March 2026
110 posts: 10 entries, 27 links, 19 quotes, 4 notes, 42 beats, 8 chapters
March 27, 2026
We Rewrote JSONata with AI in a Day, Saved $500K/Year. Bit of a hyperbolic framing but this looks like another case study of vibe porting, this time spinning up a new custom Go implementation of the JSONata JSON expression language - similar in focus to jq, and heavily associated with the Node-RED platform.
As with other vibe-porting projects the key enabling factor was JSONata's existing test suite, which helped build the first working Go version in 7 hours and $400 of token spend.
The Reco team then used a shadow deployment for a week to run the new and old versions in parallel to confirm the new implementation exactly matched the behavior of the old one.
Vibe coding SwiftUI apps is a lot of fun
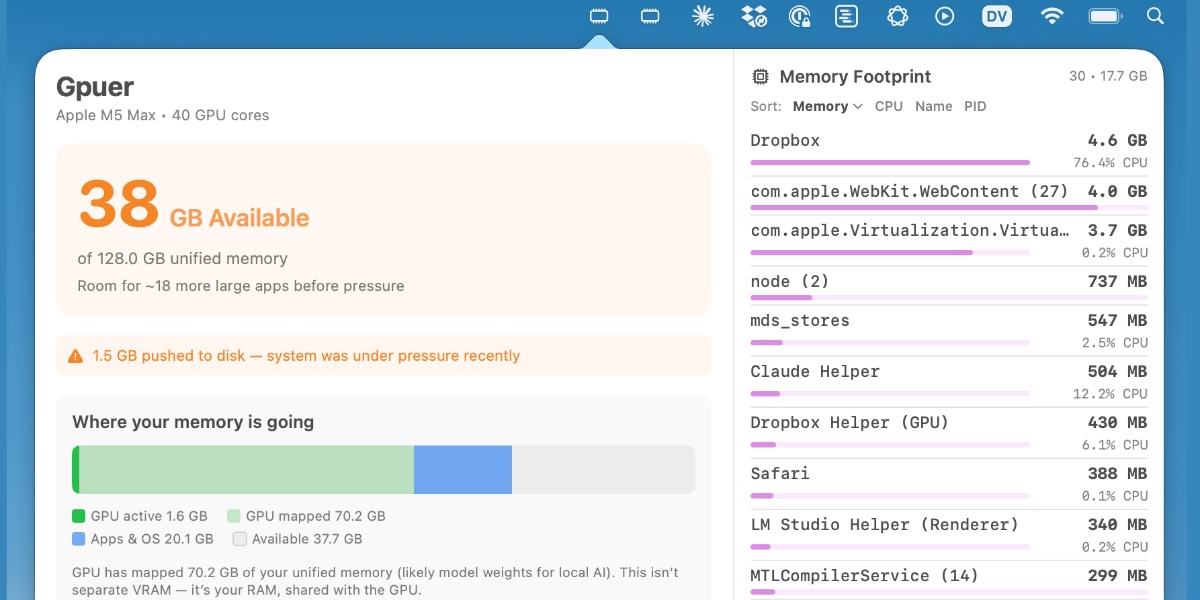
I have a new laptop—a 128GB M5 MacBook Pro, which early impressions show to be very capable for running good local LLMs. I got frustrated with Activity Monitor and decided to vibe code up some alternative tools for monitoring performance and I’m very happy with the results.
[... 1,195 words]FWIW, IANDBL, TINLA, etc., I don’t currently see any basis for concluding that chardet 7.0.0 is required to be released under the LGPL. AFAIK no one including Mark Pilgrim has identified persistence of copyrightable expressive material from earlier versions in 7.0.0 nor has anyone articulated some viable alternate theory of license violation. [...]
— Richard Fontana, LGPLv3 co-author, weighing in on the chardet relicensing situation
I added an option to export a Markdown file from my app that lets Showboat incrementally publish updates to a remote server.
March 28, 2026
The thing about agentic coding is that agents grind problems into dust. Give an agent a problem and a while loop and - long term - it’ll solve that problem even if it means burning a trillion tokens and re-writing down to the silicon. [...]
But we want AI agents to solve coding problems quickly and in a way that is maintainable and adaptive and composable (benefiting from improvements elsewhere), and where every addition makes the whole stack better.
So at the bottom is really great libraries that encapsulate hard problems, with great interfaces that make the “right” way the easy way for developers building apps with them. Architecture!
While I’m vibing (I call it vibing now, not coding and not vibe coding) while I’m vibing, I am looking at lines of code less than ever before, and thinking about architecture more than ever before.
— Matt Webb, An appreciation for (technical) architecture
March 29, 2026
Pretext (via) Exciting new browser library from Cheng Lou, previously a React core developer and the original creator of the react-motion animation library.
Pretext solves the problem of calculating the height of a paragraph of line-wrapped text without touching the DOM. The usual way of doing this is to render the text and measure its dimensions, but this is extremely expensive. Pretext uses an array of clever tricks to make this much, much faster, which enables all sorts of new text rendering effects in browser applications.
Here's one demo that shows the kind of things this makes possible:
The key to how this works is the way it separates calculations into a call to a prepare() function followed by multiple calls to layout().
The prepare() function splits the input text into segments (effectively words, but it can take things like soft hyphens and non-latin character sequences and emoji into account as well) and measures those using an off-screen canvas, then caches the results. This is comparatively expensive but only runs once.
The layout() function can then emulate the word-wrapping logic in browsers to figure out how many wrapped lines the text will occupy at a specified width and measure the overall height.
I had Claude build me this interactive artifact to help me visually understand what's going on, based on a simplified version of Pretext itself.
The way this is tested is particularly impressive. The earlier tests rendered a full copy of the Great Gatsby in multiple browsers to confirm that the estimated measurements were correct against a large volume of text. This was later joined by the corpora/ folder using the same technique against lengthy public domain documents in Thai, Chinese, Korean, Japanese, Arabic, and more.
Cheng Lou says:
The engine’s tiny (few kbs), aware of browser quirks, supports all the languages you’ll need, including Korean mixed with RTL Arabic and platform-specific emojis
This was achieved through showing Claude Code and Codex the browsers ground truth, and have them measure & iterate against those at every significant container width, running over weeks
March 30, 2026
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
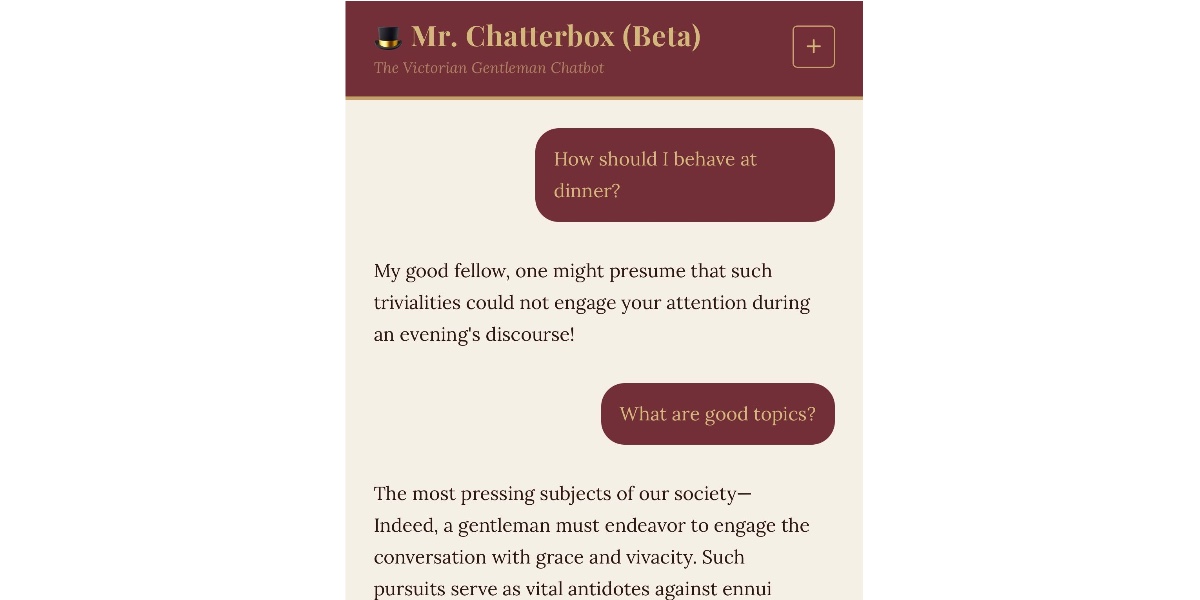
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]Adds the ability to configure which LLMs are available for which purpose, which means you can restrict the list of models that can be used with a specific plugin. #3
Note that the main issues that people currently unknowingly face with local models mostly revolve around the harness and some intricacies around model chat templates and prompt construction. Sometimes there are even pure inference bugs. From typing the task in the client to the actual result, there is a long chain of components that atm are not only fragile - are also developed by different parties. So it's difficult to consolidate the entire stack and you have to keep in mind that what you are currently observing is with very high probability still broken in some subtle way along that chain.
— Georgi Gerganov, explaining why it's hard to find local models that work well with coding agents
I'm working on integrating datasette-files into other plugins, such as datasette-extract. This necessitated a new release of the base plugin.
owners_can_editandowners_can_deleteconfiguration options, plus thefiles-editandfiles-deleteactions are now scoped to a newFileResourcewhich is a child ofFileSourceResource. #18- The file picker UI is now available as a
<datasette-file-picker>Web Component. Thanks, Alex Garcia. #19- New
from datasette_files import get_filePython API for other plugins that need to access file data. #20
March 31, 2026
- Mechanisms for testing tool calls. #3
- Mechanism for testing raw responses. #4
- New
echo-needs-keymodel for testing model key logic. #7
- Prompts now have the
input_tokensandoutput_tokensfields populated on the response.
- The register_models() plugin hook now takes an optional
model_aliasesparameter listing all of the models, async models and aliases that have been registered so far by other plugins. A plugin with@hookimpl(trylast=True)can use this to take previously registered models into account. #1389- Added docstrings to public classes and methods and included those directly in the documentation.
LLM plugins can define new models in both sync and async varieties. The async variants are most common for API-backed models - sync variants tend to be things that run the model directly within the plugin.
My llm-mrchatterbox plugin is sync only. I wanted to try it out with various Datasette LLM features (specifically datasette-enrichments-llm) but Datasette can only use async models.
So... I had Claude spin up this plugin that turns sync models into async models using a thread pool. This ended up needing an extra plugin hook mechanism in LLM itself, which I shipped just now in LLM 0.30.
- Ability to configure different API keys for models based on their purpose - for example, set it up so enrichments always use
gpt-5.4-miniwith an API key dedicated to that purpose. #4
I released llm-echo 0.3 to provide an API key testing utility I needed for the tests for this new feature.
Supply Chain Attack on Axios Pulls Malicious Dependency from npm
(via)
Useful writeup of today's supply chain attack against Axios, the HTTP client NPM package with 101 million weekly downloads. Versions 1.14.1 and 0.30.4 both included a new dependency called plain-crypto-js which was freshly published malware, stealing credentials and installing a remote access trojan (RAT).
It looks like the attack came from a leaked long-lived npm token. Axios have an open issue to adopt trusted publishing, which would ensure that only their GitHub Actions workflows are able to publish to npm. The malware packages were published without an accompanying GitHub release, which strikes me as a useful heuristic for spotting potentially malicious releases - the same pattern was present for LiteLLM last week as well.