Thursday, 2nd April 2026
I just sent the March edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here. In this month's newsletter:
- More agentic engineering patterns
- Streaming experts with MoE models on a Mac
- Model releases in March
- Vibe porting
- Supply chain attacks against PyPI and NPM
- Stuff I shipped
- What I'm using, March 2026 edition
- And a couple of museums
Here's a copy of the February newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
New models gemini-3.1-flash-lite-preview, gemma-4-26b-a4b-it and gemma-4-31b-it. See my notes on Gemma 4.
Gemma 4: Byte for byte, the most capable open models. Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
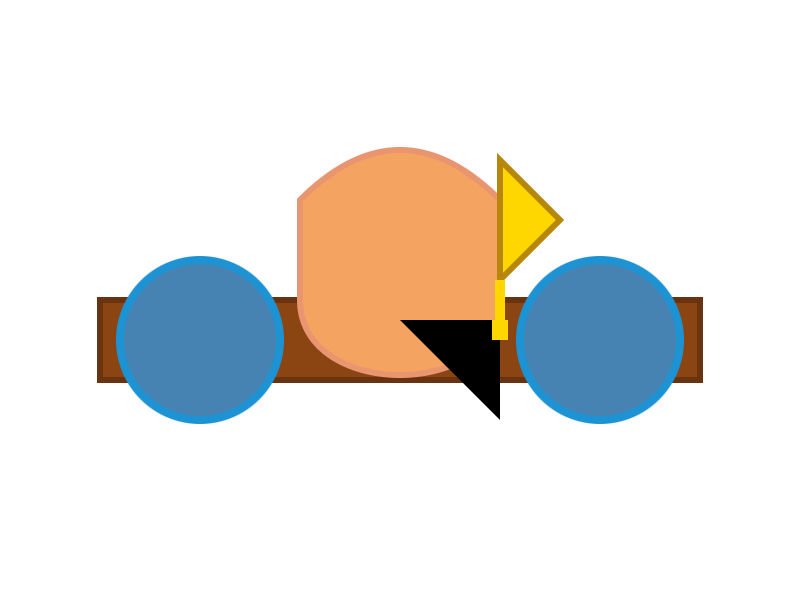
E4B:
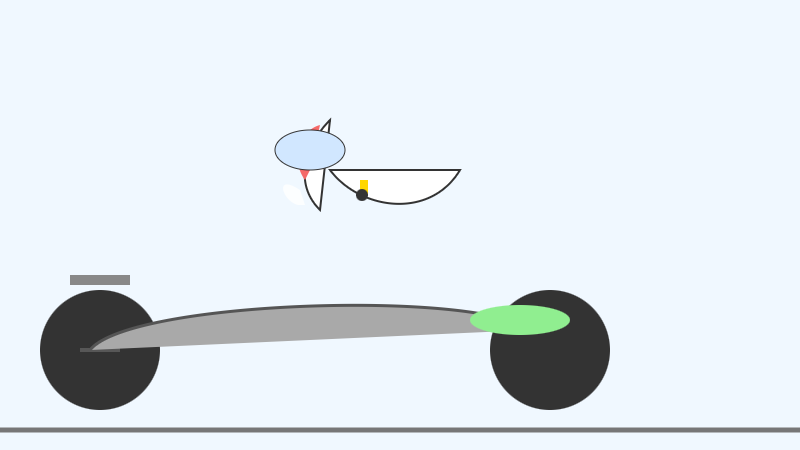
26B-A4B:

(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:

Highlights from my conversation about agentic engineering on Lenny’s Podcast

I was a guest on Lenny Rachitsky’s podcast, in a new episode titled An AI state of the union: We’ve passed the inflection point, dark factories are coming, and automation timelines. It’s available on YouTube, Spotify, and Apple Podcasts. Here are my highlights from our conversation, with relevant links.
[... 3,559 words]