May 2025
167 posts: 11 entries, 59 links, 14 quotes, 21 notes, 62 beats
May 6, 2025
What’s the carbon footprint of using ChatGPT? Inspired by Andy Masley's cheat sheet (which I linked to last week) Hannah Ritchie explores some of the numbers herself.
Hanah is Head of Research at Our World in Data, a Senior Researcher at the University of Oxford (bio) and maintains a prolific newsletter on energy and sustainability so she has a lot more credibility in this area than Andy or myself!
My sense is that a lot of climate-conscious people feel guilty about using ChatGPT. In fact it goes further: I think many people judge others for using it, because of the perceived environmental impact. [...]
But after looking at the data on individual use of LLMs, I have stopped worrying about it and I think you should too.
The inevitable counter-argument to the idea that the impact of ChatGPT usage by an individual is negligible is that aggregate user demand is still the thing that drives these enormous investments in huge data centers and new energy sources to power them. Hannah acknowledges that:
I am not saying that AI energy demand, on aggregate, is not a problem. It is, even if it’s “just” of a similar magnitude to the other sectors that we need to electrify, such as cars, heating, or parts of industry. It’s just that individuals querying chatbots is a relatively small part of AI's total energy consumption. That’s how both of these facts can be true at the same time.
Meanwhile Arthur Clune runs the numbers on the potential energy impact of some much more severe usage patterns.
Developers burning through $100 of tokens per day (not impossible given some of the LLM-heavy development patterns that are beginning to emerge) could end the year with the equivalent of a short haul flight or 600 mile car journey.
In the panopticon scenario where all 10 million security cameras in the UK analyze video through a vision LLM at one frame per second Arthur estimates we would need to duplicate the total usage of Birmingham, UK - the output of a 1GW nuclear plant.
Let's not build that panopticon!
May 7, 2025
astral-sh/ty (via) Astral have been working on this "extremely fast Python type checker and language server, written in Rust" quietly but in-the-open for a while now. Here's the first alpha public release - albeit not yet announced - as ty on PyPI (nice donated two-letter name!)
You can try it out via uvx like this - run the command in a folder full of Python code and see what comes back:
uvx ty check
I got zero errors for my recent, simple condense-json library and a ton of errors for my more mature sqlite-utils library - output here.
It really is fast:
cd /tmp
git clone https://github.com/simonw/sqlite-utils
cd sqlite-utils
time uvx ty check
Reports it running in around a tenth of a second (0.109 total wall time) using multiple CPU cores:
uvx ty check 0.18s user 0.07s system 228% cpu 0.109 total
Running time uvx mypy . in the same folder (both after first ensuring the underlying tools had been cached) took around 7x longer:
uvx mypy . 0.46s user 0.09s system 74% cpu 0.740 total
This isn't a fair comparison yet as ty still isn't feature complete in comparison to mypy.
llm-prices.com.
I've been maintaining a simple LLM pricing calculator since October last year. I finally decided to split it out to its own domain name (previously it was hosted at tools.simonwillison.net/llm-prices), running on Cloudflare Pages.
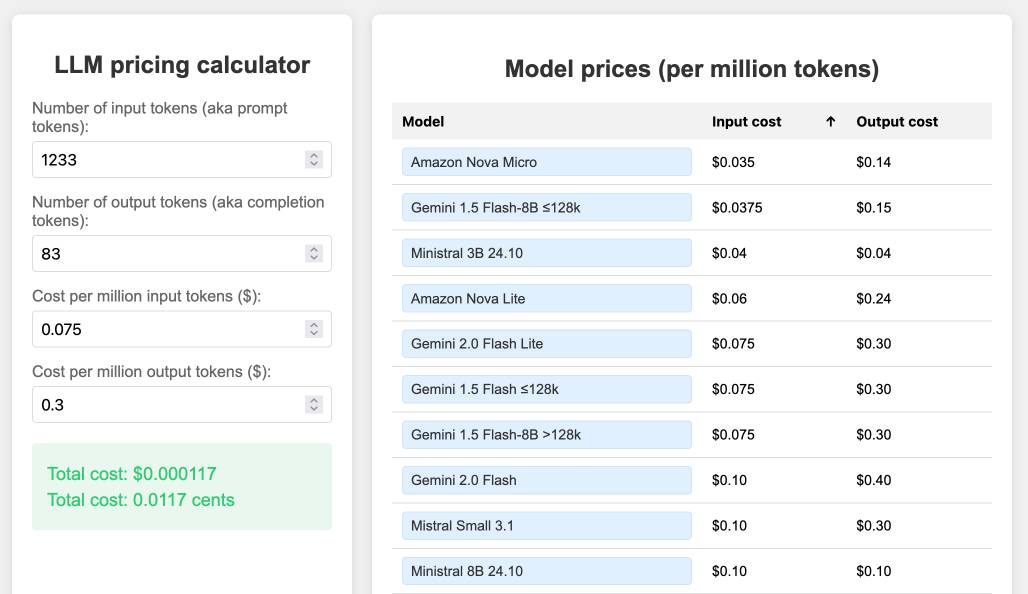
The site runs out of my simonw/llm-prices GitHub repository. I ported the history of the old llm-prices.html file using a vibe-coded bash script that I forgot to save anywhere.
I rarely use AI-generated imagery in my own projects, but for this one I found an excellent reason to use GPT-4o image outputs... to generate the favicon! I dropped a screenshot of the site into ChatGPT (o4-mini-high in this case) and asked for the following:
design a bunch of options for favicons for this site in a single image, white background

I liked the top right one, so I cropped it into Pixelmator and made a 32x32 version. Here's what it looks like in my browser:
I added a new feature just now: the state of the calculator is now reflected in the #fragment-hash URL of the page, which means you can link to your previous calculations.
I implemented that feature using the new gemini-2.5-pro-preview-05-06, since that model boasts improved front-end coding abilities. It did a pretty great job - here's how I prompted it:
llm -m gemini-2.5-pro-preview-05-06 -f https://www.llm-prices.com/ -s 'modify this code so that the state of the page is reflected in the fragmenth hash URL - I want to capture the values filling out the form fields and also the current sort order of the table. These should be respected when the page first loads too. Update them using replaceHistory, no need to enable the back button.'
Here's the transcript and the commit updating the tool, plus an example link showing the new feature in action (and calculating the cost for that Gemini 2.5 Pro prompt at 16.8224 cents, after fixing the calculation.)
Medium is the new large. New model release from Mistral - this time closed source/proprietary. Mistral Medium claims strong benchmark scores similar to GPT-4o and Claude 3.7 Sonnet, but is priced at $0.40/million input and $2/million output - about the same price as GPT 4.1 Mini. For comparison, GPT-4o is $2.50/$10 and Claude 3.7 Sonnet is $3/$15.
The model is a vision LLM, accepting both images and text.
More interesting than the price is the deployment model. Mistral Medium may not be open weights but it is very much available for self-hosting:
Mistral Medium 3 can also be deployed on any cloud, including self-hosted environments of four GPUs and above.
Mistral's other announcement today is Le Chat Enterprise. This is a suite of tools that can integrate with your company's internal data and provide "agents" (these look similar to Claude Projects or OpenAI GPTs), again with the option to self-host.
Is there a new open weights model coming soon? This note tucked away at the bottom of the Mistral Medium 3 announcement seems to hint at that:
With the launches of Mistral Small in March and Mistral Medium today, it's no secret that we're working on something 'large' over the next few weeks. With even our medium-sized model being resoundingly better than flagship open source models such as Llama 4 Maverick, we're excited to 'open' up what's to come :)
I released llm-mistral 0.12 adding support for the new model.
Create and edit images with Gemini 2.0 in preview (via) Gemini 2.0 Flash has had image generation capabilities for a while now, and they're now available via the paid Gemini API - at 3.9 cents per generated image.
According to the API documentation you need to use the new gemini-2.0-flash-preview-image-generation model ID and specify {"responseModalities":["TEXT","IMAGE"]} as part of your request.
Here's an example that calls the API using curl (and fetches a Gemini key from the llm keys get store):
curl -s -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-preview-image-generation:generateContent?key=$(llm keys get gemini)" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [ {"text": "Photo of a raccoon in a trash can with a paw-written sign that says I love trash"} ] }], "generationConfig":{"responseModalities":["TEXT","IMAGE"]} }' > /tmp/raccoon.json
Here's the response. I got Gemini 2.5 Pro to vibe-code me a new debug tool for visualizing that JSON. If you visit that tool and click the "Load an example" link you'll see the result of the raccoon image visualized:
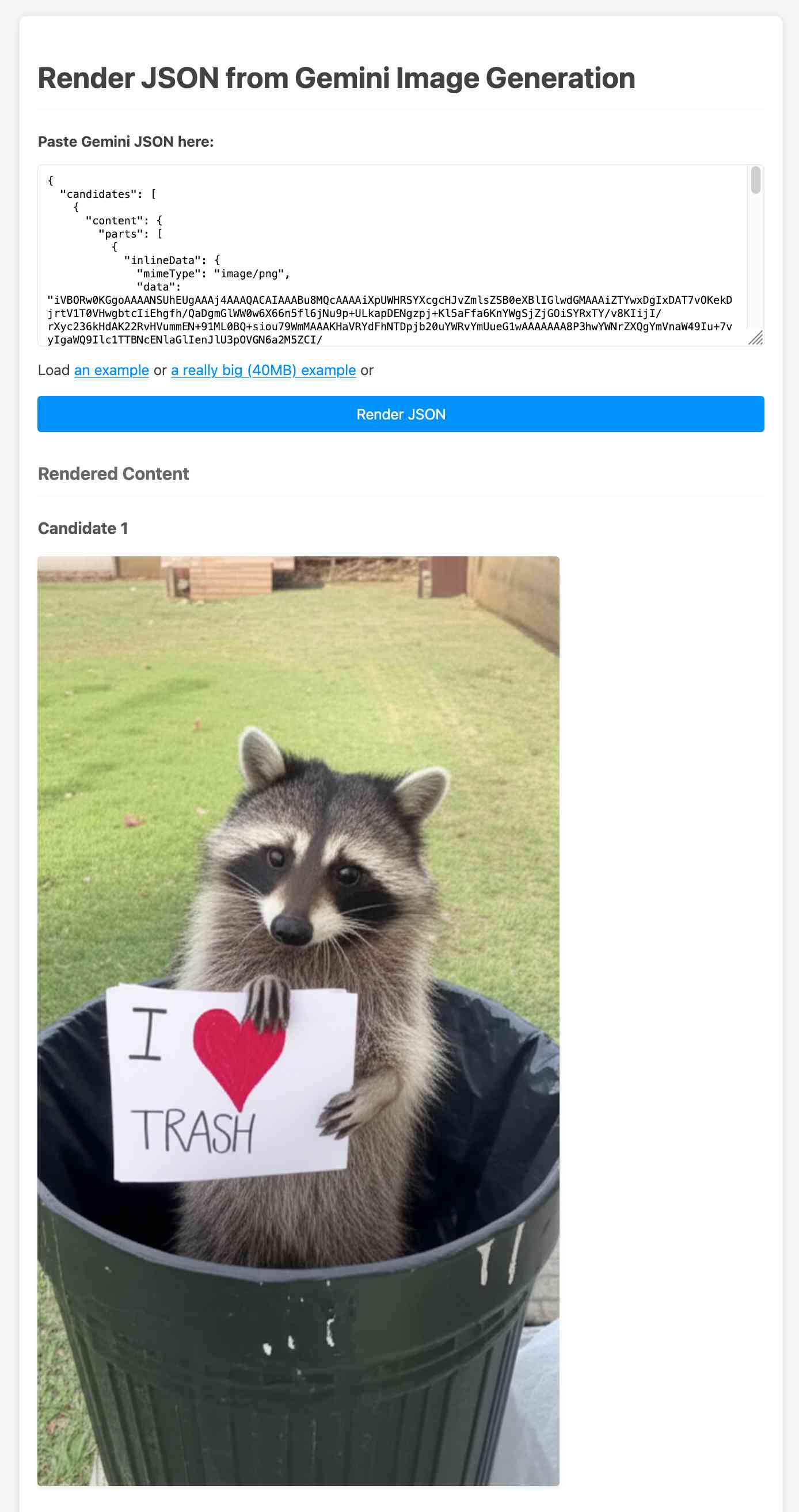
The other prompt I tried was this one:
Provide a vegetarian recipe for butter chicken but with chickpeas not chicken and include many inline illustrations along the way
The result of that one was a 41MB JSON file(!) containing 28 images - which presumably cost over a dollar since images are 3.9 cents each.
Some of the illustrations it chose for that one were somewhat unexpected:

If you want to see that one you can click the "Load a really big example" link in the debug tool, then wait for your browser to fetch and render the full 41MB JSON file.
The most interesting feature of Gemini (as with GPT-4o images) is the ability to accept images as inputs. I tried that out with this pelican photo like this:
{kind=link}
cat > /tmp/request.json << EOF { "contents": [{ "parts":[ {"text": "Modify this photo to add an inappropriate hat"}, { "inline_data": { "mime_type":"image/jpeg", "data": "$(base64 -i pelican.jpg)" } } ] }], "generationConfig": {"responseModalities": ["TEXT", "IMAGE"]} } EOF # Execute the curl command with the JSON file curl -X POST \ 'https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-preview-image-generation:generateContent?key='$(llm keys get gemini) \ -H 'Content-Type: application/json' \ -d @/tmp/request.json \ > /tmp/out.json
And now the pelican is wearing a hat:

Introducing web search on the Anthropic API
(via)
Anthropic's web search (presumably still powered by Brave) is now also available through their API, in the shape of a new web search tool called web_search_20250305.
You can specify a maximum number of uses per prompt and you can also pass a list of disallowed or allowed domains, plus hints as to the user's current location.
Search results are returned in a format that looks similar to the Anthropic Citations API.
It's charged at $10 per 1,000 searches, which is a little more expensive than what the Brave Search API charges ($3 or $5 or $9 per thousand depending on how you're using them).
I couldn't find any details of additional rules surrounding storage or display of search results, which surprised me because both Google Gemini and OpenAI have these for their own API search results.
May 8, 2025
llm-gemini 0.19.1.
Bugfix release for my llm-gemini plugin, which was recording the number of output tokens (needed to calculate the price of a response) incorrectly for the Gemini "thinking" models. Those models turn out to return candidatesTokenCount and thoughtsTokenCount as two separate values which need to be added together to get the total billed output token count. Full details in this issue.
I spotted this potential bug in this response log this morning, and my concerns were confirmed when Paul Gauthier wrote about a similar fix in Aider in Gemini 2.5 Pro Preview 03-25 benchmark cost, where he noted that the $6.32 cost recorded to benchmark Gemini 2.5 Pro Preview 03-25 was incorrect. Since that model is no longer available (despite the date-based model alias persisting) Paul is not able to accurately calculate the new cost, but it's likely a lot more since the Gemini 2.5 Pro Preview 05-06 benchmark cost $37.
I've gone through my gemini tag and attempted to update my previous posts with new calculations - this mostly involved increases in the order of 12.336 cents to 16.316 cents (as seen here).
But I’ve also had my own quiet concerns about what [vibe coding] means for early-career developers. So much of how I learned came from chasing bugs in broken tutorials and seeing how all the pieces connected, or didn’t. There was value in that. And maybe I’ve been a little protective of it.
A mentor challenged that. He pointed out that debugging AI generated code is a lot like onboarding into a legacy codebase, making sense of decisions you didn’t make, finding where things break, and learning to trust (or rewrite) what’s already there. That’s the kind of work a lot of developers end up doing anyway.
— Ashley Willis, What Even Is Vibe Coding?
Microservices only pay off when you have real scaling bottlenecks, large teams, or independently evolving domains. Before that? You’re paying the price without getting the benefit: duplicated infra, fragile local setups, and slow iteration.
— Oleg Pustovit, Microservices Are a Tax Your Startup Probably Can’t Afford
Reservoir Sampling (via) Yet another outstanding interactive essay by Sam Rose (previously), this time explaining how reservoir sampling can be used to select a "fair" random sample when you don't know how many options there are and don't want to accumulate them before making a selection.
Reservoir sampling is one of my favourite algorithms, and I've been wanting to write about it for years now. It allows you to solve a problem that at first seems impossible, in a way that is both elegant and efficient.
I appreciate that Sam starts the article with "No math notation, I promise." Lots of delightful widgets to interact with here, all of which help build an intuitive understanding of the underlying algorithm.
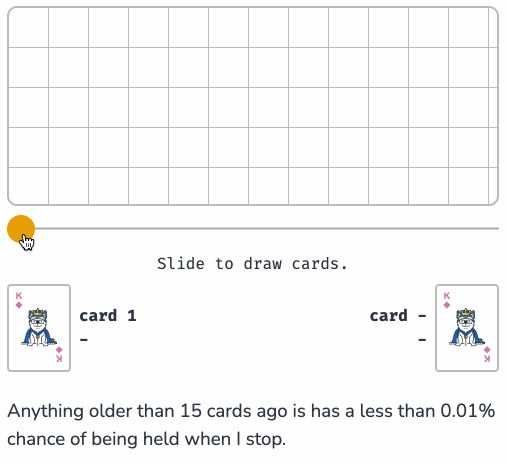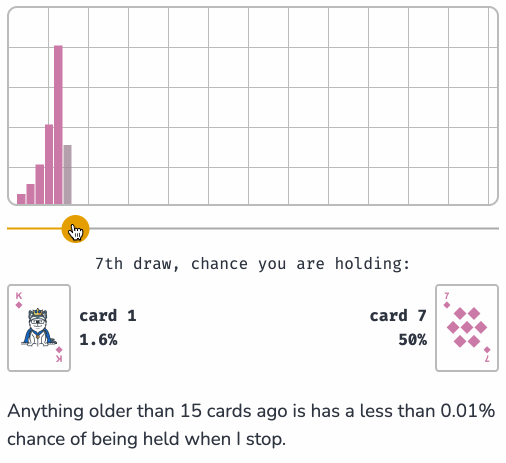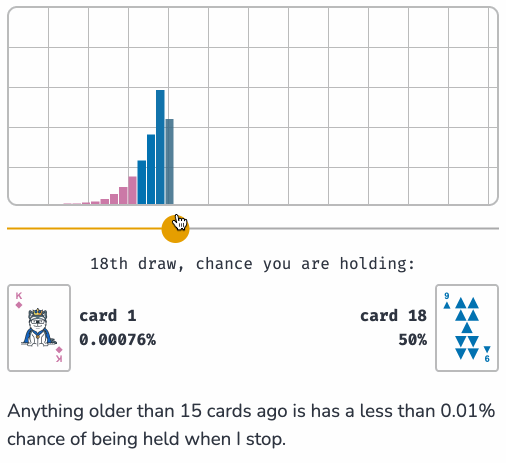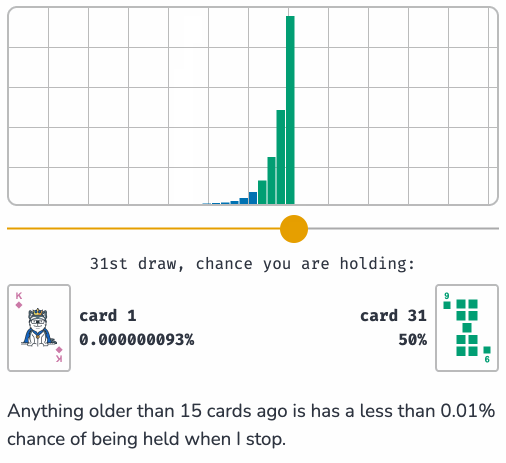
Sam shows how this algorithm can be applied to the real-world problem of sampling log files when incoming logs threaten to overwhelm a log aggregator.
The dog illustration is commissioned art and the MIT-licensed code is available on GitHub.
If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step. [...]
If Claude is shown a classic puzzle, before proceeding, it quotes every constraint or premise from the person’s message word for word before inside quotation marks to confirm it’s not dealing with a new variant. [...]
If asked to write poetry, Claude avoids using hackneyed imagery or metaphors or predictable rhyming schemes.
— Claude's system prompt, via Drew Breunig
SQLite CREATE TABLE: The DEFAULT clause. If your SQLite create table statement includes a line like this:
CREATE TABLE alerts (
-- ...
alert_created_at text default current_timestamp
)
current_timestamp will be replaced with a UTC timestamp in the format 2025-05-08 22:19:33. You can also use current_time for HH:MM:SS and current_date for YYYY-MM-DD, again using UTC.
Posting this here because I hadn't previously noticed that this defaults to UTC, which is a useful detail. It's also a strong vote in favor of YYYY-MM-DD HH:MM:SS as a string format for use with SQLite, which doesn't otherwise provide a formal datetime type.
May 9, 2025
Gemini 2.5 Models now support implicit caching.
I just spotted a cacheTokensDetails key in the token usage JSON while running a long chain of prompts against Gemini 2.5 Flash - despite not configuring caching myself:
{"cachedContentTokenCount": 200658, "promptTokensDetails": [{"modality": "TEXT", "tokenCount": 204082}], "cacheTokensDetails": [{"modality": "TEXT", "tokenCount": 200658}], "thoughtsTokenCount": 2326}
I went searching and it turns out Gemini had a massive upgrade to their prompt caching earlier today:
Implicit caching directly passes cache cost savings to developers without the need to create an explicit cache. Now, when you send a request to one of the Gemini 2.5 models, if the request shares a common prefix as one of previous requests, then it’s eligible for a cache hit. We will dynamically pass cost savings back to you, providing the same 75% token discount. [...]
To make more requests eligible for cache hits, we reduced the minimum request size for 2.5 Flash to 1024 tokens and 2.5 Pro to 2048 tokens.
Previously you needed to both explicitly configure the cache and pay a per-hour charge to keep that cache warm.
This new mechanism is so much more convenient! It imitates how both DeepSeek and OpenAI implement prompt caching, leaving Anthropic as the remaining large provider who require you to manually configure prompt caching to get it to work.
Gemini's explicit caching mechanism is still available. The documentation says:
Explicit caching is useful in cases where you want to guarantee cost savings, but with some added developer work.
With implicit caching the cost savings aren't possible to predict in advance, especially since the cache timeout within which a prefix will be discounted isn't described and presumably varies based on load and other circumstances outside of the developer's control.
Update: DeepMind's Philipp Schmid:
There is no fixed time, but it's should be a few minutes.
sqlite-utils 4.0a0. New alpha release of sqlite-utils, my Python library and CLI tool for manipulating SQLite databases.
It's the first 4.0 alpha because there's a (minor) backwards-incompatible change: I've upgraded the .upsert() and .upsert_all() methods to use SQLIte's UPSERT mechanism, INSERT INTO ... ON CONFLICT DO UPDATE. Details in this issue.
That feature was added to SQLite in version 3.24.0, released 2018-06-04. I'm pretty cautious about my SQLite version support since the underlying library can be difficult to upgrade, depending on your platform and operating system.
I'm going to leave the new alpha to bake for a little while before pushing a stable release. Since this is a major version bump I'm going to take the opportunity to see if there are any other minor API warts that I can clean up at the same time.
I had some notes in a GitHub issue thread in a private repository that I wanted to export as Markdown. I realized that I could get them using a combination of several recent projects.
Here's what I ran:
export GITHUB_TOKEN="$(llm keys get github)"
llm -f issue:https://github.com/simonw/todos/issues/170 \
-m echo --no-log | jq .prompt -r > notes.md
I have a GitHub personal access token stored in my LLM keys, for use with Anthony Shaw's llm-github-models plugin.
My own llm-fragments-github plugin expects an optional GITHUB_TOKEN environment variable, so I set that first - here's an issue to have it use the github key instead.
With that set, the issue: fragment loader can take a URL to a private GitHub issue thread and load it via the API using the token, then concatenate the comments together as Markdown. Here's the code for that.
Fragments are meant to be used as input to LLMs. I built a llm-echo plugin recently which adds a fake LLM called "echo" which simply echos its input back out again.
Adding --no-log prevents that junk data from being stored in my LLM log database.
The output is JSON with a "prompt" key for the original prompt. I use jq .prompt to extract that out, then -r to get it as raw text (not a "JSON string").
... and I write the result to notes.md.
May 10, 2025

TIL: SQLite triggers. I've been doing some work with SQLite triggers recently while working on sqlite-chronicle, and I decided I needed a single reference to exactly which triggers are executed for which SQLite actions and what data is available within those triggers.
I wrote this triggers.py script to output as much information about triggers as possible, then wired it into a TIL article using Cog. The Cog-powered source code for the TIL article can be seen here.
Trying out llama.cpp’s new vision support
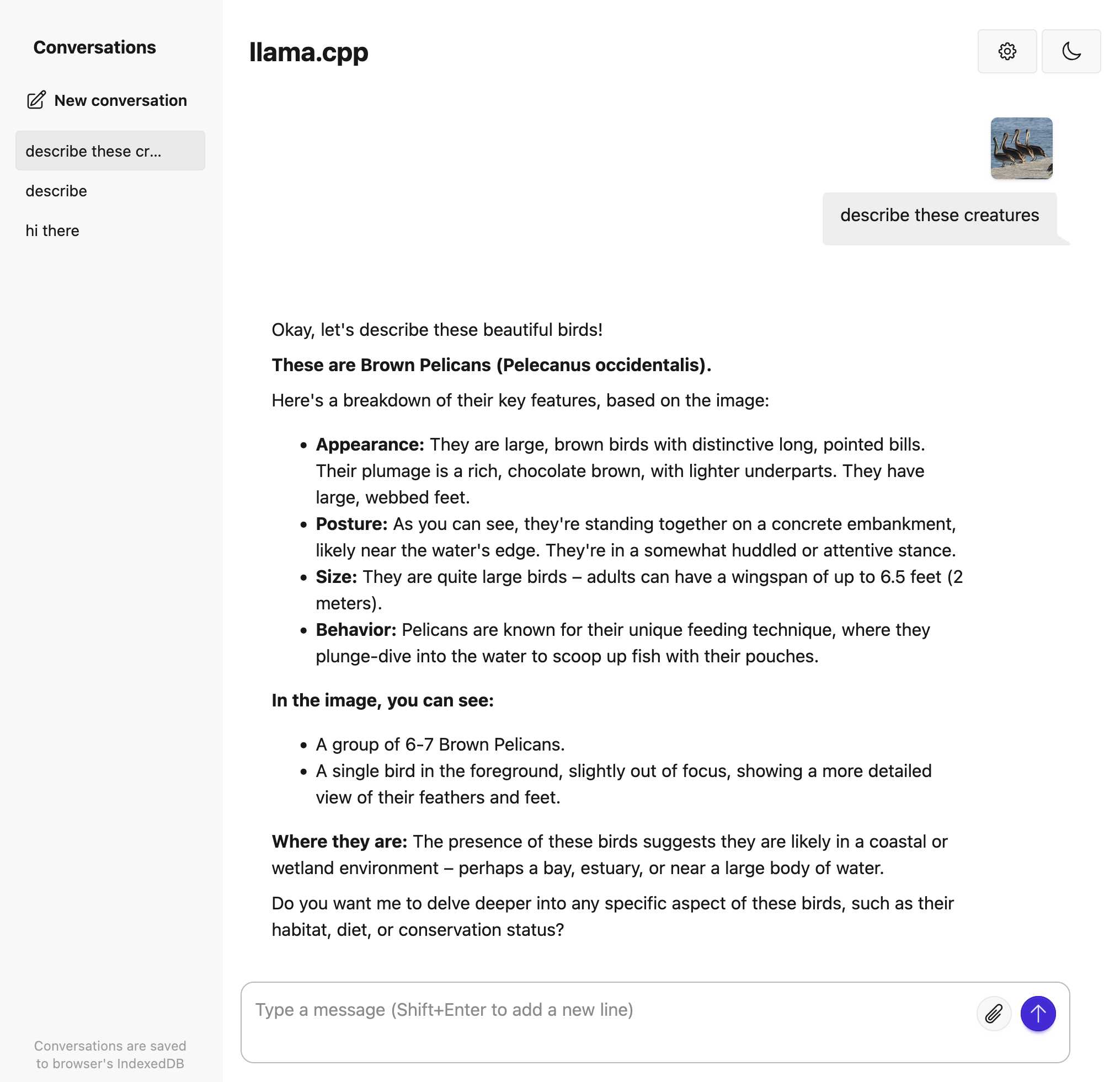
This llama.cpp server vision support via libmtmd pull request—via Hacker News—was merged earlier today. The PR finally adds full support for vision models to the excellent llama.cpp project. It’s documented on this page, but the more detailed technical details are covered here. Here are my notes on getting it working on a Mac.
[... 1,693 words]Poker Face season two just started on Peacock (the US streaming service). It's my favorite thing on TV right now. I've started threads on MetaFilter FanFare for episodes one, two and three.
May 11, 2025
Achievement unlocked: tap danced in the local community college dance recital.
Cursor: Security (via) Cursor's security documentation page includes a surprising amount of detail about how the Cursor text editor's backend systems work.
I've recently learned that checking an organization's list of documented subprocessors is a great way to get a feel for how everything works under the hood - it's a loose "view source" for their infrastructure! That was how I confirmed that Anthropic's search features used Brave search back in March.
Cursor's list includes AWS, Azure and GCP (AWS for primary infrastructure, Azure and GCP for "some secondary infrastructure"). They host their own custom models on Fireworks and make API calls out to OpenAI, Anthropic, Gemini and xAI depending on user preferences. They're using turbopuffer as a hosted vector store.
The most interesting section is about codebase indexing:
Cursor allows you to semantically index your codebase, which allows it to answer questions with the context of all of your code as well as write better code by referencing existing implementations. […]
At our server, we chunk and embed the files, and store the embeddings in Turbopuffer. To allow filtering vector search results by file path, we store with every vector an obfuscated relative file path, as well as the line range the chunk corresponds to. We also store the embedding in a cache in AWS, indexed by the hash of the chunk, to ensure that indexing the same codebase a second time is much faster (which is particularly useful for teams).
At inference time, we compute an embedding, let Turbopuffer do the nearest neighbor search, send back the obfuscated file path and line range to the client, and read those file chunks on the client locally. We then send those chunks back up to the server to answer the user’s question.
When operating in privacy mode - which they say is enabled by 50% of their users - they are careful not to store any raw code on their servers for longer than the duration of a single request. This is why they store the embeddings and obfuscated file paths but not the code itself.
Reading this made me instantly think of the paper Text Embeddings Reveal (Almost) As Much As Text about how vector embeddings can be reversed. The security documentation touches on that in the notes:
Embedding reversal: academic work has shown that reversing embeddings is possible in some cases. Current attacks rely on having access to the model and embedding short strings into big vectors, which makes us believe that the attack would be somewhat difficult to do here. That said, it is definitely possible for an adversary who breaks into our vector database to learn things about the indexed codebases.
May 12, 2025
It's interesting how much my perception of o3 as being the latest, best model released by OpenAI is tarnished by the co-release of o4-mini. I'm also still not entirely sure how to compare o3 to o1-pro, especially given o1-pro is 15x more expensive via the OpenAI API.