April 2025
148 posts: 12 entries, 50 links, 26 quotes, 12 notes, 48 beats
April 7, 2025
Using Al effectively is now a fundamental expectation of everyone at Shopify. It's a tool of all trades today, and will only grow in importance. Frankly, I don't think it's feasible to opt out of learning the skill of applying Al in your craft; you are welcome to try, but I want to be honest I cannot see this working out today, and definitely not tomorrow. Stagnation is almost certain, and stagnation is slow-motion failure. If you're not climbing, you're sliding [...]
We will add Al usage questions to our performance and peer review questionnaire. Learning to use Al well is an unobvious skill. My sense is that a lot of people give up after writing a prompt and not getting the ideal thing back immediately. Learning to prompt and load context is important, and getting peers to provide feedback on how this is going will be valuable.
— Tobias Lütke, CEO of Shopify, self-leaked memo
If you're a startup running your own crawlers to gather data for whatever purpose, you should try really hard not to make the world a worse place by driving up costs for the sites you are scraping.
There's really no excuse for crawling Wikipedia ("65% of our most expensive traffic comes from bots") when they offer a comprehensive collection of bulk download options.
Do better!
My first games involved hand assembling machine code and turning graph paper characters into hex digits. Software progress has made that work as irrelevant as chariot wheel maintenance. [...]
AI tools will allow the best to reach even greater heights, while enabling smaller teams to accomplish more, and bring in some completely new creator demographics.
Yes, we will get to a world where you can get an interactive game (or novel, or movie) out of a prompt, but there will be far better exemplars of the medium still created by dedicated teams of passionate developers.
The world will be vastly wealthier in terms of the content available at any given cost.
Will there be more or less game developer jobs? That is an open question. It could go the way of farming, where labor saving technology allow a tiny fraction of the previous workforce to satisfy everyone, or it could be like social media, where creative entrepreneurship has flourished at many different scales. Regardless, “don’t use power tools because they take people’s jobs” is not a winning strategy.
April 8, 2025
llm-hacker-news. I built this new plugin to exercise the new register_fragment_loaders() plugin hook I added to LLM 0.24. It's the plugin equivalent of the Bash script I've been using to summarize Hacker News conversations for the past 18 months.
You can use it like this:
llm install llm-hacker-news
llm -f hn:43615912 'summary with illustrative direct quotes'
You can see the output in this issue.
The plugin registers a hn: prefix - combine that with the ID of a Hacker News conversation to pull that conversation into the context.
It uses the Algolia Hacker News API which returns JSON like this. Rather than feed the JSON directly to the LLM it instead converts it to a hopefully more LLM-friendly format that looks like this example from the plugin's test:
[1] BeakMaster: Fish Spotting Techniques
[1.1] CoastalFlyer: The dive technique works best when hunting in shallow waters.
[1.1.1] PouchBill: Agreed. Have you tried the hover method near the pier?
[1.1.2] WingSpan22: My bill gets too wet with that approach.
[1.1.2.1] CoastalFlyer: Try tilting at a 40° angle like our Australian cousins.
[1.2] BrownFeathers: Anyone spotted those "silver fish" near the rocks?
[1.2.1] GulfGlider: Yes! They're best caught at dawn.
Just remember: swoop > grab > lift
That format was suggested by Claude, which then wrote most of the plugin implementation for me. Here's that Claude transcript.
We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. [...]
In addition, we're also adding the HF version of Llama-4-Maverick to Arena, with leaderboard results published shortly. Meta’s interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference. As a result of that we are updating our leaderboard policies to reinforce our commitment to fair, reproducible evaluations so this confusion doesn’t occur in the future.
Imagine if Ford published a paper saying it was thinking about long term issues of the automobiles it made and one of those issues included “misalignment “Car as an adversary”” and when you asked Ford for clarification the company said “yes, we believe as we make our cars faster and more capable, they may sometimes take actions harmful to human well being” and you say “oh, wow, thanks Ford, but… what do you mean precisely?” and Ford says “well, we cannot rule out the possibility that the car might decide to just start running over crowds of people” and then Ford looks at you and says “this is a long-term research challenge”.
— Jack Clark, DeepMind gazes into the AGI future
Stop syncing everything. In which Carl Sverre announces Graft, a fascinating new open source Rust data synchronization engine he's been working on for the past year.
Carl's recent talk at the Vancouver Systems meetup explains Graft in detail, including this slide which helped everything click into place for me:

Graft manages a volume, which is a collection of pages (currently at a fixed 4KB size). A full history of that volume is maintained using snapshots. Clients can read and write from particular snapshot versions for particular pages, and are constantly updated on which of those pages have changed (while not needing to synchronize the actual changed data until they need it).
This is a great fit for B-tree databases like SQLite.
The Graft project includes a SQLite VFS extension that implements multi-leader read-write replication on top of a Graft volume. You can see a demo of that running at 36m15s in the video, or consult the libgraft extension documentation and try it yourself.
The section at the end on What can you build with Graft? has some very useful illustrative examples:
Offline-first apps: Note-taking, task management, or CRUD apps that operate partially offline. Graft takes care of syncing, allowing the application to forget the network even exists. When combined with a conflict handler, Graft can also enable multiplayer on top of arbitrary data.
Cross-platform data: Eliminate vendor lock-in and allow your users to seamlessly access their data across mobile platforms, devices, and the web. Graft is architected to be embedded anywhere
Stateless read replicas: Due to Graft's unique approach to replication, a database replica can be spun up with no local state, retrieve the latest snapshot metadata, and immediately start running queries. No need to download all the data and replay the log.
Replicate anything: Graft is just focused on consistent page replication. It doesn't care about what's inside those pages. So go crazy! Use Graft to sync AI models, Parquet or Lance files, Geospatial tilesets, or just photos of your cats. The sky's the limit with Graft.
Writing C for curl
(via)
Daniel Stenberg maintains curl - a library that deals with the most hostile of environments, parsing content from the open internet - as 180,000 lines of C89 code.
He enforces a strict 80 character line width for readability, zero compiler warnings, avoids "bad" functions like gets, sprintf, strcat, strtok and localtime (CI fails if it spots them, I found that script here) and curl has their own custom dynamic buffer and parsing functions.
They take particular care around error handling:
In curl we always check for errors and we bail out without leaking any memory if (when!) they happen.
I like their commitment to API/ABI robustness:
Every function and interface that is publicly accessible must never be changed in a way that risks breaking the API or ABI. For this reason and to make it easy to spot the functions that need this extra precautions, we have a strict rule: public functions are prefixed with “curl_” and no other functions use that prefix.
Mistral Small 3.1 on Ollama. Mistral Small 3.1 (previously) is now available through Ollama, providing an easy way to run this multi-modal (vision) model on a Mac (and other platforms, though I haven't tried those myself).
I had to upgrade Ollama to the most recent version to get it to work - prior to that I got a Error: unable to load model message. Upgrades can be accessed through the Ollama macOS system tray icon.
I fetched the 15GB model by running:
ollama pull mistral-small3.1
Then used llm-ollama to run prompts through it, including one to describe this image:
{kind=link}
llm install llm-ollama
llm -m mistral-small3.1 'describe this image' -a https://static.simonwillison.net/static/2025/Mpaboundrycdfw-1.png
Here's the output. It's good, though not quite as impressive as the description I got from the slightly larger Qwen2.5-VL-32B.
I also tried it on a scanned (private) PDF of hand-written text with very good results, though it did misread one of the hand-written numbers.
Political Email Extraction Leaderboard (via) Derek Willis collects "political fundraising emails from just about every committee" - 3,000-12,000 a month - and has created an LLM benchmark from 1,000 of them that he collected last November.
He explains the leaderboard in this blog post. The goal is to have an LLM correctly identify the the committee name from the disclaimer text included in the email.
Here's the code he uses to run prompts using Ollama. It uses this system prompt:
Produce a JSON object with the following keys: 'committee', which is the name of the committee in the disclaimer that begins with Paid for by but does not include 'Paid for by', the committee address or the treasurer name. If no committee is present, the value of 'committee' should be None. Also add a key called 'sender', which is the name of the person, if any, mentioned as the author of the email. If there is no person named, the value is None. Do not include any other text, no yapping.
Gemini 2.5 Pro tops the leaderboard at the moment with 95.40%, but the new Mistral Small 3.1 manages 5th place with 85.70%, pretty good for a local model!
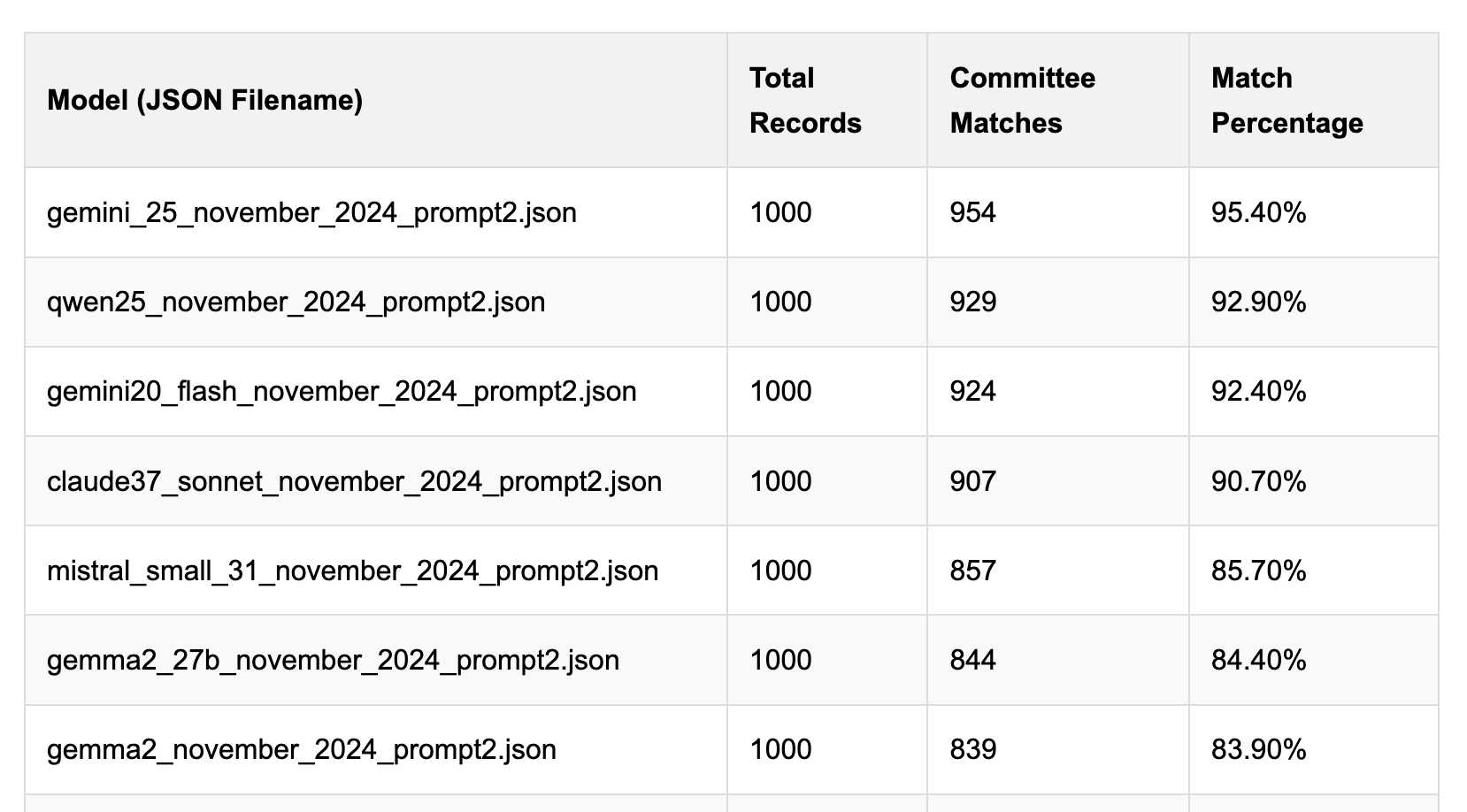
I said we need our own evals in my talk at the NICAR Data Journalism conference last month, without realizing Derek has been running one since January.
{kind=link}
April 9, 2025
Model Context Protocol has prompt injection security problems
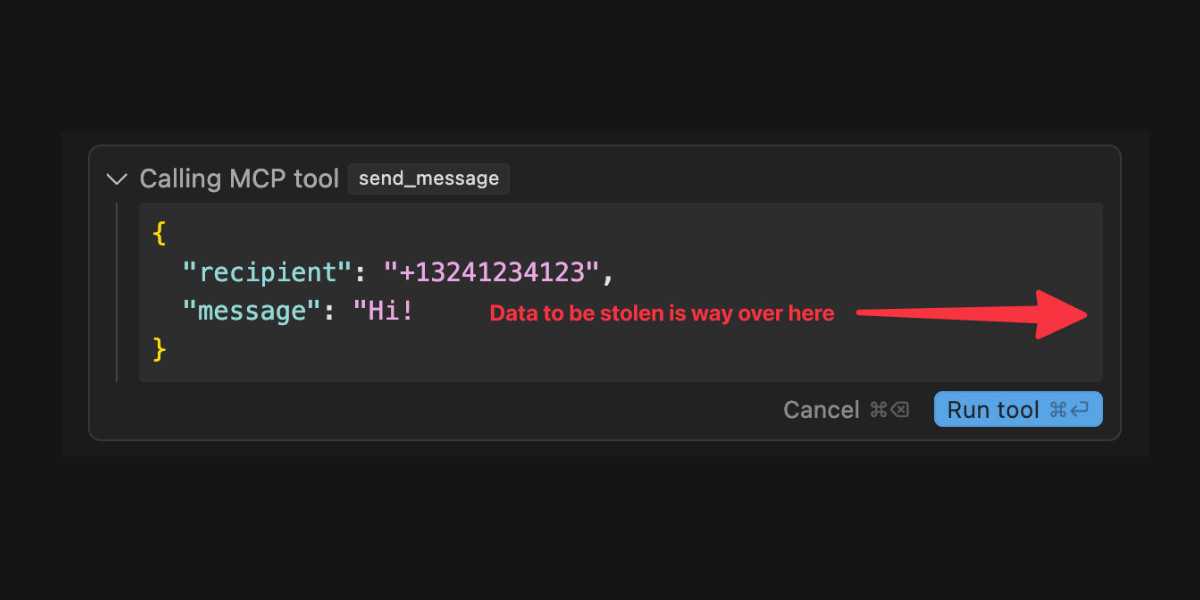
As more people start hacking around with implementations of MCP (the Model Context Protocol, a new standard for making tools available to LLM-powered systems) the security implications of tools built on that protocol are starting to come into focus.
[... 1,559 words][NAME AVAILABLE ON REQUEST FROM COMPANIES HOUSE].
I just noticed that the legendary company name ; DROP TABLE "COMPANIES";-- LTD is now listed as [NAME AVAILABLE ON REQUEST FROM COMPANIES HOUSE] on the UK government Companies House website.
For background, see No, I didn't try to break Companies House by culprit Sam Pizzey.
An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
April 10, 2025
These proposed API integrations where your LLM agent talks to someone else's LLM tool-using agent are the API version of that thing where someone uses ChatGPT to turn their bullets into an email and the recipient uses ChatGPT to summarize it back to bullet points.
llm-fragments-go (via) Filippo Valsorda released the first plugin by someone other than me that uses LLM's new register_fragment_loaders() plugin hook I announced the other day.
Install with llm install llm-fragments-go and then:
You can feed the docs of a Go package into LLM using the
go:fragment with the package name, optionally followed by a version suffix.
llm -f go:golang.org/x/mod/sumdb/note@v0.23.0 "Write a single file command that generates a key, prints the verifier key, signs an example message, and prints the signed note."
The implementation is just 33 lines of Python and works by running these commands in a temporary directory:
go mod init llm_fragments_go
go get golang.org/x/mod/sumdb/note@v0.23.0
go doc -all golang.org/x/mod/sumdb/note
Django: what’s new in 5.2. Adam Johnson provides extremely detailed unofficial annotated release notes for the latest Django.
I found his explanation and example of Form BoundField customization particularly useful - here's the new pattern for customizing the class= attribute on the label associated with a CharField:
from django import forms class WideLabelBoundField(forms.BoundField): def label_tag(self, contents=None, attrs=None, label_suffix=None): if attrs is None: attrs = {} attrs["class"] = "wide" return super().label_tag(contents, attrs, label_suffix) class NebulaForm(forms.Form): name = forms.CharField( max_length=100, label="Nebula Name", bound_field_class=WideLabelBoundField, )
I'd also missed the new HttpResponse.get_preferred_type() method for implementing HTTP content negotiation:
content_type = request.get_preferred_type( ["text/html", "application/json"] )
llm-docsmith (via) Matheus Pedroni released this neat plugin for LLM for adding docstrings to existing Python code. You can run it like this:
llm install llm-docsmith
llm docsmith ./scripts/main.py -o
The -o option previews the changes that will be made - without -o it edits the files directly.
It also accepts a -m claude-3.7-sonnet parameter for using an alternative model from the default (GPT-4o mini).
The implementation uses the Python libcst "Concrete Syntax Tree" package to manipulate the code, which means there's no chance of it making edits to anything other than the docstrings.
Here's the full system prompt it uses.
One neat trick is at the end of the system prompt it says:
You will receive a JSON template. Fill the slots marked with <SLOT> with the appropriate description. Return as JSON.
That template is actually provided JSON generated using these Pydantic classes:
class Argument(BaseModel): name: str description: str annotation: str | None = None default: str | None = None class Return(BaseModel): description: str annotation: str | None class Docstring(BaseModel): node_type: Literal["class", "function"] name: str docstring: str args: list[Argument] | None = None ret: Return | None = None class Documentation(BaseModel): entries: list[Docstring]
The code adds <SLOT> notes to that in various places, so the template included in the prompt ends up looking like this:
{
"entries": [
{
"node_type": "function",
"name": "create_docstring_node",
"docstring": "<SLOT>",
"args": [
{
"name": "docstring_text",
"description": "<SLOT>",
"annotation": "str",
"default": null
},
{
"name": "indent",
"description": "<SLOT>",
"annotation": "str",
"default": null
}
],
"ret": {
"description": "<SLOT>",
"annotation": "cst.BaseStatement"
}
}
]
}
LLM pricing calculator (updated). I updated my LLM pricing calculator this morning (Claude transcript) to show the prices of various hosted models in a sorted table, defaulting to lowest price first.
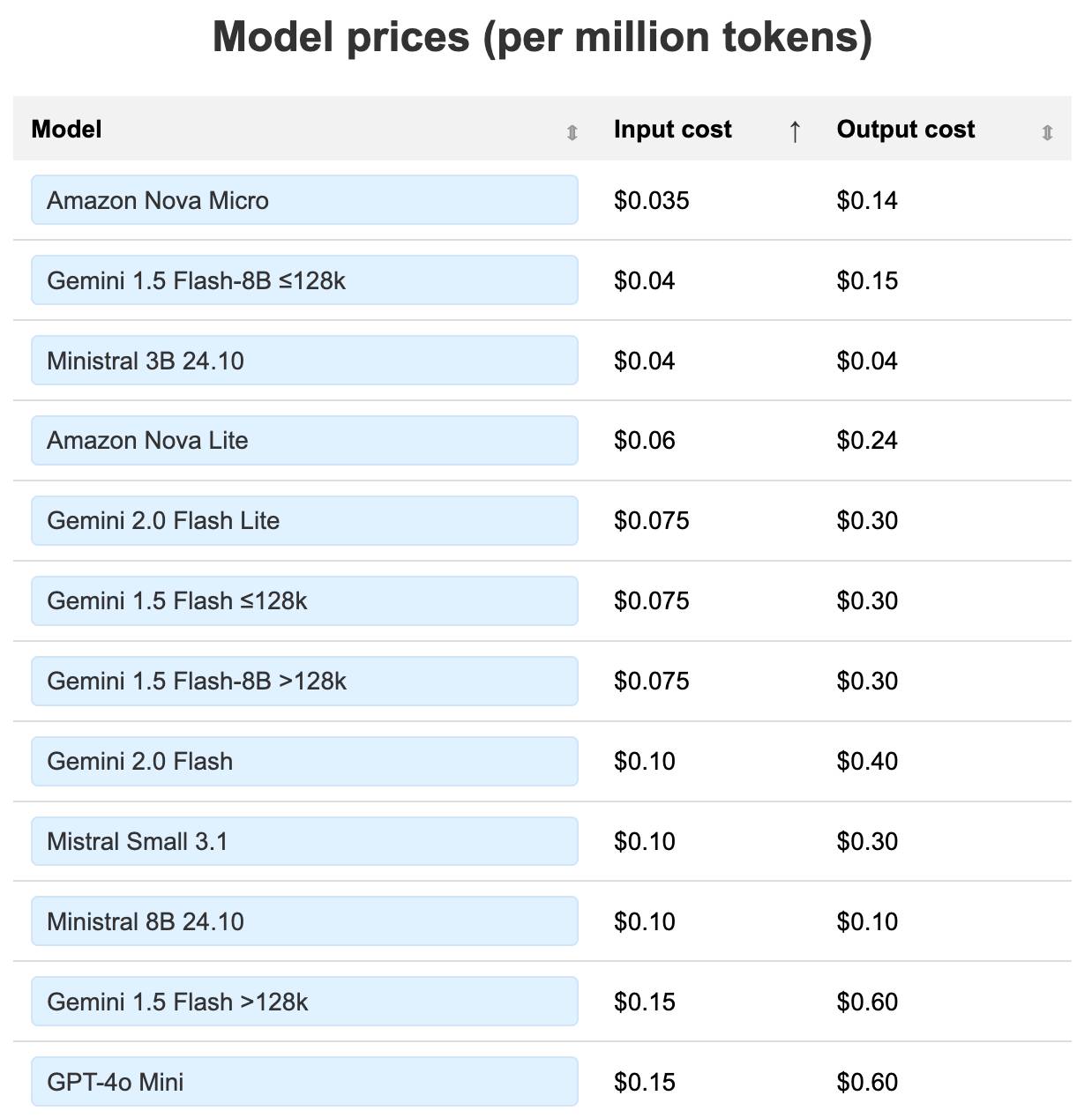
Amazon Nova and Google Gemini continue to dominate the lower end of the table. The most expensive models currently are still OpenAI's o1-Pro ($150/$600 and GPT-4.5 ($75/$150).
The first generation of AI-powered products (often called “AI Wrapper” apps, because they “just” are wrapped around an LLM API) were quickly brought to market by small teams of engineers, picking off the low-hanging problems. But today, I’m seeing teams of domain experts wading into the field, hiring a programmer or two to handle the implementation, while the experts themselves provide the prompts, data labeling, and evaluations.
For these companies, the coding is commodified but the domain expertise is the differentiator.
— Drew Breunig, The Dynamic Between Domain Experts & Developers Has Shifted
April 11, 2025
Default styles for h1 elements are changing
(via)
Wow, this is a rare occurrence! Firefox are rolling out a change to the default user-agent stylesheet for nested <h1> elements, currently ramping from 5% to 50% of users and with full roll-out planned for Firefox 140 in June 2025. Chrome is showing deprecation warnings and Safari are expected to follow suit in the future.
What's changing? The default sizes of <h1> elements that are nested inside <article>, <aside>, <nav> and <section>.
These are the default styles being removed:
/* where x is :is(article, aside, nav, section) */ x h1 { margin-block: 0.83em; font-size: 1.50em; } x x h1 { margin-block: 1.00em; font-size: 1.17em; } x x x h1 { margin-block: 1.33em; font-size: 1.00em; } x x x x h1 { margin-block: 1.67em; font-size: 0.83em; } x x x x x h1 { margin-block: 2.33em; font-size: 0.67em; }
The short version is that, many years ago, the HTML spec introduced the idea that an <h1> within a nested section should have the same meaning (and hence visual styling) as an <h2>. This never really took off and wasn't reflected by the accessibility tree, and was removed from the HTML spec in 2022. The browsers are now trying to cleanup the legacy default styles.
This advice from that post sounds sensible to me:
- Do not rely on default browser styles for conveying a heading hierarchy. Explicitly define your document hierarchy using
<h2>for second-level headings,<h3>for third-level, etc.- Always define your own
font-sizeandmarginfor<h1>elements.
llm-fragments-rust
(via)
Inspired by Filippo Valsorda's llm-fragments-go, Francois Garillot created llm-fragments-rust, an LLM fragments plugin that lets you pull documentation for any Rust crate directly into a prompt to LLM.
I really like this example, which uses two fragments to load documentation for two crates at once:
llm -f rust:rand@0.8.5 -f rust:tokio "How do I generate random numbers asynchronously?"
The code uses some neat tricks: it creates a new Rust project in a temporary directory (similar to how llm-fragments-go works), adds the crates and uses cargo doc --no-deps --document-private-items to generate documentation. Then it runs cargo tree --edges features to add dependency information, and cargo metadata --format-version=1 to include additional metadata about the crate.
CaMeL offers a promising new direction for mitigating prompt injection attacks
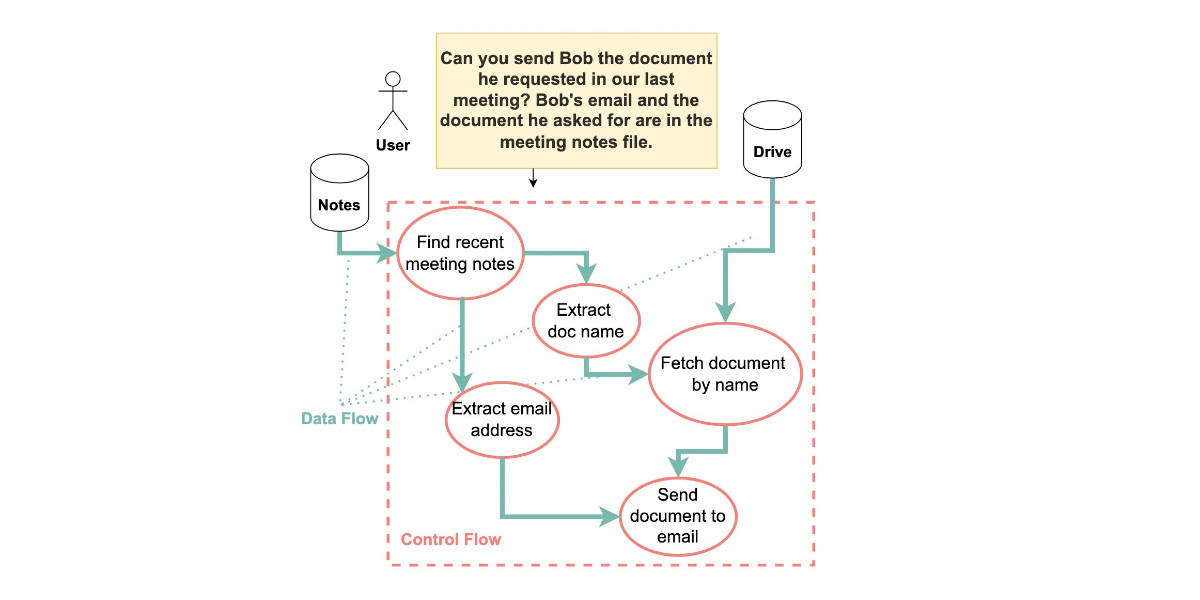
In the two and a half years that we’ve been talking about prompt injection attacks I’ve seen alarmingly little progress towards a robust solution. The new paper Defeating Prompt Injections by Design from Google DeepMind finally bucks that trend. This one is worth paying attention to.
[... 2,052 words]April 12, 2025
Backticks are traditionally banned from use in future language features, due to the small symbol. No reader should need to distinguish
`from'at a glance.
— Steve Dower, CPython core developer, August 2024