Saturday, 30th March 2024
Running OCR against PDFs and images directly in your browser
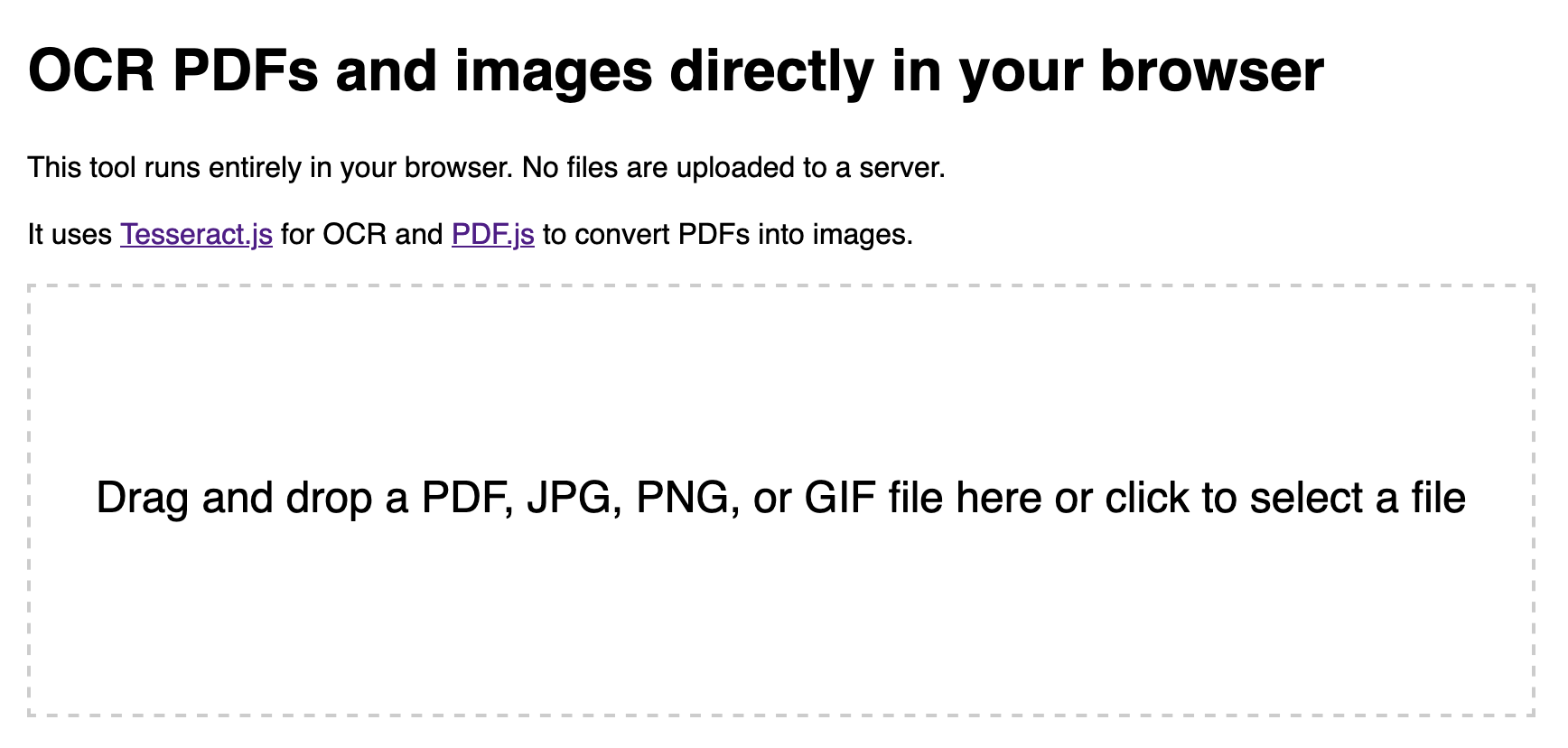
I attended the Story Discovery At Scale data journalism conference at Stanford this week. One of the perennial hot topics at any journalism conference concerns data extraction: how can we best get data out of PDFs and images?
[... 2,263 words]textract-cli. This is my other OCR project from yesterday: I built the thinnest possible CLI wrapper around Amazon Textract, out of frustration at how hard that tool is to use on an ad-hoc basis.
It only works with JPEGs and PNGs (not PDFs) up to 5MB in size, reflecting limitations in Textract’s synchronous API: it can handle PDFs amazingly well but you have to upload them to an S3 bucket yet and I decided to keep the scope tight for the first version of this tool.
Assuming you’ve configured AWS credentials already, this is all you need to know:
pipx install textract-cli
textract-cli image.jpeg > output.txt