68 items tagged “edge-llms”
LLMs that can run on consumer hardware like laptops or mobile phones.
2023
Ollama (via) This tool for running LLMs on your own laptop directly includes an installer for macOS (Apple Silicon) and provides a terminal chat interface for interacting with models. They already have Llama 2 support working, with a model that downloads directly from their own registry service without need to register for an account or work your way through a waiting list.
Accessing Llama 2 from the command-line with the llm-replicate plugin
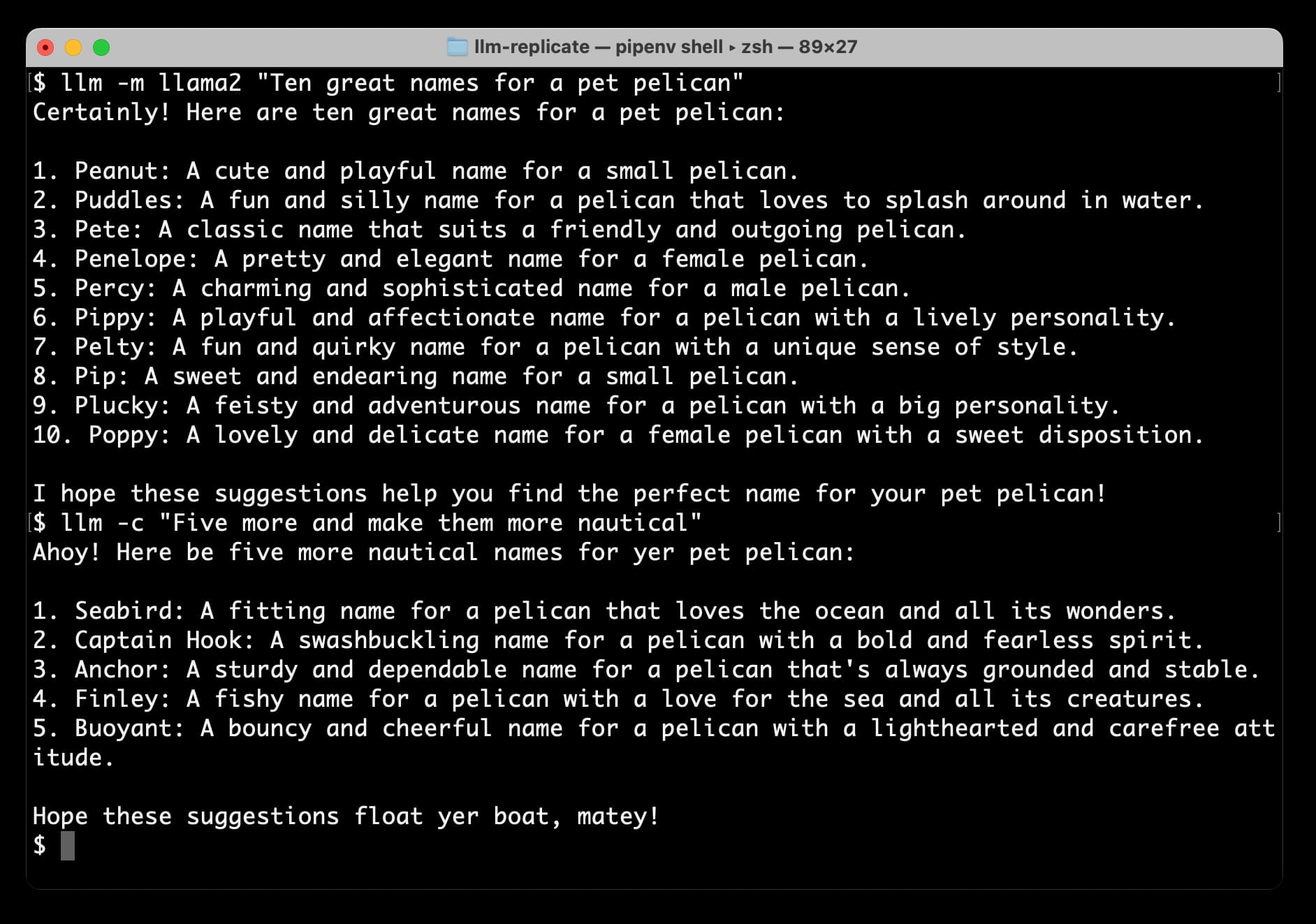
The big news today is Llama 2, the new openly licensed Large Language Model from Meta AI. It’s a really big deal:
[... 1,206 words]Weeknotes: Self-hosted language models with LLM plugins, a new Datasette tutorial, a dozen package releases, a dozen TILs
A lot of stuff to cover from the past two and a half weeks.
[... 1,742 words]My LLM CLI tool now supports self-hosted language models via plugins
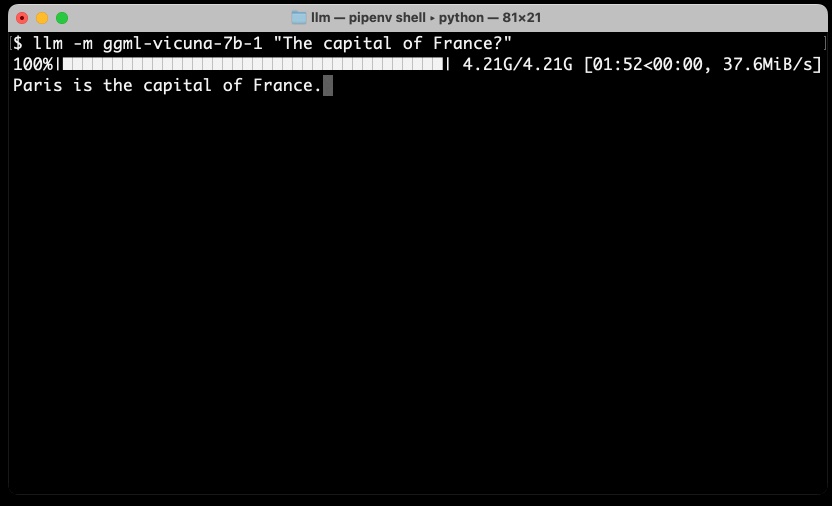
LLM is my command-line utility and Python library for working with large language models such as GPT-4. I just released version 0.5 with a huge new feature: you can now install plugins that add support for additional models to the tool, including models that can run on your own hardware.
[... 1,656 words]Databricks Signs Definitive Agreement to Acquire MosaicML, a Leading Generative AI Platform. MosaicML are the team behind MPT-7B and MPT-30B, two of the most impressive openly licensed LLMs. They just got acquired by Databricks for $1.3 billion dollars.
abacaj/mpt-30B-inference. MPT-30B, released last week, is an extremely capable Apache 2 licensed open source language model. This repo shows how it can be run on a CPU, using the ctransformers Python library based on GGML. Following the instructions in the README got me a working MPT-30B model on my M2 MacBook Pro. The model is a 19GB download and it takes a few seconds to start spitting out tokens, but it works as advertised.
MLC: Bringing Open Large Language Models to Consumer Devices (via) “We bring RedPajama, a permissive open language model to WebGPU, iOS, GPUs, and various other platforms.” I managed to get this running on my Mac (see via link) with a few tweaks to their official instructions.
LocalAI (via) “Self-hosted, community-driven, local OpenAI-compatible API”. Designed to let you run local models such as those enabled by llama.cpp without rewriting your existing code that calls the OpenAI REST APIs. Reminds me of the various S3-compatible storage APIs that exist today.
Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs (via) There’s a lot to absorb about this one. Mosaic trained this model from scratch on 1 trillion tokens, at a cost of $200,000 taking 9.5 days. It’s Apache-2.0 licensed and the model weights are available today.
They’re accompanying the base model with an instruction-tuned model called MPT-7B-Instruct (licensed for commercial use) and a non-commercially licensed MPT-7B-Chat trained using OpenAI data. They also announced MPT-7B-StoryWriter-65k+—“a model designed to read and write stories with super long context lengths”—with a previously unheard of 65,000 token context length.
They’re releasing these models mainly to demonstrate how inexpensive and powerful their custom model training service is. It’s a very convincing demo!
No Moat: Closed AI gets its Open Source wakeup call — ft. Simon Willison (via) I joined the Latent Space podcast yesterday (on short notice, so I was out and about on my phone) to talk about the leaked Google memo about open source LLMs. This was a Twitter Space, but swyx did an excellent job of cleaning up the audio and turning it into a podcast.
Leaked Google document: “We Have No Moat, And Neither Does OpenAI”
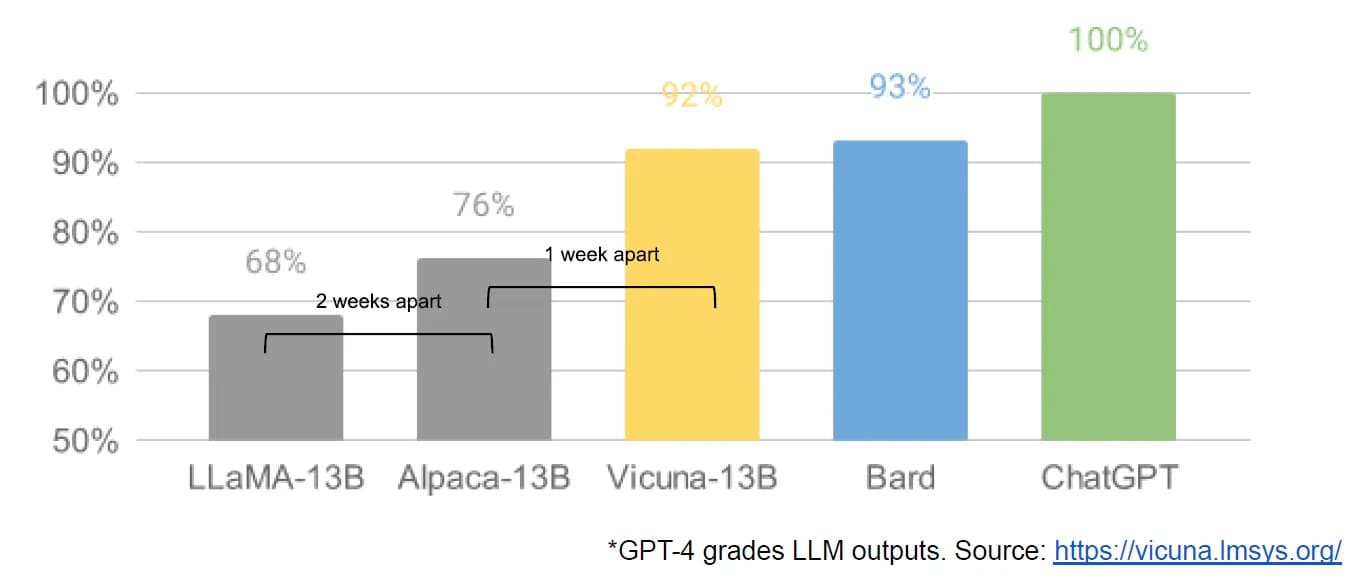
SemiAnalysis published something of a bombshell leaked document this morning: Google “We Have No Moat, And Neither Does OpenAI”.
[... 1,073 words]OpenLLaMA. The first openly licensed model I’ve seen trained on the RedPajama dataset. This initial release is a 7B model trained on 200 billion tokens, but the team behind it are promising a full 1 trillion token model in the near future. I haven’t found a live demo of this one running anywhere yet.
replit-code-v1-3b (via) As promised last week, Replit have released their 2.7b “Causal Language Model”, a foundation model trained from scratch in partnership with MosaicML with a focus on code completion. It’s licensed CC BY-SA-4.0 and is available for commercial use. They repo includes a live demo and initial experiments with it look good—you could absolutely run a local GitHub Copilot style editor on top of this model.
We show for the first time that large-scale generative pretrained transformer (GPT) family models can be pruned to at least 50% sparsity in one-shot, without any retraining, at minimal loss of accuracy. [...] We can execute SparseGPT on the largest available open-source models, OPT-175B and BLOOM-176B, in under 4.5 hours, and can reach 60% unstructured sparsity with negligible increase in perplexity: remarkably, more than 100 billion weights from these models can be ignored at inference time.
— SparseGPT, by Elias Frantar and Dan Alistarh
Let’s be bear or bunny
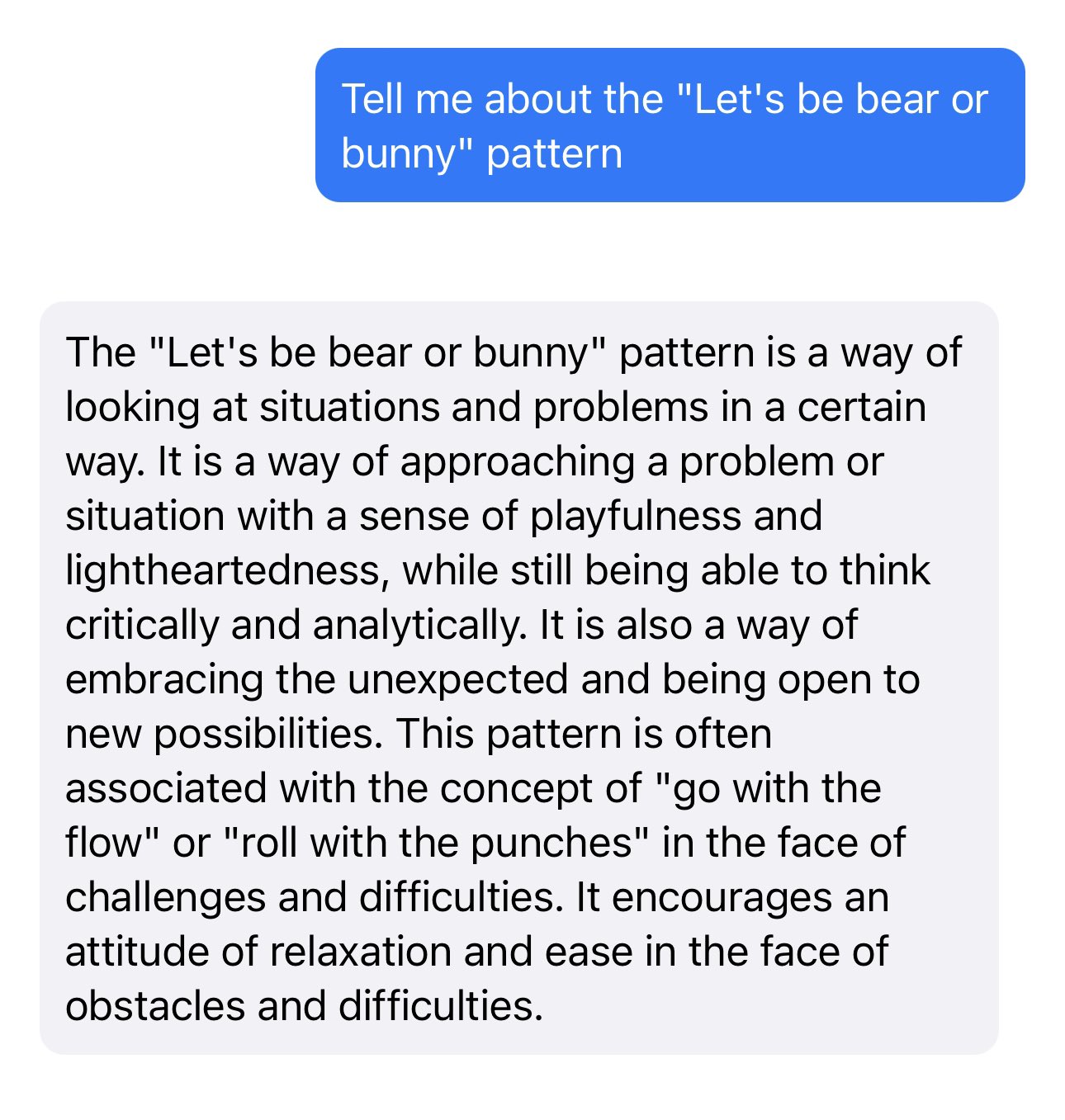
The Machine Learning Compilation group (MLC) are my favourite team of AI researchers at the moment.
[... 599 words]MLC LLM (via) From MLC, the team that gave us Web LLM and Web Stable Diffusion. “MLC LLM is a universal solution that allows any language model to be deployed natively on a diverse set of hardware backends and native applications”. I installed their iPhone demo from TestFlight this morning and it does indeed provide an offline LLM that runs on my phone. It’s reasonably capable—the underlying model for the app is vicuna-v1-7b, a LLaMA derivative.
Stability AI Launches the First of its StableLM Suite of Language Models (via) 3B and 7B base models, with 15B and 30B are on the way. CC BY-SA-4.0. “StableLM is trained on a new experimental dataset built on The Pile, but three times larger with 1.5 trillion tokens of content. We will release details on the dataset in due course.”
What’s in the RedPajama-Data-1T LLM training set
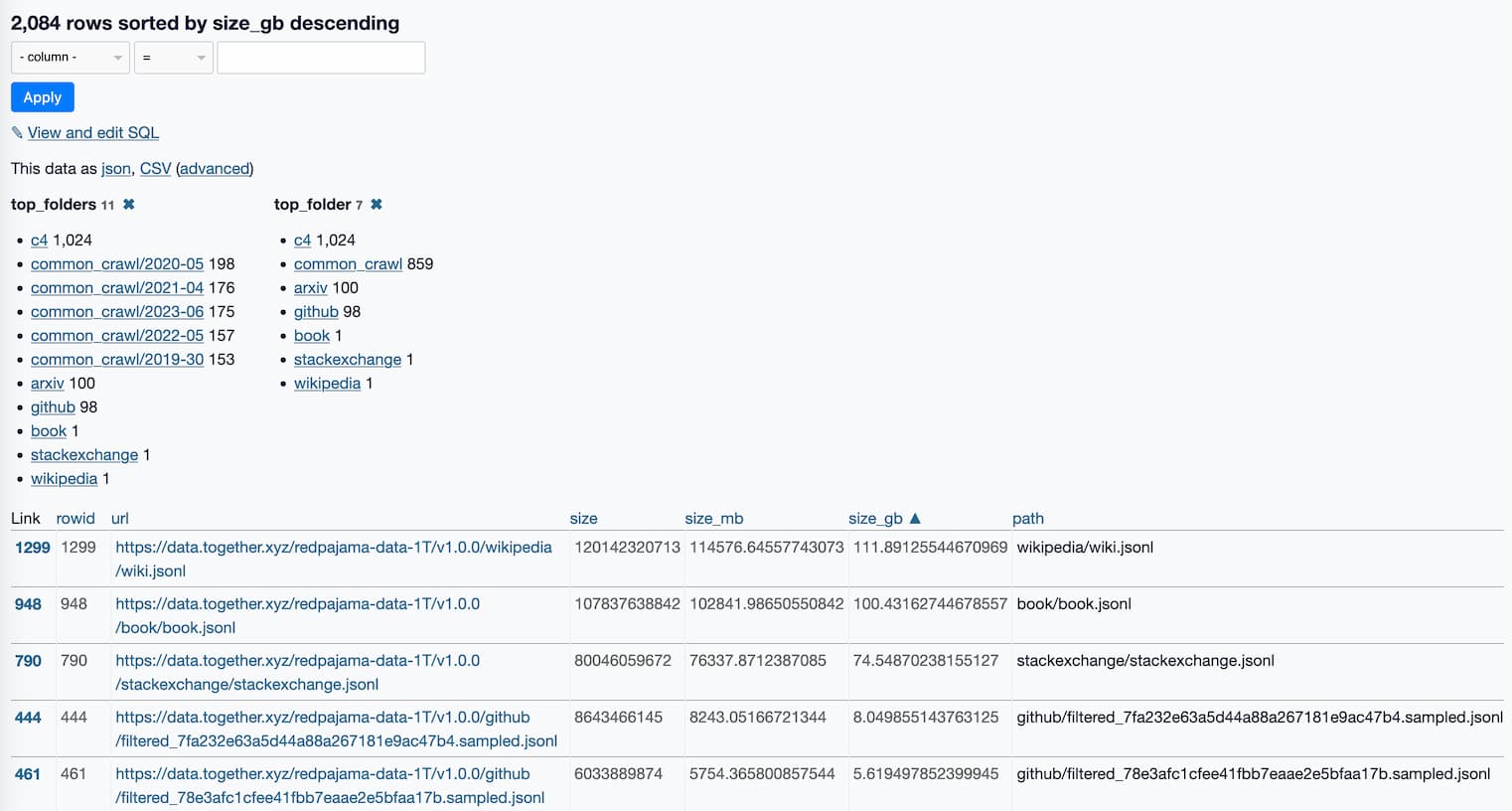
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute.
[... 1,077 words]RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens. With the amount of projects that have used LLaMA as a foundation model since its release two months ago—despite its non-commercial license—it’s clear that there is a strong desire for a fully openly licensed alternative.
RedPajama is a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute aiming to build exactly that.
Step one is gathering the training data: the LLaMA paper described a 1.2 trillion token training set gathered from sources that included Wikipedia, Common Crawl, GitHub, arXiv, Stack Exchange and more.
RedPajama-Data-1T is an attempt at recreating that training set. It’s now available to download, as 2,084 separate multi-GB jsonl files—2.67TB total.
Even without a trained model, this is a hugely influential contribution to the world of open source LLMs. Any team looking to build their own LLaMA from scratch can now jump straight to the next stage, training the model.
MiniGPT-4 (via) An incredible project with a poorly chosen name. A team from King Abdullah University of Science and Technology in Saudi Arabia combined Vicuna-13B (a model fine-tuned on top of Facebook’s LLaMA) with the BLIP-2 vision-language model to create a model that can conduct ChatGPT-style conversations around an uploaded image. The demo is very impressive, and the weights are available to download—45MB for MiniGPT-4, but you’ll need the much larger Vicuna and LLaMA weights as well.
Web LLM runs the vicuna-7b Large Language Model entirely in your browser, and it’s very impressive

A month ago I asked Could you train a ChatGPT-beating model for $85,000 and run it in a browser?. $85,000 was a hypothetical training cost for LLaMA 7B plus Stanford Alpaca. “Run it in a browser” was based on the fact that Web Stable Diffusion runs a 1.9GB Stable Diffusion model in a browser, so maybe it’s not such a big leap to run a small Large Language Model there as well.
[... 2,276 words]Free Dolly: Introducing the World’s First Truly Open Instruction-Tuned LLM (via) Databricks released a large language model called Dolly a few weeks ago. They just released Dolly 2.0 and it is MUCH more interesting—it’s an instruction tuned 12B parameter upgrade of EleutherAI’s Pythia model. Unlike other recent instruction tuned models Databricks didn’t use a training set derived from GPT-3—instead, they recruited 5,000 employees to help put together 15,000 human-generated request/response pairs, which they have released under a Creative Commons Attribution-ShareAlike license. The model itself is a 24GB download from Hugging Face—I’ve run it slowly on a small GPU-enabled Paperspace instance, but hopefully optimized ways to run it will emerge in short order.
Replacing my best friends with an LLM trained on 500,000 group chat messages (via) Izzy Miller used a 7 year long group text conversation with five friends from college to fine-tune LLaMA, such that it could simulate ongoing conversations. They started by extracting the messages from the iMessage SQLite database on their Mac, then generated a new training set from those messages and ran it using code from the Stanford Alpaca repository. This is genuinely one of the clearest explanations of the process of fine-tuning a model like this I’ve seen anywhere.
Sheepy-T—an LLM running on an iPhone. Kevin Kwok has a video on Twitter demonstrating Sheepy-T—his iPhone app which runs a full instruction-tuned large language model, based on EleutherAI’s GPT-J, entirely on an iPhone 14. I applied for the TestFlight beta and I have this running on my phone now: it works!
Thoughts on AI safety in this era of increasingly powerful open source LLMs
This morning, VentureBeat published a story by Sharon Goldman: With a wave of new LLMs, open source AI is having a moment — and a red-hot debate. It covers the explosion in activity around openly available Large Language Models such as LLaMA—a trend I’ve been tracking in my own series LLMs on personal devices—and talks about their implications with respect to AI safety.
[... 782 words]Downloading and converting the original models (Cerebras-GPT) (via) Georgi Gerganov added support for the Apache 2 licensed Cerebras-GPT language model to his ggml C++ inference library, as used by llama.cpp.
gpt4all. Similar to Alpaca, here’s a project which takes the LLaMA base model and fine-tunes it on instruction examples generated by GPT-3—in this case, it’s 800,000 examples generated using the ChatGPT GPT 3.5 turbo model (Alpaca used 52,000 generated by regular GPT-3). This is currently the easiest way to get a LLaMA derived chatbot running on your own computer: the repo includes compiled binaries for running on M1/M2, Intel Mac, Windows and Linux and provides a link to download the 3.9GB 4-bit quantized model.
Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models (via) The latest example of an open source large language model you can run your own hardware. This one is particularly interesting because the entire thing is under the Apache 2 license. Cerebras are an AI hardware company offering a product with 850,000 cores—this release was trained on their hardware, presumably to demonstrate its capabilities. The model comes in seven sizes from 111 million to 13 billion parameters, and the smaller sizes can be tried directly on Hugging Face.
LLaMA voice chat, with Whisper and Siri TTS. llama.cpp author Georgi Gerganov has stitched together the LLaMA language model, the Whisper voice to text model (with his whisper.cpp library) and the macOS “say” command to create an entirely offline AI agent that he can talk to with his voice and that can speak replies straight back to him.
Hello Dolly: Democratizing the magic of ChatGPT with open models. A team at DataBricks applied the same fine-tuning data used by Stanford Alpaca against LLaMA to a much older model—EleutherAI’s GPT-J 6B, first released in May 2021. As with Alpaca, they found that instruction tuning took the raw model—which was extremely difficult to interact with—and turned it into something that felt a lot more like ChatGPT. It’s a shame they reused the license-encumbered 52,000 training samples from Alpaca, but I doubt it will be long before someone recreates a freely licensed alternative to that training set.