113 posts tagged “sql”
2024
DuckDB as the New jq (via) The DuckDB CLI tool can query JSON files directly, making it a surprisingly effective replacement for jq. Paul Gross demonstrates the following query:
select license->>'key' as license, count(*) from 'repos.json' group by 1
repos.json contains an array of {"license": {"key": "apache-2.0"}..} objects. This example query shows counts for each of those licenses.
Endatabas (via) Endatabas is “an open source immutable database”—also described as “SQL document database with full history”.
It uses a variant of SQL which allows you to insert data into tables that don’t exist yet (they’ll be created automatically) then run standard select queries, joins etc. It maintains a full history of every record and supports the recent SQL standard “FOR SYSTEM_TIME AS OF” clause for retrieving historical records as they existed at a specified time (it defaults to the most recent versions).
It’s written in Common Lisp plus a bit of Rust, and includes Docker images for running the server and client libraries in JavaScript and Python. The on-disk storage format is Apache Arrow, the license is AGPL and it’s been under development for just over a year.
It’s also a document database: you can insert JSON-style nested objects directly into a table, and query them with path expressions like “select users.friends[1] from users where id = 123;”
They have a WebAssembly version and a nice getting started tutorial which you can try out directly in your browser.
Their “Why?” page lists full history, time travel queries, separation of storage from compute, schemaless tables and columnar storage as the five pillars that make up their product. I think it’s a really interesting amalgamation of ideas.
Announcing DuckDB 0.10.0.
Somewhat buried in this announcement: DuckDB has Fixed-Length Arrays now, along with array_cross_product(a1, a2), array_cosine_similarity(a1, a2) and array_inner_product(a1, a2) functions.
This means you can now use DuckDB to find related content (and other tricks) using vector embeddings!
Also notable:
DuckDB can now attach MySQL, Postgres, and SQLite databases in addition to databases stored in its own format. This allows data to be read into DuckDB and moved between these systems in a convenient manner, as attached databases are fully functional, appear just as regular tables, and can be updated in a safe, transactional manner.
SQL for Data Scientists in 100 Queries. New comprehensive SQLite SQL tutorial from Greg Wilson, author of Teaching Tech Together and founder of The Carpentries.
GPT in 500 lines of SQL (via) Utterly brilliant piece of PostgreSQL hackery by Alex Bolenok, who implements a full GPT-2 style language model in SQL on top of pg_vector. The final inference query is 498 lines long!
2023
Making PostgreSQL tick: New features in pg_cron (via) pg_cron adds cron-style scheduling directly to PostgreSQL. It's a pretty mature extension at this point, and recently gained the ability to schedule repeating tasks at intervals as low as every 1s.
The examples in this post are really informative. I like this example, which cleans up the ever-growing cron.job_run_details table by using pg_cron itself to run the cleanup:
SELECT cron.schedule('delete-job-run-details', '0 12 * * *', $$DELETE FROM cron.job_run_details WHERE end_time < now() - interval '3 days'$$);
pg_cron can be used to schedule functions written in PL/pgSQL, which is a great example of the kind of DSL that I used to avoid but I'm now much happier to work with because I know GPT-4 can write basic examples for me and help me understand exactly what unfamiliar code is doing.
Upsert in SQL (via) Anton Zhiyanov is currently on a one-man quest to write detailed documentation for all of the fundamental SQL operations, comparing and contrasting how they work across multiple engines, generally with interactive examples.
Useful tips in here on why “insert... on conflict” is usually a better option than “insert or replace into” because the latter can perform a delete and then an insert, firing triggers that you may not have wanted to be fired.
Online gradient descent written in SQL (via) Max Halford trains an online gradient descent model against two years of AAPL stock data using just a single advanced SQL query. He built this against DuckDB—I tried to replicate his query in SQLite and it almost worked, but it gave me a “recursive reference in a subquery” error that I was unable to resolve.
2022
konstantint/SKompiler (via) A tool for compiling trained SKLearn models into other representations —including SQL queries and Excel formulas. I’ve been pondering the most light-weight way to package a simple machine learning model as part of a larger application without needing to bundle heavy dependencies, this set of techniques looks ideal!
[SQLite is] a database that in full-stack culture has been relegated to "unit test database mock" for about 15 years that is (1) surprisingly capable as a SQL engine, (2) the simplest SQL database to get your head around and manage, and (3) can embed directly in literally every application stack, which is especially interesting in latency-sensitive and globally-distributed applications.
Reason (3) is clearly our ulterior motive here, so we're not disinterested: our model user deploys a full-stack app (Rails, Elixir, Express, whatever) in a bunch of regions around the world, hoping for sub-100ms responses for users in most places around the world. Even within a single data center, repeated queries to SQL servers can blow that budget. Running an in-process SQL server neatly addresses it.
Efficient Pagination Using Deferred Joins (via) Surprisingly simple trick for speeding up deep OFFSET x LIMIT y pagination queries, which get progressively slower as you paginate deeper into the data. Instead of applying them directly, apply them to a “select id from ...” query to fetch just the IDs, then either use a join or run a separate “select * from table where id in (...)” query to fetch the full records for that page.
The Checkered Flag Diagram for visualizing SQL joins. I really like this alternative to Venn diagrams for showing the difference between different types of SQL join (left join, right join, cross join etc).
Joining CSV files in your browser using Datasette Lite
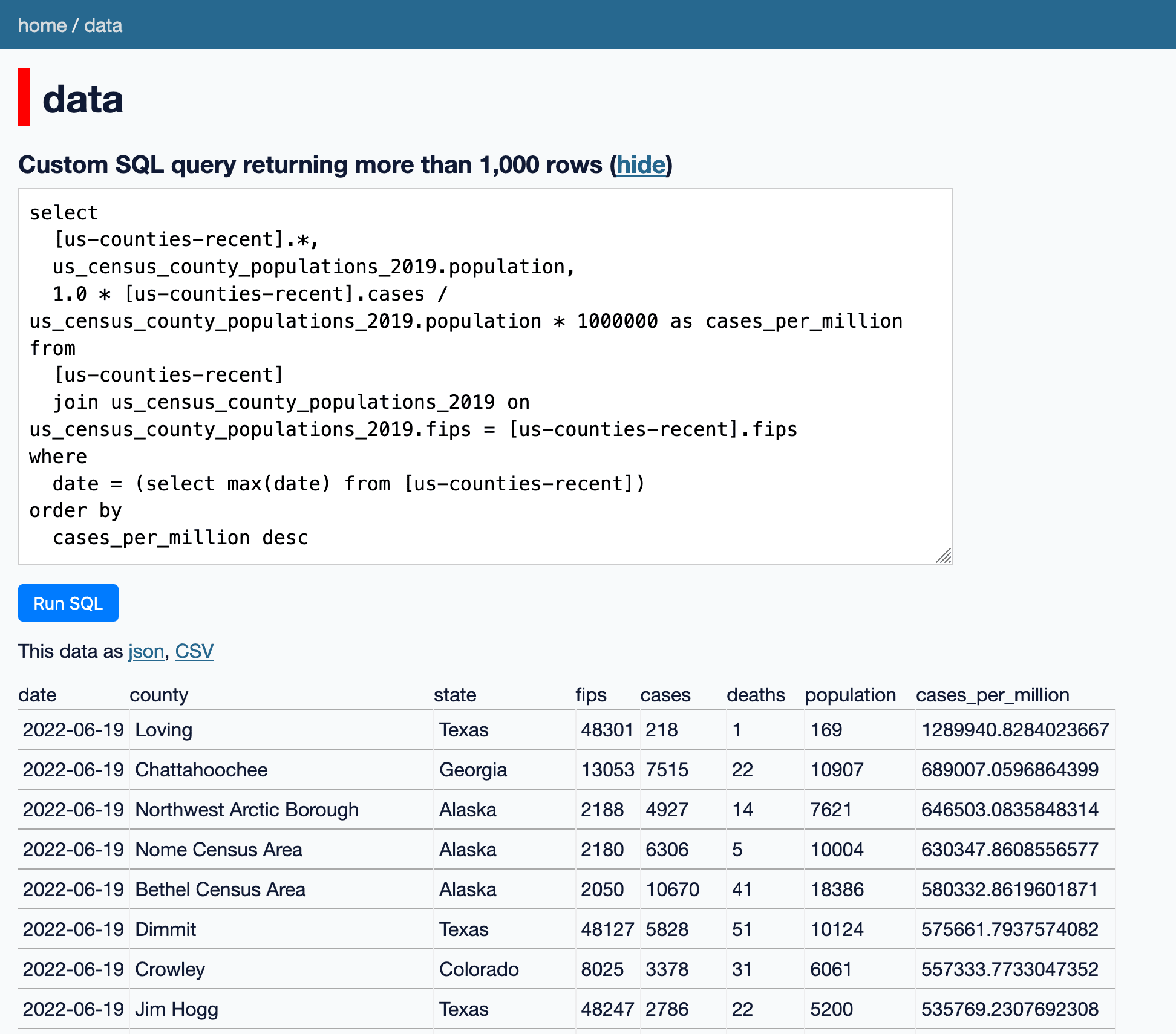
I added a new feature to Datasette Lite—my version of Datasette that runs entirely in your browser using WebAssembly (previously): you can now use it to load one or more CSV files by URL, and then run SQL queries against them—including joins across data from multiple files.
[... 546 words]How Materialize and other databases optimize SQL subqueries. Jamie Brandon offers a survey of the state-of-the-art in optimizing correlated subqueries, across a number of different database engines.
2021
SQLModel. A new project by FastAPI creator Sebastián Ramírez: SQLModel builds on top of both SQLAlchemy and Sebastián’s Pydantic validation library to provide a new ORM that’s designed around Python 3’s optional typing. The real brilliance here is that a SQLModel subclass is simultaneously a valid SQLAlchemy ORM model AND a valid Pydantic validation model, saving on duplicate code by allowing the same class to be used both for form/API validation and for interacting with the database.
Datasette on Codespaces, sqlite-utils API reference documentation and other weeknotes
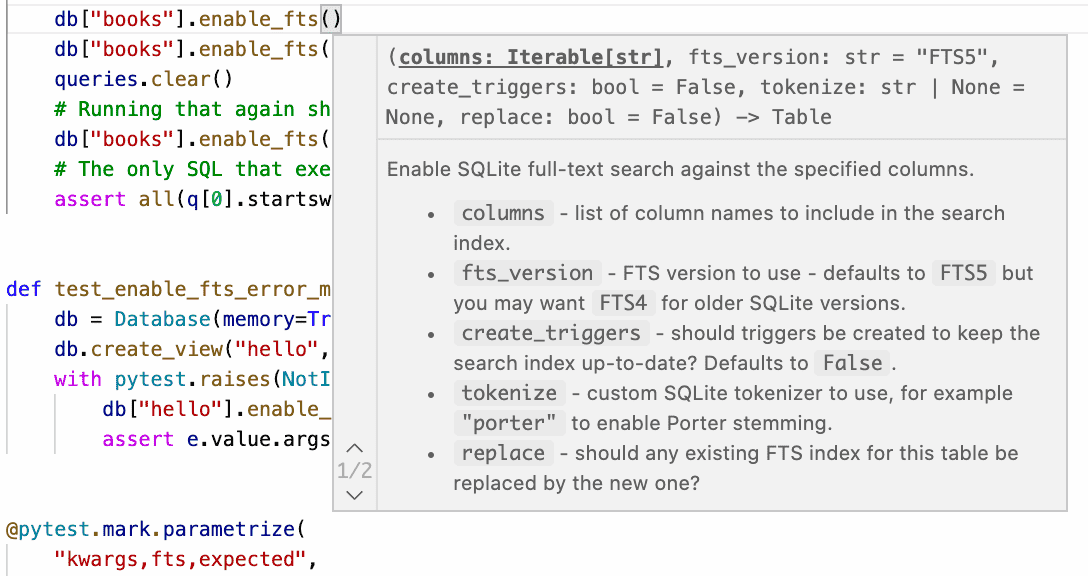
This week I broke my streak of not sending out the Datasette newsletter, figured out how to use Sphinx for Python class documentation, worked out how to run Datasette on GitHub Codespaces, implemented Datasette column metadata and got tantalizingly close to a solution for an elusive Datasette feature.
[... 2,164 words]Bare columns in an aggregate queries. This is a really nice SQL tweak implemented in SQLite: If you run a query like “SELECT a, b, max(c) FROM tab1 GROUP BY a” SQLite will find the row with the highest value for c and use the columns of that row as the returned values for the other columns mentioned in the query.
Django SQL Dashboard 1.0
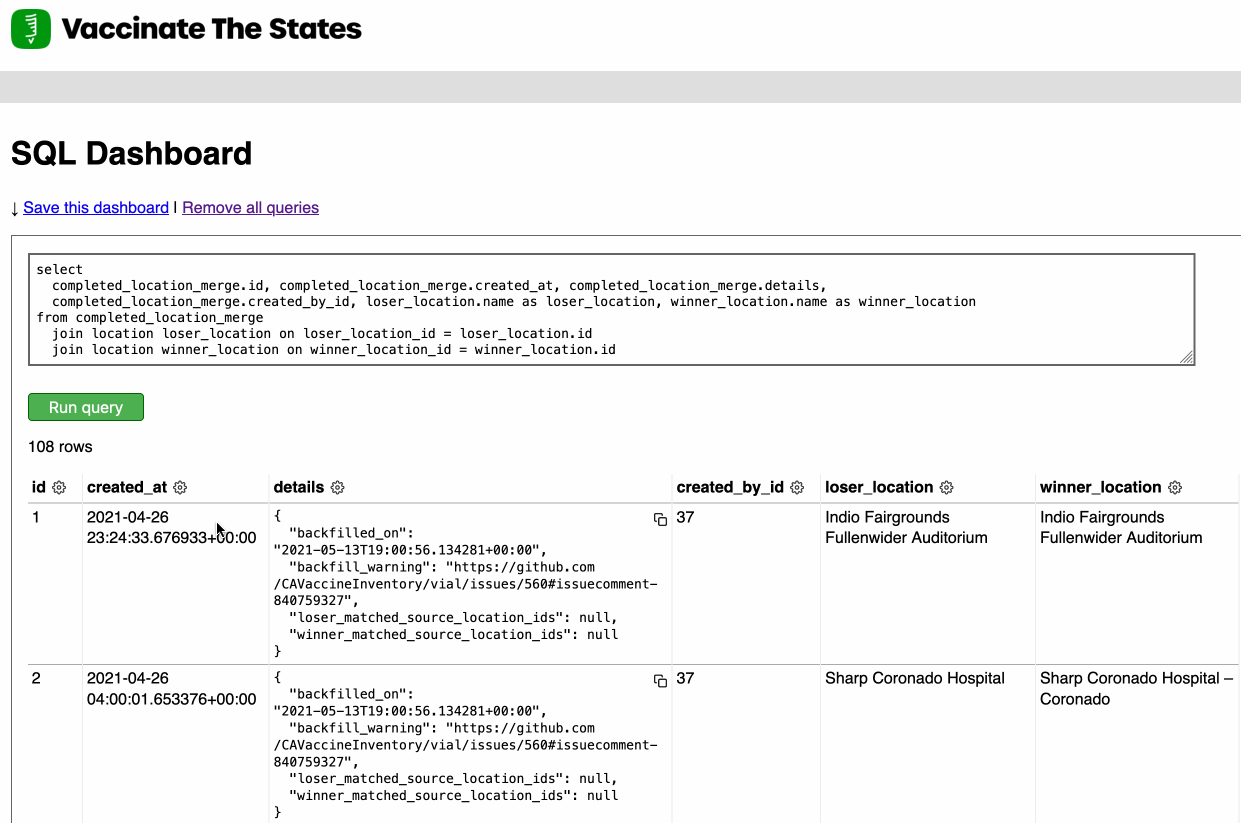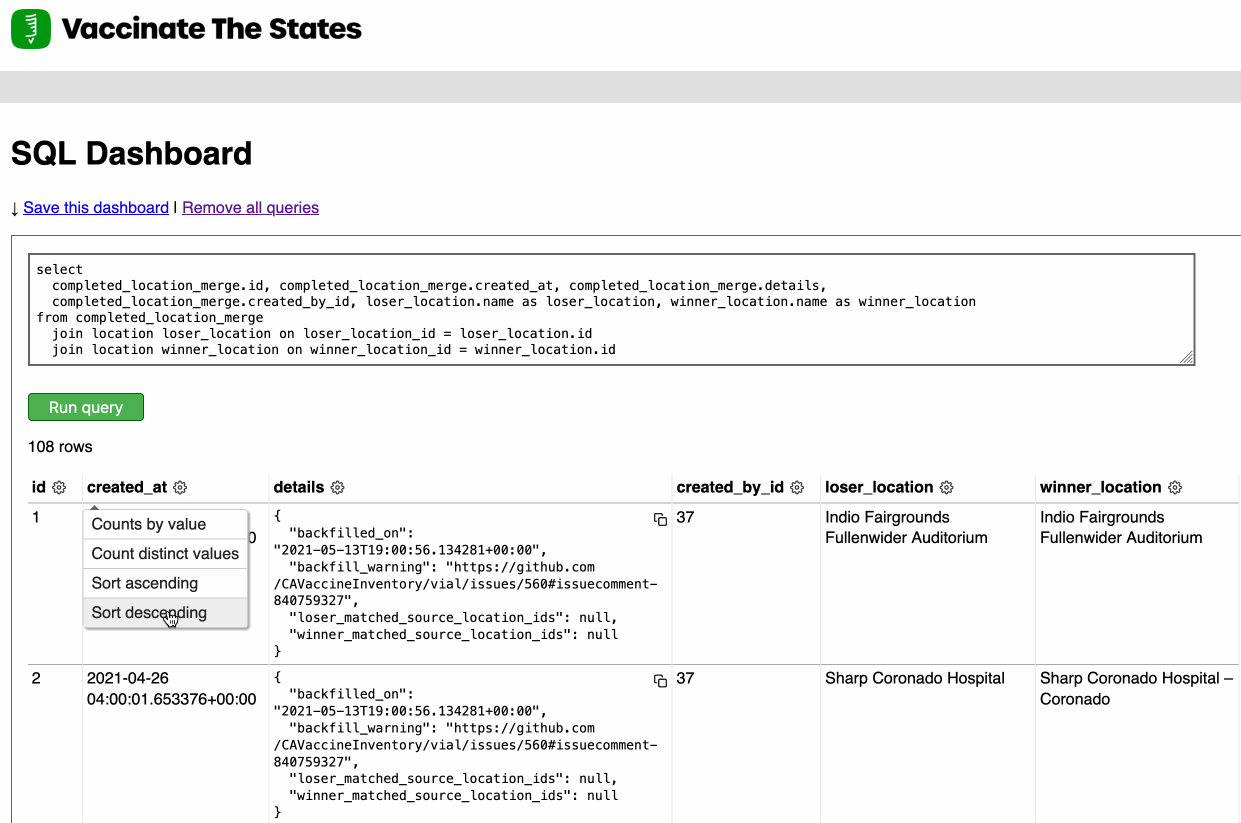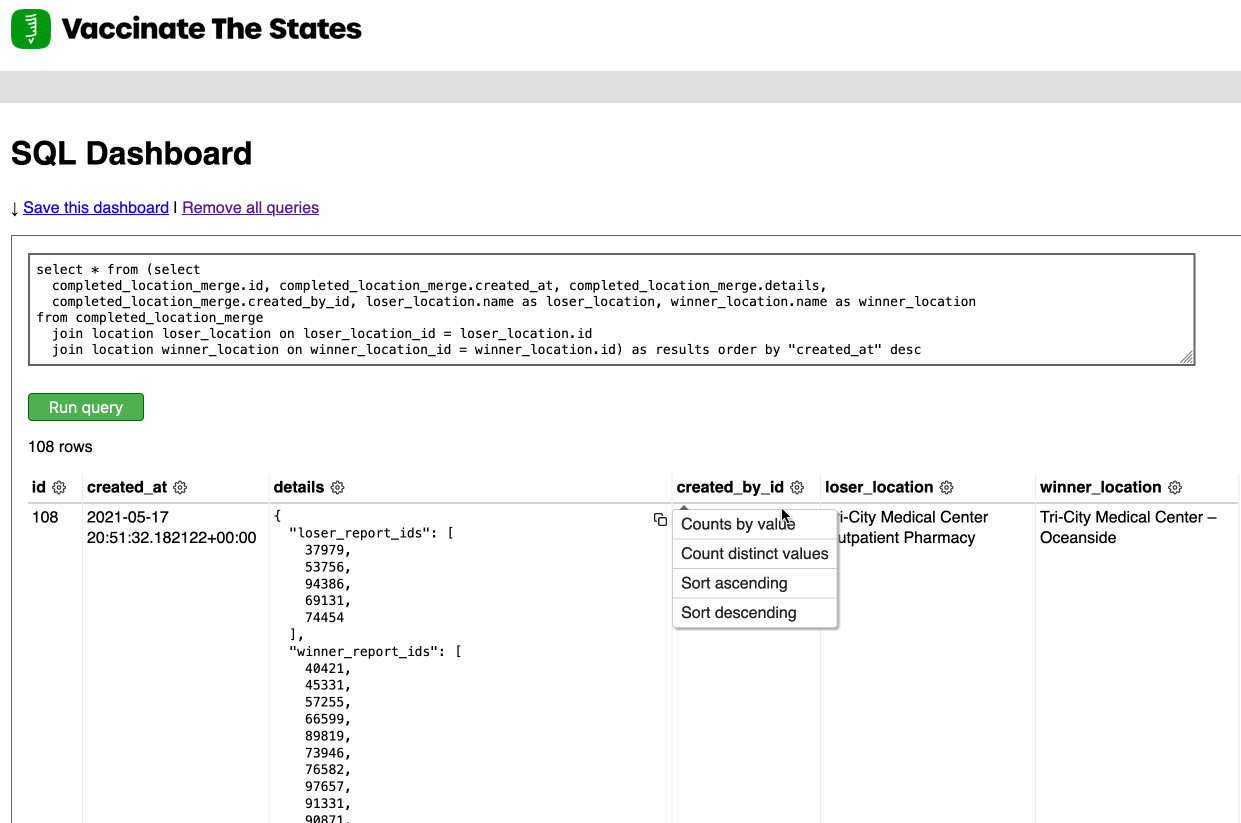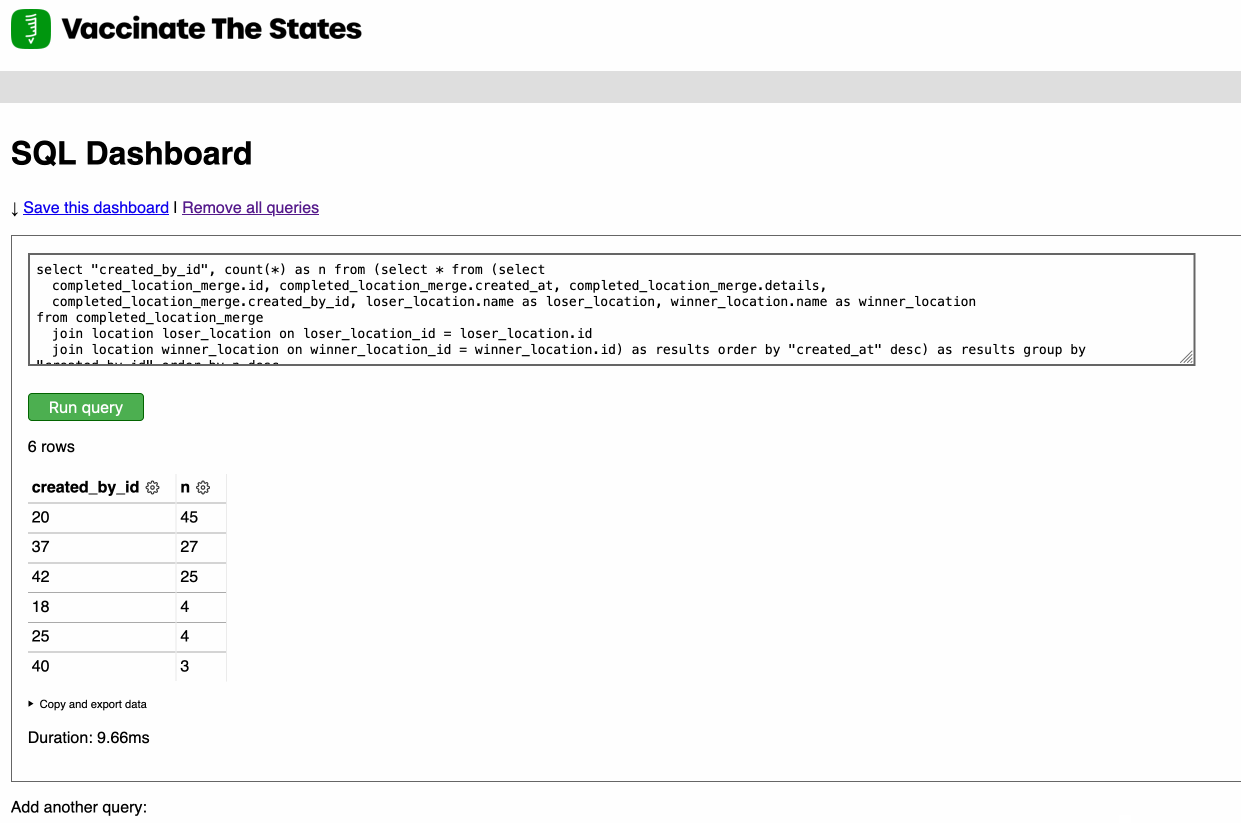
Earlier this week I released Django SQL Dashboard 1.0. I also just released 1.0.1, with a bug fix for PostgreSQL 10 contributed by Ryan Cheley.
[... 629 words]Django SQL Dashboard 1.0 (via) As part of my ongoing attempt to be braver about 1.0 releases (crucial if you want to do semantic versioning properly) I’ve released version 1.0 of Django SQL Dashboard, my Datasette-inspired app for Django that adds an interface for running read-only, bookmarkable SQL queries against a PostgreSQL database. The new version adds a column cog menu providing shortcuts for changing the sort order, counting distinct values and performing a group-by/count against column values.
Hierarchical Structures in PostgreSQL (via) Two techniques I hadn’t seen before: the first is to define a materialized view using a CTE that offers efficient tree queries against a PostgreSQL array of path components (plus a trigger to update the materialized view), the second is with the PostgreSQL ltree extension which ships as part of PostgreSQL and hence should be widely available.
Joining CSV and JSON data with an in-memory SQLite database
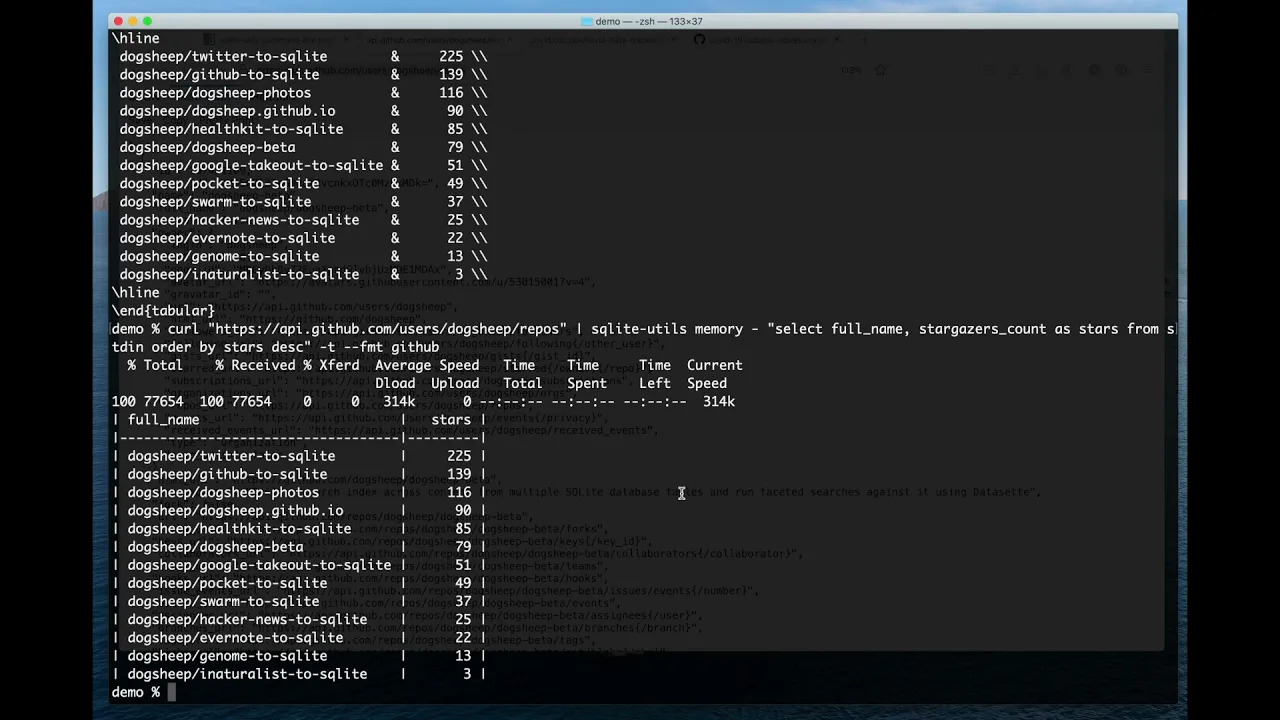
The new sqlite-utils memory command can import CSV and JSON data directly into an in-memory SQLite database, combine and query it using SQL and output the results as CSV, JSON or various other formats of plain text tables.
The humble hash aggregate (via) Today I learned that “hash aggregate” is the name for the algorithm where you split a list of tuples on a common key, run an aggregation against each resulting group and combine the results back together again—I’d previously thought if this in terms of map/reduce but hash aggregate is a much older term used widely by SQL engines—I’ve seen it come up in PostgreSQL explain query output (for GROUP BY) before but didn’t know what it meant.
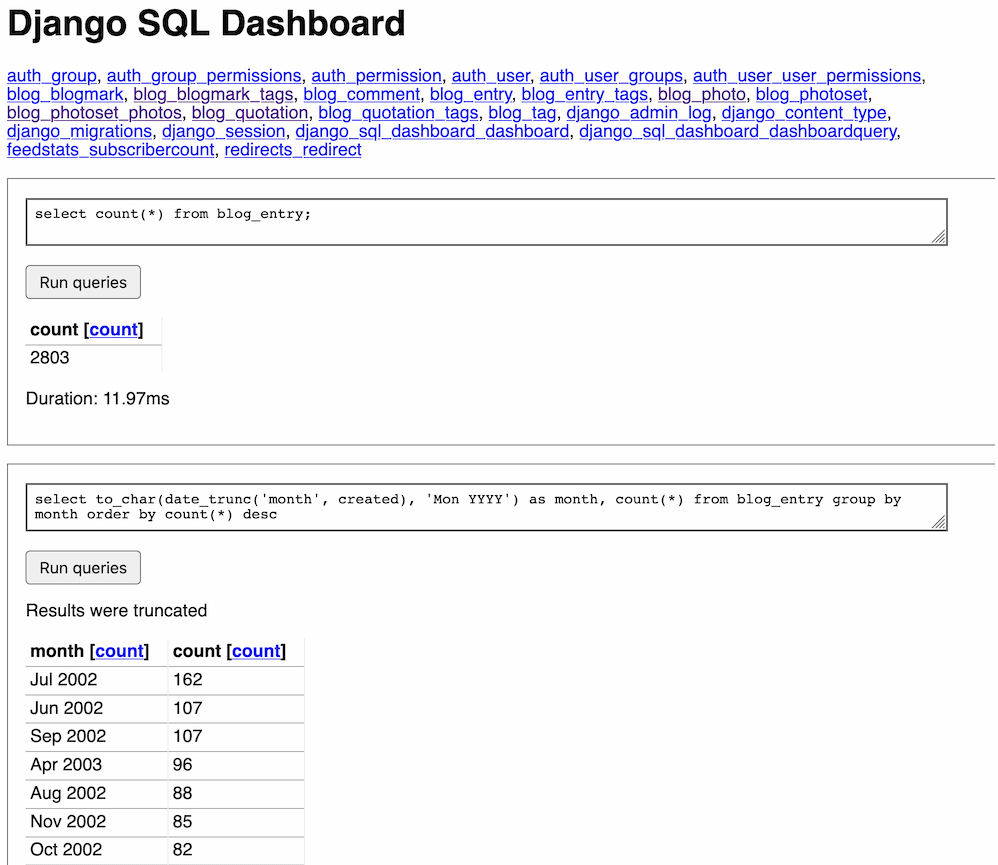
Django SQL Dashboard
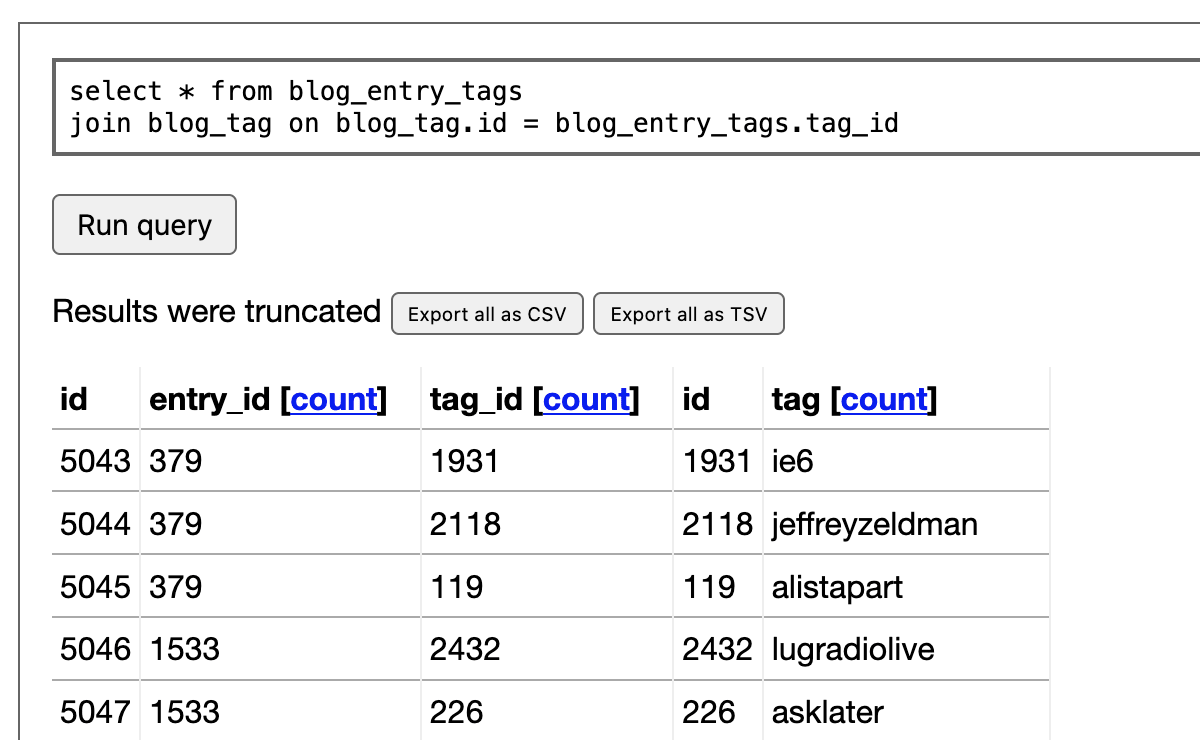
I’ve released the first non-alpha version of Django SQL Dashboard, which provides an interface for running arbitrary read-only SQL queries directly against a PostgreSQL database, protected by the Django authentication scheme. It can also be used to create saved dashboards that can be published or shared internally.
[... 2,171 words]Practical SQL for Data Analysis
(via)
This is a really great SQL tutorial: it starts with the basics, but quickly moves on to a whole array of advanced PostgreSQL techniques - CTEs, window functions, efficient sampling, rollups, pivot tables and even linear regressions executed directly in the database using regr_slope(), regr_intercept() and regr_r2(). I picked up a whole bunch of tips for things I didn't know you could do with PostgreSQL here.
Weeknotes: tableau-to-sqlite, django-sql-dashboard
This week I started a limited production run of my new backend for Vaccinate CA calling, built a tableau-to-sqlite import tool and started working on a subset of Datasette for PostgreSQL and Django called django-sql-dashboard.
Everything You Always Wanted To Know About GitHub (But Were Afraid To Ask) (via) ClickHouse by Yandex is an open source column-oriented data warehouse, designed to run analytical queries against TBs of data. They've loaded the full GitHub Archive of events since 2011 into a public instance, which is a great way of both exploring GitHub activity and trying out ClickHouse. Here's a query I just ran that shows number of watch events per year, for example:
SELECT toYear(created_at) as yyyy, count()
FROM github_events
WHERE event_type = 'WatchEvent' group by yyyy
2020
Some SQL Tricks of an Application DBA (via) This post taught me so many PostgreSQL tricks that I hadn’t seen before. Did you know you can start a transaction, drop an index, run explain and then rollback the transaction (cancelling the index drop) to see what explain would look like without that index? Among other things I also learned what the “correlation” database statistic does: it’s a measure of how close-to-sorted the values in a specific column are, which helps PostgreSQL decide if it should do an index scan or a bitmap scan when making use of an index.
How much can you learn from just two columns?
Derek Willis shared an intriguing dataset this morning: a table showing every Twitter account followed by an official GOP congressional Twitter account.
[... 951 words]Get Started—Materialize. Materialize is a really interesting new database—“a streaming SQL materialized view engine”. It builds materialized views on top of streaming data sources (such as Kafka)—you define the view using a SQL query, then it figures out how to keep that view up-to-date automatically as new data streams in. It speaks the PostgreSQL protocol so you can talk to it using the psql tool or any PostgreSQL client library. The “get started” guide is particularly impressive: it uses a curl stream of the Wikipedia recent changes API, parsed using a regular expression. And it’s written in Rust, so installing it is as easy as downloading and executing a single binary (though I used Homebrew).
Using SQL to Look Through All of Your iMessage Text Messages (via) Dan Kelch shows how to access the iMessage SQLite database at ~/Library/Messages/chat.db—it’s protected under macOS Catalina so you have to enable Full Disk Access in the privacy settings first. I usually use the macOS terminal app but I installed iTerm for this because I’d rather enable full disk access to a separate terminal program than let anything I’m running in my regular terminal take advantage of it. It worked! Now I can run “datasette ~/Library/Messages/chat.db” to browse my messages.