6 posts tagged “replicate”
2024
Announcing FLUX1.1 [pro] and the BFL API (via) FLUX is the image generation model family from Black Forest Labs, a startup founded by members of the team that previously created Stable Diffusion.
Released today, FLUX1.1 [pro] continues the general trend of AI models getting both better and more efficient:
FLUX1.1 [pro] provides six times faster generation than its predecessor FLUX.1 [pro] while also improving image quality, prompt adherence, and diversity.
Black Forest Labs appear to have settled on a potentially workable business model: their smallest, fastest model FLUX.1 [schnell] is Apache 2 licensed. The next step up is FLUX.1 [dev] which is open weights for non-commercial use only. The [pro] models are closed weights, made available exclusively through their API or partnerships with other API providers.
I tried the new 1.1 model out using black-forest-labs/flux-1.1-pro on Replicate just now. Here's my prompt:
Photograph of a Faberge egg representing the California coast. It should be decorated with ornate pelicans and sea lions and a humpback whale.

The FLUX models have a reputation for being really good at following complex prompts. In this case I wanted the sea lions to appear in the egg design rather than looking at the egg from the beach, but I imagine I could get better results if I continued to iterate on my prompt.
The FLUX models are also better at applying text than any other image models I've tried myself.
2023
Accessing Llama 2 from the command-line with the llm-replicate plugin
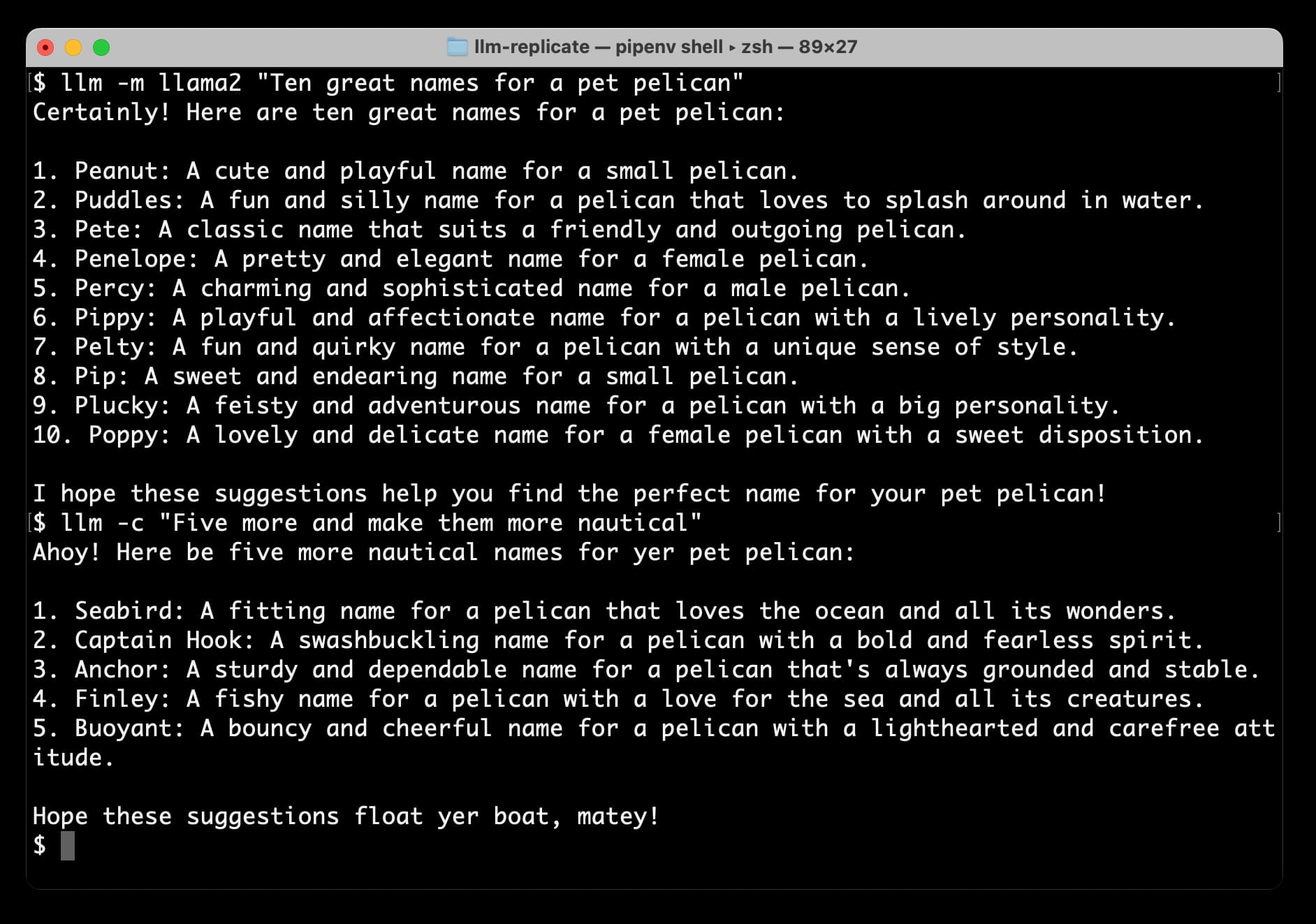
The big news today is Llama 2, the new openly licensed Large Language Model from Meta AI. It’s a really big deal:
[... 1,206 words]How I Used Stable Diffusion and Dreambooth to Create A Painted Portrait of My Dog (via) I like posts like this that go into detail in terms of how much work it takes to deliberately get the kind of result you really want using generative AI tools. Jake Dahn trained a Dreambooth model from 40 photos of Queso—his photogenic Golden Retriever—using Replicate, then gathered the prompts from ten images he liked on Lexica and generated over 1,000 different candidate images, picked his favourite, used Draw Things img2img resizing to expand the image beyond the initial crop, then Automatic1111 inpainting to tweak the ears, then Real-ESRGAN 4x+ to upscale for the final print.
Fine-tune LLaMA to speak like Homer Simpson. Replicate spent 90 minutes fine-tuning LLaMA on 60,000 lines of dialog from the first 12 seasons of the Simpsons, and now it can do a good job of producing invented dialog from any of the characters from the series. This is a really interesting result: I’ve been skeptical about how much value can be had from fine-tuning large models on just a tiny amount of new data, assuming that the new data would be statistically irrelevant compared to the existing model. Clearly my mental model around this was incorrect.
Train and run Stanford Alpaca on your own machine. The team at Replicate managed to train their own copy of Stanford’s Alpaca—a fine-tuned version of LLaMA that can follow instructions like ChatGPT. Here they provide step-by-step instructions for recreating Alpaca yourself—running the training needs one or more A100s for a few hours, which you can rent through various cloud providers.
2022
A tool to run caption extraction against online videos using Whisper and GitHub Issues/Actions
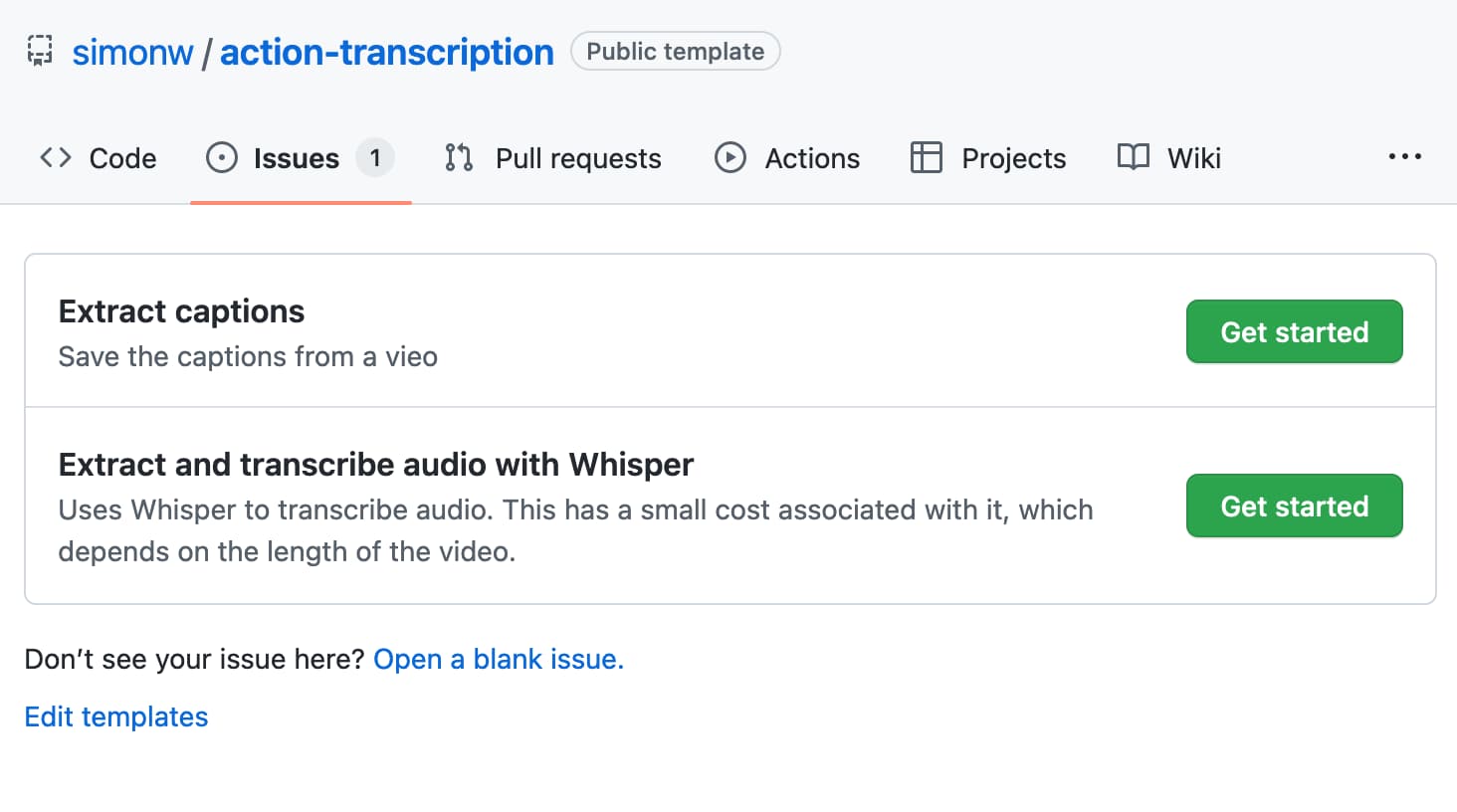
I released a new project this weekend, built during the Bellingcat Hackathon (I came second!) It’s called Action Transcription and it’s a tool for caturing captions and transcripts from online videos.
[... 1,362 words]