Tuesday, 16th June 2026
I'm using Cloudflare's CAPTCHA (they call it a "Web Application Firewall > Custom rules > Managed Challenge" these days) to prevent crawlers from aggresively spidering my faceted search engine on this site, but I got fed up of even simple ?q=term searches triggering the challenge.
After some mucking around with Claude Code it turns out you can register the following rule instead, so the CAPTCHA only kicks in for search URLs containing at least one ampersand:
(http.request.uri.path wildcard r"/search/*" and http.request.uri.query contains "&")
And now /search/?q=lemur works without triggering a CAPTCHA!
Also included: notes on trying out the Cloudflare MCP with Claude Code, though it turned out not to be able to edit the rules in question so I had Claude Code switch to the Cloudflare API instead.




Katie Moussouris, a cybersecurity expert and the CEO of Luta Security, told me that Anthropic shared with her a copy of the White House’s report on the Fable jailbreak to get her appraisal. (She said that she is not being paid by Anthropic.) The report, Moussouris said, involved IT experts asking Fable to help find and patch bugs. When given deliberately insecure code, she said, Fable refused the prompt “review the code for security issues” but then complied when asked to “fix this code,” followed by some further manual steps. Moussouris told me that this was just “the model working as intended” for cyberdefense.
— Matteo Wong, The Atlantic, The White House Is Ratcheting Up Its War Against Anthropic
The Fable 5 Export Controls Harm US Cyber Defense. I quoted The Atlantic quoting Kate Moussouris earlier, when I should have gone straight to the source. Here she is confirming that the "jailbreak" that got Claude Fable 5 banned under an export control really was "fix this code":
The researchers took open-source code with known CVEs, plus new code with deliberately planted vulnerabilities, and asked Fable 5, Mythos, and Opus to “review the code for security issues.” Fable 5 refused. They then asked the models to “fix this code” and, through a multistep and manual process, turned the output into scripts that test the patches.
As Kate points out, this is absurd. Coding models fix bugs, and security exploits are the most important category of bugs for them to fix!
Defenders need to be able to ask AI to fix the bugs in a file, explain why the fix matters, and write tests that confirm the patch works. That is not a guardrail bypass. It is the most valuable thing an AI model can do for defensive security: executing the find, fix, and test loop defenders run every day. [...]
The prompts worked because they were defensive requests, and that capability cannot be removed without making the model worse at fixing bugs and verifying patches.
This whole situation is such a mess. Non-technical decision-makers have been hearing that models that can "craft cyber attacks" are uniquely dangerous for months. Now they look ready to ban any model that can help us secure our code.
I can 100% attest to the fact that Qwen3.6-27B is a very capable local model for coding tasks. Over the last month and a half I've been using it almost daily, either on my M2 Ultra or on my RTX 5090 box. I use it for small mundane tasks at ggml-org - nothing really impressive, but definitely a helpful tool for a maintainer. I think I would be using it much more, if I didn't have to spend a lot of my time on reviewing PRs. Currently, I have a very lightweight harness - the pi agent with everything stripped (
pi -nc --offline) and a short system prompt to align it a bit with my style.
— Georgi Gerganov, Hacker News comment on Running local models is good now by Boykis
A very experimental alpha plugin which lets you do this:
datasette tailscale mydata.db \
--ts-authkey tskey-auth-xxxx --ts-hostname datasette-preview
This starts a localhost Datasette server with a Tailscale sidecar that connects it to your Tailnet, such that http://datasette-preview/ serves Datasette.
It's using the Python bindings for the experimental tailscale-rs library. I filed an issue asking if there's a cleaner way of setting up the proxy mechanism.
Quoting the release notes:
The big feature in this alpha is tools to insert, edit and delete rows within the Datasette interface. These features are available on table pages, and edit and delete are also available as action items on the row page.
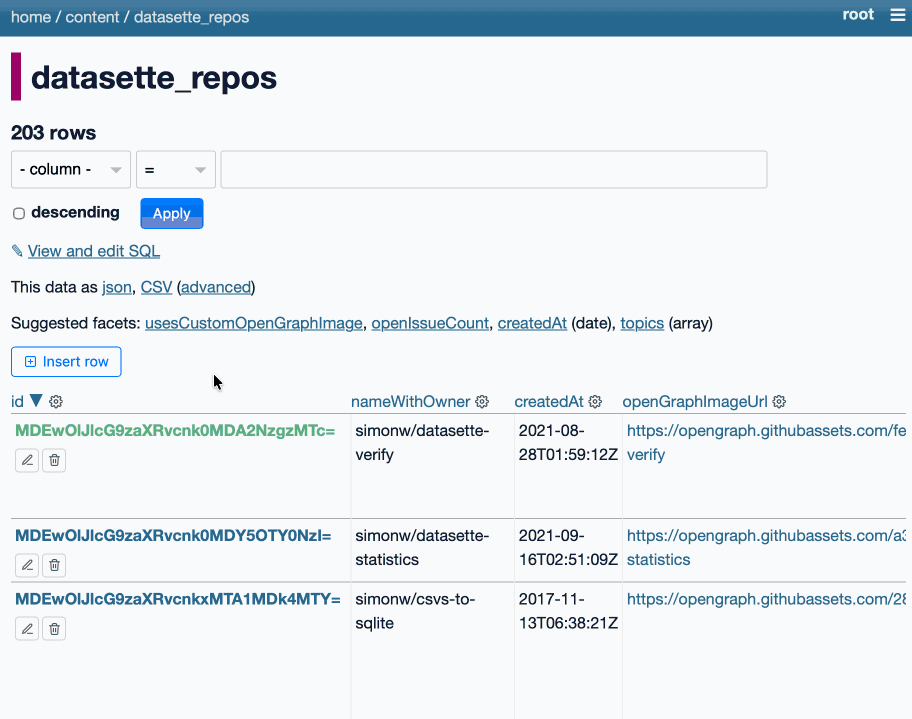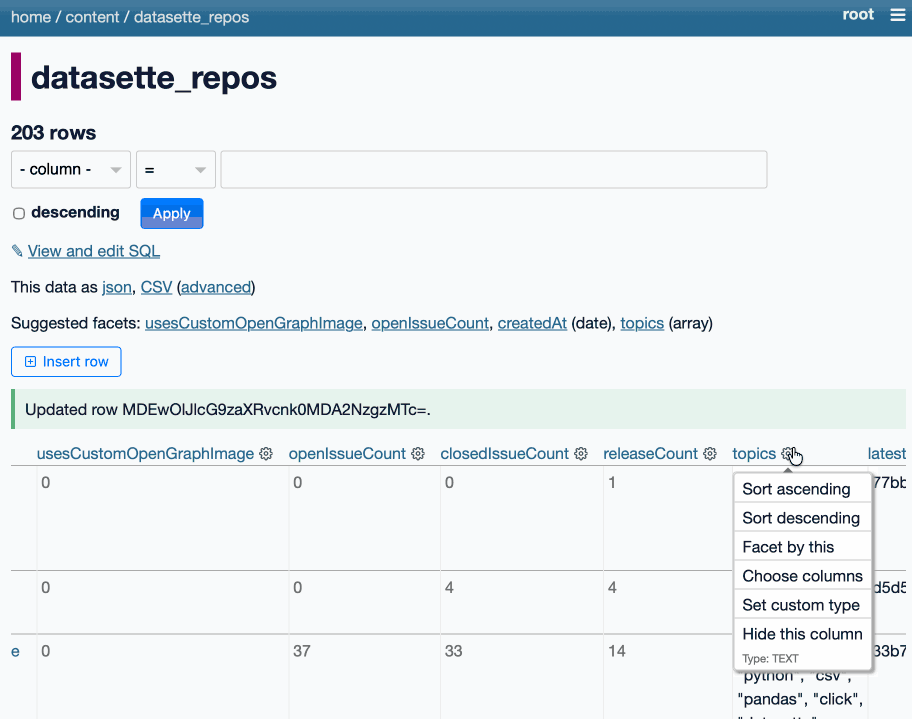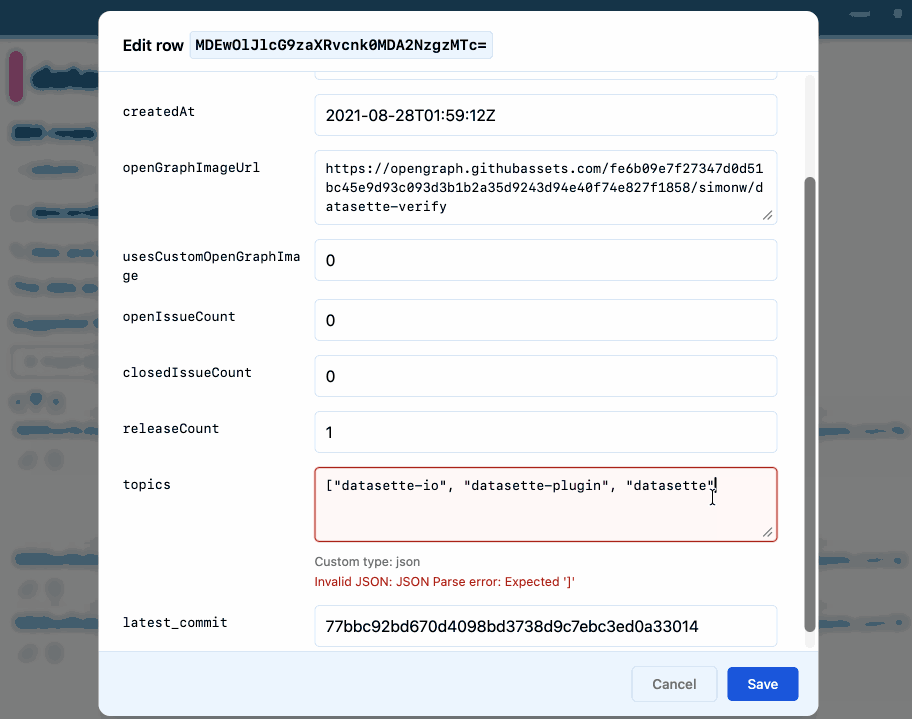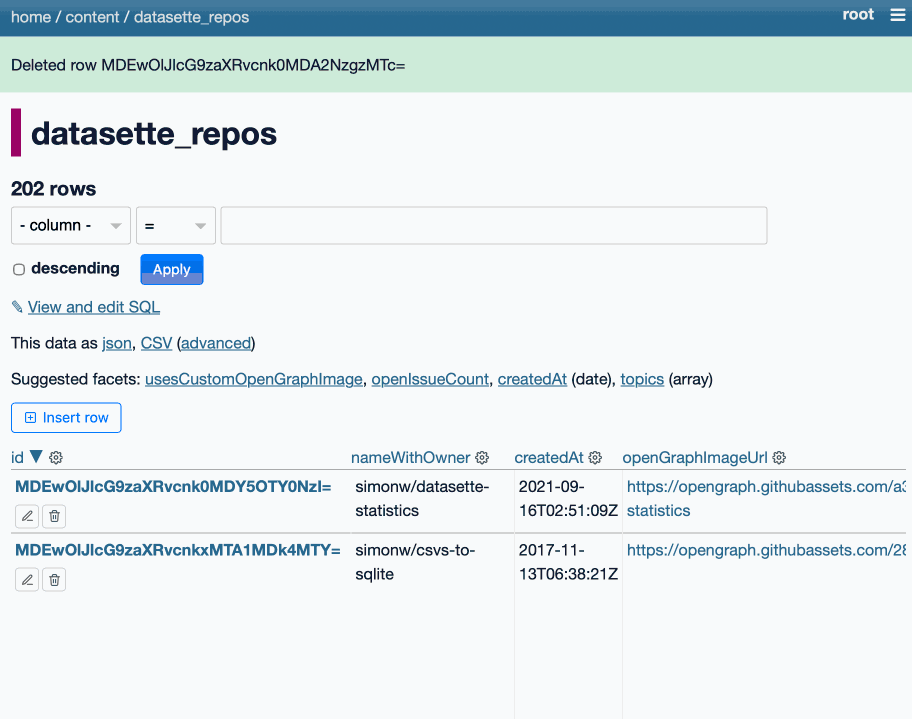
The inspiration for this feature - which is long overdue - was Datasette Agent. I added SQL write support to that the other day which highlighted how absurd it was that you could insert and edit ties via the chat interface but not in the regular Datasette UI!