1,267 posts tagged “python”
The Python programming language.
2024
Why I Still Use Python Virtual Environments in Docker (via) Hynek Schlawack argues for using virtual environments even when running Python applications in a Docker container. This argument was most convincing to me:
I'm responsible for dozens of services, so I appreciate the consistency of knowing that everything I'm deploying is in
/app, and if it's a Python application, I know it's a virtual environment, and if I run/app/bin/python, I get the virtual environment's Python with my application ready to be imported and run.
Also:
It’s good to use the same tools and primitives in development and in production.
Also worth a look: Hynek's guide to Production-ready Docker Containers with uv, an actively maintained guide that aims to reflect ongoing changes made to uv itself.
Anatomy of a Textual User Interface. Will McGugan used Textual and my LLM Python library to build a delightful TUI for talking to a simulation of Mother, the AI from the Aliens movies:
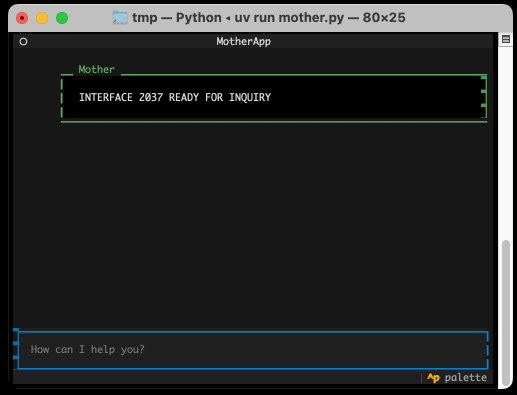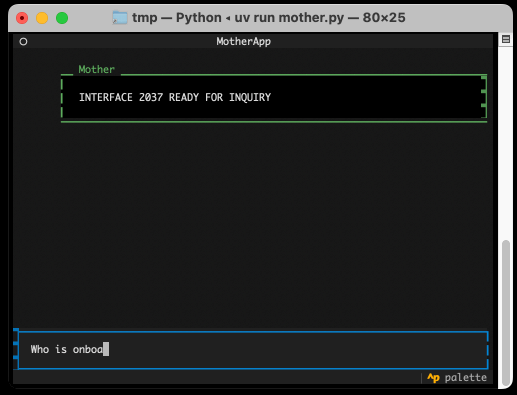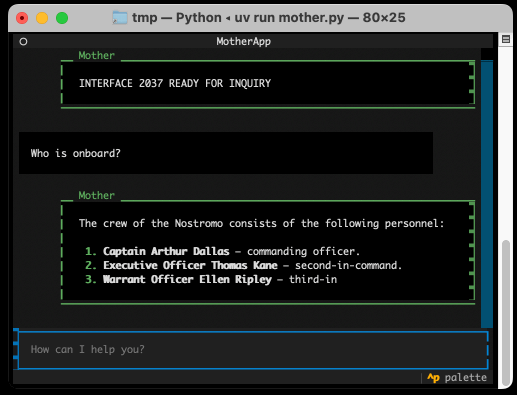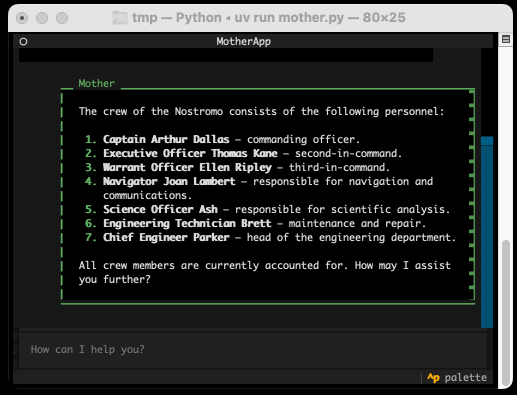
The entire implementation is just 77 lines of code. It includes PEP 723 inline dependency information:
# /// script # requires-python = ">=3.12" # dependencies = [ # "llm", # "textual", # ] # ///
Which means you can run it in a dedicated environment with the correct dependencies installed using uv run like this:
wget 'https://gist.githubusercontent.com/willmcgugan/648a537c9d47dafa59cb8ece281d8c2c/raw/7aa575c389b31eb041ae7a909f2349a96ffe2a48/mother.py'
export OPENAI_API_KEY='sk-...'
uv run mother.pyI found the send_prompt() method particularly interesting. Textual uses asyncio for its event loop, but LLM currently only supports synchronous execution and can block for several seconds while retrieving a prompt.
Will used the Textual @work(thread=True) decorator, documented here, to run that operation in a thread:
@work(thread=True) def send_prompt(self, prompt: str, response: Response) -> None: response_content = "" llm_response = self.model.prompt(prompt, system=SYSTEM) for chunk in llm_response: response_content += chunk self.call_from_thread(response.update, response_content)
Looping through the response like that and calling self.call_from_thread(response.update, response_content) with an accumulated string is all it takes to implement streaming responses in the Textual UI, and that Response object sublasses textual.widgets.Markdown so any Markdown is rendered using Rich.
uvtrick (via) This "fun party trick" by Vincent D. Warmerdam is absolutely brilliant and a little horrifying. The following code:
from uvtrick import Env def uses_rich(): from rich import print print("hi :vampire:") Env("rich", python="3.12").run(uses_rich)
Executes that uses_rich() function in a fresh virtual environment managed by uv, running the specified Python version (3.12) and ensuring the rich package is available - even if it's not installed in the current environment.
It's taking advantage of the fact that uv is so fast that the overhead of getting this to work is low enough for it to be worth at least playing with the idea.
The real magic is in how uvtrick works. It's only 127 lines of code with some truly devious trickery going on.
That Env.run() method:
- Creates a temporary directory
- Pickles the
argsandkwargsand saves them topickled_inputs.pickle - Uses
inspect.getsource()to retrieve the source code of the function passed torun() - Writes that to a
pytemp.pyfile, along with a generatedif __name__ == "__main__":block that calls the function with the pickled inputs and saves its output to another pickle file calledtmp.pickle
Having created the temporary Python file it executes the program using a command something like this:
uv run --with rich --python 3.12 --quiet pytemp.pyIt reads the output from tmp.pickle and returns it to the caller!
Anthropic’s Prompt Engineering Interactive Tutorial (via) Anthropic continue their trend of offering the best documentation of any of the leading LLM vendors. This tutorial is delivered as a set of Jupyter notebooks - I used it as an excuse to try uvx like this:
git clone https://github.com/anthropics/courses
uvx --from jupyter-core jupyter notebook coursesThis installed a working Jupyter system, started the server and launched my browser within a few seconds.
The first few chapters are pretty basic, demonstrating simple prompts run through the Anthropic API. I used %pip install anthropic instead of !pip install anthropic to make sure the package was installed in the correct virtual environment, then filed an issue and a PR.
One new-to-me trick: in the first chapter the tutorial suggests running this:
API_KEY = "your_api_key_here" %store API_KEY
This stashes your Anthropic API key in the IPython store. In subsequent notebooks you can restore the API_KEY variable like this:
%store -r API_KEY
I poked around and on macOS those variables are stored in files of the same name in ~/.ipython/profile_default/db/autorestore.
Chapter 4: Separating Data and Instructions included some interesting notes on Claude's support for content wrapped in XML-tag-style delimiters:
Note: While Claude can recognize and work with a wide range of separators and delimeters, we recommend that you use specifically XML tags as separators for Claude, as Claude was trained specifically to recognize XML tags as a prompt organizing mechanism. Outside of function calling, there are no special sauce XML tags that Claude has been trained on that you should use to maximally boost your performance. We have purposefully made Claude very malleable and customizable this way.
Plus this note on the importance of avoiding typos, with a nod back to the problem of sandbagging where models match their intelligence and tone to that of their prompts:
This is an important lesson about prompting: small details matter! It's always worth it to scrub your prompts for typos and grammatical errors. Claude is sensitive to patterns (in its early years, before finetuning, it was a raw text-prediction tool), and it's more likely to make mistakes when you make mistakes, smarter when you sound smart, sillier when you sound silly, and so on.
Chapter 5: Formatting Output and Speaking for Claude includes notes on one of Claude's most interesting features: prefill, where you can tell it how to start its response:
client.messages.create( model="claude-3-haiku-20240307", max_tokens=100, messages=[ {"role": "user", "content": "JSON facts about cats"}, {"role": "assistant", "content": "{"} ] )
Things start to get really interesting in Chapter 6: Precognition (Thinking Step by Step), which suggests using XML tags to help the model consider different arguments prior to generating a final answer:
Is this review sentiment positive or negative? First, write the best arguments for each side in <positive-argument> and <negative-argument> XML tags, then answer.
The tags make it easy to strip out the "thinking out loud" portions of the response.
It also warns about Claude's sensitivity to ordering. If you give Claude two options (e.g. for sentiment analysis):
In most situations (but not all, confusingly enough), Claude is more likely to choose the second of two options, possibly because in its training data from the web, second options were more likely to be correct.
This effect can be reduced using the thinking out loud / brainstorming prompting techniques.
A related tip is proposed in Chapter 8: Avoiding Hallucinations:
How do we fix this? Well, a great way to reduce hallucinations on long documents is to make Claude gather evidence first.
In this case, we tell Claude to first extract relevant quotes, then base its answer on those quotes. Telling Claude to do so here makes it correctly notice that the quote does not answer the question.
I really like the example prompt they provide here, for answering complex questions against a long document:
<question>What was Matterport's subscriber base on the precise date of May 31, 2020?</question>
Please read the below document. Then, in <scratchpad> tags, pull the most relevant quote from the document and consider whether it answers the user's question or whether it lacks sufficient detail. Then write a brief numerical answer in <answer> tags.
light-the-torchis a small utility that wrapspipto ease the installation process for PyTorch distributions liketorch,torchvision,torchaudio, and so on as well as third-party packages that depend on them. It auto-detects compatible CUDA versions from the local setup and installs the correct PyTorch binaries without user interference.
Use it like this:
pip install light-the-torch
ltt install torchIt works by wrapping and patching pip.
There is an elephant in the room which is that Astral is a VC funded company. What does that mean for the future of these tools? Here is my take on this: for the community having someone pour money into it can create some challenges. For the PSF and the core Python project this is something that should be considered. However having seen the code and what uv is doing, even in the worst possible future this is a very forkable and maintainable thing. I believe that even in case Astral shuts down or were to do something incredibly dodgy licensing wise, the community would be better off than before uv existed.
#!/usr/bin/env -S uv run (via) This is a really neat pattern. Start your Python script like this:
#!/usr/bin/env -S uv run
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flask==3.*",
# ]
# ///
import flask
# ...
And now if you chmod 755 it you can run it on any machine with the uv binary installed like this: ./app.py - and it will automatically create its own isolated environment and run itself with the correct installed dependencies and even the correctly installed Python version.
All of that from putting uv run in the shebang line!
Code from this PR by David Laban.
uv: Unified Python packaging (via) Huge new release from the Astral team today. uv 0.3.0 adds a bewildering array of new features, as part of their attempt to build "Cargo, for Python".
It's going to take a while to fully absorb all of this. Some of the key new features are:
uv tool run cowsay, aliased touvx cowsay- a pipx alternative that runs a tool in its own dedicated virtual environment (tucked away in~/Library/Caches/uv), installing it if it's not present. It has a neat--withoption for installing extras - I tried that just now withuvx --with datasette-cluster-map datasetteand it ran Datasette with thedatasette-cluster-mapplugin installed.- Project management, as an alternative to tools like Poetry and PDM.
uv initcreates apyproject.tomlfile in the current directory,uv add sqlite-utilsthen creates and activates a.venvvirtual environment, adds the package to thatpyproject.tomland adds all of its dependencies to a newuv.lockfile (like this one). Thatuv.lockis described as a universal or cross-platform lockfile that can support locking dependencies for multiple platforms. - Single-file script execution using
uv run myscript.py, where those scripts can define their own dependencies using PEP 723 inline metadata. These dependencies are listed in a specially formatted comment and will be installed into a virtual environment before the script is executed. - Python version management similar to pyenv. The new
uv python listcommand lists all Python versions available on your system (including detecting various system and Homebrew installations), anduv python install 3.13can then install a uv-managed Python using Gregory Szorc's invaluable python-build-standalone releases.
It's all accompanied by new and very thorough documentation.
The paint isn't even dry on this stuff - it's only been out for a few hours - but this feels very promising to me. The idea that you can install uv (a single Rust binary) and then start running all of these commands to manage Python installations and their dependencies is very appealing.
If you’re wondering about the relationship between this and Rye - another project that Astral adopted solving a subset of these problems - this forum thread clarifies that they intend to continue maintaining Rye but are eager for uv to work as a full replacement.
Writing your pyproject.toml (via) When I started exploring pyproject.toml a year ago I had trouble finding comprehensive documentation about what should go in that file.
Since then the Python Packaging Guide split out this page, which is exactly what I was looking for back then.
Upgrading my cookiecutter templates to use python -m pytest.
Every now and then I get caught out by weird test failures when I run pytest and it turns out I'm running the wrong installation of that tool, so my tests fail because that pytest is executing in a different virtual environment from the one needed by the tests.
The fix for this is easy: run python -m pytest instead, which guarantees that you will run pytest in the same environment as your currently active Python.
Yesterday I went through and updated every one of my cookiecutter templates (python-lib, click-app, datasette-plugin, sqlite-utils-plugin, llm-plugin) to use this pattern in their READMEs and generated repositories instead, to help spread that better recipe a little bit further.
mlx-whisper
(via)
Apple's MLX framework for running GPU-accelerated machine learning models on Apple Silicon keeps growing new examples. mlx-whisper is a Python package for running OpenAI's Whisper speech-to-text model. It's really easy to use:
pip install mlx-whisper
Then in a Python console:
>>> import mlx_whisper
>>> result = mlx_whisper.transcribe(
... "/tmp/recording.mp3",
... path_or_hf_repo="mlx-community/distil-whisper-large-v3")
.gitattributes: 100%|███████████| 1.52k/1.52k [00:00<00:00, 4.46MB/s]
config.json: 100%|██████████████| 268/268 [00:00<00:00, 843kB/s]
README.md: 100%|████████████████| 332/332 [00:00<00:00, 1.95MB/s]
Fetching 4 files: 50%|████▌ | 2/4 [00:01<00:01, 1.26it/s]
weights.npz: 63%|██████████ ▎ | 944M/1.51G [02:41<02:15, 4.17MB/s]
>>> result.keys()
dict_keys(['text', 'segments', 'language'])
>>> result['language']
'en'
>>> len(result['text'])
100105
>>> print(result['text'][:3000])
This is so exciting. I have to tell you, first of all ...Here's Activity Monitor confirming that the Python process is using the GPU for the transcription:

This example downloaded a 1.5GB model from Hugging Face and stashed it in my ~/.cache/huggingface/hub/models--mlx-community--distil-whisper-large-v3 folder.
Calling .transcribe(filepath) without the path_or_hf_repo argument uses the much smaller (74.4 MB) whisper-tiny-mlx model.
A few people asked how this compares to whisper.cpp. Bill Mill compared the two and found mlx-whisper to be about 3x faster on an M1 Max.
Update: this note from Josh Marshall:
That '3x' comparison isn't fair; completely different models. I ran a test (14" M1 Pro) with the full (non-distilled) large-v2 model quantised to 8 bit (which is my pick), and whisper.cpp was 1m vs 1m36 for mlx-whisper.
I've now done a better test, using the MLK audio, multiple runs and 2 models (distil-large-v3, large-v2-8bit)... and mlx-whisper is indeed 30-40% faster
PEP 750 – Tag Strings For Writing Domain-Specific Languages. A new PEP by Jim Baker, Guido van Rossum and Paul Everitt that proposes introducing a feature to Python inspired by JavaScript's tagged template literals.
F strings in Python already use a f"f prefix", this proposes allowing any Python symbol in the current scope to be used as a string prefix as well.
I'm excited about this. Imagine being able to compose SQL queries like this:
query = sql"select * from articles where id = {id}"
Where the sql tag ensures that the {id} value there is correctly quoted and escaped.
Currently under active discussion on the official Python discussion forum.
django-http-debug, a new Django app mostly written by Claude
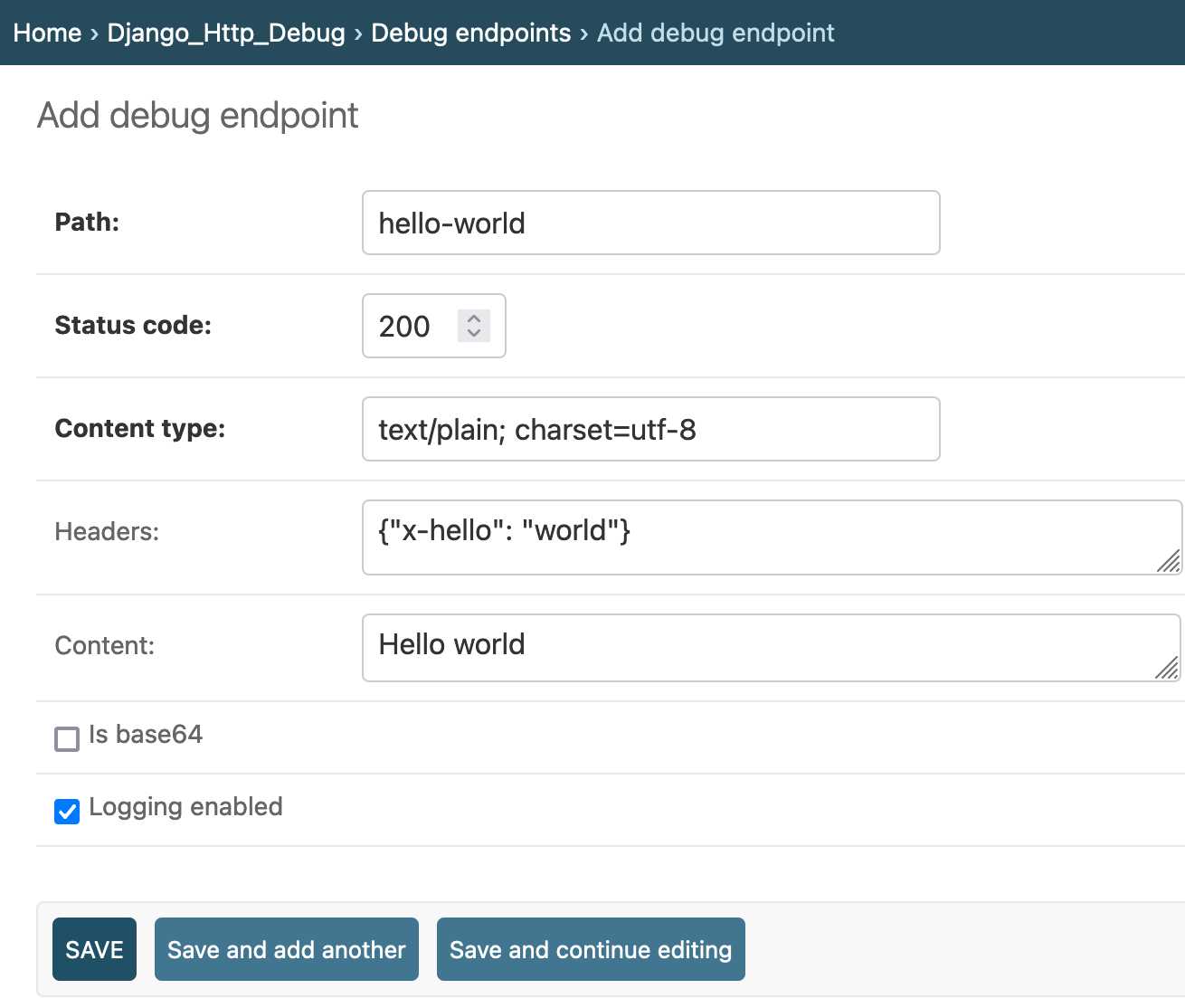
Yesterday I finally developed something I’ve been casually thinking about building for a long time: django-http-debug. It’s a reusable Django app—something you can pip install into any Django project—which provides tools for quickly setting up a URL that returns a canned HTTP response and logs the full details of any incoming request to a database table.
cibuildwheel 2.20.0 now builds Python 3.13 wheels by default (via)
CPython 3.13 wheels are now built by default […] This release includes CPython 3.13.0rc1, which is guaranteed to be ABI compatible with the final release.
cibuildwheel is an underrated but crucial piece of the overall Python ecosystem.
Python wheel packages that include binary compiled components - packages with C extensions for example - need to be built multiple times, once for each combination of Python version, operating system and architecture.
A package like Adam Johnson’s time-machine - which bundles a 500 line C extension - can end up with 55 different wheel files with names like time_machine-2.15.0-cp313-cp313-win_arm64.whl and time_machine-2.15.0-cp38-cp38-musllinux_1_2_x86_64.whl.
Without these wheels, anyone who runs pip install time-machine will need to have a working C compiler toolchain on their machine for the command to work.
cibuildwheel solves the problem of building all of those wheels for all of those different platforms on the CI provider of your choice. Adam is using it in GitHub Actions for time-machine, and his .github/workflows/build.yml file neatly demonstrates how concise the configuration can be once you figure out how to use it.
The first release candidate of Python 3.13 hit its target release date of August 1st, and the final version looks on schedule for release on the 1st of October. Since this rc should be binary compatible with the final build now is the time to start shipping those wheels to PyPI.
Aider. Aider is an impressive open source local coding chat assistant terminal application, developed by Paul Gauthier (founding CTO of Inktomi back in 1996-2000).
I tried it out today, using an Anthropic API key to run it using Claude 3.5 Sonnet:
pipx install aider-chat
export ANTHROPIC_API_KEY=api-key-here
aider --dark-mode
I found the --dark-mode flag necessary to make it legible using the macOS terminal "Pro" theme.
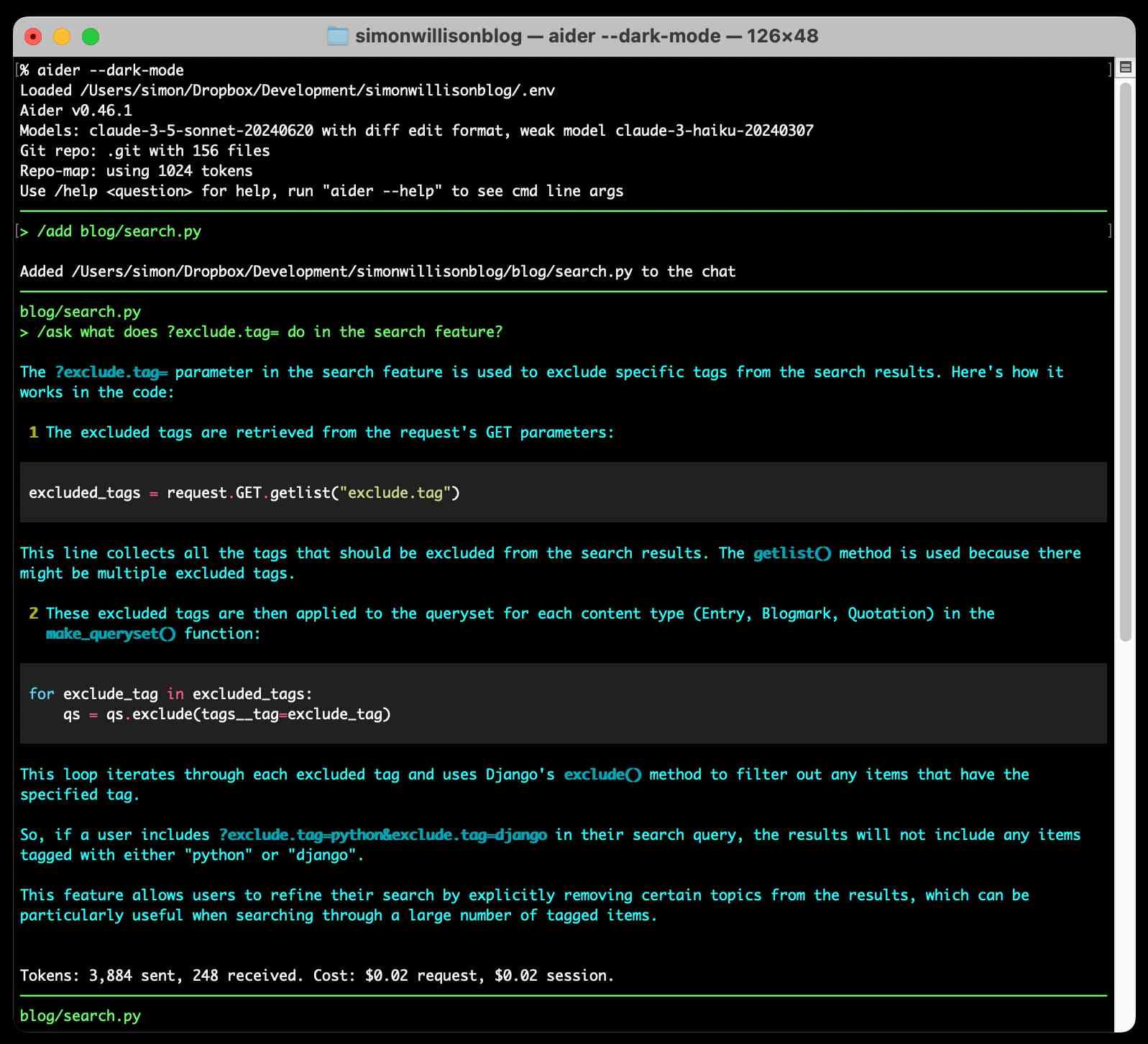
Aider starts by generating a concise map of files in your current Git repository. This is passed to the LLM along with the prompts that you type, and Aider can then request additional files be added to that context - or you can add the manually with the /add filename command.
It defaults to making modifications to files and then committing them directly to Git with a generated commit message. I found myself preferring the /ask command which lets you ask a question without making any file modifications:
The Aider documentation includes extensive examples and the tool can work with a wide range of different LLMs, though it recommends GPT-4o, Claude 3.5 Sonnet (or 3 Opus) and DeepSeek Coder V2 for the best results. Aider maintains its own leaderboard, emphasizing that "Aider works best with LLMs which are good at editing code, not just good at writing code".
The prompts it uses are pretty fascinating - they're tucked away in various *_prompts.py files in aider/coders.
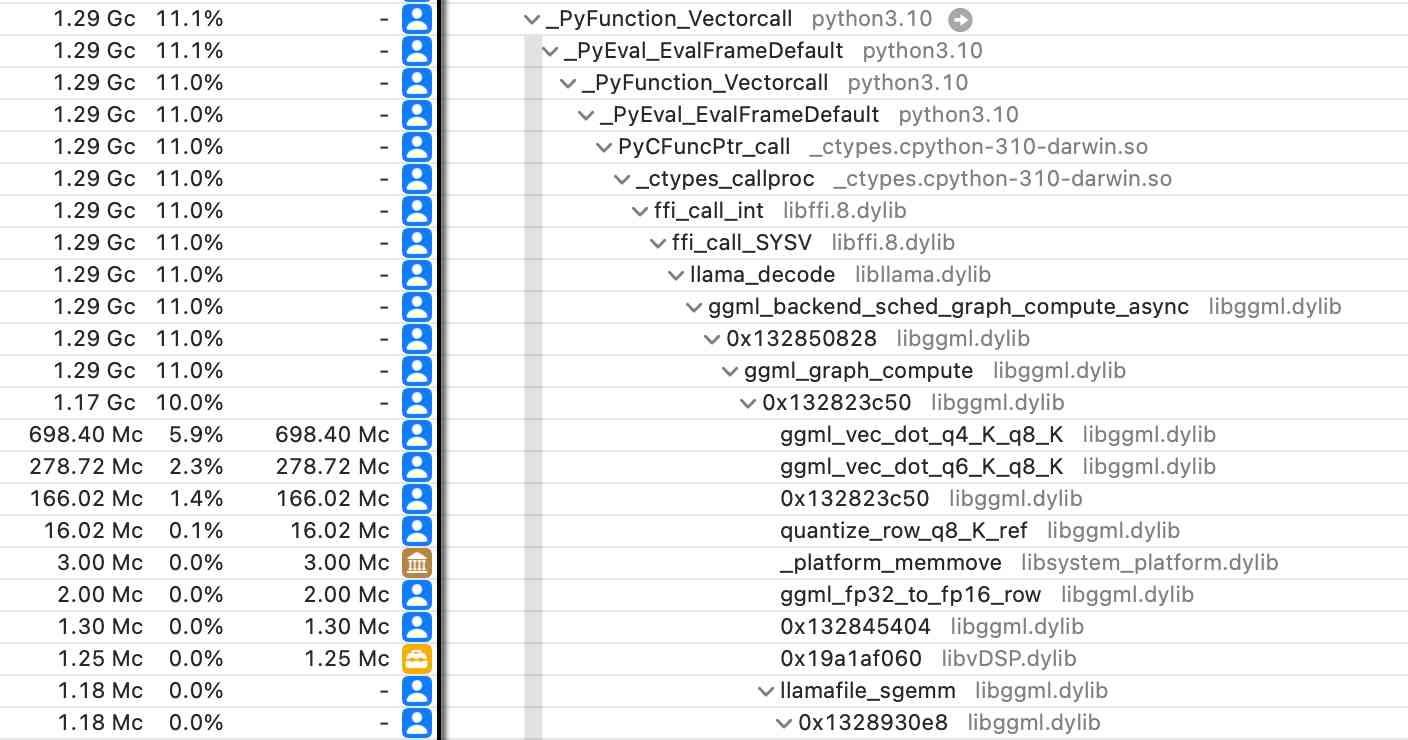
Did you know about Instruments? (via) Thorsten Ball shows how the macOS Instruments app (installed as part of Xcode) can be used to run a CPU profiler against any application - not just code written in Swift/Objective C.
I tried this against a Python process running LLM executing a Llama 3.1 prompt with my new llm-gguf plugin and captured this:
wat
(via)
This is a really neat Python debugging utility. Install with pip install wat-inspector and then inspect any Python object like this:
from wat import wat
wat / myvariable
The wat / x syntax is a shortcut for wat(x) that's quicker to type.
The tool dumps out all sorts of useful introspection about the variable, value, class or package that you pass to it.
There are several variants: wat.all / x gives you all of them, or you can chain several together like wat.dunder.code / x.
The documentation also provides a slightly intimidating copy-paste version of the tool which uses exec(), zlib and base64 to help you paste the full implementation directly into any Python interactive session without needing to install it first.
pip install GPT (via) I've been uploading wheel files to ChatGPT in order to install them into Code Interpreter for a while now. Nico Ritschel built a better way: this GPT can download wheels directly from PyPI and then install them.
I didn't think this was possible, since Code Interpreter is blocked from making outbound network requests.
Nico's trick uses a new-to-me feature of GPT Actions: you can return up to ten files from an action call and ChatGPT will download those files to the same disk volume that Code Interpreter can access.
Nico wired up a Val Town endpoint that can divide a PyPI wheel into multiple 9.5MB files (if necessary) to fit the file size limit for files returned to a GPT, then uses prompts to tell ChatGPT to combine the resulting files and treat them as installable wheels.
GitHub Actions: Faster Python runs with cached virtual environments (via) Adam Johnson shares his improved pattern for caching Python environments in GitHub Actions.
I've been using the pattern where you add cache: pip to the actions/setup-python block, but it has two disadvantages: if the tests fail the cache won't be saved at the end, and it still spends time installing the packages despite not needing to download them fresh since the wheels are in the cache.
Adam's pattern works differently: he caches the entire .venv/ folder between runs, avoiding the overhead of installing all of those packages. He also wraps the block that installs the packages between explicit actions/cache/restore and actions/cache/save steps to avoid the case where failed tests skip the cache persistence.
Announcing our DjangoCon US 2024 Talks! I'm speaking at DjangoCon in Durham, NC in September.
My accepted talk title was How to design and implement extensible software with plugins. Here's my abstract:
Plugins offer a powerful way to extend software packages. Tools that support a plugin architecture include WordPress, Jupyter, VS Code and pytest - each of which benefits from an enormous array of plugins adding all kinds of new features and expanded capabilities.
Adding plugin support to an open source project can greatly reduce the friction involved in attracting new contributors. Users can work independently and even package and publish their work without needing to directly coordinate with the project's core maintainers. As a maintainer this means you can wake up one morning and your software grew new features without you even having to review a pull request!
There's one catch: information on how to design and implement plugin support for a project is scarce.
I now have three major open source projects that support plugins, with over 200 plugins published across those projects. I'll talk about everything I've learned along the way: when and how to use plugins, how to design plugin hooks and how to ensure your plugin authors have as good an experience as possible.
I'm going to be talking about what I've learned integrating Pluggy with Datasette, LLM and sqlite-utils. I've been looking for an excuse to turn this knowledge into a talk for ages, very excited to get to do it at DjangoCon!
Imitation Intelligence, my keynote for PyCon US 2024

I gave an invited keynote at PyCon US 2024 in Pittsburgh this year. My goal was to say some interesting things about AI—specifically about Large Language Models—both to help catch people up who may not have been paying close attention, but also to give people who were paying close attention some new things to think about.
[... 10,624 words]Free-threaded CPython is ready to experiment with! The Python 3.13 beta releases that include a "free-threaded" version that removes the GIL are now available to test! A team from Quansight Labs, home of the PyData core team, just launched py-free-threading.github.io to help document the new builds and track compatibility with Python's larger ecosystem.
Free-threading mode will not be enabled in Python installations by default. You can install special builds that have the option enabled today - I used the macOS installer and, after enabling the new build in the "Customize" panel in the installer, ended up with a /usr/local/bin/python3.13t binary which shows "Python 3.13.0b3 experimental free-threading build" when I run it.
Here's my TIL describing my experiments so far installing and running the 3.13 beta on macOS, which also includes a correction to an embarrassing bug that Claude introduced but I failed to catch!
datasette-python.
I just released a small new plugin for Datasette to assist with debugging. It adds a python subcommand which runs a Python process in the same virtual environment as Datasette itself.
I built it initially to help debug some issues in Datasette installed via Homebrew. The Homebrew installation has its own virtual environment, and sometimes it can be useful to run commands like pip list in the same environment as Datasette itself.
Now you can do this:
brew install datasette
datasette install datasette-python
datasette python -m pip list
I built a similar plugin for LLM last year, called llm-python - it's proved useful enough that I duplicated the design for Datasette.
Russell Keith-Magee: Build a cross-platform app with BeeWare. The session videos from PyCon US 2024 have started showing up on YouTube. So far just for the tutorials, which gave me a chance to catch up on the BeeWare project with this tutorial run by Russell Keith-Magee.
Here are the accompanying slides (PDF), or you can work through the official tutorial in the BeeWare documentation.
The tutorial did a great job of clarifying the difference between Briefcase and Toga, the two key components of the BeeWare ecosystem - each of which can be used independently of the other.
Briefcase solves packaging and installation: it allows a Python project to be packaged as a native application across macOS, Windows, iOS, Android and various flavours of Linux.
Toga is a toolkit for building cross-platform GUI applications in Python. A UI built using Toga will render with native widgets across all of those supported platforms, and experimental new modes also allow Toga apps to run as SPA web applications and as Rich-powered terminal tools (via toga-textual).
Russell is excellent at both designing and presenting tutorial-style workshops, and I made a bunch of mental notes on the structure of this one which I hope to apply to my own in the future.
marimo.app. The Marimo reactive notebook (previously) - a Python notebook that's effectively a cross between Jupyter and Observable - now also has a version that runs entirely in your browser using WebAssembly and Pyodide. Here's the documentation.
Python 3.12 change results in Apple App Store rejection
(via)
Such a frustrating demonstration of the very worst of Apple's opaque App Store review process. The Python 3.12 standard library urllib package includes the string itms-services, and after much investigation Eric Froemling managed to determine that Apple use a scanner and reject any app that has that string mentioned anywhere within their bundle.
Russell Keith-Magee has a thread on the Python forum discussing solutions. He doesn't think attempts to collaborate with Apple are likely to help:
That definitely sounds appealing as an approach - but in this case, it’s going to be screaming into the void. There’s barely even an appeals process for app rejection on Apple’s App Store. We definitely don’t have any sort of channel to raise a complaint that we could reasonably believe would result in a change of policy.
pkgutil.resolve_name(name) (via) Adam Johnson pointed out this utility method, added to the Python standard library in Python 3.9. It lets you provide a string that specifies a Python identifier to import from a module - a pattern frequently used in things like Django's configuration.
Path = pkgutil.resolve_name("pathlib:Path")
Encryption At Rest: Whose Threat Model Is It Anyway? (via) Security engineer Scott Arciszewski talks through the challenges of building a useful encryption-at-rest system for hosted software. Encryption at rest on a hard drive protects against physical access to the powered-down disk and little else. To implement encryption at rest in a multi-tenant SaaS system - such that even individuals with insider access (like access to the underlying database) are unable to read other user's data, is a whole lot more complicated.
Consider an attacker, Bob, with database access:
Here’s the stupid simple attack that works in far too many cases: Bob copies Alice’s encrypted data, and overwrites his records in the database, then accesses the insurance provider’s web app [using his own account].
The fix for this is to "use the AAD mechanism (part of the standard AEAD interface) to bind a ciphertext to its context." Python's cryptography package covers Authenticated Encryption with Associated Data as part of its "hazardous materials" advanced modules.
Katherine Michel’s PyCon US 2024 Recap (via) An informative write-up of this year’s PyCon US conference. It’s rare to see conference retrospectives with this much detail, this one is great!
Pyodide 0.26 Release (via) PyOdide provides Python packaged for browser WebAssembly alongside an ecosystem of additional tools and libraries to help Python and JavaScript work together.
The latest release bumps the Python version up to 3.12, and also adds support for pygame-ce, allowing games written using pygame to run directly in the browser.
The PyOdide community also just landed a 14-month-long PR adding support to cibuildwheel, which should make it easier to ship binary wheels targeting PyOdide.