1,912 posts tagged “generative-ai”
Machine learning systems that can generate new content: text, images, audio, video and more.
2026
The last six months in LLMs in five minutes

I put together these annotated slides from my five minute lightning talk at PyCon US 2026, using the latest iteration of my annotated presentation tool.
[... 2,061 words]GDS weighs in on the NHS’s decision to retreat from Open Source. Terence Eden continues his coverage of the NHS' poorly considered decision to close down access to their open source repositories in response to vulnerabilities reported to them as part of Project Glasswing.
Now the Government Digital Service have joined the conversation with AI, open code and vulnerability risk in the public sector, published May 14th. Their key recommendation:
Keep open by default. Making everything private adds additional delivery and policy costs, and can reduce reuse and scrutiny. Openness should remain the default posture, with closure used sparingly and deliberately.
While they don't mention the NHS by name, Terence speaks the language of the civil service and interprets this as a major escalation:
Within the UK's Civil Service you occasionally hear the expression "being invited to a meeting without biscuits". It implies a rather frosty discussion without any of the polite niceties of a normal meeting. In general though, even when people have severe disagreements, it is rare for tempers to fray. It is even rarer for those internal disagreements to spill over into public.
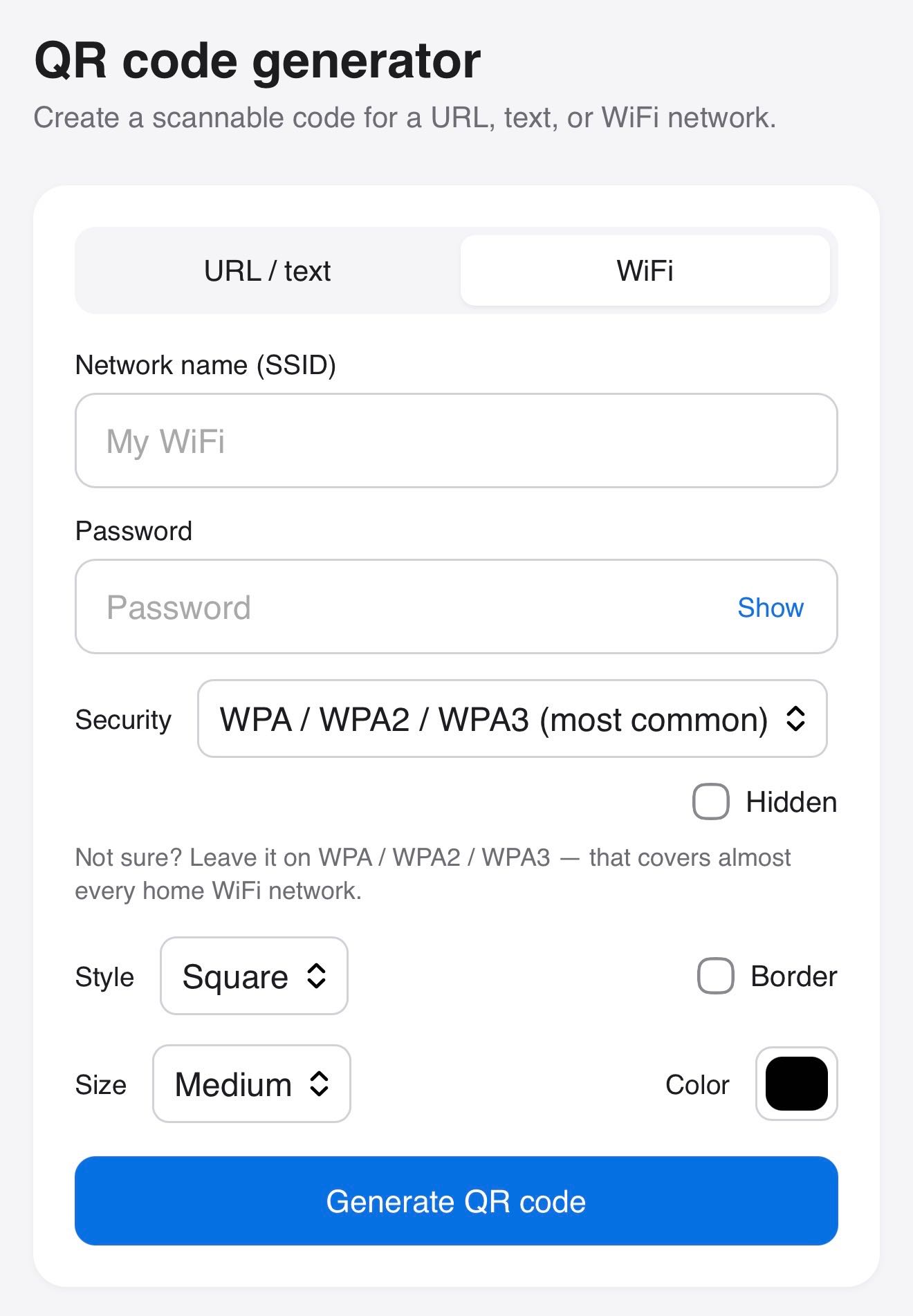
Claude helped me build this tool for creating QR codes, for both text/URLs and for connecting to WiFi networks.
This Mitchell Hashimoto quote about Bun migrating from Zig to Rust reminded me of a similar conversation I had at a conference last week.
I was talking to someone who worked for a medium sized technology company with a pair of legacy/legendary iPhone and Android apps.
They told me they had just completed a coding-agent driven rewrite of both apps to React Native.
I asked why they chose that, given that coding agents presumably drive down the cost of maintaining separate iPhone and Android apps.
They said that React Native has improved a lot over the past few years and covered everything their apps needed to do.
And... if it turned out to be the wrong decision, they could just port back to native in the future.
Like Mitchell said:
Programming languages used to be LOCK IN, and they're increasingly not so.
[...] On the interesting side is how fungible programming languages are nowadays. Programming languages used to be LOCK IN, and they're increasingly not so. You think the Bun rewrite in Rust is good for Rust? Bun has shown they can be in probably any language they want in roughly a week or two. Rust is expendable. Its useful until its not then it can be thrown out. That's interesting!
— Mitchell Hashimoto, on Bun porting from Zig to Rust
Welcome to the Datasette blog. We have a bunch of neat Datasette announcements in the pipeline so we decided it was time the project grew an official blog.
I built this using OpenAI Codex desktop, which turns out to have the Markdown session transcript export feature I've always wanted. Here's the session that built the blog. See also issue 179.
A bunch of useful stuff in this LLM alpha, but the most important detail is this one:
Most reasoning-capable OpenAI models now use the
/v1/responsesendpoint instead of/v1/chat/completions. This enables interleaved reasoning across tool calls for GPT-5 class models. #1435
This means you can now see the summarized reasoning tokens when you run prompts against an OpenAI model, displayed in a different color to standard error. Use the -R or --hide-reasoning flags if you don't want to see that.
Your AI coding agent, the one you use to write code, needs to reduce your maintenance costs. Not by a little bit, either. You write code twice as quick now? Better hope you’ve halved your maintenance costs. Three times as productive? One third the maintenance costs. Otherwise, you’re screwed. You’re trading a temporary speed boost for permanent indenture. [...]
The math only works if the LLM decreases your maintenance costs, and by exactly the inverse of the rate it adds code. If you double your output and your cost of maintaining that output, two times two means you’ve quadrupled your maintenance costs. If you double your output and hold your maintenance costs steady, two times one means you’ve still doubled your maintenance costs.
— James Shore, You Need AI That Reduces Maintenance Costs
Your AI Use Is Breaking My Brain (via) Excellent, angry piece by Jason Koebler on how AI writing online is becoming impossible to avoid, filtering it is mentally exhausting and it's even starting to distort regular human writing styles.
I particularly liked his use of the term "Zombie Internet" to define a different, more insidious alternative to the "Dead Internet" (which is just bots talking to each other):
I called it the Zombie Internet because the truth is that large parts of the internet are not just bots talking to bots or bots talking to people. It’s people talking to bots, people talking to people, people creating “AI agents” and then instructing them to interact with people. It’s people using AI talking to people who are not using AI, and it’s people using AI talking to other people who are using AI. It’s influencer hustlebros who are teaching each other how to make AI influencers and have spun up automated YouTube channels and blogs and social media accounts that are spamming the internet for the sole purpose of making money. It is whatever the fuck “Moltbook” is and whatever the fuck X and LinkedIn have become. It’s AI summaries of real books being sold as the book itself and inspirational Reddit posts and comment threads in which people give heartfelt advice to some account that’s actually being run by a marketing firm. [...]

Kim_Bruning on Hacker News:
But seriously, you can put a shebang on an english text file now (if you're sufficiently brave) [...]
This inspired me to look at patterns for doing exactly that with LLM. Here's the simplest, which takes advantage of LLM fragments:
#!/usr/bin/env -S llm -f
Generate an SVG of a pelican riding a bicycle
But you can also incorporate tool calls using the -T name_of_tool option:
#!/usr/bin/env -S llm -T llm_time -f
Write a haiku that mentions the exact current time
Or even execute YAML templates directly that define extra tools as Python functions:
#!/usr/bin/env -S llm -t model: gpt-5.4-mini system: | Use tools to run calculations functions: | def add(a: int, b: int) -> int: return a + b def multiply(a: int, b: int) -> int: return a * b
Then:
./calc.sh 'what is 2344 * 5252 + 134' --td
Which outputs (thanks to that --td tools debug option):
Tool call: multiply({'a': 2344, 'b': 5252})
12310688
Tool call: add({'a': 12310688, 'b': 134})
12310822
2344 × 5252 + 134 = **12,310,822**
Read the full TIL for a more complex example that uses the Datasette SQL API to answer questions about content on my blog.
Learning on the Shop floor. Tobias Lütke describes Shopify's internal coding agent tool, River, which operates entirely in public on their Slack:
River does not respond to direct messages. She politely declines and suggests to create a public channel for you and her to start working in. I myself work with river in
#tobi_riverchannel and many followed this pattern. Every conversation is therefore searchable. Anyone at Shopify can jump in. In my own channel, there are over 100 people who, react to threads, add color and add context, pick up the torch, help with the reviews, remind me how rusty I am, and importantly, learn from watching. [...]As so often with German, there is a word for the kind of environment: Lehrwerkstatt. Literally: A teaching workshop. The whole shop floor is the classroom. You learn by being near the work. Being a constant learner is one of the core values of the firm.
Shopify wants to be a Lehrwerkstatt at scale and River has now gotten us closer to this ideal than ever. It’s osmosis learning, because it does not require a curriculum, a training plan, or a manager. It just requires everyone's work to be visible to the maximum extent possible. Everyone learns from each other.
I'm reminded of how Midjourney spent its first few years with the primary interface being public Discord channels, forcing users to share their prompts and learn from each other's experiments. I continue to believe that the early success of Midjourney was tied to this mechanism, helping to compensate for how weird and finicky text-to-image prompting is.
This article was updated after The Times learned that a remark attributed to Pierre Poilievre, the Conservative leader, was in fact an A.I.-generated summary of his views about Canadian politics that A.I. rendered as a quotation. The reporter should have checked the accuracy of what the A.I. tool returned. The article now accurately quotes from a speech delivered by Mr. Poilievre in April. [...] He did not refer to politicians who changed allegiances as turncoats in that speech.
Using Claude Code: The Unreasonable Effectiveness of HTML. Thought-provoking piece by Thariq Shihipar (on the Claude Code team at Anthropic) advocating for HTML over Markdown as an output format to request from Claude.
The article is crammed with interesting examples (collected on this site) and prompt suggestions like this one:
Help me review this PR by creating an HTML artifact that describes it. I'm not very familiar with the streaming/backpressure logic so focus on that. Render the actual diff with inline margin annotations, color-code findings by severity and whatever else might be needed to convey the concept well.
I've been defaulting to asking for most things in Markdown since the GPT-4 days, when the 8,192 token limit meant that Markdown's token-efficiency over HTML was extremely worthwhile.
Thariq's piece here has caused me to reconsider that, especially for output. Asking Claude for an explanation in HTML means it can drop in SVG diagrams, interactive widgets, in-page navigation and all sorts of other neat ways of making the information more pleasant to navigate.
I wrote about Useful patterns for building HTML tools last December, but that was focused very much on interactive utilities like the ones on my tools.simonwillison.net site. I'm excited to start experimenting more with rich HTML explanations in response to ad-hoc prompts.
Trying this out on copy.fail
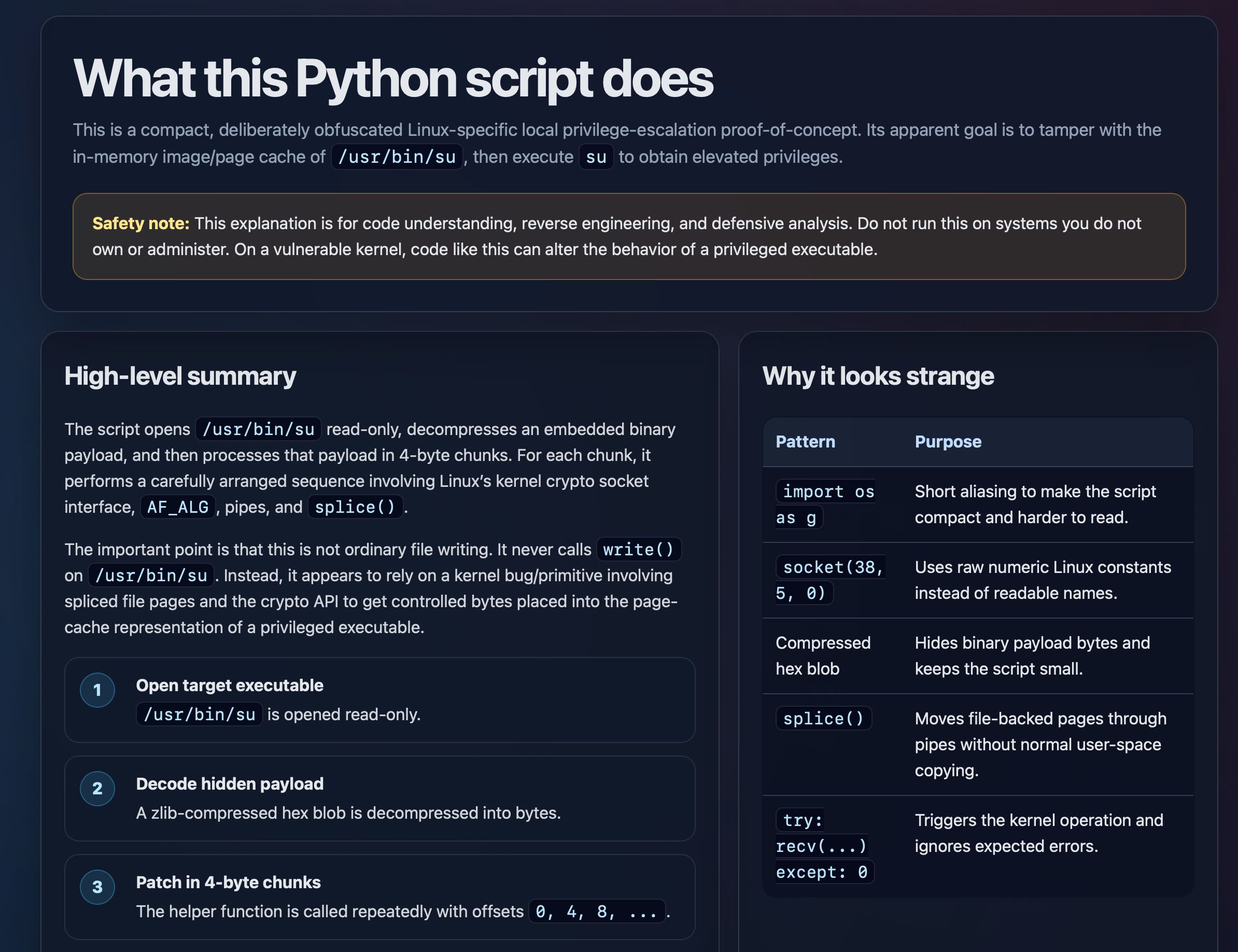
copy.fail describes a recently discovered Linux security exploit, including a proof of concept distributed as obfuscated Python.
I tried having GPT-5.5 create an HTML explanation of the exploit like this:
curl https://copy.fail/exp | llm -m gpt-5.5 -s 'Explain this code in detail. Reformat it, expand out any confusing bits and go deep into what it does and how it works. Output HTML, neatly styled and using capabilities of HTML and CSS and JavaScript to make the explanation rich and interactive and as clear as possible'
Here's the resulting HTML page. It's pretty good, though I should have emphasized explaining the exploit over the Python harness around it.
gemini-3.1-flash-liteis no longer a preview.
Here's my write-up of the Gemini 3.1 Flash-Lite Preview model back in March. I don't believe this new non-preview model has changed since then.
Behind the Scenes Hardening Firefox with Claude Mythos Preview (via) Fascinating, in-depth details on how Mozilla used their access to the Claude Mythos preview to locate and then fix hundreds of vulnerabilities in Firefox:
Suddenly, the bugs are very good
Just a few months ago, AI-generated security bug reports to open source projects were mostly known for being unwanted slop. Dealing with reports that look plausibly correct but are wrong imposes an asymmetric cost on project maintainers: it’s cheap and easy to prompt an LLM to find a “problem” in code, but slow and expensive to respond to it.
It is difficult to overstate how much this dynamic changed for us over a few short months. This was due to a combination of two main factors. First, the models got a lot more capable. Second, we dramatically improved our techniques for harnessing these models — steering them, scaling them, and stacking them to generate large amounts of signal and filter out the noise.
They include some detailed bug descriptions too, including a 20-year old XSLT bug and a 15-year-old bug in the <legend> element.
A lot of the attempts made by the harness were blocked by Firefox's existing defense-in-depth measures, which is reassuring.
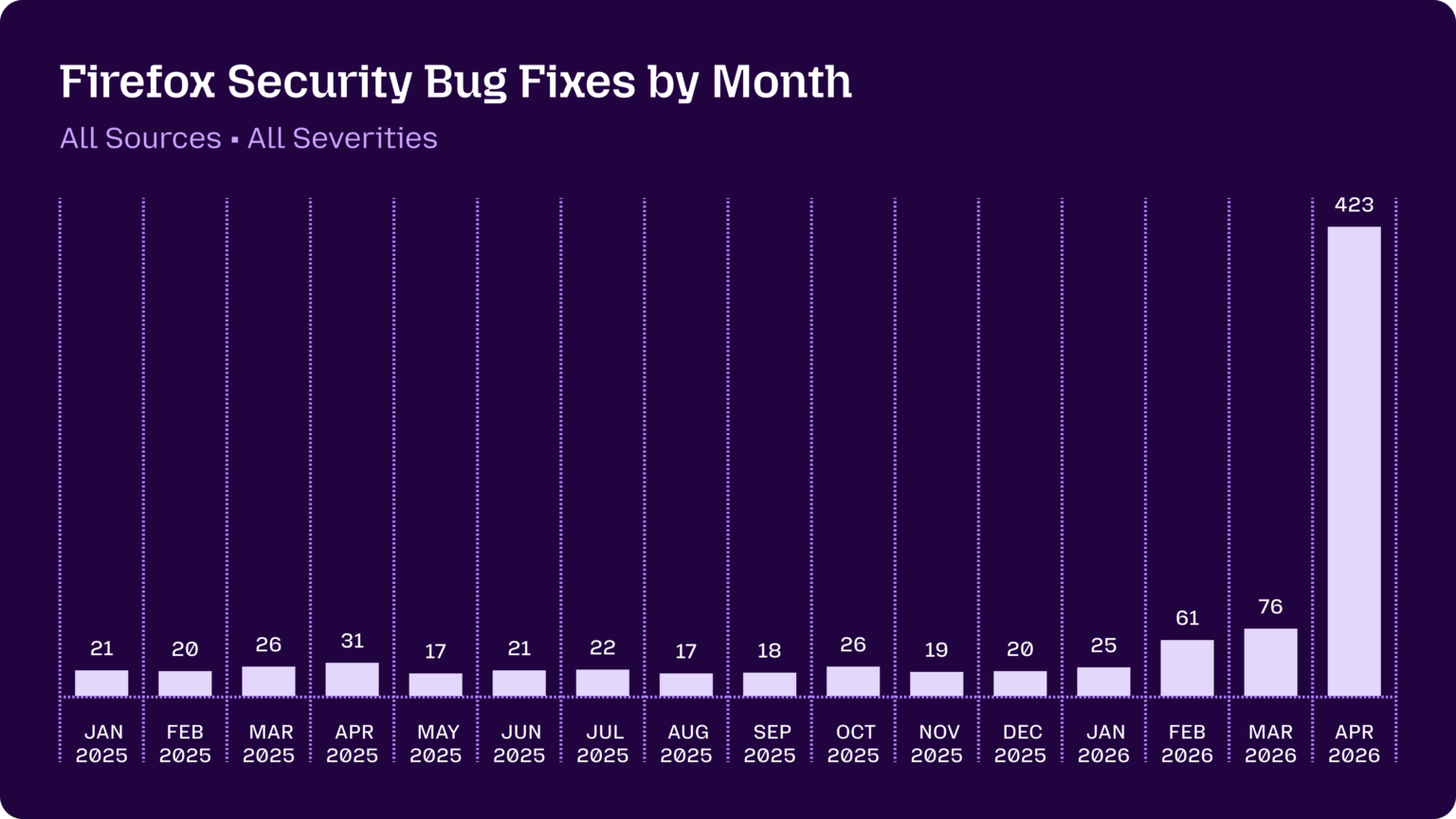
Mozilla were fixing around 20-30 security bugs in Firefox per month through 2025. That jumped to 423 in April.
Live blog: Code w/ Claude 2026
I’m at Anthropic’s Code w/ Claude event today. Here’s my live blog of the morning keynote sessions.
Vibe coding and agentic engineering are getting closer than I’d like
I recently talked with Joseph Ruscio about AI coding tools for Heavybit’s High Leverage podcast: Ep. #9, The AI Coding Paradigm Shift with Simon Willison. Here are some of my highlights, including my disturbing realization that vibe coding and agentic engineering have started to converge in my own work.
[... 1,542 words]Our AI started a cafe in Stockholm (via) Andon Labs previously started an AI-run retail store in San Francisco. Now they're running a similar experiment in Stockholm, Sweden, only this time it's a cafe.
These experiments are interesting, and often throw out amusing anecdotes:
During the first week of inventory, Mona ordered 120 eggs even though the café has no stove. When the staff told her they couldn’t cook them, she suggested using the high-speed oven, until they pointed out the eggs would likely explode. She also tried to solve the problem of fresh tomatoes being spoiled too fast by ordering 22.5 kg of canned tomatoes for the fresh sandwiches. The baristas eventually started a “Hall of Shame”, a shelf visible to customers with all the weird things Mona ordered, including 6,000 napkins, 3,000 nitrile gloves, 9L coconut milk, and industrial-sized trash bags.
Where they lose their shine is when these AI managers start wasting the time of human beings who have not opted into the experiment:
She also successfully applied for an outdoor seating permit through the Police e-service, which didn’t require BankID. Her first submission included a sketch she had generated herself, despite having never seen the street outside the café. Unsurprisingly, the Police sent it back for revision. [...]
When she makes a mistake, she often sends multiple emails to suppliers with the subject “EMERGENCY” to cancel or change the order.
I don't think it's ethical to run experiments like this that affect real-world systems and steal time from people.
I'm reminded of the incident last year where the AI Village experiment infuriated Rob Pike by sending him unsolicited gratitude emails as an "act of kindness". That was just an unwanted email - asking suppliers to correct mistakes that were made without a human-in-the-loop or wasting police time with slop diagrams feels a whole lot worse to me.
I think experiments like this need to keep their own human operators in-the-loop for outbound actions that affect other people.
Granite 4.1 3B SVG Pelican Gallery. IBM released their Granite 4.1 family of LLMs a few days ago. They're Apache 2.0 licensed and come in 3B, 8B and 30B sizes.
Granite 4.1 LLMs: How They’re Built by Granite team member Yousaf Shah describes the training process in detail.
Unsloth released the unsloth/granite-4.1-3b-GGUF collection of GGUF encoded quantized variants of the 3B model - 21 different model files ranging in size from 1.2GB to 6.34GB.
All 21 of those Unsloth files add up to 51.3GB, which inspired me to finally try an experiment I've been wanting to run for ages: prompting "Generate an SVG of a pelican riding a bicycle" against different sized quantized variants of the same model to see what the results would look like.
Honestly, the results are less interesting than I expected. There's no distinguishable pattern relating quality to size - they're all pretty terrible!
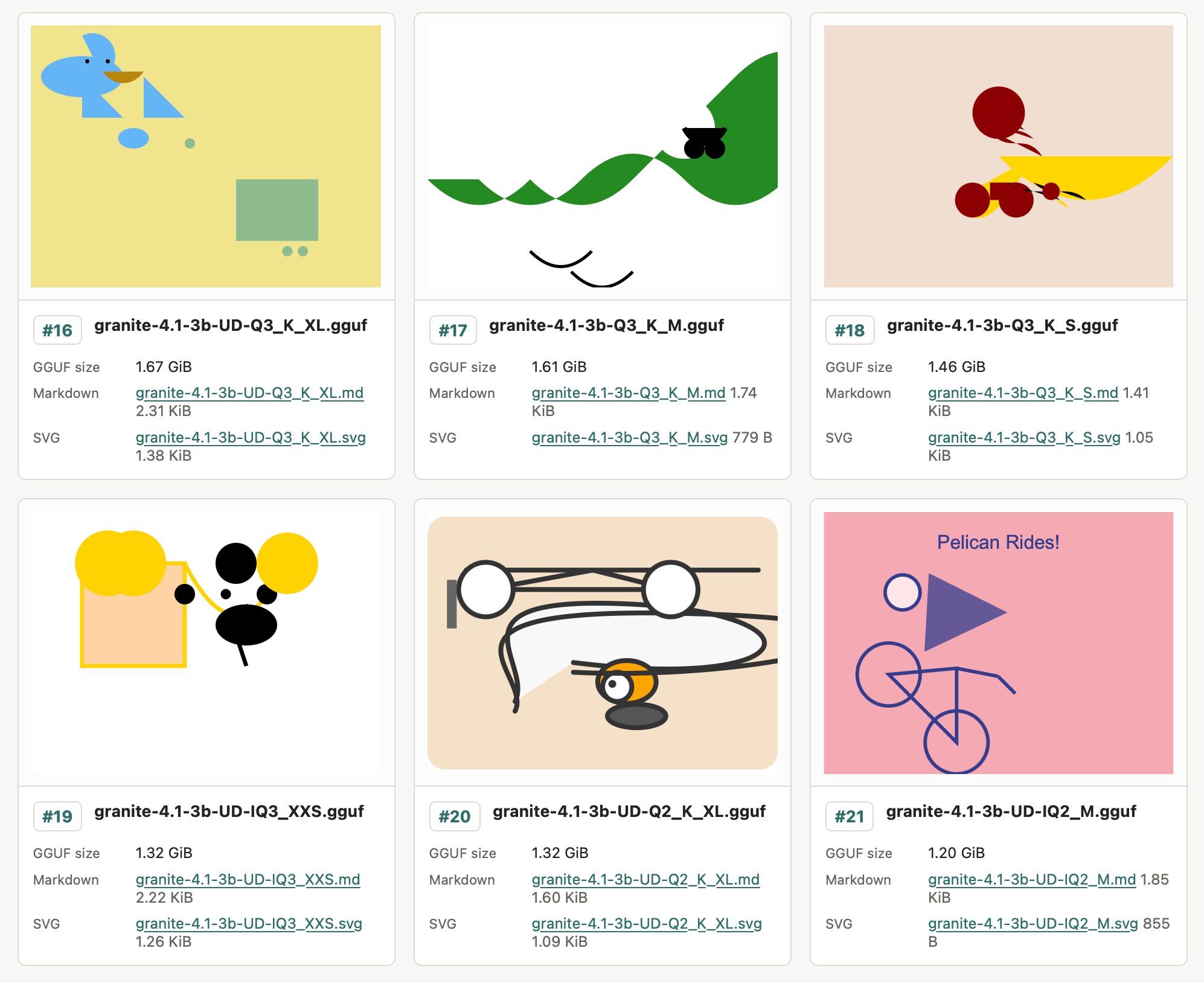
I'll likely try this again in the future with a model that's better at drawing pelicans.
[...] Between 2000 and 2024, farmers sold in total a Colorado-sized chunk of land all on their own, 77 times all land on data center property in 2028, and grew more food than ever on what was left. None of this caused any problems for US food access.
And then, in the middle of all this, a farmer in Loudoun County sells a few acres of mediocre hay field to a hyperscaler for ten times its agricultural value, and the response is that we’re running out of farmland.
— Andy Masley, pushing back against the "land use" argument against data center construction
Salvatore Sanfilippo submitted a PR adding a new data type - arrays - to Redis.
The new commands are ARCOUNT, ARDEL, ARDELRANGE, ARGET, ARGETRANGE, ARGREP, ARINFO, ARINSERT, ARLASTITEMS, ARLEN, ARMGET, ARMSET, ARNEXT, AROP, ARRING, ARSCAN, ARSEEK, ARSET.
The implementation is currently available in a branch, so I had Claude Code for web build this interactive playground for trying out the new commands in a WASM-compiled build of a subset of Redis running in the browser.
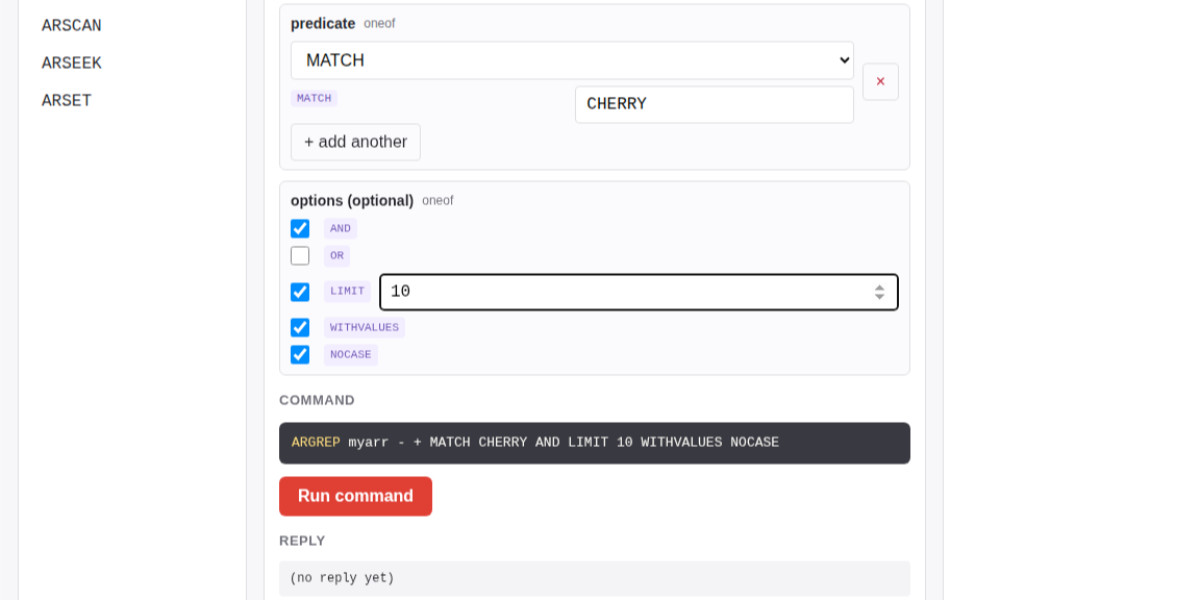
The most interesting new command is ARGREP which can run a server-side grep against a range of values in the array using the newly vendored TRE regex library.
Salvatore wrote more about the AI-assisted development process for the array type in Redis array type: short story of a long development.
We used an automatic classifier which judged sycophancy by looking at whether Claude showed a willingness to push back, maintain positions when challenged, give praise proportional to the merit of ideas, and speak frankly regardless of what a person wants to hear. Most of the time in these situations, Claude expressed no sycophancy—only 9% of conversations included sycophantic behavior (Figure 2). But two domains were exceptions: we saw sycophantic behavior in 38% of conversations focused on spirituality, and 25% of conversations on relationships.
— Anthropic, How people ask Claude for personal guidance
/elsewhere/sightings/. I have a new camera (a Canon R6 Mark II) so I'm taking a lot more photos of birds. I share my best wildlife photos on iNaturalist, and based on yesterday's successful prototype I decided to add those to my blog.
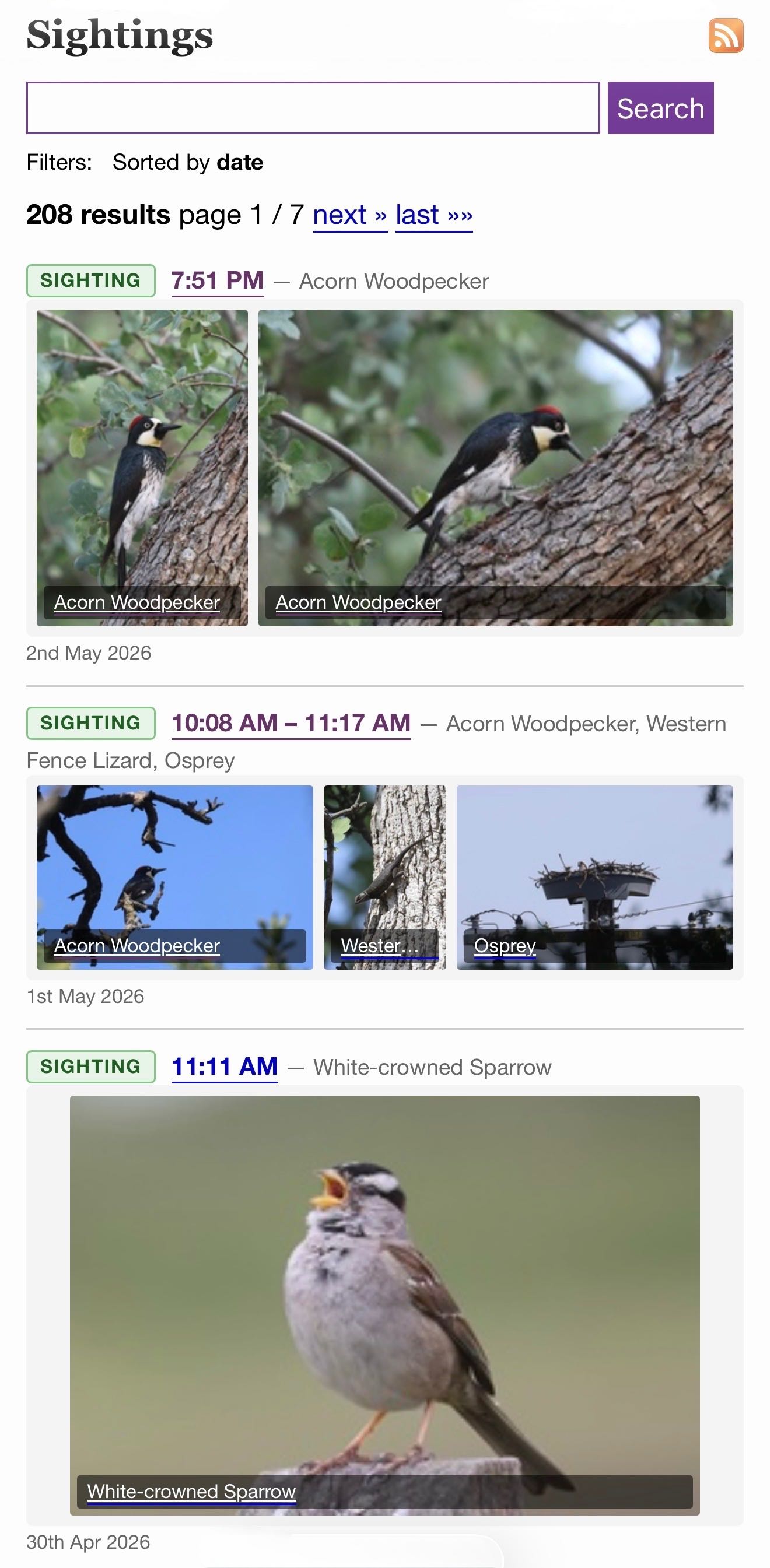
I built this feature on my phone using Claude Code for web, as an extension of my beats system for syndicating external content. Here's the PR and prompt.
As with my other forms of incoming syndicated content sightings show up on the homepage, the date archive pages, and in site search results.
I back-populated over a decade of iNaturalist sightings, which means you that if you search for lemur you'll see my lemur photos from Madagascar in 2019!

I wanted to see my iNaturalist observations - across two separate accounts - grouped by when they occurred. I'm camping this weekend so I built this entirely on my phone using Claude Code for web.
I started by building an inaturalist-clumper Python CLI for fetching and "clumping" observations - by default clumps use observations within 2 hours and 5km of each other.
Then I setup simonw/inaturalist-clumps as a Git scraping repository to run that tool and record the result to clumps.json.
That JSON file is hosted on GitHub, which means it can be fetched by JavaScript using CORS.
Finally I ran this prompt against my simonw/tools repo:
Build inat-sightings.html - an app that does a fetch() against https://raw.githubusercontent.com/simonw/inaturalist-clumps/refs/heads/main/clumps.json and then displays all of the observations on one page using the https://static.inaturalist.org/photos/538073008/small.jpg small.jpg URLs for the thumbnails - with loading=lazy - but when a thumbnail is clicked showing the large.jpg in an HTML modal. Both small and large should include the common species names if available
Codex CLI 0.128.0 adds /goal
(via)
The latest version of OpenAI's Codex CLI coding agent adds their own version of the Ralph loop: you can now set a /goal and Codex will keep on looping until it evaluates that the goal has been completed... or the configured token budget has been exhausted.
It looks like the feature is mainly implemented though the goals/continuation.md and goals/budget_limit.md prompts, which are automatically injected at the end of a turn.
Our evaluation of OpenAI’s GPT-5.5 cyber capabilities. The UK's AI Security Institute previously evaluated Claude Mythos: now they've evaluated GPT-5.5 for finding security vulnerability and found it to be comparable to Mythos, but unlike Mythos it's generally available right now.
It's a common misconception that we can't tell who is using LLM and who is not. I'm sure we didn't catch 100% of LLM-assisted PRs over the past few months, but the kind of mistakes humans make are fundamentally different than LLM hallucinations, making them easy to spot. Furthermore, people who come from the world of agentic coding have a certain digital smell that is not obvious to them but is obvious to those who abstain. It's like when a smoker walks into the room, everybody who doesn't smoke instantly knows it.
I'm not telling you not to smoke, but I am telling you not to smoke in my house.
— Andrew Kelley, Creator of Zig
Zig has one of the most stringent anti-LLM policies of any major open source project:
No LLMs for issues.
No LLMs for pull requests.
No LLMs for comments on the bug tracker, including translation. English is encouraged, but not required. You are welcome to post in your native language and rely on others to have their own translation tools of choice to interpret your words.
The most prominent project written in Zig may be the Bun JavaScript runtime, which was acquired by Anthropic in December 2025 and, unsurprisingly, makes heavy use of AI assistance.
Bun operates its own fork of Zig, and recently achieved a 4x performance improvement on Bun compile after adding "parallel semantic analysis and multiple codegen units to the llvm backend". Here's that code. But @bunjavascript says:
We do not currently plan to upstream this, as Zig has a strict ban on LLM-authored contributions.
(Update: here's a Zig core contributor providing details on why they wouldn't accept that particular patch independent of the LLM issue - parallel semantic analysis is a long planned feature but has implications "for the Zig language itself".)
In Contributor Poker and Zig's AI Ban (via Lobste.rs) Zig Software Foundation VP of Community Loris Cro explains the rationale for this strict ban. It's the best articulation I've seen yet for a blanket ban on LLM-assisted contributions:
In successful open source projects you eventually reach a point where you start getting more PRs than what you’re capable of processing. Given what I mentioned so far, it would make sense to stop accepting imperfect PRs in order to maximize ROI from your work, but that’s not what we do in the Zig project. Instead, we try our best to help new contributors to get their work in, even if they need some help getting there. We don’t do this just because it’s the “right” thing to do, but also because it’s the smart thing to do.
Zig values contributors over their contributions. Each contributor represents an investment by the Zig core team - the primary goal of reviewing and accepting PRs isn't to land new code, it's to help grow new contributors who can become trusted and prolific over time.
LLM assistance breaks that completely. It doesn't matter if the LLM helps you submit a perfect PR to Zig - the time the Zig team spends reviewing your work does nothing to help them add new, confident, trustworthy contributors to their overall project.
Loris explains the name here:
The reason I call it “contributor poker” is because, just like people say about the actual card game, “you play the person, not the cards”. In contributor poker, you bet on the contributor, not on the contents of their first PR.
This makes a lot of sense to me. It relates to an idea I've seen circulating elsewhere: if a PR was mostly written by an LLM, why should a project maintainer spend time reviewing and discussing that PR as opposed to firing up their own LLM to solve the same problem?
LLM 0.32a0 is a major backwards-compatible refactor
I just released LLM 0.32a0, an alpha release of my LLM Python library and CLI tool for accessing LLMs, with some consequential changes that I’ve been working towards for quite a while.
[... 1,874 words]
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query.
— OpenAI Codex base_instructions, for GPT-5.5