33 posts tagged “deepseek”
DeepSeek is an AI lab from Chinese hedge fund High-Flyer.
2024
DeepSeek_V3.pdf (via) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented model weights.
Plenty of interesting details in here. The model pre-trained on 14.8 trillion "high-quality and diverse tokens" (not otherwise documented).
Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
By far the most interesting detail though is how much the training cost. DeepSeek v3 trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. For comparison, Meta AI's Llama 3.1 405B (smaller than DeepSeek v3's 685B parameters) trained on 11x that - 30,840,000 GPU hours, also on 15 trillion tokens.
DeepSeek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now possible to train a frontier-class model (at least for the 2024 version of the frontier) for less than $6 million!
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
DeepSeek also announced their API pricing. From February 8th onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Claude 3.5 Sonnet is currently $3/million for input and $15/million for output, so if the models are indeed of equivalent quality this is a dramatic new twist in the ongoing LLM pricing wars.
deepseek-ai/DeepSeek-V3-Base (via) No model card or announcement yet, but this new model release from Chinese AI lab DeepSeek (an arm of Chinese hedge fund High-Flyer) looks very significant.
It's a huge model - 685B parameters, 687.9 GB on disk (TIL how to size a git-lfs repo). The architecture is a Mixture of Experts with 256 experts, using 8 per token.
For comparison, Meta AI's largest released model is their Llama 3.1 model with 405B parameters.
The new model is apparently available to some people via both chat.deepseek.com and the DeepSeek API as part of a staged rollout.
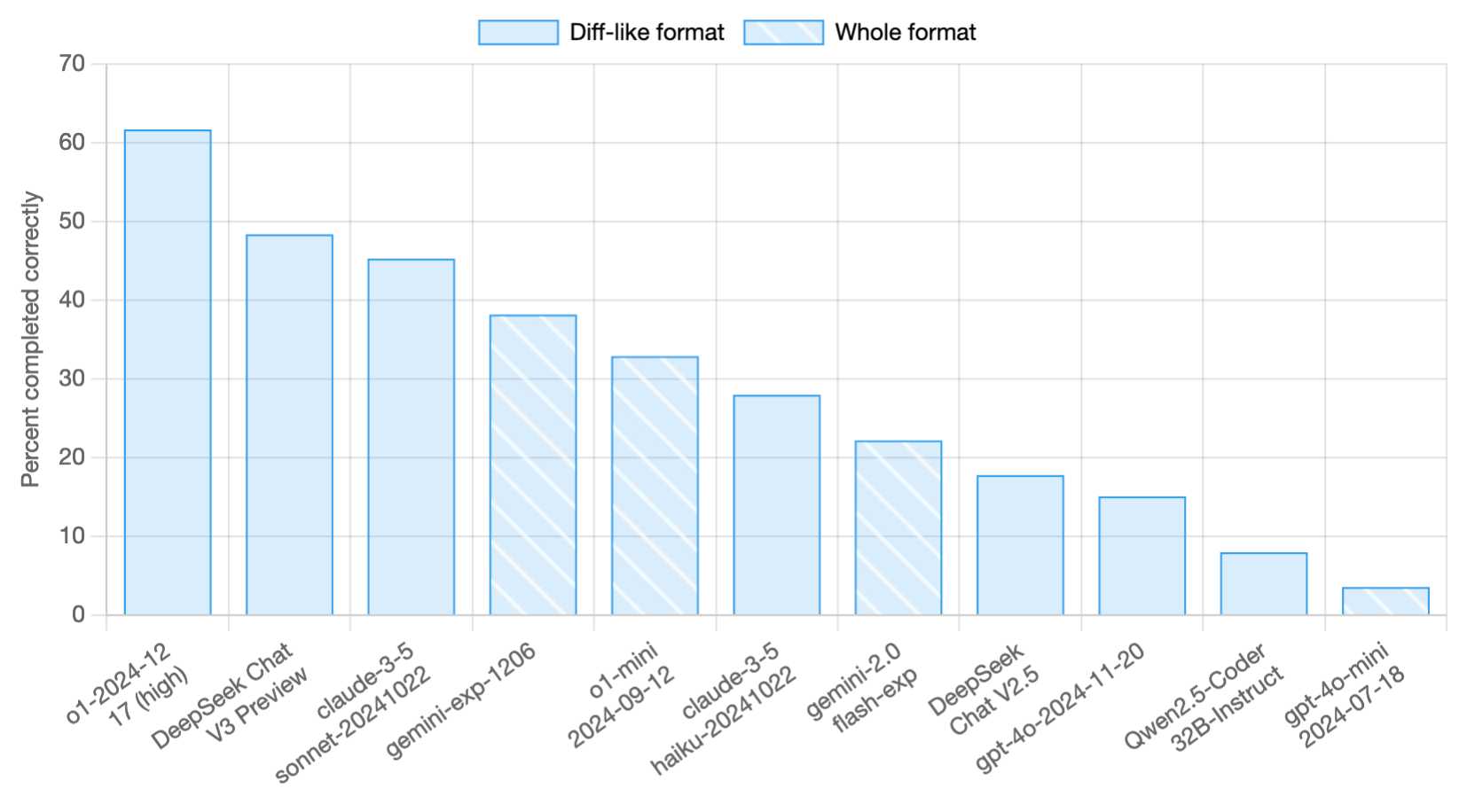
Paul Gauthier got API access and used it to update his new Aider Polyglot leaderboard - DeepSeek v3 preview scored 48.4%, putting it in second place behind o1-2024-12-17 (high) and in front of both claude-3-5-sonnet-20241022 and gemini-exp-1206!
I never know if I can believe models or not (the first time I asked "what model are you?" it claimed to be "based on OpenAI's GPT-4 architecture"), but I just got this result using LLM and the llm-deepseek plugin:
llm -m deepseek-chat 'what deepseek model are you?'
I'm DeepSeek-V3 created exclusively by DeepSeek. I'm an AI assistant, and I'm at your service! Feel free to ask me anything you'd like. I'll do my best to assist you.
Here's my initial experiment log.
DeepSeek API introduces Context Caching on Disk (via) I wrote about Claude prompt caching this morning. It turns out Chinese LLM lab DeepSeek released their own implementation of context caching a couple of weeks ago, with the simplest possible pricing model: it's just turned on by default for all users.
When duplicate inputs are detected, the repeated parts are retrieved from the cache, bypassing the need for recomputation. This not only reduces service latency but also significantly cuts down on overall usage costs.
For cache hits, DeepSeek charges $0.014 per million tokens, slashing API costs by up to 90%.
[...]
The disk caching service is now available for all users, requiring no code or interface changes. The cache service runs automatically, and billing is based on actual cache hits.
DeepSeek currently offer two frontier models, DeepSeek-V2 and DeepSeek-Coder-V2, both of which can be run as open weights models or accessed via their API.