surely someone had compiled Perl to WebAssembly...?
WebPerl by Hauke Dämpfling is exactly that, even adding a neat <script type="text/perl"> tag.
I told Claude Code for web on my iPhone to figure it out and build something, giving it some hints from my initial research:
Build sloccount.html - a mobile friendly UI for running the Perl sloccount tool against pasted code or against a GitHub repository that is provided in a form field
It works using the webperl webassembly build of Perl, plus it loads Perl code from this exact commit of this GitHub repository https://github.com/licquia/sloccount/tree/7220ff627334a8f646617fe0fa542d401fb5287e - I guess via the GitHub API, maybe using the https://github.com/licquia/sloccount/archive/7220ff627334a8f646617fe0fa542d401fb5287e.zip URL if that works via CORS
Test it with playwright Python - don’t edit any file other than sloccount.html and a tests/test_sloccount.py file
Since I was working on my phone I didn't review the results at all. It seemed to work so I deployed it to static hosting... and then when I went to look at it properly later on found that Claude had given up, cheated and reimplemented it in JavaScript instead!
So I switched to Claude Code on my laptop where I have more control and coached Claude through implementing the project for real. This took way longer than the project deserved - probably a solid hour of my active time, spread out across the morning.
I've shared some of the transcripts - one, two, and three - as terminal sessions rendered to HTML using my rtf-to-html tool.
At one point I realized that the original SLOCCount project wasn't even entirely Perl as I had assumed, it included several C utilities! So I had Claude Code figure out how to compile those to WebAssembly (it used Emscripten) and incorporate those into the project (with notes on what it did.)
The end result (source code here) is actually pretty cool. It's a web UI with three tabs - one for pasting in code, a second for loading code from a GitHub repository and a third that lets you open a Zip file full of code that you want to analyze. Here's an animated demo:
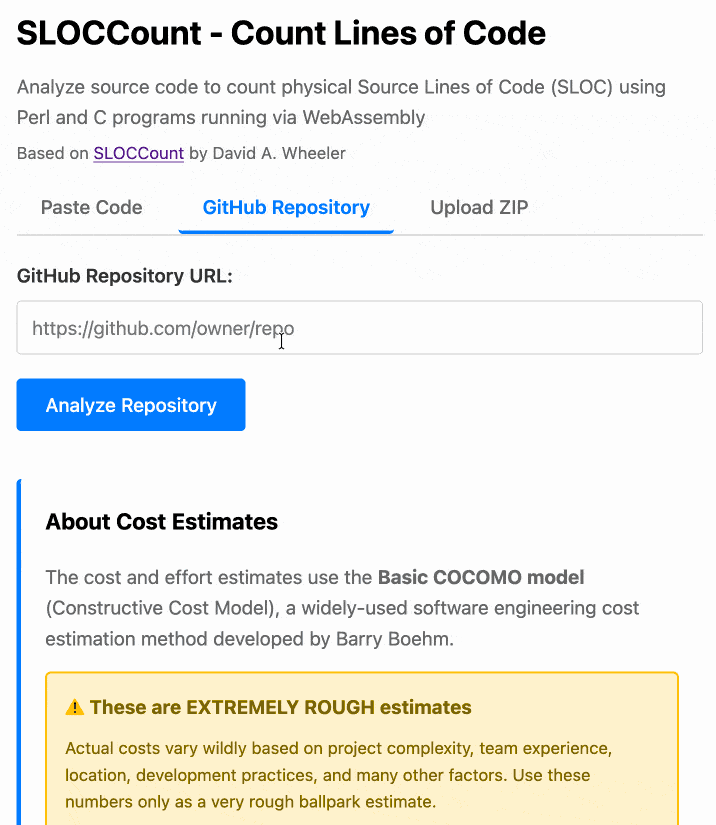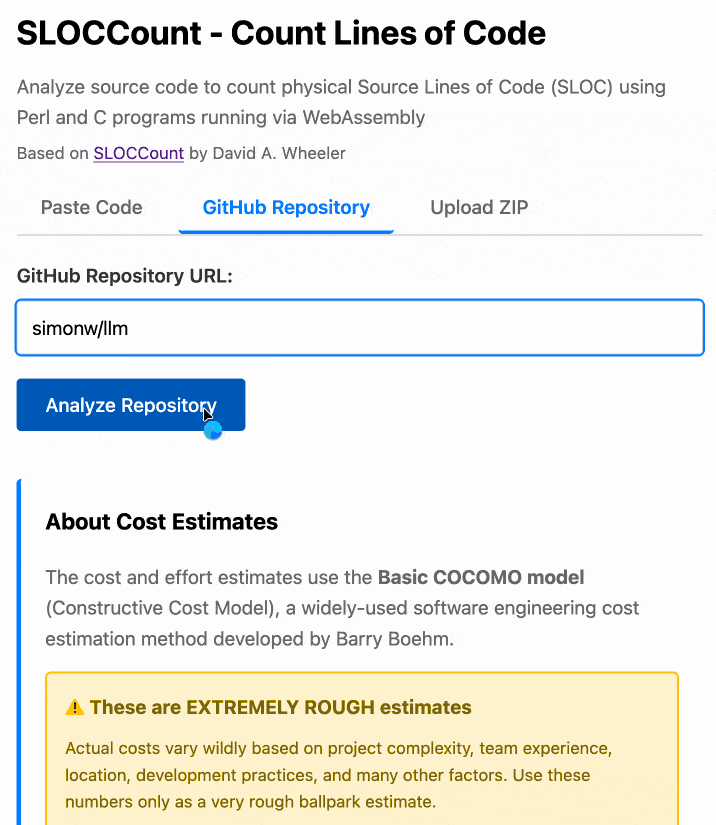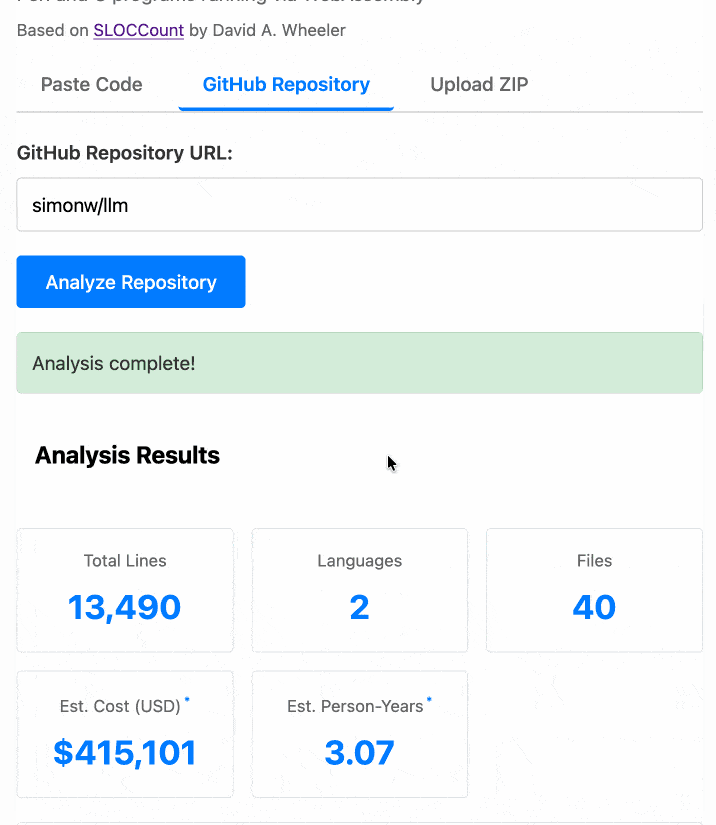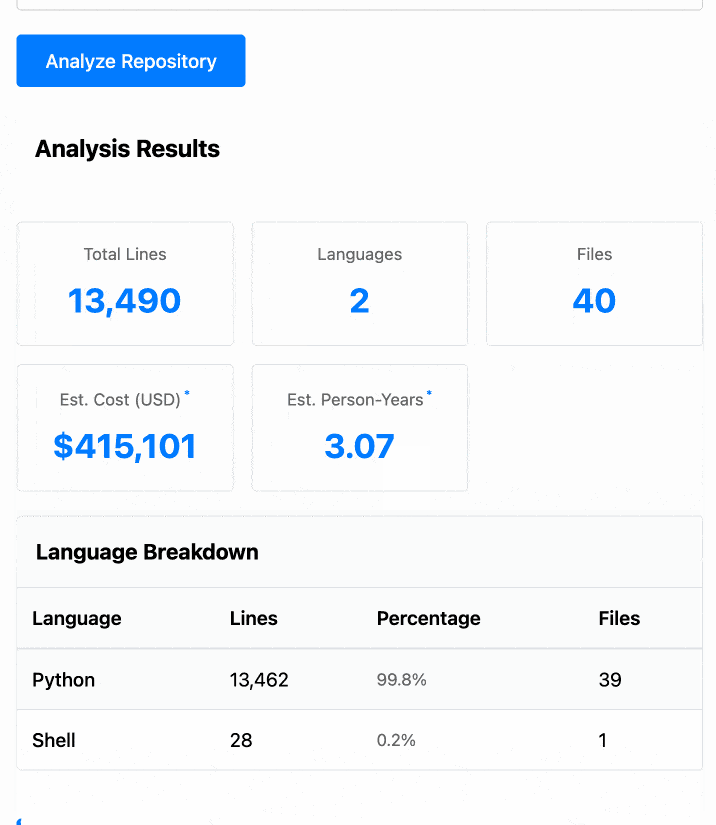
The cost estimates it produces are of very little value. By default it uses the original method from 2001. You can also twiddle the factors - bumping up the expected US software engineer's annual salary from its 2000 estimate of $56,286 is a good start!
I had ChatGPT take a guess at what those figures should be for today and included those in the tool, with a very prominent warning not to trust them in the slightest.
Claude can write complete Datasette plugins now
This isn’t necessarily surprising, but it’s worth noting anyway. Claude Sonnet 4.5 is capable of building a full Datasette plugin now.
[... 1,296 words]llm-openrouter 0.5. New release of my LLM plugin for accessing models made available via OpenRouter. The release notes in full:
- Support for tool calling. Thanks, James Sanford. #43
- Support for reasoning options, for example
llm -m openrouter/openai/gpt-5 'prove dogs exist' -o reasoning_effort medium. #45
Tool calling is a really big deal, as it means you can now use the plugin to try out tools (and build agents, if you like) against any of the 179 tool-enabled models on that platform:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm models --tools | grep 'OpenRouter:' | wc -l
# Outputs 179
Quite a few of the models hosted on OpenRouter can be accessed for free. Here's a tool-usage example using the llm-tools-datasette plugin against the new Grok 4 Fast model:
llm install llm-tools-datasette
llm -m openrouter/x-ai/grok-4-fast:free -T 'Datasette("https://datasette.io/content")' 'Count available plugins'
Outputs:
There are 154 available plugins.
The output of llm logs -cu shows the tool calls and SQL queries it executed to get that result.
Any time I share my collection of tools built using vibe coding and AI-assisted development (now at 124, here's the definitive list) someone will inevitably complain that they're mostly trivial.
A lot of them are! Here's a list of some that I think are genuinely useful and worth highlighting:
- OCR PDFs and images directly in your browser. This is the tool that started the collection, and I still use it on a regular basis. You can open any PDF in it (even PDFs that are just scanned images with no embedded text) and it will extract out the text so you can copy-and-paste it. It uses PDF.js and Tesseract.js to do that entirely in the browser. I wrote about how I originally built that here.
- Annotated Presentation Creator - this one is so useful. I use it to turn talks that I've given into full annotated presentations, where each slide is accompanied by detailed notes. I have 29 blog entries like that now and most of them were written with the help of this tool. Here's how I built that, plus follow-up prompts I used to improve it.
- Image resize, crop, and quality comparison - I use this for every single image I post to my blog. It lets me drag (or paste) an image onto the page and then shows me a comparison of different sizes and quality settings, each of which I can download and then upload to my S3 bucket. I recently added a slightly janky but mobile-accessible cropping tool as well. Prompts.
- Social Media Card Cropper - this is an even more useful image tool. Bluesky, Twitter etc all benefit from a 2x1 aspect ratio "card" image. I built this custom tool for creating those - you can paste in an image and crop and zoom it to the right dimensions. I use this all the time. Prompts.
- SVG to JPEG/PNG - every time I publish an SVG of a pelican riding a bicycle I use this tool to turn that SVG into a JPEG or PNG. Prompts.
- Encrypt / decrypt message - I often run workshops where I want to distribute API keys to the workshop participants. This tool lets me encrypt a message with a passphrase, then share the resulting URL to the encrypted message and tell people (with a note on a slide) how to decrypt it. Prompt.
- Jina Reader - enter a URL, get back a Markdown version of the page. It's a thin wrapper over the Jina Reader API, but it's useful because it adds a "copy to clipboard" button which means it's one of the fastest way to turn a webpage into data on a clipboard on my mobile phone. I use this several times a week. Prompts.
- llm-prices.com - a pricing comparison and token pricing calculator for various hosted LLMs. This one started out as a tool but graduated to its own domain name. Here's the prompting development history.
- Open Sauce 2025 - an unofficial schedule for the Open Sauce conference, complete with option to export to ICS plus a search tool and now-and-next. I built this entirely on my phone using OpenAI Codex, including scraping the official schedule - full details here.
- Hacker News Multi-Term Histogram - compare search terms on Hacker News to see how their relative popularity changed over time. Prompts.
- Passkey experiment - a UI for trying out the Passkey / WebAuthn APIs that are built into browsers these days. Prompts.
- Incomplete JSON Pretty Printer - do you ever find yourself staring at a screen full of JSON that isn't completely valid because it got truncated? This tool will pretty-print it anyway. Prompts.
- Bluesky WebSocket Feed Monitor - I found out Bluesky has a Firehose API that can be accessed directly from the browser, so I vibe-coded up this tool to try it out. Prompts.
In putting this list together I realized I wanted to be able to link to the prompts for each tool... but those were hidden inside a collapsed <details><summary> element for each one. So I fired up OpenAI Codex and prompted:
Update the script that builds the colophon.html page such that the generated page has a tiny bit of extra JavaScript - when the page is loaded as e.g. https://tools.simonwillison.net/colophon#jina-reader.html it should notice the #jina-reader.html fragment identifier and ensure that the Development history details/summary for that particular tool is expanded when the page loads.
It authored this PR for me which fixed the problem.
simonw/codespaces-llm. GitHub Codespaces provides full development environments in your browser, and is free to use with anyone with a GitHub account. Each environment has a full Linux container and a browser-based UI using VS Code.
I found out today that GitHub Codespaces come with a GITHUB_TOKEN environment variable... and that token works as an API key for accessing LLMs in the GitHub Models collection, which includes dozens of models from OpenAI, Microsoft, Mistral, xAI, DeepSeek, Meta and more.
Anthony Shaw's llm-github-models plugin for my LLM tool allows it to talk directly to GitHub Models. I filed a suggestion that it could pick up that GITHUB_TOKEN variable automatically and Anthony shipped v0.18.0 with that feature a few hours later.
... which means you can now run the following in any Python-enabled Codespaces container and get a working llm command:
pip install llm
llm install llm-github-models
llm models default github/gpt-4.1
llm "Fun facts about pelicans"
Setting the default model to github/gpt-4.1 means you get free (albeit rate-limited) access to that OpenAI model.
To save you from needing to even run that sequence of commands I've created a new GitHub repository, simonw/codespaces-llm, which pre-installs and runs those commands for you.
Anyone with a GitHub account can use this URL to launch a new Codespaces instance with a configured llm terminal command ready to use:
codespaces.new/simonw/codespaces-llm?quickstart=1
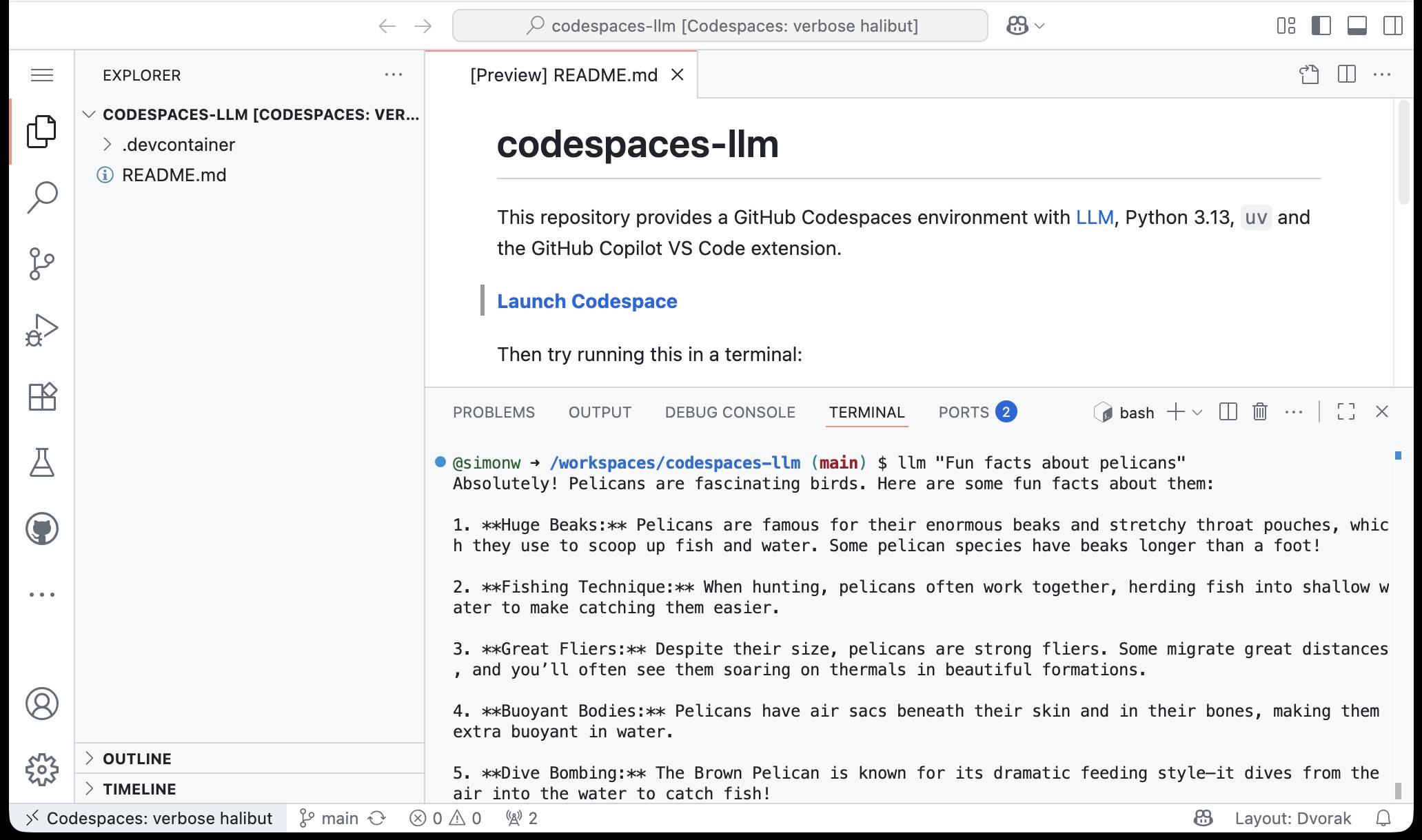
While putting this together I wrote up what I've learned about devcontainers so far as a TIL: Configuring GitHub Codespaces using devcontainers.
LLM 0.27, the annotated release notes: GPT-5 and improved tool calling
I shipped LLM 0.27 today (followed by a 0.27.1 with minor bug fixes), adding support for the new GPT-5 family of models from OpenAI plus a flurry of improvements to the tool calling features introduced in LLM 0.26. Here are the annotated release notes.
[... 1,174 words]Using LLMs for code archaeology is pretty fun.
I stumbled across this blog entry from 2003 today, in which I had gotten briefly excited about ColdFusion and implemented an experimental PHP template engine that used XML tags to achieve a similar effect:
<h1>%title%</h1> <sql id="recent"> select title from entries order by added desc limit 0, %limit% </sql> <ul> <output sql="recent"> <li>%title%</li> </output> </ul>
I'd completely forgotten about this, and in scanning through the PHP it looked like it had extra features that I hadn't described in the post.
So... I fed my 22 year old TemplateParser.class.php file into Claude and prompted:
Write detailed markdown documentation for this template language
Here's the resulting documentation. It's pretty good, but the highlight was the Claude transcript which concluded:
This appears to be a custom template system from the mid-2000s era, designed to separate presentation logic from PHP code while maintaining database connectivity for dynamic content generation.
Mid-2000s era indeed!
llm-mistral 0.14. I added tool-support to my plugin for accessing the Mistral API from LLM today, plus support for Mistral's new Codestral Embed embedding model.
An interesting challenge here is that I'm not using an official client library for llm-mistral - I rolled my own client on top of their streaming HTTP API using Florimond Manca's httpx-sse library. It's a very pleasant way to interact with streaming APIs - here's my code that does most of the work.
The problem I faced is that Mistral's API documentation for function calling has examples in Python and TypeScript but doesn't include curl or direct documentation of their HTTP endpoints!
I needed documentation at the HTTP level. Could I maybe extract that directly from Mistral's official Python library?
It turns out I could. I started by cloning the repo:
git clone https://github.com/mistralai/client-python
cd client-python/src/mistralai
files-to-prompt . | ttokMy ttok tool gave me a token count of 212,410 (counted using OpenAI's tokenizer, but that's normally a close enough estimate) - Mistral's models tap out at 128,000 so I switched to Gemini 2.5 Flash which can easily handle that many.
I ran this:
files-to-prompt -c . > /tmp/mistral.txt
llm -f /tmp/mistral.txt \
-m gemini-2.5-flash-preview-05-20 \
-s 'Generate comprehensive HTTP API documentation showing
how function calling works, include example curl commands for each step'The results were pretty spectacular! Gemini 2.5 Flash produced a detailed description of the exact set of HTTP APIs I needed to interact with, and the JSON formats I should pass to them.
There are a bunch of steps needed to get tools working in a new model, as described in the LLM plugin authors documentation. I started working through them by hand... and then got lazy and decided to see if I could get a model to do the work for me.
This time I tried the new Claude Opus 4. I fed it three files: my existing, incomplete llm_mistral.py, a full copy of llm_gemini.py with its working tools implementation and a copy of the API docs Gemini had written for me earlier. I prompted:
I need to update this Mistral code to add tool support. I've included examples of that code for Gemini, and a detailed README explaining the Mistral format.
Claude churned away and wrote me code that was most of what I needed. I tested it in a bunch of different scenarios, pasted problems back into Claude to see what would happen, and eventually took over and finished the rest of the code myself. Here's the full transcript.
I'm a little sad I didn't use Mistral to write the code to support Mistral, but I'm pleased to add yet another model family to the list that's supported for tool usage in LLM.