1,471 posts tagged “datasette”
Datasette is an open source tool for exploring and publishing data.
2026
- No longer requires Datasette - running
uvx datasette-portsnow works as well.- Installing it as a Datasette plugin continues to provide the
datasette portscommand.
Another example of README-driven development, this time solving a problem that might be unique to me.
I often find myself running a bunch of different Datasette instances with different databases and different in-development plugins, spreads across dozens of different terminal windows - enough that I frequently lose them!
Now I can run this:
datasette install datasette-ports
datasette ports
And get a list of every running instance that looks something like this:
http://127.0.0.1:8333/ - v1.0a26
Databases: data
Plugins: datasette-enrichments, datasette-enrichments-llm, datasette-llm, datasette-secrets
http://127.0.0.1:8001/ - v1.0a26
Databases: creatures
Plugins: datasette-extract, datasette-llm, datasette-secrets
http://127.0.0.1:8900/ - v0.65.2
Databases: logs
- The same model ID no longer needs to be repeated in both the default model and allowed models lists - setting it as a default model automatically adds it to the allowed models list. #6
- Improved documentation for Python API usage.
- The
actorwho triggers an enrichment is now passed to thellm.mode(... actor=actor)method. #3
- Now uses datasette-llm to manage model configuration, which means you can control which models are available for extraction tasks using the
extractpurpose and LLM model configuration. #38
- This plugin now uses datasette-llm to configure and manage models. This means it's possible to specify which models should be made available for enrichments, using the new
enrichmentspurpose.
- Removed features relating to allowances and estimated pricing. These are now the domain of datasette-llm-accountant.
- Now depends on datasette-llm for model configuration. #3
- Full prompts and responses and tool calls can now be logged to the
llm_usage_prompt_logtable in the internal database if you set the newdatasette-llm-usage.log_promptsplugin configuration setting.- Redesigned the
/-/llm-usage-simple-promptpage, which now requires thellm-usage-simple-promptpermission.
- The
llm_prompt_context()plugin hook wrapper mechanism now tracks prompts executed within a chain as well as one-off prompts, which means it can be used to track tool call loops. #5
- Ability to configure different API keys for models based on their purpose - for example, set it up so enrichments always use
gpt-5.4-miniwith an API key dedicated to that purpose. #4
I released llm-echo 0.3 to provide an API key testing utility I needed for the tests for this new feature.
I'm working on integrating datasette-files into other plugins, such as datasette-extract. This necessitated a new release of the base plugin.
owners_can_editandowners_can_deleteconfiguration options, plus thefiles-editandfiles-deleteactions are now scoped to a newFileResourcewhich is a child ofFileSourceResource. #18- The file picker UI is now available as a
<datasette-file-picker>Web Component. Thanks, Alex Garcia. #19- New
from datasette_files import get_filePython API for other plugins that need to access file data. #20
Adds the ability to configure which LLMs are available for which purpose, which means you can restrict the list of models that can be used with a specific plugin. #3
actoris now available to thellm_prompt_contextplugin hook. #2
A backend for datasette-files that adds the ability to store and retrieve files using an S3 bucket. This release added a mechanism for fetching S3 configuration periodically from a URL, which means we can use time limited IAM credentials that are restricted to a prefix within a bucket.
New release of the base plugin that makes models from LLM available for use by other Datasette plugins such as datasette-enrichments-llm.
- New
register_llm_purposes()plugin hook andget_purposes()function for retrieving registered purpose strings. #1
One of the responsibilities of this plugin is to configure which models are used for which purposes, so you can say in one place "data enrichment uses GPT-5.4-nano but SQL query assistance happens using Sonnet 4.6", for example.
Plugins that depend on this can use model = await llm.model(purpose="enrichment") to indicate the purpose of the prompts they wish to execute against the model. Those plugins can now also use the new register_llm_purposes() hook to register those purpose strings, which means future plugins can list those purposes in one place to power things like an admin UI for assigning models to purposes.
The most interesting alpha of datasette-files yet, a new plugin which adds the ability to upload files directly into a Datasette instance. Here are the release notes in full:
- Columns are now configured using the new column_types system from Datasette 1.0a26. #8
- New
file_actionsplugin hook, plus ability to import an uploaded CSV/TSV file to a table. #10- UI for uploading multiple files at once via the new documented JSON upload API. #11
- Thumbnails are now generated for image files and stored in an internal
datasette_files_thumbnailstable. #13
Coding agents for data analysis. Here's the handout I prepared for my NICAR 2026 workshop "Coding agents for data analysis" - a three hour session aimed at data journalists demonstrating ways that tools like Claude Code and OpenAI Codex can be used to explore, analyze and clean data.
Here's the table of contents:
I ran the workshop using GitHub Codespaces and OpenAI Codex, since it was easy (and inexpensive) to distribute a budget-restricted API key for Codex that attendees could use during the class. Participants ended up burning $23 of Codex tokens.
The exercises all used Python and SQLite and some of them used Datasette.
One highlight of the workshop was when we started running Datasette such that it served static content from a viz/ folder, then had Claude Code start vibe coding new interactive visualizations directly in that folder. Here's a heat map it created for my trees database using Leaflet and Leaflet.heat, source code here.

I designed the handout to also be useful for people who weren't able to attend the session in person. As is usually the case, material aimed at data journalists is equally applicable to anyone else with data to explore.
Two new Showboat tools: Chartroom and datasette-showboat
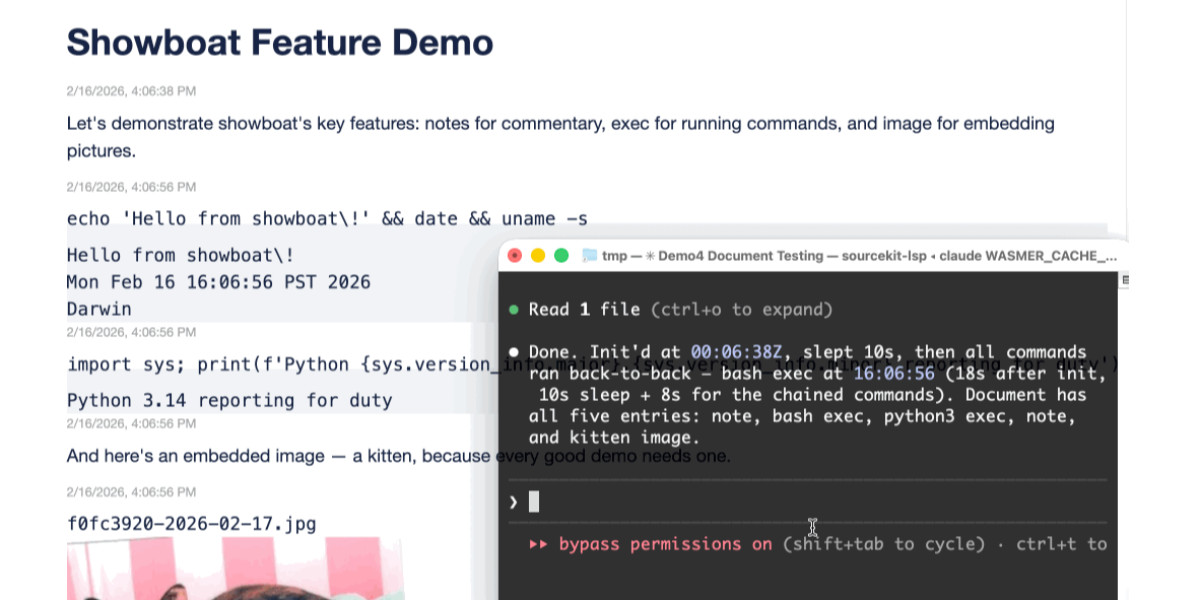
I introduced Showboat a week ago—my CLI tool that helps coding agents create Markdown documents that demonstrate the code that they have created. I’ve been finding new ways to use it on a daily basis, and I’ve just released two new tools to help get the best out of the Showboat pattern. Chartroom is a CLI charting tool that works well with Showboat, and datasette-showboat lets Showboat’s new remote publishing feature incrementally push documents to a Datasette instance.
[... 1,756 words]Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel
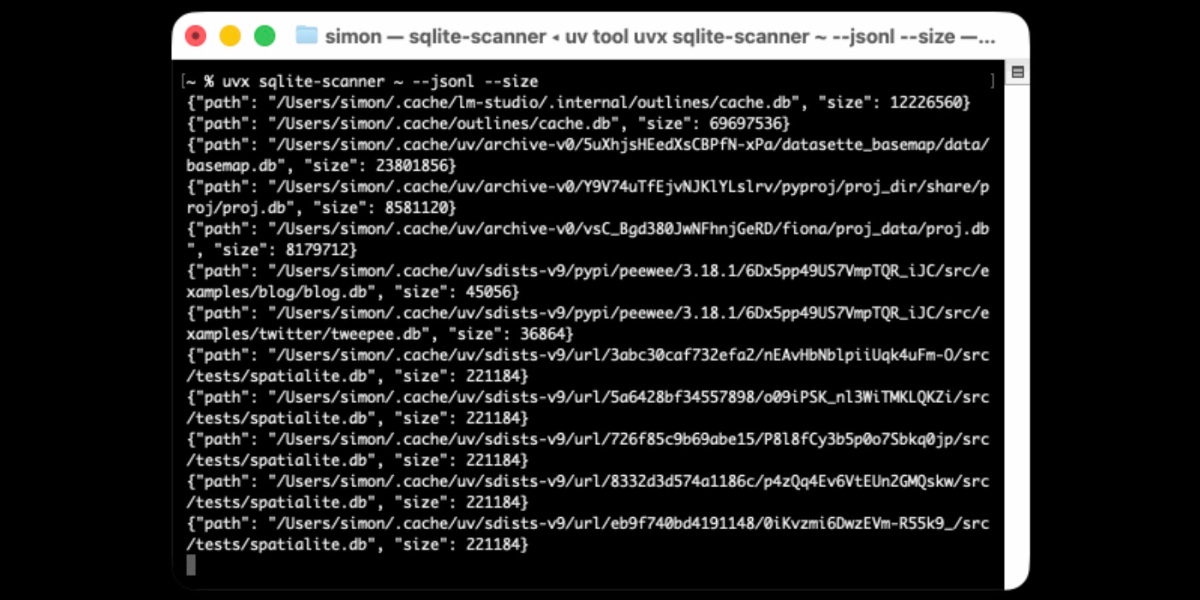
I’ve been exploring Go for building small, fast and self-contained binary applications recently. I’m enjoying how there’s generally one obvious way to do things and the resulting code is boring and readable—and something that LLMs are very competent at writing. The one catch is distribution, but it turns out publishing Go binaries to PyPI means any Go binary can be just a uvx package-name call away.
Introducing the Codex app. OpenAI just released a new macOS app for their Codex coding agent. I've had a few days of preview access - it's a solid app that provides a nice UI over the capabilities of the Codex CLI agent and adds some interesting new features, most notably first-class support for Skills, and Automations for running scheduled tasks.
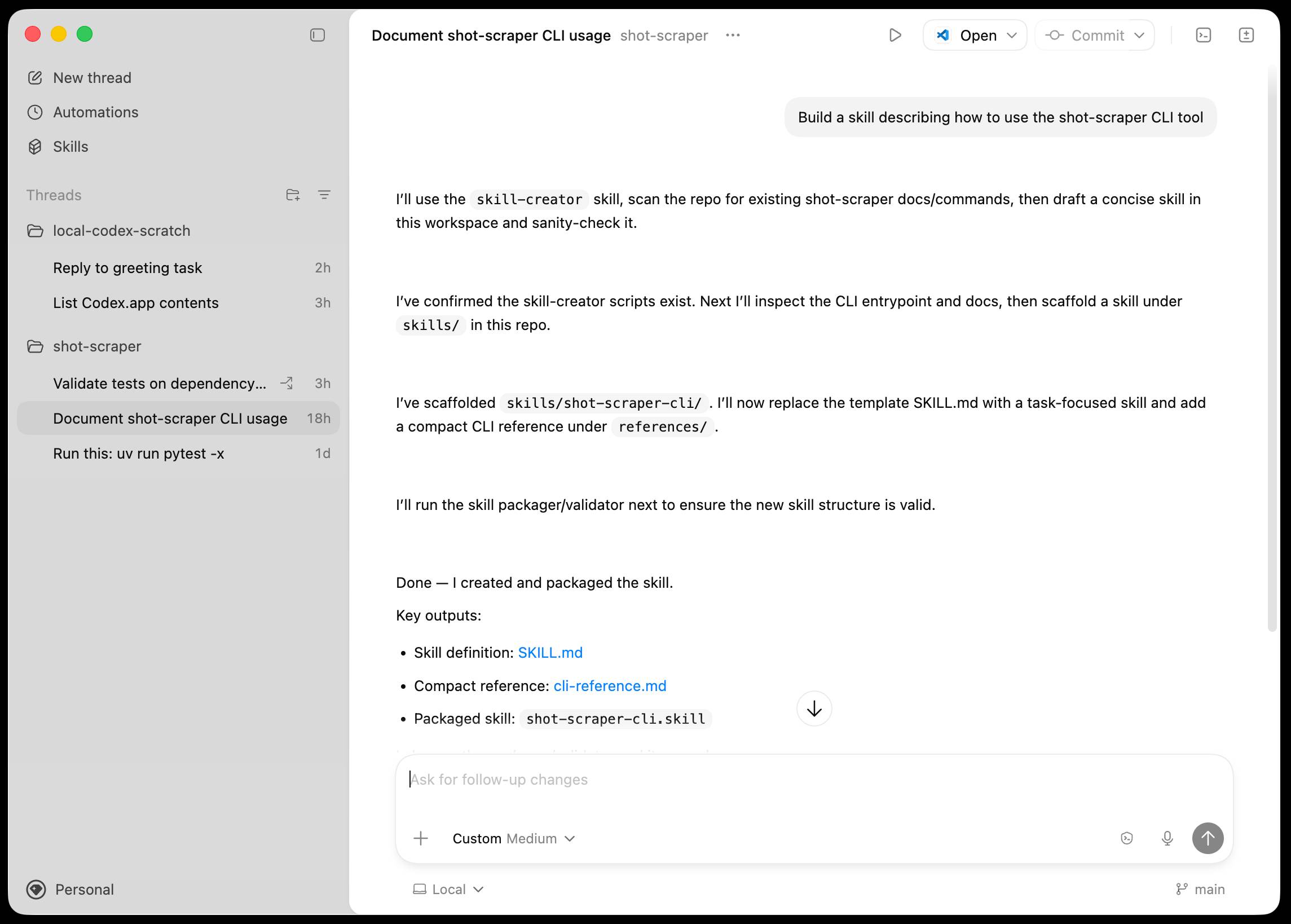
The app is built with Electron and Node.js. Automations track their state in a SQLite database - here's what that looks like if you explore it with uvx datasette ~/.codex/sqlite/codex-dev.db:

Here’s an interactive copy of that database in Datasette Lite.
The announcement gives us a hint at some usage numbers for Codex overall - the holiday spike is notable:
Since the launch of GPT‑5.2-Codex in mid-December, overall Codex usage has doubled, and in the past month, more than a million developers have used Codex.
Automations are currently restricted in that they can only run when your laptop is powered on. OpenAI promise that cloud-based automations are coming soon, which will resolve this limitation.
They chose Electron so they could target other operating systems in the future, with Windows “coming very soon”. OpenAI’s Alexander Embiricos noted on the Hacker News thread that:
it's taking us some time to get really solid sandboxing working on Windows, where there are fewer OS-level primitives for it.
Like Claude Code, Codex is really a general agent harness disguised as a tool for programmers. OpenAI acknowledge that here:
Codex is built on a simple premise: everything is controlled by code. The better an agent is at reasoning about and producing code, the more capable it becomes across all forms of technical and knowledge work. [...] We’ve focused on making Codex the best coding agent, which has also laid the foundation for it to become a strong agent for a broad range of knowledge work tasks that extend beyond writing code.
Claude Code had to rebrand to Cowork to better cover the general knowledge work case. OpenAI can probably get away with keeping the Codex name for both.
OpenAI have made Codex available to free and Go plans for "a limited time" (update: Sam Altman says two months) during which they are also doubling the rate limits for paying users.
Datasette 1.0a24. New Datasette alpha this morning. Key new features:
- Datasette's
Requestobject can now handlemultipart/form-datafile uploads via the new await request.form(files=True) method. I plan to use this for adatasette-filesplugin to support attaching files to rows of data. - The recommended development environment for hacking on Datasette itself now uses uv. Crucially, you can clone Datasette and run
uv run pytestto run the tests without needing to manually create a virtual environment or install dependencies first, thanks to the dev dependency group pattern. - A new
?_extra=render_cellparameter for both table and row JSON pages to return the results of executing the render_cell() plugin hook. This should unlock new JavaScript UI features in the future.
More details in the release notes. I also invested a bunch of work in eliminating flaky tests that were intermittently failing in CI - I think those are all handled now.