Tuesday, 17th March 2026
Subagents
LLMs are restricted by their context limit - how many tokens they can fit in their working memory at any given time. These values have not increased much over the past two years even as the LLMs themselves have seen dramatic improvements in their abilities - they generally top out at around 1,000,000, and benchmarks frequently report better quality results below 200,000.
Carefully managing the context such that it fits within those limits is critical to getting great results out of a model.
Subagents provide a simple but effective way to handle larger tasks without burning through too much of the coding agent’s valuable top-level context. [... 926 words]
If you do not understand the ticket, if you do not understand the solution, or if you do not understand the feedback on your PR, then your use of LLM is hurting Django as a whole. [...]
For a reviewer, it’s demoralizing to communicate with a facade of a human.
This is because contributing to open source, especially Django, is a communal endeavor. Removing your humanity from that experience makes that endeavor more difficult. If you use an LLM to contribute to Django, it needs to be as a complementary tool, not as your vehicle.
— Tim Schilling, Give Django your time and money, not your tokens
Adds support for OpenAI's new models gpt-5.4, gpt-5.4-mini, and gpt-5.4-nano.
GPT-5.4 mini and GPT-5.4 nano, which can describe 76,000 photos for $52
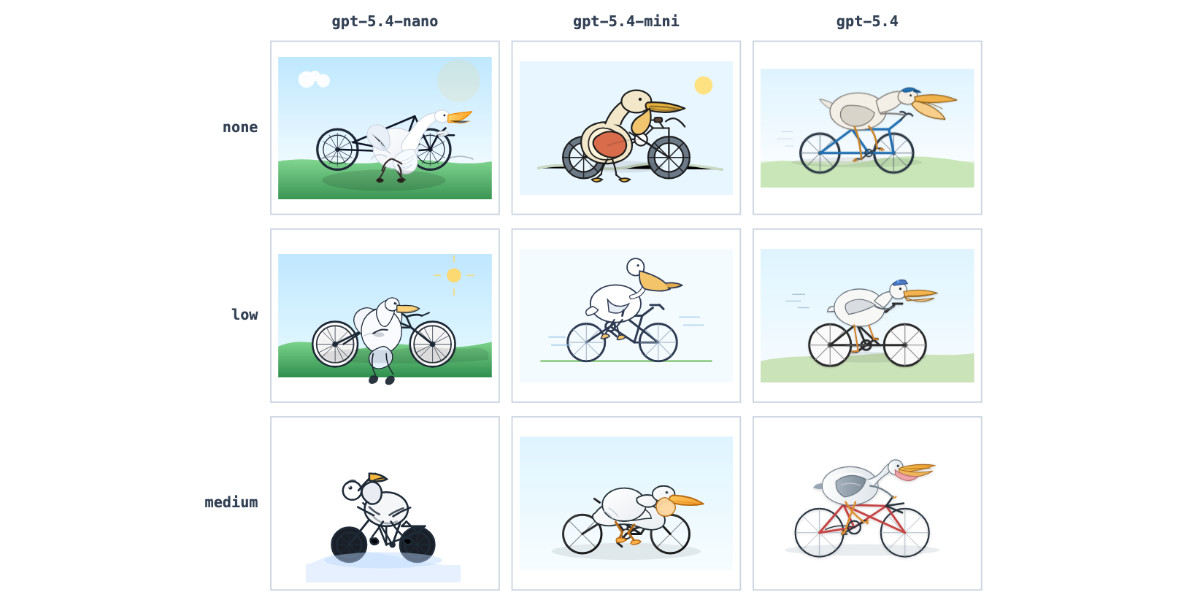
OpenAI today: Introducing GPT‑5.4 mini and nano. These models join GPT-5.4 which was released two weeks ago.
[... 717 words]Great news—we’ve hit our (very modest) performance goals for the CPython JIT over a year early for macOS AArch64, and a few months early for x86_64 Linux. The 3.15 alpha JIT is about 11-12% faster on macOS AArch64 than the tail calling interpreter, and 5-6%faster than the standard interpreter on x86_64 Linux.
— Ken Jin, Python 3.15’s JIT is now back on track