July 2023
73 posts: 4 entries, 20 links, 7 quotes, 42 beats
July 1, 2023
Once you've found something you're excessively interested in, the next step is to learn enough about it to get you to one of the frontiers of knowledge. Knowledge expands fractally, and from a distance its edges look smooth, but once you learn enough to get close to one, they turn out to be full of gaps.
July 2, 2023
Data analysis with SQLite and Python. I turned my 2hr45m workshop from PyCon into the latest official tutorial on the Datasette website. It includes an extensive handout which should be useful independently of the video itself.
July 4, 2023
Stamina: tutorial (via) Stamina is Hynek’s new Python library that implements an opinionated wrapper on top of Tenacity, providing a decorator for easily implementing exponential backoff retries. This tutorial includes a concise, clear explanation as to why this is such an important concept in building distributed systems.
July 8, 2023

Tech debt metaphor maximalism (via) I’ve long been a fan of the metaphor of technical debt, because it implies that taking on some debt is OK provided you’re strategic about how much you take on and how quickly you pay it off. Avery Pennarun provides the definitive guide to thinking about technical debt, including an extremely worthwhile explanation of how financial debt works as well.
July 9, 2023
It feels pretty likely that prompting or chatting with AI agents is going to be a major way that we interact with computers into the future, and whereas there’s not a huge spread in the ability between people who are not super good at tapping on icons on their smartphones and people who are, when it comes to working with AI it seems like we’ll have a high dynamic range. Prompting opens the door for non-technical virtuosos in a way that we haven’t seen with modern computers, outside of maybe Excel.
July 10, 2023

Why We Replaced Firecracker with QEMU (via) Hocus are building a self-hosted alternative to cloud development environment tools like GitPod and Codespaces. They moved away from Firecracker because it’s optimized for short-running (AWS Lambda style) functions—which means it never releases allocated RAM or storage volume space back to the host machine unless the container is entirely restarted. It also lacks GPU support.

At The Guardian we had a pretty direct way to fix this [the problem of zombie feature flags]: experiments were associated with expiry dates, and if your team's experiments expired the build system simply wouldn't process your jobs without outside intervention. Seems harsh, but I've found with many orgs the only way to fix negative externalities in a shared codebase is a tool that says "you broke your promises, now we break your builds".
Lima VM—Linux Virtual Machines On macOS (via) This looks really useful: “brew install lima” to install, then “limactl start default” to start an Ubuntu VM running and “lima” to get a shell. Julia Evans wrote about the tool this morning, and here Adam Gordon Bell includes details on adding a writable directory (by default lima mounts your macOS home directory in read-only mode).
Latent Space: Code Interpreter == GPT 4.5 (via) I presented as part of this Latent Space episode over the weekend, talking about the newly released ChatGPT Code Interpreter mode with swyx, Alex Volkov, Daniel Wilson and more. swyx did a great job editing our Twitter Spaces conversation into a podcast and writing up a detailed executive summary, posted here along with the transcript. If you’re curious you can listen to the first 15 minutes to get a great high-level explanation of Code Interpreter, or stick around for the full two hours for all of the details.
Apparently our live conversation had 17,000+ listeners!
July 12, 2023
My LLM CLI tool now supports self-hosted language models via plugins
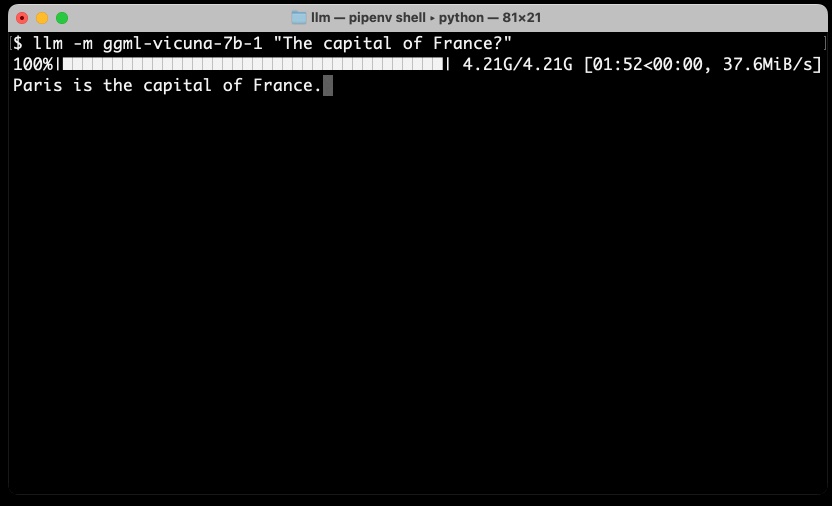
LLM is my command-line utility and Python library for working with large language models such as GPT-4. I just released version 0.5 with a huge new feature: you can now install plugins that add support for additional models to the tool, including models that can run on your own hardware.
[... 1,656 words]claude.ai. Anthropic’s new Claude 2 model is available to use online, and it has a 100k token context window and the ability to upload files to it—I tried uploading a text file with 34,000 tokens in it (according to my ttok CLI tool, counting using the GPT-3.5 tokenizer) and it gave me a workable summary.
What AI can do with a toolbox... Getting started with Code Interpreter. Ethan Mollick has been doing some very creative explorations of ChatGPT Code Interpreter over the past few months, and has tied a lot of them together into this useful introductory tutorial.
July 13, 2023
Not every conversation I had at Anthropic revolved around existential risk. But dread was a dominant theme. At times, I felt like a food writer who was assigned to cover a trendy new restaurant, only to discover that the kitchen staff wanted to talk about nothing but food poisoning.