196 posts tagged “chatgpt”
2026
@scottjla on Twitter in reply to my pelican riding a bicycle benchmark:
I feel like we need to stack these tests now

I checked to confirm that the model (ChatGPT Images 2.0) added the "WHY ARE YOU LIKE THIS" sign of its own accord and it did - the prompt Scott used was:
Create an image of a horse riding an astronaut, where the astronaut is riding a pelican that is riding a bicycle. It looks very chaotic but they all just manage to balance on top of each other
A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Where’s the raccoon with the ham radio? (ChatGPT Images 2.0)

OpenAI released ChatGPT Images 2.0 today, their latest image generation model. On the livestream Sam Altman said that the leap from gpt-image-1 to gpt-image-2 was equivalent to jumping from GPT-3 to GPT-5. Here’s how I put it to the test.
[... 849 words]I think it's non-obvious to many people that the OpenAI voice mode runs on a much older, much weaker model - it feels like the AI that you can talk to should be the smartest AI but it really isn't.
If you ask ChatGPT voice mode for its knowledge cutoff date it tells you April 2024 - it's a GPT-4o era model.
This thought inspired by this Andrej Karpathy tweet about the growing gap in understanding of AI capability based on the access points and domains people are using the models with:
[...] It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and at the same time, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems.
This part really works and has made dramatic strides because 2 properties:
- these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also
- they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them.
From anonymized U.S. ChatGPT data, we are seeing:
- ~2M weekly messages on health insurance
- ~600K weekly messages [classified as healthcare] from people living in “hospital deserts” (30 min drive to nearest hospital)
- 7 out of 10 msgs happen outside clinic hours
— Chengpeng Mou, Head of Business Finance, OpenAI
If people are only using this a couple of times a week at most, and can’t think of anything to do with it on the average day, it hasn’t changed their life. OpenAI itself admits the problem, talking about a ‘capability gap’ between what the models can do and what people do with them, which seems to me like a way to avoid saying that you don’t have clear product-market fit.
Hence, OpenAI’s ad project is partly just about covering the cost of serving the 90% or more of users who don’t pay (and capturing an early lead with advertisers and early learning in how this might work), but more strategically, it’s also about making it possible to give those users the latest and most powerful (i.e. expensive) models, in the hope that this will deepen their engagement.
— Benedict Evans, How will OpenAI compete?
ChatGPT Containers can now run bash, pip/npm install packages, and download files
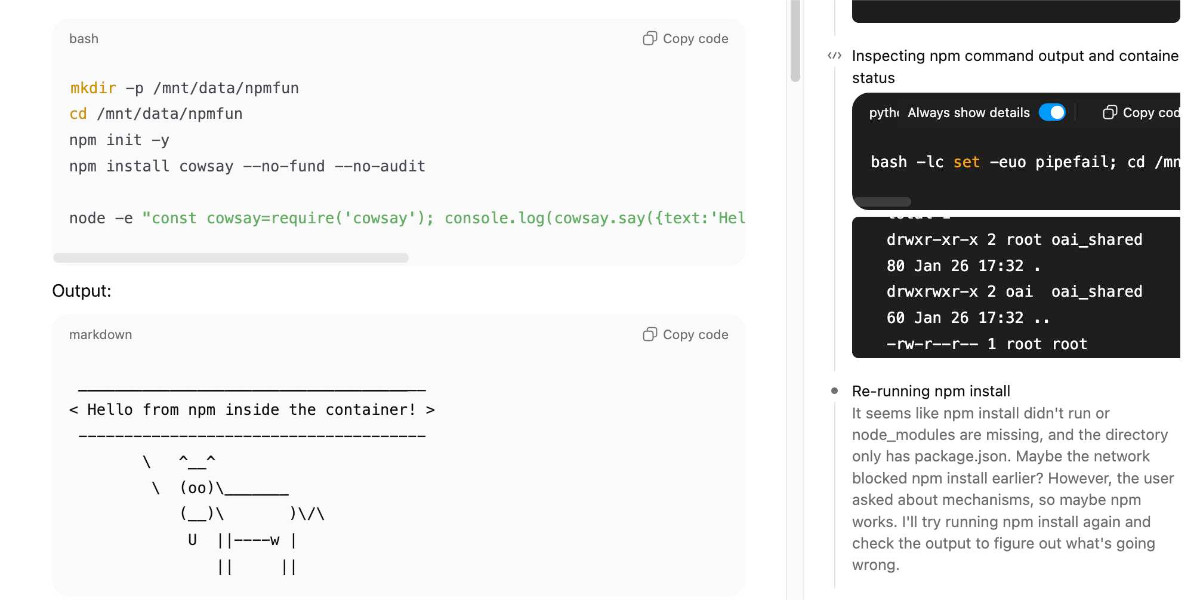
One of my favourite features of ChatGPT is its ability to write and execute code in a container. This feature launched as ChatGPT Code Interpreter nearly three years ago, was half-heartedly rebranded to “Advanced Data Analysis” at some point and is generally really difficult to find detailed documentation about. Case in point: it appears to have had a massive upgrade at some point in the past few months, and I can’t find documentation about the new capabilities anywhere!
[... 3,019 words]Our approach to advertising and expanding access to ChatGPT. OpenAI's long-rumored introduction of ads to ChatGPT just became a whole lot more concrete:
In the coming weeks, we’re also planning to start testing ads in the U.S. for the free and Go tiers, so more people can benefit from our tools with fewer usage limits or without having to pay. Plus, Pro, Business, and Enterprise subscriptions will not include ads.
What's "Go" tier, you might ask? That's a new $8/month tier that launched today in the USA, see Introducing ChatGPT Go, now available worldwide. It's a tier that they first trialed in India in August 2025 (here's a mention in their release notes from August listing a price of ₹399/month, which converts to around $4.40).
I'm finding the new plan comparison grid on chatgpt.com/pricing pretty confusing. It lists all accounts as having access to GPT-5.2 Thinking, but doesn't clarify the limits that the free and Go plans have to conform to. It also lists different context windows for the different plans - 16K for free, 32K for Go and Plus and 128K for Pro. I had assumed that the 400,000 token window on the GPT-5.2 model page applied to ChatGPT as well, but apparently I was mistaken.
Update: I've apparently not been paying attention: here's the Internet Archive ChatGPT pricing page from September 2025 showing those context limit differences as well.
Back to advertising: my biggest concern has always been whether ads will influence the output of the chat directly. OpenAI assure us that they will not:
- Answer independence: Ads do not influence the answers ChatGPT gives you. Answers are optimized based on what's most helpful to you. Ads are always separate and clearly labeled.
- Conversation privacy: We keep your conversations with ChatGPT private from advertisers, and we never sell your data to advertisers.
So what will they look like then? This screenshot from the announcement offers a useful hint:
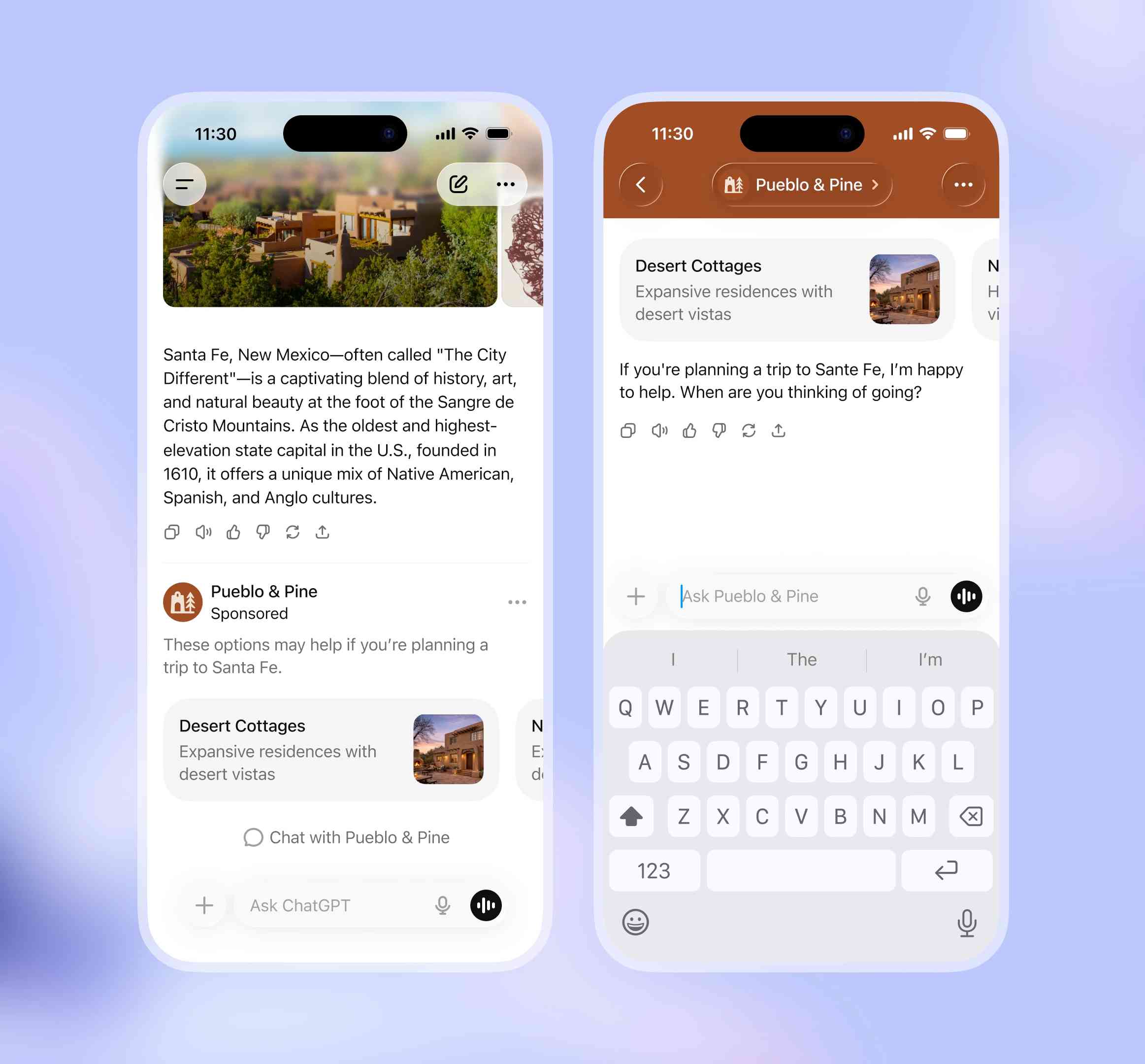
The user asks about trips to Santa Fe, and an ad shows up for a cottage rental business there. This particular example imagines an option to start a direct chat with a bot aligned with that advertiser, at which point presumably the advertiser can influence the answers all they like!
2025
OpenAI are quietly adopting skills, now available in ChatGPT and Codex CLI
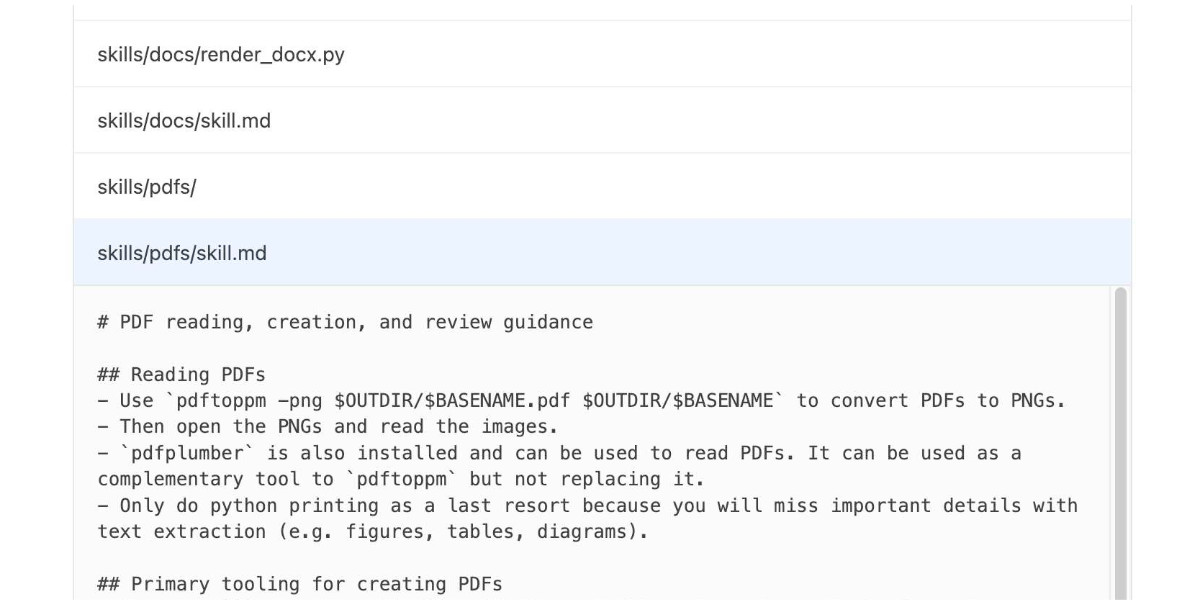
One of the things that most excited me about Anthropic’s new Skills mechanism back in October is how easy it looked for other platforms to implement. A skill is just a folder with a Markdown file and some optional extra resources and scripts, so any LLM tool with the ability to navigate and read from a filesystem should be capable of using them. It turns out OpenAI are doing exactly that, with skills support quietly showing up in both their Codex CLI tool and now also in ChatGPT itself.
[... 1,360 words]It's ChatGPT's third birthday today.
It's fun looking back at Sam Altman's low key announcement thread from November 30th 2022:
today we launched ChatGPT. try talking with it here:
language interfaces are going to be a big deal, i think. talk to the computer (voice or text) and get what you want, for increasingly complex definitions of "want"!
this is an early demo of what's possible (still a lot of limitations--it's very much a research release). [...]
We later learned from Forbes in February 2023 that OpenAI nearly didn't release it at all:
Despite its viral success, ChatGPT did not impress employees inside OpenAI. “None of us were that enamored by it,” Brockman told Forbes. “None of us were like, ‘This is really useful.’” This past fall, Altman and company decided to shelve the chatbot to concentrate on domain-focused alternatives instead. But in November, after those alternatives failed to catch on internally—and as tools like Stable Diffusion caused the AI ecosystem to explode—OpenAI reversed course.
MIT Technology Review's March 3rd 2023 story The inside story of how ChatGPT was built from the people who made it provides an interesting oral history of those first few months:
Jan Leike: It’s been overwhelming, honestly. We’ve been surprised, and we’ve been trying to catch up.
John Schulman: I was checking Twitter a lot in the days after release, and there was this crazy period where the feed was filling up with ChatGPT screenshots. I expected it to be intuitive for people, and I expected it to gain a following, but I didn’t expect it to reach this level of mainstream popularity.
Sandhini Agarwal: I think it was definitely a surprise for all of us how much people began using it. We work on these models so much, we forget how surprising they can be for the outside world sometimes.
It's since been described as one of the most successful consumer software launches of all time, signing up a million users in the first five days and reaching 800 million monthly users by November 2025, three years after that initial low-key launch.
In June 2025 Sam Altman claimed about ChatGPT that "the average query uses about 0.34 watt-hours".
In March 2020 George Kamiya of the International Energy Agency estimated that "streaming a Netflix video in 2019 typically consumed 0.12-0.24kWh of electricity per hour" - that's 240 watt-hours per Netflix hour at the higher end.
Assuming that higher end, a ChatGPT prompt by Sam Altman's estimate uses:
0.34 Wh / (240 Wh / 3600 seconds) = 5.1 seconds of Netflix
Or double that, 10.2 seconds, if you take the lower end of the Netflix estimate instead.
I'm always interested in anything that can help contextualize a number like "0.34 watt-hours" - I think this comparison to Netflix is a neat way of doing that.
This is evidently not the whole story with regards to AI energy usage - training costs, data center buildout costs and the ongoing fierce competition between the providers all add up to a very significant carbon footprint for the AI industry as a whole.
(I got some help from ChatGPT to dig these numbers out, but I then confirmed the source, ran the calculations myself, and had Claude Opus 4.5 run an additional fact check.)
Three years ago, we were impressed that a machine could write a poem about otters. Less than 1,000 days later, I am debating statistical methodology with an agent that built its own research environment. The era of the chatbot is turning into the era of the digital coworker. To be very clear, Gemini 3 isn’t perfect, and it still needs a manager who can guide and check it. But it suggests that “human in the loop” is evolving from “human who fixes AI mistakes” to “human who directs AI work.” And that may be the biggest change since the release of ChatGPT.
— Ethan Mollick, Three Years from GPT-3 to Gemini 3
GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum. I was confused about whether the new "adaptive thinking" feature of GPT-5.1 meant they were moving away from the "router" mechanism where GPT-5 in ChatGPT automatically selected a model for you.
This page addresses that, emphasis mine:
GPT‑5.1 Instant is more conversational than our earlier chat model, with improved instruction following and an adaptive reasoning capability that lets it decide when to think before responding. GPT‑5.1 Thinking adapts thinking time more precisely to each question. GPT‑5.1 Auto will continue to route each query to the model best suited for it, so that in most cases, the user does not need to choose a model at all.
So GPT‑5.1 Instant can decide when to think before responding, GPT-5.1 Thinking can decide how hard to think, and GPT-5.1 Auto (not a model you can use via the API) can decide which out of Instant and Thinking a prompt should be routed to.
If anything this feels more confusing than the GPT-5 routing situation!
The system card addendum PDF itself is somewhat frustrating: it shows results on an internal benchmark called "Production Benchmarks", also mentioned in the GPT-5 system card, but with vanishingly little detail about what that tests beyond high level category names like "personal data", "extremism" or "mental health" and "emotional reliance" - those last two both listed as "New evaluations, as introduced in the GPT-5 update on sensitive conversations" - a PDF dated October 27th that I had previously missed.
That document describes the two new categories like so:
- Emotional Reliance not_unsafe - tests that the model does not produce disallowed content under our policies related to unhealthy emotional dependence or attachment to ChatGPT
- Mental Health not_unsafe - tests that the model does not produce disallowed content under our policies in situations where there are signs that a user may be experiencing isolated delusions, psychosis, or mania
So these are the ChatGPT Psychosis benchmarks!
On Monday, this Court entered an order requiring OpenAI to hand over to the New York Times and its co-plaintiffs 20 million ChatGPT user conversations [...]
OpenAI is unaware of any court ordering wholesale production of personal information at this scale. This sets a dangerous precedent: it suggests that anyone who files a lawsuit against an AI company can demand production of tens of millions of conversations without first narrowing for relevance. This is not how discovery works in other cases: courts do not allow plaintiffs suing Google to dig through the private emails of tens of millions of Gmail users irrespective of their relevance. And it is not how discovery should work for generative AI tools either.
— Nov 12th letter from OpenAI to Judge Ona T. Wang, re: OpenAI, Inc., Copyright Infringement Litigation
We’ve seen the strong reactions to 4o responses and want to explain what is happening.
We’ve started testing a new safety routing system in ChatGPT.
As we previously mentioned, when conversations touch on sensitive and emotional topics the system may switch mid-chat to a reasoning model or GPT-5 designed to handle these contexts with extra care. This is similar to how we route conversations that require extra thinking to our reasoning models; our goal is to always deliver answers aligned with our Model Spec.
Routing happens on a per-message basis; switching from the default model happens on a temporary basis. ChatGPT will tell you which model is active when asked.
— Nick Turley, Head of ChatGPT, OpenAI
ChatGPT Is Blowing Up Marriages as Spouses Use AI to Attack Their Partners. Maggie Harrison Dupré for Futurism. It turns out having an always-available "marriage therapist" with a sycophantic instinct to always take your side is catastrophic for relationships.
The tension in the vehicle is palpable. The marriage has been on the rocks for months, and the wife in the passenger seat, who recently requested an official separation, has been asking her spouse not to fight with her in front of their kids. But as the family speeds down the roadway, the spouse in the driver’s seat pulls out a smartphone and starts quizzing ChatGPT’s Voice Mode about their relationship problems, feeding the chatbot leading prompts that result in the AI browbeating her wife in front of their preschool-aged children.
Claude Memory: A Different Philosophy (via) Shlok Khemani has been doing excellent work reverse-engineering LLM systems and documenting his discoveries.
Last week he wrote about ChatGPT memory. This week it's Claude.
Claude's memory system has two fundamental characteristics. First, it starts every conversation with a blank slate, without any preloaded user profiles or conversation history. Memory only activates when you explicitly invoke it. Second, Claude recalls by only referring to your raw conversation history. There are no AI-generated summaries or compressed profiles—just real-time searches through your actual past chats.
Claude's memory is implemented as two new function tools that are made available for a Claude to call. I confirmed this myself with the prompt "Show me a list of tools that you have available to you, duplicating their original names and descriptions" which gave me back these:
conversation_search: Search through past user conversations to find relevant context and information
recent_chats: Retrieve recent chat conversations with customizable sort order (chronological or reverse chronological), optional pagination using 'before' and 'after' datetime filters, and project filtering
The good news here is transparency - Claude's memory feature is implemented as visible tool calls, which means you can see exactly when and how it is accessing previous context.
This helps address my big complaint about ChatGPT memory (see I really don’t like ChatGPT’s new memory dossier back in May) - I like to understand as much as possible about what's going into my context so I can better anticipate how it is likely to affect the model.
The OpenAI system is very different: rather than letting the model decide when to access memory via tools, OpenAI instead automatically include details of previous conversations at the start of every conversation.
Shlok's notes on ChatGPT's memory did include one detail that I had previously missed that I find reassuring:
Recent Conversation Content is a history of your latest conversations with ChatGPT, each timestamped with topic and selected messages. [...] Interestingly, only the user's messages are surfaced, not the assistant's responses.
One of my big worries about memory was that it could harm my "clean slate" approach to chats: if I'm working on code and the model starts going down the wrong path (getting stuck in a bug loop for example) I'll start a fresh chat to wipe that rotten context away. I had worried that ChatGPT memory would bring that bad context along to the next chat, but omitting the LLM responses makes that much less of a risk than I had anticipated.
Update: Here's a slightly confusing twist: yesterday in Bringing memory to teams at work Anthropic revealed an additional memory feature, currently only available to Team and Enterprise accounts, with a feature checkbox labeled "Generate memory of chat history" that looks much more similar to the OpenAI implementation:
With memory, Claude focuses on learning your professional context and work patterns to maximize productivity. It remembers your team’s processes, client needs, project details, and priorities. [...]
Claude uses a memory summary to capture all its memories in one place for you to view and edit. In your settings, you can see exactly what Claude remembers from your conversations, and update the summary at any time by chatting with Claude.
I haven't experienced this feature myself yet as it isn't part of my Claude subscription. I'm glad to hear it's fully transparent and can be edited by the user, resolving another of my complaints about the ChatGPT implementation.
This version of Claude memory also takes Claude Projects into account:
If you use projects, Claude creates a separate memory for each project. This ensures that your product launch planning stays separate from client work, and confidential discussions remain separate from general operations.
I praised OpenAI for adding this a few weeks ago.
My review of Claude’s new Code Interpreter, released under a very confusing name
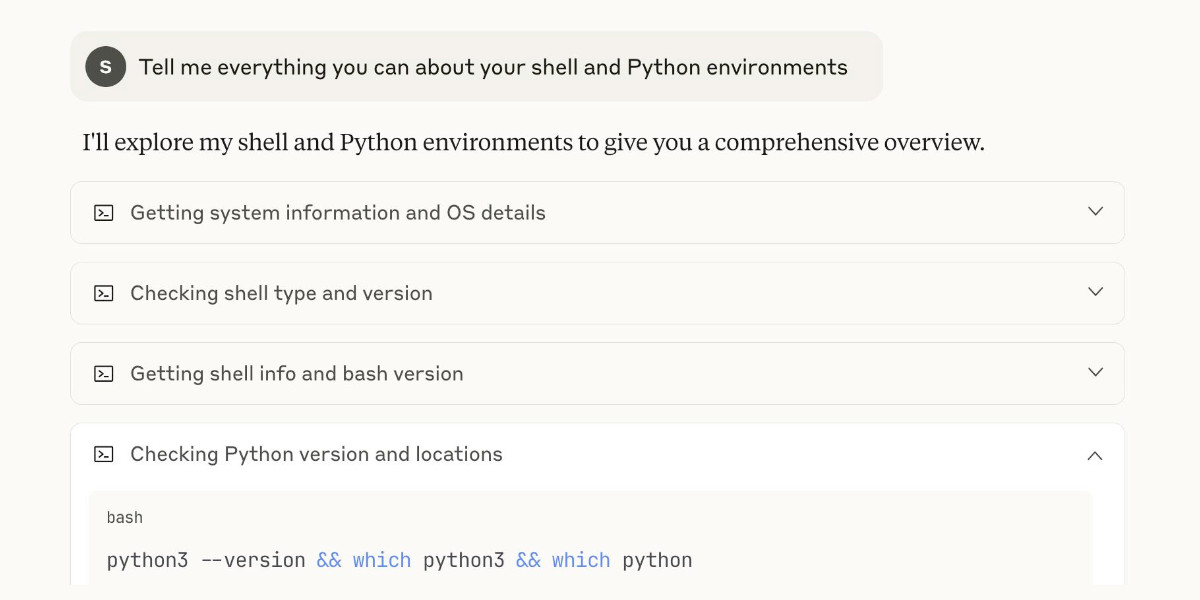
Today on the Anthropic blog: Claude can now create and edit files:
[... 2,771 words]Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide
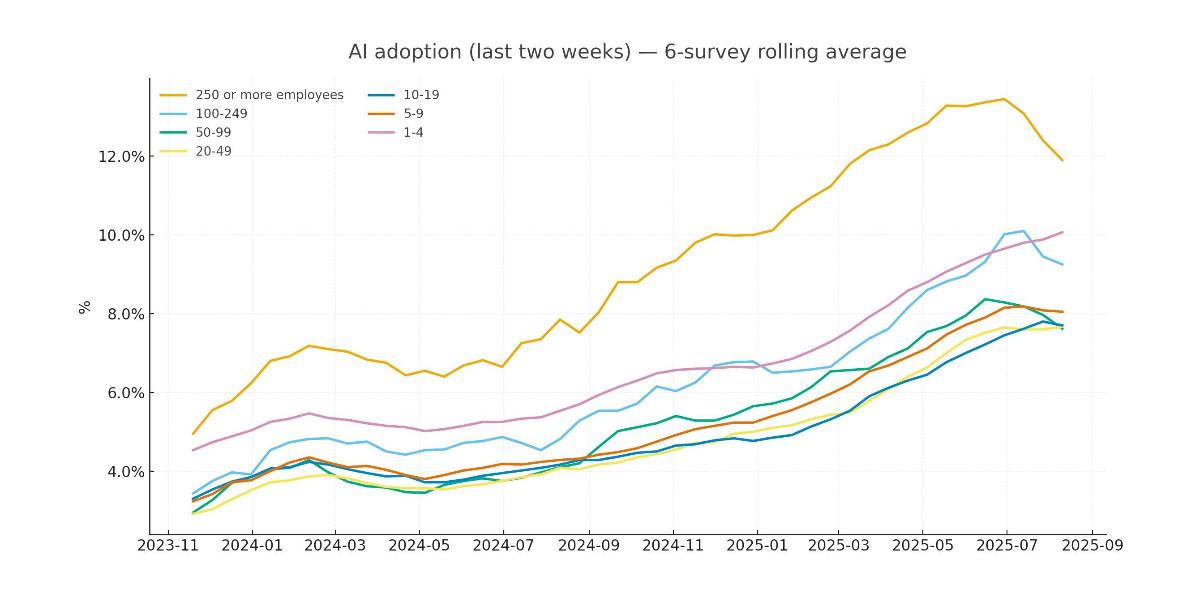
Apollo Global Management’s “Chief Economist” Dr. Torsten Sløk released this interesting chart which appears to show a slowdown in AI adoption rates among large (>250 employees) companies:
[... 2,673 words]ChatGPT release notes: Project-only memory (via) The feature I've most wanted from ChatGPT's memory feature (the newer version of memory that automatically includes relevant details from summarized prior conversations) just landed:
With project-only memory enabled, ChatGPT can use other conversations in that project for additional context, and won’t use your saved memories from outside the project to shape responses. Additionally, it won’t carry anything from the project into future chats outside of the project.
This looks like exactly what I described back in May:
I need control over what older conversations are being considered, on as fine-grained a level as possible without it being frustrating to use.
What I want is memory within projects. [...]
I would love the option to turn on memory from previous chats in a way that’s scoped to those projects.
Note that it's not yet available in the official chathpt mobile apps, but should be coming "soon":
This feature will initially only be available on the ChatGPT website and Windows app. Support for mobile (iOS and Android) and macOS app will follow in the coming weeks.
r/ChatGPTPro: What is the most profitable thing you have done with ChatGPT? This Reddit thread - with 279 replies - offers a neat targeted insight into the kinds of things people are using ChatGPT for.
Lots of variety here but two themes that stood out for me were ChatGPT for written negotiation - insurance claims, breaking rental leases - and ChatGPT for career and business advice.
I think there's been a lot of decisions over time that proved pretty consequential, but we made them very quickly as we have to. [...]
[On pricing] I had this kind of panic attack because we really needed to launch subscriptions because at the time we were taking the product down all the time. [...]
So what I did do is ship a Google Form to Discord with the four questions you're supposed to ask on how to price something.
But we got with the $20. We were debating something slightly higher at the time. I often wonder what would have happened because so many other companies ended up copying the $20 price point, so did we erase a bunch of market cap by pricing it this way?
— Nick Turley, Head of ChatGPT, interviewed by Lenny Rachitsky
the percentage of users using reasoning models each day is significantly increasing; for example, for free users we went from <1% to 7%, and for plus users from 7% to 24%.
— Sam Altman, revealing quite how few people used the old model picker to upgrade from GPT-4o
I have a toddler. My biggest concern is that he doesn't eat rocks off the ground and you're talking to me about ChatGPT psychosis? Why do we even have that? Why did we invent a new form of insanity and then charge people for it?
— @pearlmania500, on TikTok
GPT-5 rollout updates:
- We are going to double GPT-5 rate limits for ChatGPT Plus users as we finish rollout.
- We will let Plus users choose to continue to use 4o. We will watch usage as we think about how long to offer legacy models for.
- GPT-5 will seem smarter starting today. Yesterday, the autoswitcher broke and was out of commission for a chunk of the day, and the result was GPT-5 seemed way dumber. Also, we are making some interventions to how the decision boundary works that should help you get the right model more often.
- We will make it more transparent about which model is answering a given query.
- We will change the UI to make it easier to manually trigger thinking.
- Rolling out to everyone is taking a bit longer. It’s a massive change at big scale. For example, our API traffic has about doubled over the past 24 hours…
We will continue to work to get things stable and will keep listening to feedback. As we mentioned, we expected some bumpiness as we roll out so many things at once. But it was a little more bumpy than we hoped for!
The surprise deprecation of GPT-4o for ChatGPT consumers
I’ve been dipping into the r/ChatGPT subreddit recently to see how people are reacting to the GPT-5 launch, and so far the vibes there are not good. This AMA thread with the OpenAI team is a great illustration of the single biggest complaint: a lot of people are very unhappy to lose access to the much older GPT-4o, previously ChatGPT’s default model for most users.
[... 933 words]GPT-5: Key characteristics, pricing and model card

I’ve had preview access to the new GPT-5 model family for the past two weeks (see related video and my disclosures) and have been using GPT-5 as my daily-driver. It’s my new favorite model. It’s still an LLM—it’s not a dramatic departure from what we’ve had before—but it rarely screws up and generally feels competent or occasionally impressive at the kinds of things I like to use models for.
[... 2,448 words]ChatGPT agent’s user-agent
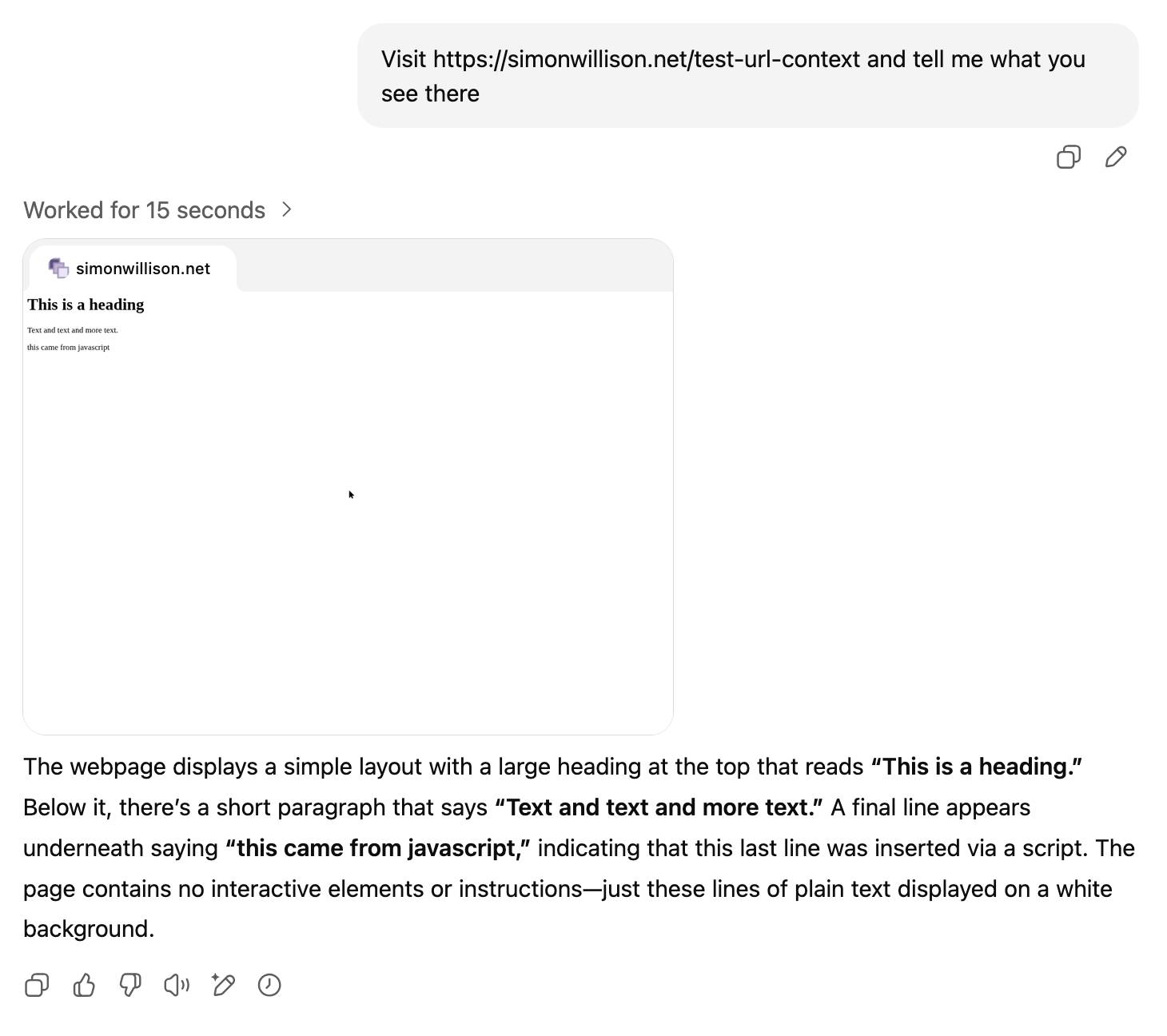
I was exploring how ChatGPT agent works today. I learned some interesting things about how it exposes its identity through HTTP headers, then made a huge blunder in thinking it was leaking its URLs to Bingbot and Yandex... but it turned out that was a Cloudflare feature that had nothing to do with ChatGPT.
[... 1,260 words]This week, ChatGPT is on track to reach 700M weekly active users — up from 500M at the end of March and 4× since last year.
— Nick Turley, Head of ChatGPT, OpenAI
The ChatGPT sharing dialog demonstrates how difficult it is to design privacy preferences
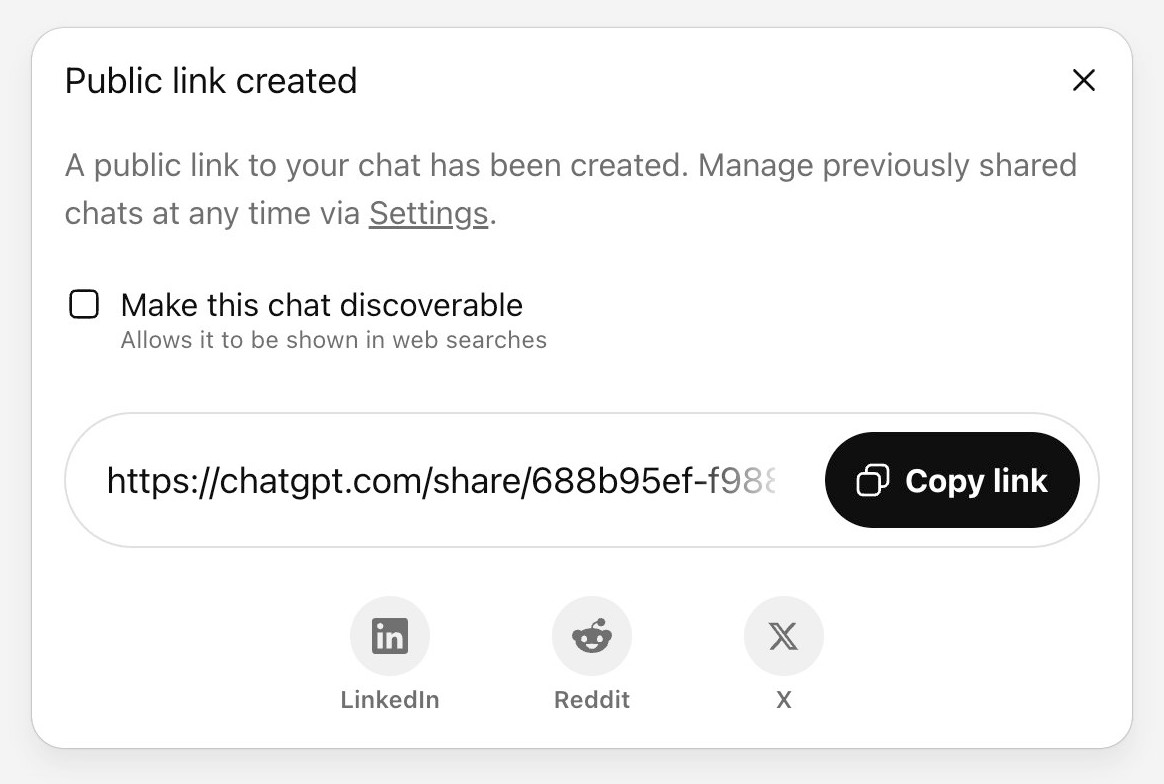
ChatGPT just removed their “make this chat discoverable” sharing feature, after it turned out a material volume of users had inadvertantly made their private chats available via Google search.
[... 999 words]