24 posts tagged “files-to-prompt”
files-to-prompt concatenate a directory full of files into a single prompt for use with LLMs.
2025
Long context support in LLM 0.24 using fragments and template plugins
LLM 0.24 is now available with new features to help take advantage of the increasingly long input context supported by modern LLMs.
[... 1,896 words]I've added a new content type to my blog: notes. These join my existing types: entries, bookmarks and quotations.
A note is a little bit like a bookmark without a link. They're for short form writing - thoughts or images that don't warrant a full entry with a title. The kind of things I used to post to Twitter, but that don't feel right to cross-post to multiple social networks (Mastodon and Bluesky, for example.)
I was partly inspired by Molly White's short thoughts, notes, links, and musings.
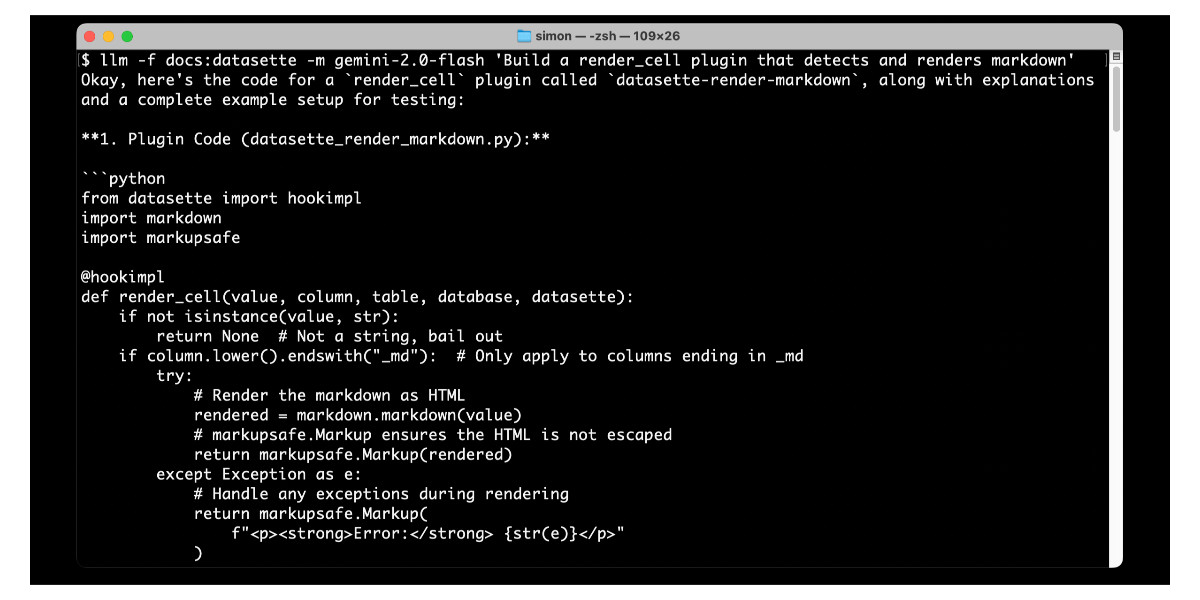
I've been thinking about this for a while, but the amount of work involved in modifying all of the parts of my site that handle the three different content types was daunting. Then this evening I tried running my blog's source code (using files-to-prompt and LLM) through the new Gemini 2.5 Pro:
files-to-prompt . -e py -c | \
llm -m gemini-2.5-pro-exp-03-25 -s \
'I want to add a new type of content called a Note,
similar to quotation and bookmark and entry but it
only has a markdown text body. Output all of the
code I need to add for that feature and tell me
which files to add the code to.'Gemini gave me a detailed 13 step plan covering all of the tedious changes I'd been avoiding having to figure out!
The code is in this PR, which touched 18 different files. The whole project took around 45 minutes start to finish.
(I used Claude to brainstorm names for the feature - I had it come up with possible nouns and then "rank those by least pretentious to most pretentious", and "notes" came out on top.)
This is now far too long for a note and should really be upgraded to an entry, but I need to post a first note to make sure everything is working as it should.
Putting Gemini 2.5 Pro through its paces

There’s a new release from Google Gemini this morning: the first in the Gemini 2.5 series. Google call it “a thinking model, designed to tackle increasingly complex problems”. It’s already sat at the top of the LM Arena leaderboard, and from initial impressions looks like it may deserve that top spot.
[... 2,400 words]microsoft/playwright-mcp. The Playwright team at Microsoft have released an MCP (Model Context Protocol) server wrapping Playwright, and it's pretty fascinating.
They implemented it on top of the Chrome accessibility tree, so MCP clients (such as the Claude Desktop app) can use it to drive an automated browser and use the accessibility tree to read and navigate pages that they visit.
Trying it out is quite easy if you have Claude Desktop and Node.js installed already. Edit your claude_desktop_config.json file:
code ~/Library/Application\ Support/Claude/claude_desktop_config.json
And add this:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Now when you launch Claude Desktop various new browser automation tools will be available to it, and you can tell Claude to navigate to a website and interact with it.
I ran the following to get a list of the available tools:
cd /tmp
git clone https://github.com/microsoft/playwright-mcp
cd playwright-mcp/src/tools
files-to-prompt . | llm -m claude-3.7-sonnet \
'Output a detailed description of these tools'
The full output is here, but here's the truncated tool list:
Navigation Tools (
common.ts)
- browser_navigate: Navigate to a specific URL
- browser_go_back: Navigate back in browser history
- browser_go_forward: Navigate forward in browser history
- browser_wait: Wait for a specified time in seconds
- browser_press_key: Press a keyboard key
- browser_save_as_pdf: Save current page as PDF
- browser_close: Close the current page
Screenshot and Mouse Tools (
screenshot.ts)
- browser_screenshot: Take a screenshot of the current page
- browser_move_mouse: Move mouse to specific coordinates
- browser_click (coordinate-based): Click at specific x,y coordinates
- browser_drag (coordinate-based): Drag mouse from one position to another
- browser_type (keyboard): Type text and optionally submit
Accessibility Snapshot Tools (
snapshot.ts)
- browser_snapshot: Capture accessibility structure of the page
- browser_click (element-based): Click on a specific element using accessibility reference
- browser_drag (element-based): Drag between two elements
- browser_hover: Hover over an element
- browser_type (element-based): Type text into a specific element
Here’s how I use LLMs to help me write code
Online discussions about using Large Language Models to help write code inevitably produce comments from developers who’s experiences have been disappointing. They often ask what they’re doing wrong—how come some people are reporting such great results when their own experiments have proved lacking?
[... 5,178 words]monolith (via) Neat CLI tool built in Rust that can create a single packaged HTML file of a web page plus all of its dependencies.
cargo install monolith # or brew install
monolith https://simonwillison.net/ > simonwillison.html
That command produced this 1.5MB single file result. All of the linked images, CSS and JavaScript assets have had their contents inlined into base64 URIs in their src= and href= attributes.
I was intrigued as to how it works, so I dumped the whole repository into Gemini 2.0 Pro and asked for an architectural summary:
cd /tmp
git clone https://github.com/Y2Z/monolith
cd monolith
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'architectural overview as markdown'
Here's what I got. Short version: it uses the reqwest, html5ever, markup5ever_rcdom and cssparser crates to fetch and parse HTML and CSS and extract, combine and rewrite the assets. It doesn't currently attempt to run any JavaScript.
files-to-prompt 0.6. New release of my CLI tool for turning a whole directory of code into a single prompt ready to pipe or paste into an LLM.
Here are the full release notes:
- New
-m/--markdownoption for outputting results as Markdown with each file in a fenced code block. #42- Support for reading a list of files from standard input. Thanks, Ankit Shankar. #44
Here's how to process just files modified within the last day:find . -mtime -1 | files-to-promptYou can also use the
-0/--nullflag to accept lists of file paths separated by null delimiters, which is useful for handling file names with spaces in them:find . -name "*.txt" -print0 | files-to-prompt -0
I also have a potential fix for a reported bug concerning nested .gitignore files that's currently sitting in a PR. I'm waiting for someone else to confirm that it behaves as they would expect. I've left details in this issue comment, but the short version is that you can try out the version from the PR using this uvx incantation:
uvx --with git+https://github.com/simonw/files-to-prompt@nested-gitignore files-to-prompt
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
Gemini 2.0 is now available to everyone. Big new Gemini 2.0 releases today:
- Gemini 2.0 Pro (Experimental) is Google's "best model yet for coding performance and complex prompts" - currently available as a free preview.
- Gemini 2.0 Flash is now generally available.
-
Gemini 2.0 Flash-Lite looks particularly interesting:
We’ve gotten a lot of positive feedback on the price and speed of 1.5 Flash. We wanted to keep improving quality, while still maintaining cost and speed. So today, we’re introducing 2.0 Flash-Lite, a new model that has better quality than 1.5 Flash, at the same speed and cost. It outperforms 1.5 Flash on the majority of benchmarks.
That means Gemini 2.0 Flash-Lite is priced at 7.5c/million input tokens and 30c/million output tokens - half the price of OpenAI's GPT-4o mini (15c/60c).
Gemini 2.0 Flash isn't much more expensive: 10c/million for text/image input, 70c/million for audio input, 40c/million for output. Again, cheaper than GPT-4o mini.
I pushed a new LLM plugin release, llm-gemini 0.10, adding support for the three new models:
llm install -U llm-gemini
llm keys set gemini
# paste API key here
llm -m gemini-2.0-flash "impress me"
llm -m gemini-2.0-flash-lite-preview-02-05 "impress me"
llm -m gemini-2.0-pro-exp-02-05 "impress me"
Here's the output for those three prompts.
I ran Generate an SVG of a pelican riding a bicycle through the three new models. Here are the results, cheapest to most expensive:
gemini-2.0-flash-lite-preview-02-05

gemini-2.0-flash

gemini-2.0-pro-exp-02-05

I also ran the same prompt I tried with o3-mini the other day:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m gemini-2.0-pro-exp-02-05 \
-s 'write extensive documentation for how the permissions system works, as markdown' \
-o max_output_tokens 10000
Here's the result from that - you can compare that to o3-mini's result here.
o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.
OpenAI reasoning models: Advice on prompting (via) OpenAI's documentation for their o1 and o3 "reasoning models" includes some interesting tips on how to best prompt them:
- Developer messages are the new system messages: Starting with
o1-2024-12-17, reasoning models supportdevelopermessages rather thansystemmessages, to align with the chain of command behavior described in the model spec.
This appears to be a purely aesthetic change made for consistency with their instruction hierarchy concept. As far as I can tell the old system prompts continue to work exactly as before - you're encouraged to use the new developer message type but it has no impact on what actually happens.
Since my LLM tool already bakes in a llm --system "system prompt" option which works across multiple different models from different providers I'm not going to rush to adopt this new language!
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
Anthropic have been encouraging XML-ish delimiters for a while (I say -ish because there's no requirement that the resulting prompt is valid XML). My files-to-prompt tool has a -c option which outputs Claude-style XML, and in my experiments this same option works great with o1 and o3 too:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.
This makes me thing that o1/o3 are not good models to implement RAG on at all - with RAG I like to be able to dump as much extra context into the prompt as possible and leave it to the models to figure out what's relevant.
- Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
Providing examples remains the single most powerful prompting tip I know, so it's interesting to see advice here to only switch to examples if zero-shot doesn't work out.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
This makes sense: reasoning models "think" until they reach a conclusion, so making the goal as unambiguous as possible leads to better results.
- Markdown formatting: Starting with
o1-2024-12-17, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the stringFormatting re-enabledon the first line of yourdevelopermessage.
This one was a real shock to me! I noticed that o3-mini was outputting • characters instead of Markdown * bullets and initially thought that was a bug.
I first saw this while running this prompt against limbo/bindings/python using files-to-prompt:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'Here's the full result, which includes text like this (note the weird bullets):
Features
--------
• High‑performance, in‑process database engine written in Rust
• SQLite‑compatible SQL interface
• Standard Python DB‑API 2.0–style connection and cursor objects
I ran it again with this modified prompt:
Formatting re-enabled. Write a detailed README with extensive usage examples.
And this time got back proper Markdown, rendered in this Gist. That did a really good job, and included bulleted lists using this valid Markdown syntax instead:
- **`make test`**: Run tests using pytest.
- **`make lint`**: Run linters (via [ruff](https://github.com/astral-sh/ruff)).
- **`make check-requirements`**: Validate that the `requirements.txt` files are in sync with `pyproject.toml`.
- **`make compile-requirements`**: Compile the `requirements.txt` files using pip-tools.
(Using LLMs like this to get me off the ground with under-documented libraries is a trick I use several times a month.)
Update: OpenAI's Nikunj Handa:
we agree this is weird! fwiw, it’s a temporary thing we had to do for the existing o-series models. we’ll fix this in future releases so that you can go back to naturally prompting for markdown or no-markdown.
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra
2024
Introducing Limbo: A complete rewrite of SQLite in Rust (via) This looks absurdly ambitious:
Our goal is to build a reimplementation of SQLite from scratch, fully compatible at the language and file format level, with the same or higher reliability SQLite is known for, but with full memory safety and on a new, modern architecture.
The Turso team behind it have been maintaining their libSQL fork for two years now, so they're well equipped to take on a challenge of this magnitude.
SQLite is justifiably famous for its meticulous approach to testing. Limbo plans to take an entirely different approach based on "Deterministic Simulation Testing" - a modern technique pioneered by FoundationDB and now spearheaded by Antithesis, the company Turso have been working with on their previous testing projects.
Another bold claim (emphasis mine):
We have both added DST facilities to the core of the database, and partnered with Antithesis to achieve a level of reliability in the database that lives up to SQLite’s reputation.
[...] With DST, we believe we can achieve an even higher degree of robustness than SQLite, since it is easier to simulate unlikely scenarios in a simulator, test years of execution with different event orderings, and upon finding issues, reproduce them 100% reliably.
The two most interesting features that Limbo is planning to offer are first-party WASM support and fully asynchronous I/O:
SQLite itself has a synchronous interface, meaning driver authors who want asynchronous behavior need to have the extra complication of using helper threads. Because SQLite queries tend to be fast, since no network round trips are involved, a lot of those drivers just settle for a synchronous interface. [...]
Limbo is designed to be asynchronous from the ground up. It extends
sqlite3_step, the main entry point API to SQLite, to be asynchronous, allowing it to return to the caller if data is not ready to consume immediately.
Datasette provides an async API for executing SQLite queries which is backed by all manner of complex thread management - I would be very interested in a native asyncio Python library for talking to SQLite database files.
I successfully tried out Limbo's Python bindings against a demo SQLite test database using uv like this:
uv run --with pylimbo python
>>> import limbo
>>> conn = limbo.connect("/tmp/demo.db")
>>> cursor = conn.cursor()
>>> print(cursor.execute("select * from foo").fetchall())
It crashed when I tried against a more complex SQLite database that included SQLite FTS tables.
The Python bindings aren't yet documented, so I piped them through LLM and had the new google-exp-1206 model write this initial documentation for me:
files-to-prompt limbo/bindings/python -c | llm -m gemini-exp-1206 -s 'write extensive usage documentation in markdown, including realistic usage examples'
Generating documentation from tests using files-to-prompt and LLM. I was experimenting with the wasmtime-py Python library today (for executing WebAssembly programs from inside CPython) and I found the existing API docs didn't quite show me what I wanted to know.
The project has a comprehensive test suite so I tried seeing if I could generate documentation using that:
cd /tmp
git clone https://github.com/bytecodealliance/wasmtime-py
files-to-prompt -e py wasmtime-py/tests -c | \
llm -m claude-3.5-sonnet -s \
'write detailed usage documentation including realistic examples'
More notes in my TIL. You can see the full Claude transcript here - I think this worked really well!
files-to-prompt 0.4. New release of my files-to-prompt tool adding an option for filtering just for files with a specific extension.
The following command will output Claude XML-style markup for all Python and Markdown files in the current directory, and copy that to the macOS clipboard ready to be pasted into an LLM:
files-to-prompt . -e py -e md -c | pbcopy
An LLM TDD loop (via) Super neat demo by David Winterbottom, who wrapped my LLM and files-to-prompt tools in a short Bash script that can be fed a file full of Python unit tests and an empty implementation file and will then iterate on that file in a loop until the tests pass.
lm.rs: run inference on Language Models locally on the CPU with Rust (via) Impressive new LLM inference implementation in Rust by Samuel Vitorino. I tried it just now on an M2 Mac with 64GB of RAM and got very snappy performance for this Q8 Llama 3.2 1B, with Activity Monitor reporting 980% CPU usage over 13 threads.
Here's how I compiled the library and ran the model:
cd /tmp
git clone https://github.com/samuel-vitorino/lm.rs
cd lm.rs
RUSTFLAGS="-C target-cpu=native" cargo build --release --bin chat
curl -LO 'https://huggingface.co/samuel-vitorino/Llama-3.2-1B-Instruct-Q8_0-LMRS/resolve/main/tokenizer.bin?download=true'
curl -LO 'https://huggingface.co/samuel-vitorino/Llama-3.2-1B-Instruct-Q8_0-LMRS/resolve/main/llama3.2-1b-it-q80.lmrs?download=true'
./target/release/chat --model llama3.2-1b-it-q80.lmrs --show-metrics
That --show-metrics option added this at the end of a response:
Speed: 26.41 tok/s
It looks like the performance is helped by two key dependencies: wide, which provides data types optimized for SIMD operations and rayon for running parallel iterators across multiple cores (used for matrix multiplication).
(I used LLM and files-to-prompt to help figure this out.)
Llama 3.2. In further evidence that AI labs are terrible at naming things, Llama 3.2 is a huge upgrade to the Llama 3 series - they've released their first multi-modal vision models!
Today, we’re releasing Llama 3.2, which includes small and medium-sized vision LLMs (11B and 90B), and lightweight, text-only models (1B and 3B) that fit onto edge and mobile devices, including pre-trained and instruction-tuned versions.
The 1B and 3B text-only models are exciting too, with a 128,000 token context length and optimized for edge devices (Qualcomm and MediaTek hardware get called out specifically).
Meta partnered directly with Ollama to help with distribution, here's the Ollama blog post. They only support the two smaller text-only models at the moment - this command will get the 3B model (2GB):
ollama run llama3.2
And for the 1B model (a 1.3GB download):
ollama run llama3.2:1b
I had to first upgrade my Ollama by clicking on the icon in my macOS task tray and selecting "Restart to update".
The two vision models are coming to Ollama "very soon".
Once you have fetched the Ollama model you can access it from my LLM command-line tool like this:
pipx install llm
llm install llm-ollama
llm chat -m llama3.2:1b
I tried running my djp codebase through that tiny 1B model just now and got a surprisingly good result - by no means comprehensive, but way better than I would ever expect from a model of that size:
files-to-prompt **/*.py -c | llm -m llama3.2:1b --system 'describe this code'
Here's a portion of the output:
The first section defines several test functions using the
@djp.hookimpldecorator from the djp library. These hook implementations allow you to intercept and manipulate Django's behavior.
test_middleware_order: This function checks that the middleware order is correct by comparing theMIDDLEWAREsetting with a predefined list.test_middleware: This function tests various aspects of middleware:- It retrieves the response from the URL
/from-plugin/using theClientobject, which simulates a request to this view.- It checks that certain values are present in the response:
X-DJP-Middleware-AfterX-DJP-MiddlewareX-DJP-Middleware-Before[...]
I found the GGUF file that had been downloaded by Ollama in my ~/.ollama/models/blobs directory. The following command let me run that model directly in LLM using the llm-gguf plugin:
llm install llm-gguf
llm gguf register-model ~/.ollama/models/blobs/sha256-74701a8c35f6c8d9a4b91f3f3497643001d63e0c7a84e085bed452548fa88d45 -a llama321b
llm chat -m llama321b
Meta themselves claim impressive performance against other existing models:
Our evaluation suggests that the Llama 3.2 vision models are competitive with leading foundation models, Claude 3 Haiku and GPT4o-mini on image recognition and a range of visual understanding tasks. The 3B model outperforms the Gemma 2 2.6B and Phi 3.5-mini models on tasks such as following instructions, summarization, prompt rewriting, and tool-use, while the 1B is competitive with Gemma.
Here's the Llama 3.2 collection on Hugging Face. You need to accept the new Llama 3.2 Community License Agreement there in order to download those models.
You can try the four new models out via the Chatbot Arena - navigate to "Direct Chat" there and select them from the dropdown menu. You can upload images directly to the chat there to try out the vision features.
Solving a bug with o1-preview, files-to-prompt and LLM.
I added a new feature to DJP this morning: you can now have plugins specify their middleware in terms of how it should be positioned relative to other middleware - inserted directly before or directly after django.middleware.common.CommonMiddleware for example.
At one point I got stuck with a weird test failure, and after ten minutes of head scratching I decided to pipe the entire thing into OpenAI's o1-preview to see if it could spot the problem. I used files-to-prompt to gather the code and LLM to run the prompt:
files-to-prompt **/*.py -c | llm -m o1-preview "
The middleware test is failing showing all of these - why is MiddlewareAfter repeated so many times?
['MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware4', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware', 'MiddlewareBefore']"The model whirled away for a few seconds and spat out an explanation of the problem - one of my middleware classes was accidentally calling self.get_response(request) in two different places.
I did enjoy how o1 attempted to reference the relevant Django documentation and then half-repeated, half-hallucinated a quote from it:

This took 2,538 input tokens and 4,354 output tokens - by my calculations at $15/million input and $60/million output that prompt cost just under 30 cents.
Jiter (via) One of the challenges in dealing with LLM streaming APIs is the need to parse partial JSON - until the stream has ended you won't have a complete valid JSON object, but you may want to display components of that JSON as they become available.
I've solved this previously using the ijson streaming JSON library, see my previous TIL.
Today I found out about Jiter, a new option from the team behind Pydantic. It's written in Rust and extracted from pydantic-core, so the Python wrapper for it can be installed using:
pip install jiter
You can feed it an incomplete JSON bytes object and use partial_mode="on" to parse the valid subset:
import jiter partial_json = b'{"name": "John", "age": 30, "city": "New Yor' jiter.from_json(partial_json, partial_mode="on") # {'name': 'John', 'age': 30}
Or use partial_mode="trailing-strings" to include incomplete string fields too:
jiter.from_json(partial_json, partial_mode="trailing-strings") # {'name': 'John', 'age': 30, 'city': 'New Yor'}
The current README was a little thin, so I submiitted a PR with some extra examples. I got some help from files-to-prompt and Claude 3.5 Sonnet):
cd crates/jiter-python/ && files-to-prompt -c README.md tests | llm -m claude-3.5-sonnet --system 'write a new README with comprehensive documentation'
files-to-prompt 0.3.
New version of my files-to-prompt CLI tool for turning a bunch of files into a prompt suitable for piping to an LLM, described here previously.
It now has a -c/--cxml flag for outputting the files in Claude XML-ish notation (XML-ish because it's not actually valid XML) using the format Anthropic describe as recommended for long context:
files-to-prompt llm-*/README.md --cxml | llm -m claude-3.5-sonnet \
--system 'return an HTML page about these plugins with usage examples' \
> /tmp/fancy.html
The format itself looks something like this:
<documents>
<document index="1">
<source>llm-anyscale-endpoints/README.md</source>
<document_content>
# llm-anyscale-endpoints
...
</document_content>
</document>
</documents>json-flatten, now with format documentation.
json-flatten is a fun little Python library I put together a few years ago for converting JSON data into a flat key-value format, suitable for inclusion in an HTML form or query string. It lets you take a structure like this one:
{"foo": {"bar": [1, True, None]}
And convert it into key-value pairs like this:
foo.bar.[0]$int=1
foo.bar.[1]$bool=True
foo.bar.[2]$none=None
The flatten(dictionary) function function converts to that format, and unflatten(dictionary) converts back again.
I was considering the library for a project today and realized that the 0.3 README was a little thin - it showed how to use the library but didn't provide full details of the format it used.
On a hunch, I decided to see if files-to-prompt plus LLM plus Claude 3.5 Sonnet could write that documentation for me. I ran this command:
files-to-prompt *.py | llm -m claude-3.5-sonnet --system 'write detailed documentation in markdown describing the format used to represent JSON and nested JSON as key/value pairs, include a table as well'
That *.py picked up both json_flatten.py and test_json_flatten.py - I figured the test file had enough examples in that it should act as a good source of information for the documentation.
This worked really well! You can see the first draft it produced here.
It included before and after examples in the documentation. I didn't fully trust these to be accurate, so I gave it this follow-up prompt:
llm -c "Rewrite that document to use the Python cog library to generate the examples"
I'm a big fan of Cog for maintaining examples in READMEs that are generated by code. Cog has been around for a couple of decades now so it was a safe bet that Claude would know about it.
This almost worked - it produced valid Cog syntax like the following:
[[[cog
example = {
"fruits": ["apple", "banana", "cherry"]
}
cog.out("```json\n")
cog.out(str(example))
cog.out("\n```\n")
cog.out("Flattened:\n```\n")
for key, value in flatten(example).items():
cog.out(f"{key}: {value}\n")
cog.out("```\n")
]]]
[[[end]]]
But that wasn't entirely right, because it forgot to include the Markdown comments that would hide the Cog syntax, which should have looked like this:
<!-- [[[cog -->
...
<!-- ]]] -->
...
<!-- [[[end]]] -->
I could have prompted it to correct itself, but at this point I decided to take over and edit the rest of the documentation by hand.
The end result was documentation that I'm really happy with, and that I probably wouldn't have bothered to write if Claude hadn't got me started.
Language models on the command-line
I gave a talk about accessing Large Language Models from the command-line last week as part of the Mastering LLMs: A Conference For Developers & Data Scientists six week long online conference. The talk focused on my LLM Python command-line utility and ways you can use it (and its plugins) to explore LLMs and use them for useful tasks.
[... 4,992 words]Building files-to-prompt entirely using Claude 3 Opus

files-to-prompt is a new tool I built to help me pipe several files at once into prompts to LLMs such as Claude and GPT-4.
[... 3,235 words]