9 posts tagged “transformers”
2026
ggml.ai joins Hugging Face to ensure the long-term progress of Local AI (via) I don't normally cover acquisition news like this, but I have some thoughts.
It's hard to overstate the impact Georgi Gerganov has had on the local model space. Back in March 2023 his release of llama.cpp made it possible to run a local LLM on consumer hardware. The original README said:
The main goal is to run the model using 4-bit quantization on a MacBook. [...] This was hacked in an evening - I have no idea if it works correctly.
I wrote about trying llama.cpp out at the time in Large language models are having their Stable Diffusion moment:
I used it to run the 7B LLaMA model on my laptop last night, and then this morning upgraded to the 13B model—the one that Facebook claim is competitive with GPT-3.
Meta's original LLaMA release depended on PyTorch and their FairScale PyTorch extension for running on multiple GPUs, and required CUDA and NVIDIA hardware. Georgi's work opened that up to a much wider range of hardware and kicked off the local model movement that has continued to grow since then.
Hugging Face are already responsible for the incredibly influential Transformers library used by the majority of LLM releases today. They've proven themselves a good steward for that open source project, which makes me optimistic for the future of llama.cpp and related projects.
This section from the announcement looks particularly promising:
Going forward, our joint efforts will be geared towards the following objectives:
- Towards seamless "single-click" integration with the transformers library. The
transformersframework has established itself as the 'source of truth' for AI model definitions. Improving the compatibility between the transformers and the ggml ecosystems is essential for wider model support and quality control.- Better packaging and user experience of ggml-based software. As we enter the phase in which local inference becomes a meaningful and competitive alternative to cloud inference, it is crucial to improve and simplify the way in which casual users deploy and access local models. We will work towards making llama.cpp ubiquitous and readily available everywhere, and continue partnering with great downstream projects.
Given the influence of Transformers, this closer integration could lead to model releases that are compatible with the GGML ecosystem out of the box. That would be a big win for the local model ecosystem.
I'm also excited to see investment in "packaging and user experience of ggml-based software". This has mostly been left to tools like Ollama and LM Studio. ggml-org released LlamaBarn last year - "a macOS menu bar app for running local LLMs" - and I'm hopeful that further investment in this area will result in more high quality open source tools for running local models from the team best placed to deliver them.
2025
r1.py script to run R1 with a min-thinking-tokens parameter
(via)
Fantastically creative hack by Theia Vogel. The DeepSeek R1 family of models output their chain of thought inside a <think>...</think> block. Theia found that you can intercept that closing </think> and replace it with "Wait, but" or "So" or "Hmm" and trick the model into extending its thought process, producing better solutions!
You can stop doing this after a few iterations, or you can keep on denying the </think> string and effectively force the model to "think" forever.
Theia's code here works against Hugging Face transformers but I'm confident the same approach could be ported to llama.cpp or MLX.
2024
Finally, a replacement for BERT: Introducing ModernBERT (via) BERT was an early language model released by Google in October 2018. Unlike modern LLMs it wasn't designed for generating text. BERT was trained for masked token prediction and was generally applied to problems like Named Entity Recognition or Sentiment Analysis. BERT also wasn't very useful on its own - most applications required you to fine-tune a model on top of it.
In exploring BERT I decided to try out dslim/distilbert-NER, a popular Named Entity Recognition model fine-tuned on top of DistilBERT (a smaller distilled version of the original BERT model). Here are my notes on running that using uv run.
Jeremy Howard's Answer.AI research group, LightOn and friends supported the development of ModernBERT, a brand new BERT-style model that applies many enhancements from the past six years of advances in this space.
While BERT was trained on 3.3 billion tokens, producing 110 million and 340 million parameter models, ModernBERT trained on 2 trillion tokens, resulting in 140 million and 395 million parameter models. The parameter count hasn't increased much because it's designed to run on lower-end hardware. It has a 8192 token context length, a significant improvement on BERT's 512.
I was able to run one of the demos from the announcement post using uv run like this (I'm not sure why I had to use numpy<2.0 but without that I got an error about cannot import name 'ComplexWarning' from 'numpy.core.numeric'):
uv run --with 'numpy<2.0' --with torch --with 'git+https://github.com/huggingface/transformers.git' pythonThen this Python:
import torch from transformers import pipeline from pprint import pprint pipe = pipeline( "fill-mask", model="answerdotai/ModernBERT-base", torch_dtype=torch.bfloat16, ) input_text = "He walked to the [MASK]." results = pipe(input_text) pprint(results)
Which downloaded 573MB to ~/.cache/huggingface/hub/models--answerdotai--ModernBERT-base and output:
[{'score': 0.11669921875,
'sequence': 'He walked to the door.',
'token': 3369,
'token_str': ' door'},
{'score': 0.037841796875,
'sequence': 'He walked to the office.',
'token': 3906,
'token_str': ' office'},
{'score': 0.0277099609375,
'sequence': 'He walked to the library.',
'token': 6335,
'token_str': ' library'},
{'score': 0.0216064453125,
'sequence': 'He walked to the gate.',
'token': 7394,
'token_str': ' gate'},
{'score': 0.020263671875,
'sequence': 'He walked to the window.',
'token': 3497,
'token_str': ' window'}]
I'm looking forward to trying out models that use ModernBERT as their base. The model release is accompanied by a paper (Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference) and new documentation for using it with the Transformers library.
SQL injection-like attack on LLMs with special tokens. Andrej Karpathy explains something that's been confusing me for the best part of a year:
The decision by LLM tokenizers to parse special tokens in the input string (
<s>,<|endoftext|>, etc.), while convenient looking, leads to footguns at best and LLM security vulnerabilities at worst, equivalent to SQL injection attacks.
LLMs frequently expect you to feed them text that is templated like this:
<|user|>\nCan you introduce yourself<|end|>\n<|assistant|>
But what happens if the text you are processing includes one of those weird sequences of characters, like <|assistant|>? Stuff can definitely break in very unexpected ways.
LLMs generally reserve special token integer identifiers for these, which means that it should be possible to avoid this scenario by encoding the special token as that ID (for example 32001 for <|assistant|> in the Phi-3-mini-4k-instruct vocabulary) while that same sequence of characters in untrusted text is encoded as a longer sequence of smaller tokens.
Many implementations fail to do this! Thanks to Andrej I've learned that modern releases of Hugging Face transformers have a split_special_tokens=True parameter (added in 4.32.0 in August 2023) that can handle it. Here's an example:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
>>> tokenizer.encode("<|assistant|>")
[32001]
>>> tokenizer.encode("<|assistant|>", split_special_tokens=True)
[529, 29989, 465, 22137, 29989, 29958]A better option is to use the apply_chat_template() method, which should correctly handle this for you (though I'd like to see confirmation of that).
llm-sentence-transformers 0.2. I added a new --trust-remote-code option when registering an embedding model, which means LLM can now run embeddings through the new Nomic AI nomic-embed-text-v1 model.
The Random Transformer (via) “Understand how transformers work by demystifying all the math behind them”—Omar Sanseviero from Hugging Face meticulously implements the transformer architecture behind LLMs from scratch using Python and numpy. There’s a lot to take in here but it’s all very clearly explained.
2023
Seamless Communication (via) A new “family of AI research models” from Meta AI for speech and text translation. The live demo is particularly worth trying—you can record a short webcam video of yourself speaking and get back the same video with your speech translated into another language.
The key to it is the new SeamlessM4T v2 model, which supports 101 languages for speech input, 96 Languages for text input/output and 35 languages for speech output. SeamlessM4T-Large v2 is a 9GB file, available on Hugging Face.
Also in this release: SeamlessExpressive, which “captures certain underexplored aspects of prosody such as speech rate and pauses”—effectively maintaining things like expressed enthusiasm across languages.
Plus SeamlessStreaming, “a model that can deliver speech and text translations with around two seconds of latency”.
Observable notebook: Detect objects in images (via) I built an Observable notebook that uses Transformers.js and the Xenova/detra-resnet-50 model to detect objects in images, entirely running within your browser. You can select an image using a file picker and it will show you that image with bounding boxes and labels drawn around items within it. I have a demo image showing some pelicans flying ahead, but it works with any image you give it - all without uploading that image to a server.
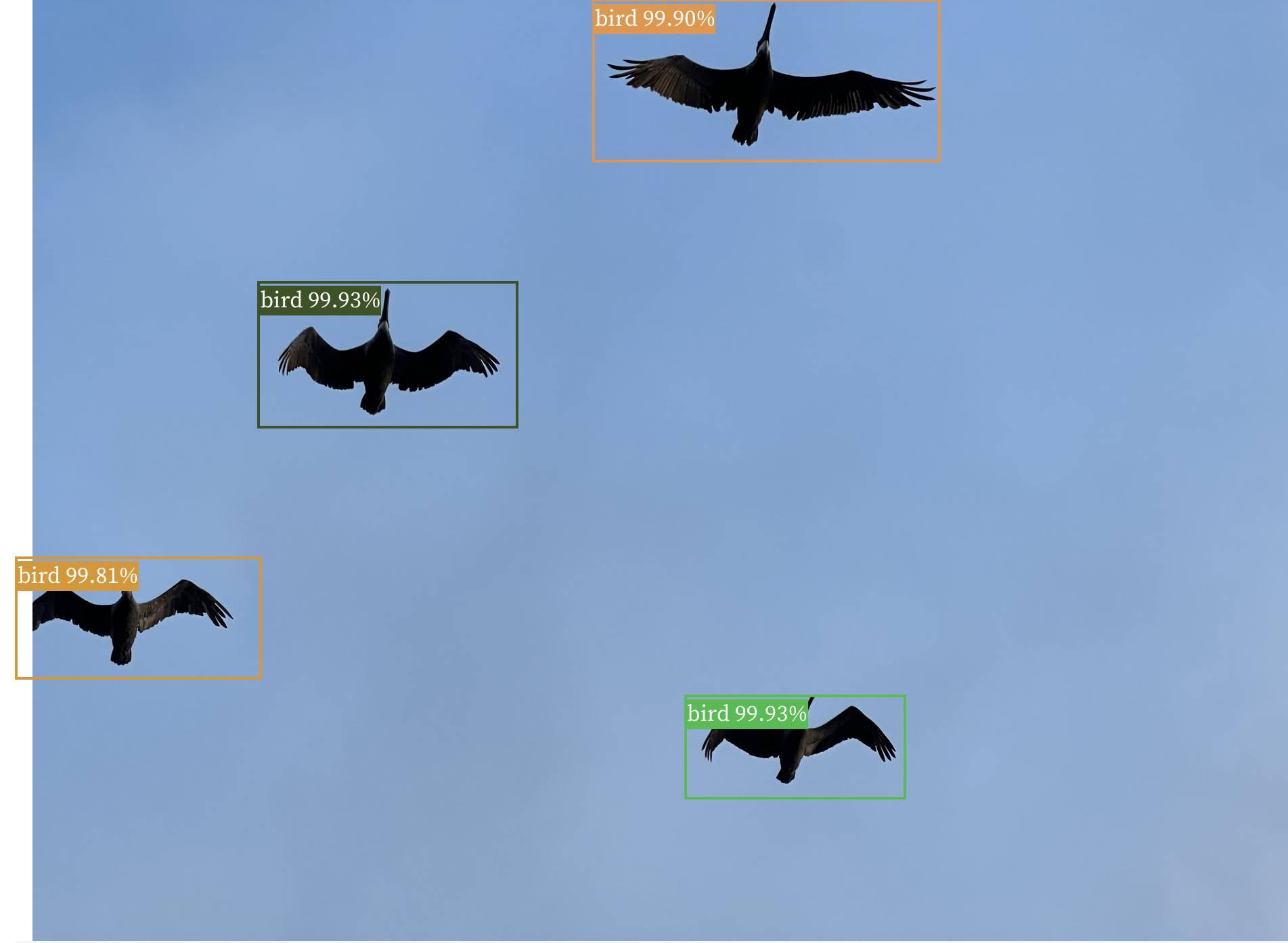
Transformers.js. Hugging Face Transformers is a library of Transformer machine learning models plus a Python package for loading and running them. Transformers.js provides a JavaScript alternative interface which runs in your browser, thanks to a set of precompiled WebAssembly binaries for a selection of models. This interactive demo is incredible: in particular, try running the Image classification with google/vit-base-patch16-224 (91MB) model against any photo to get back labels representing that photo. Dropping one of these models onto a page is as easy as linking to a hosted CDN script and running a few lines of JavaScript.