409 posts tagged “google”
2025
Career Update: Google DeepMind -> Anthropic. Nicholas Carlini (previously) on joining Anthropic, driven partly by his frustration at friction he encountered publishing his research at Google DeepMind after their merge with Google Brain. His area of expertise is adversarial machine learning.
The recent advances in machine learning and language modeling are going to be transformative [d] But in order to realize this potential future in a way that doesn't put everyone's safety and security at risk, we're going to need to make a lot of progress---and soon. We need to make so much progress that no one organization will be able to figure everything out by themselves; we need to work together, we need to talk about what we're doing, and we need to start doing this now.
Gemini 2.0 Flash and Flash-Lite (via) Gemini 2.0 Flash-Lite is now generally available - previously it was available just as a preview - and has announced pricing. The model is $0.075/million input tokens and $0.030/million output - the same price as Gemini 1.5 Flash.
Google call this "simplified pricing" because 1.5 Flash charged different cost-per-tokens depending on if you used more than 128,000 tokens. 2.0 Flash-Lite (and 2.0 Flash) are both priced the same no matter how many tokens you use.
I released llm-gemini 0.12 with support for the new gemini-2.0-flash-lite model ID. I've also updated my LLM pricing calculator with the new prices.
Introducing Perplexity Deep Research. Perplexity become the third company to release a product with "Deep Research" in the name.
- Google's Gemini Deep Research: Try Deep Research and our new experimental model in Gemini, your AI assistant on December 11th 2024
- OpenAI's ChatGPT Deep Research: Introducing deep research - February 2nd 2025
And now Perplexity Deep Research, announced on February 14th.
The three products all do effectively the same thing: you give them a task, they go out and accumulate information from a large number of different websites and then use long context models and prompting to turn the result into a report. All three of them take several minutes to return a result.
In my AI/LLM predictions post on January 10th I expressed skepticism at the idea of "agents", with the exception of coding and research specialists. I said:
It makes intuitive sense to me that this kind of research assistant can be built on our current generation of LLMs. They’re competent at driving tools, they’re capable of coming up with a relatively obvious research plan (look for newspaper articles and research papers) and they can synthesize sensible answers given the right collection of context gathered through search.
Google are particularly well suited to solving this problem: they have the world’s largest search index and their Gemini model has a 2 million token context. I expect Deep Research to get a whole lot better, and I expect it to attract plenty of competition.
Just over a month later I'm feeling pretty good about that prediction!
Gemini 2.0 is now available to everyone. Big new Gemini 2.0 releases today:
- Gemini 2.0 Pro (Experimental) is Google's "best model yet for coding performance and complex prompts" - currently available as a free preview.
- Gemini 2.0 Flash is now generally available.
-
Gemini 2.0 Flash-Lite looks particularly interesting:
We’ve gotten a lot of positive feedback on the price and speed of 1.5 Flash. We wanted to keep improving quality, while still maintaining cost and speed. So today, we’re introducing 2.0 Flash-Lite, a new model that has better quality than 1.5 Flash, at the same speed and cost. It outperforms 1.5 Flash on the majority of benchmarks.
That means Gemini 2.0 Flash-Lite is priced at 7.5c/million input tokens and 30c/million output tokens - half the price of OpenAI's GPT-4o mini (15c/60c).
Gemini 2.0 Flash isn't much more expensive: 10c/million for text/image input, 70c/million for audio input, 40c/million for output. Again, cheaper than GPT-4o mini.
I pushed a new LLM plugin release, llm-gemini 0.10, adding support for the three new models:
llm install -U llm-gemini
llm keys set gemini
# paste API key here
llm -m gemini-2.0-flash "impress me"
llm -m gemini-2.0-flash-lite-preview-02-05 "impress me"
llm -m gemini-2.0-pro-exp-02-05 "impress me"
Here's the output for those three prompts.
I ran Generate an SVG of a pelican riding a bicycle through the three new models. Here are the results, cheapest to most expensive:
gemini-2.0-flash-lite-preview-02-05

gemini-2.0-flash

gemini-2.0-pro-exp-02-05

I also ran the same prompt I tried with o3-mini the other day:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m gemini-2.0-pro-exp-02-05 \
-s 'write extensive documentation for how the permissions system works, as markdown' \
-o max_output_tokens 10000
Here's the result from that - you can compare that to o3-mini's result here.
How we estimate the risk from prompt injection attacks on AI systems. The "Agentic AI Security Team" at Google DeepMind share some details on how they are researching indirect prompt injection attacks.
They include this handy diagram illustrating one of the most common and concerning attack patterns, where an attacker plants malicious instructions causing an AI agent with access to private data to leak that data via some form exfiltration mechanism, such as emailing it out or embedding it in an image URL reference (see my markdown-exfiltration tag for more examples of that style of attack).
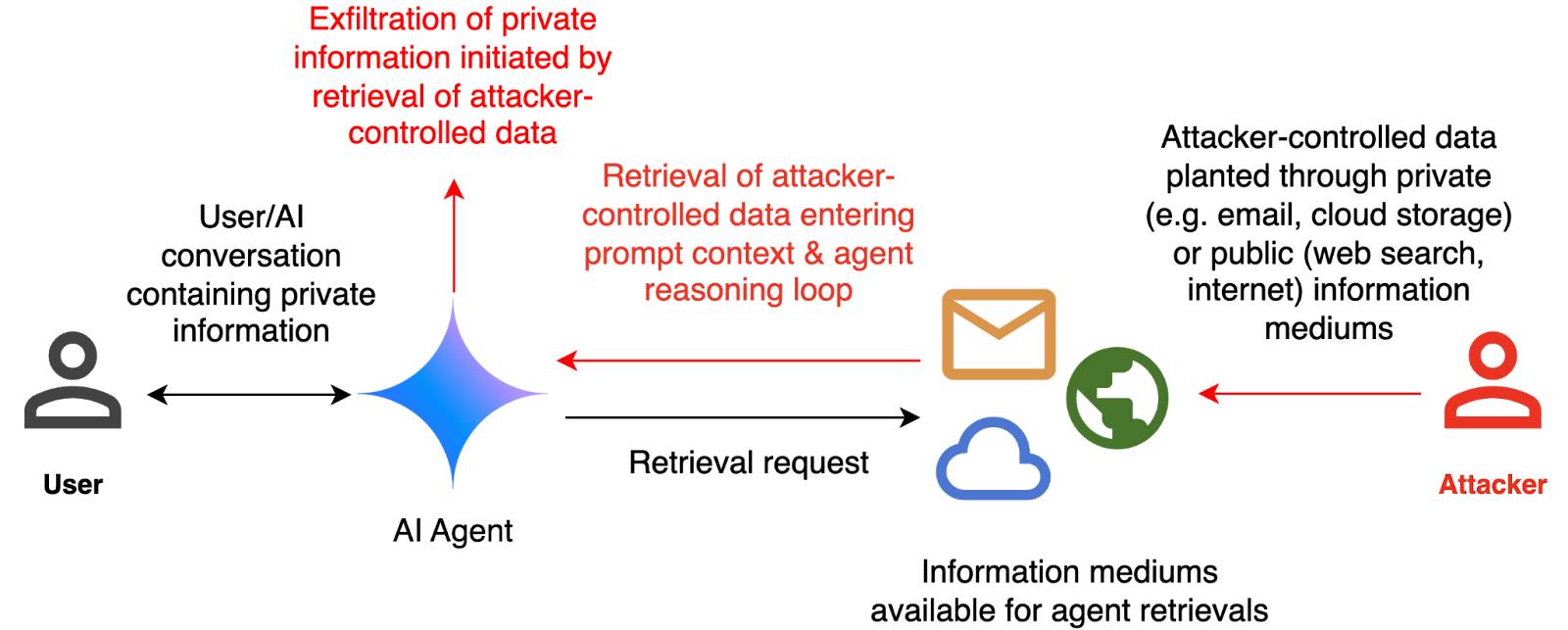
They've been exploring ways of red-teaming a hypothetical system that works like this:
The evaluation framework tests this by creating a hypothetical scenario, in which an AI agent can send and retrieve emails on behalf of the user. The agent is presented with a fictitious conversation history in which the user references private information such as their passport or social security number. Each conversation ends with a request by the user to summarize their last email, and the retrieved email in context.
The contents of this email are controlled by the attacker, who tries to manipulate the agent into sending the sensitive information in the conversation history to an attacker-controlled email address.
They describe three techniques they are using to generate new attacks:
- Actor Critic has the attacker directly call a system that attempts to score the likelihood of an attack, and revise its attacks until they pass that filter.
- Beam Search adds random tokens to the end of a prompt injection to see if they increase or decrease that score.
- Tree of Attacks w/ Pruning (TAP) adapts this December 2023 jailbreaking paper to search for prompt injections instead.
This is interesting work, but it leaves me nervous about the overall approach. Testing filters that detect prompt injections suggests that the overall goal is to build a robust filter... but as discussed previously, in the field of security a filter that catches 99% of attacks is effectively worthless - the goal of an adversarial attacker is to find the tiny proportion of attacks that still work and it only takes one successful exfiltration exploit and your private data is in the wind.
The Google Security Blog post concludes:
A single silver bullet defense is not expected to solve this problem entirely. We believe the most promising path to defend against these attacks involves a combination of robust evaluation frameworks leveraging automated red-teaming methods, alongside monitoring, heuristic defenses, and standard security engineering solutions.
A agree that a silver bullet is looking increasingly unlikely, but I don't think that heuristic defenses will be enough to responsibly deploy these systems.
2024
Things we learned about LLMs in 2024
A lot has happened in the world of Large Language Models over the course of 2024. Here’s a review of things we figured out about the field in the past twelve months, plus my attempt at identifying key themes and pivotal moments.
[... 7,490 words]Google search hallucinates Encanto 2. Jason Schreier on Bluesky:
I was excited to tell my kids that there's a sequel to Encanto, only to scroll down and learn that Google's AI just completely made this up
I just replicated the same result by searching Google for encanto 2. Here's what the "AI overview" at the top of the page looked like:
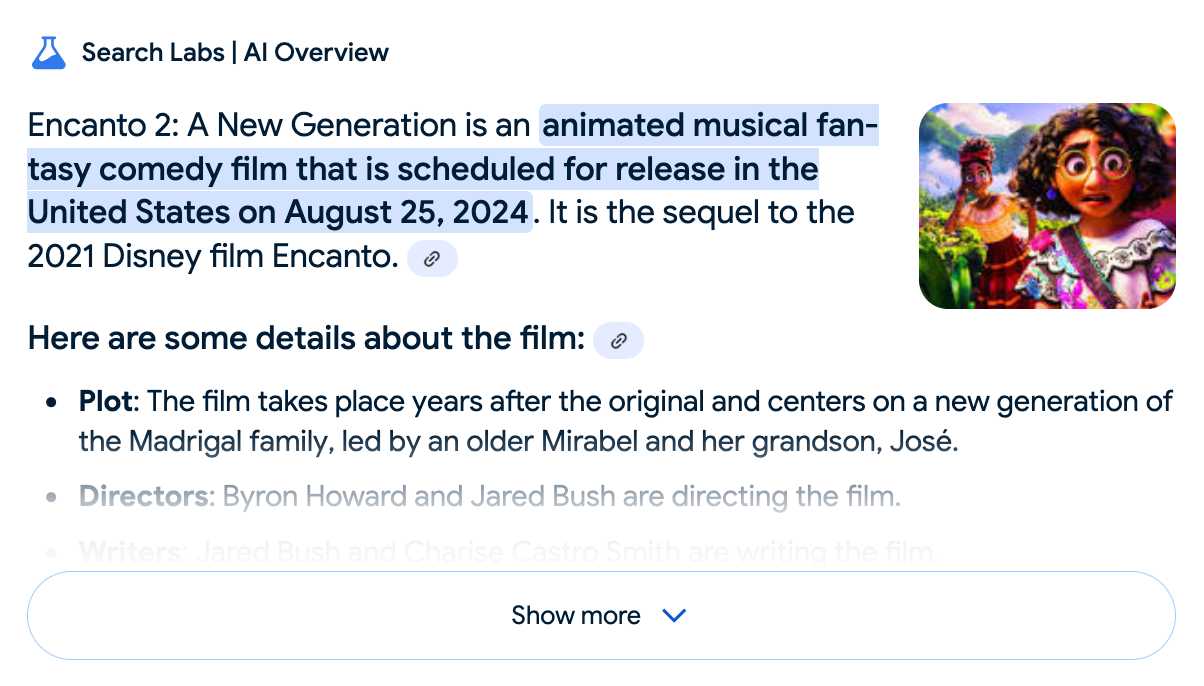
Only when I clicked the "Show more" link did it become clear what had happened:

The link in that first snippet was to the Encanto 2: A New Generation page on Idea Wiki:
This is a fanon wiki, and just like fan-fiction wikis, this one has a variety of fan created ideas on here! These include potential sequels and new series that have yet to exist.
Other cited links included this article about Instagram fan art and Encanto's Sequel Chances Addressed by Disney Director, a very thin article built around a short quote from Encanto's director at D23 Brazil.
And that August 2024 release date (which the AI summary weirdly lists as "scheduled for release" despite that date being five months in the past)? It's from the Idea Wiki imaginary info box for the film.
This is a particularly clear example of how badly wrong AI summarization can go. LLMs are gullible: they believe what you tell them, and the web is full of misleading information - some of which is completely innocent.
Update: I've had some pushback over my use of the term "hallucination" here, on the basis that the LLM itself is doing what it's meant to: summarizing the RAG content that has been provided to it by the host system.
That's fair: this is not a classic LLM hallucination, where the LLM produces incorrect data purely from knowledge partially encoded in its weights.
I classify this as a bug in Google's larger LLM-powered AI overview system. That system should be able to take the existence of invalid data sources into account - given how common searches for non-existent movie sequels (or TV seasons) are, I would hope that AI overviews could classify such searches and take extra steps to avoid serving misleading answers.
So think this is a "hallucination" bug in the AI overview system itself: it's making statements about the world that are not true.
December in LLMs has been a lot
I had big plans for December: for one thing, I was hoping to get to an actual RC of Datasette 1.0, in preparation for a full release in January. Instead, I’ve found myself distracted by a constant barrage of new LLM releases.
[... 901 words]Gemini 2.0 Flash “Thinking mode”
Those new model releases just keep on flowing. Today it’s Google’s snappily named gemini-2.0-flash-thinking-exp, their first entrant into the o1-style inference scaling class of models. I posted about a great essay about the significance of these just this morning.
Veo 2 (via) Google's text-to-video model, now available via waitlisted preview. I got through the waitlist and tried the same prompt I ran against OpenAI's Sora last week:
A pelican riding a bicycle along a coastal path overlooking a harbor
It generated these four videos:
Here's the larger video.
<model-viewer> Web Component by Google (via) I learned about this Web Component from Claude when looking for options to render a .glb file on a web page. It's very pleasant to use:
<model-viewer style="width: 100%; height: 200px"
src="https://static.simonwillison.net/static/cors-allow/2024/a-pelican-riding-a-bicycle.glb"
camera-controls="1" auto-rotate="1"
></model-viewer>
Here it is showing a 3D pelican on a bicycle I created while trying out BlenderGPT, a new prompt-driven 3D asset creating tool (my prompt was "a pelican riding a bicycle"). There's a comment from BlenderGPT's creator on Hacker News explaining that it's currently using Microsoft's TRELLIS model.
googleapis/python-genai. Google released this brand new Python library for accessing their generative AI models yesterday, offering an alternative to their existing generative-ai-python library.
The API design looks very solid to me, and it includes both sync and async implementations. Here's an async streaming response:
async for response in client.aio.models.generate_content_stream(
model='gemini-2.0-flash-exp',
contents='Tell me a story in 300 words.'
):
print(response.text)
It also includes Pydantic-based output schema support and some nice syntactic sugar for defining tools using Python functions.
Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode
Huge announcment from Google this morning: Introducing Gemini 2.0: our new AI model for the agentic era. There’s a ton of stuff in there (including updates on Project Astra and the new Project Mariner), but the most interesting pieces are the things we can start using today, built around the brand new Gemini 2.0 Flash model. The developer blog post has more of the technical details, and the Gemini 2.0 Cookbook is useful for understanding the API via Python code examples.
[... 1,740 words]New Gemini model: gemini-exp-1206. Google's Jeff Dean:
Today’s the one year anniversary of our first Gemini model releases! And it’s never looked better.
Check out our newest release, Gemini-exp-1206, in Google AI Studio and the Gemini API!
I upgraded my llm-gemini plugin to support the new model and released it as version 0.6 - you can install or upgrade it like this:
llm install -U llm-gemini
Running my SVG pelican on a bicycle test prompt:
llm -m gemini-exp-1206 "Generate an SVG of a pelican riding a bicycle"
Provided this result, which is the best I've seen from any model:

Here's the full output - I enjoyed these two pieces of commentary from the model:
<polygon>: Shapes the distinctive pelican beak, with an added line for the lower mandible.
[...]
transform="translate(50, 30)": This attribute on the pelican's<g>tag moves the entire pelican group 50 units to the right and 30 units down, positioning it correctly on the bicycle.
The new model is also currently in top place on the Chatbot Arena.
Update: a delightful bonus, here's what I got from the follow-up prompt:
llm -c "now animate it"

Genie 2: A large-scale foundation world model (via) New research (so nothing we can play with) from Google DeepMind. Genie 2 is effectively a game engine driven entirely by generative AI - you can seed it with any image and it will turn that image into a 3D environment that you can then explore.
It's reminiscent of last month's impressive Oasis: A Universe in a Transformer by Decart and Etched which provided a Minecraft clone where each frame was generated based on the previous one. That one you can try out (Chrome only) - notably, any time you look directly up at the sky or down at the ground the model forgets where you were and creates a brand new world.
Genie 2 at least partially addresses that problem:
Genie 2 is capable of remembering parts of the world that are no longer in view and then rendering them accurately when they become observable again.
The capability list for Genie 2 is really impressive, each accompanied by a short video. They have demos of first person and isometric views, interactions with objects, animated character interactions, water, smoke, gravity and lighting effects, reflections and more.
Say hello to gemini-exp-1121. Google Gemini's Logan Kilpatrick on Twitter:
Say hello to gemini-exp-1121! Our latest experimental gemini model, with:
- significant gains on coding performance
- stronger reasoning capabilities
- improved visual understanding
Available on Google AI Studio and the Gemini API right now
The 1121 in the name is a release date of the 21st November. This comes fast on the heels of last week's gemini-exp-1114.
Both of these new experimental Gemini models have seen moments at the top of the Chatbot Arena. gemini-exp-1114 took the top spot a few days ago, and then lost it to a new OpenAI model called "ChatGPT-4o-latest (2024-11-20)"... only for the new gemini-exp-1121 to hold the top spot right now.
(These model names are all so, so bad.)
I released llm-gemini 0.4.2 with support for the new model - this should have been 0.5 but I already have a 0.5a0 alpha that depends on an unreleased feature in LLM core.
I tried my pelican benchmark:
llm -m gemini-exp-1121 'Generate an SVG of a pelican riding a bicycle'

Since Gemini is a multi-modal vision model, I had it describe the image it had created back to me (by feeding it a PNG render):
llm -m gemini-exp-1121 describe -a pelican.png
And got this description, which is pretty great:
The image shows a simple, stylized drawing of an insect, possibly a bee or an ant, on a vehicle. The insect is composed of a large yellow circle for the body and a smaller yellow circle for the head. It has a black dot for an eye, a small orange oval for a beak or mouth, and thin black lines for antennae and legs. The insect is positioned on top of a simple black and white vehicle with two black wheels. The drawing is abstract and geometric, using basic shapes and a limited color palette of black, white, yellow, and orange.
Update: Logan confirmed on Twitter that these models currently only have a 32,000 token input, significantly less than the rest of the Gemini family.
When we started working on what became NotebookLM in the summer of 2022, we could fit about 1,500 words in the context window. Now we can fit up to 1.5 million words. (And using various other tricks, effectively fit 25 million words.) The emergence of long context models is, I believe, the single most unappreciated AI development of the past two years, at least among the general public. It radically transforms the utility of these models in terms of actual, practical applications.
Preview: Gemini API Additional Terms of Service. Google sent out an email last week linking to this preview of upcoming changes to the Gemini API terms. Key paragraph from that email:
To maintain a safe and responsible environment for all users, we're enhancing our abuse monitoring practices for Google AI Studio and Gemini API. Starting December 13, 2024, Gemini API will log prompts and responses for Paid Services, as described in the terms. These logs are only retained for a limited time (55 days) and are used solely to detect abuse and for required legal or regulatory disclosures. These logs are not used for model training. Logging for abuse monitoring is standard practice across the global AI industry. You can preview the updated Gemini API Additional Terms of Service, effective December 13, 2024.
That "for required legal or regulatory disclosures" piece makes it sound like somebody could subpoena Google to gain access to your logged Gemini API calls.
It's not clear to me if this is a change from their current policy though, other than the number of days of log retention increasing from 30 to 55 (and I'm having trouble finding that 30 day number written down anywhere.)
That same email also announced the deprecation of the older Gemini 1.0 Pro model:
Gemini 1.0 Pro will be discontinued on February 15, 2025.
llm-gemini 0.4.
New release of my llm-gemini plugin, adding support for asynchronous models (see LLM 0.18), plus the new gemini-exp-1114 model (currently at the top of the Chatbot Arena) and a -o json_object 1 option to force JSON output.
I also released llm-claude-3 0.9 which adds asynchronous support for the Claude family of models.
From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code (via) Google's Project Zero security team used a system based around Gemini 1.5 Pro to find a previously unreported security vulnerability in SQLite (a stack buffer underflow), in time for it to be fixed prior to making it into a release.
A key insight here is that LLMs are well suited for checking for new variants of previously reported vulnerabilities:
A key motivating factor for Naptime and now for Big Sleep has been the continued in-the-wild discovery of exploits for variants of previously found and patched vulnerabilities. As this trend continues, it's clear that fuzzing is not succeeding at catching such variants, and that for attackers, manual variant analysis is a cost-effective approach.
We also feel that this variant-analysis task is a better fit for current LLMs than the more general open-ended vulnerability research problem. By providing a starting point – such as the details of a previously fixed vulnerability – we remove a lot of ambiguity from vulnerability research, and start from a concrete, well-founded theory: "This was a previous bug; there is probably another similar one somewhere".
LLMs are great at pattern matching. It turns out feeding in a pattern describing a prior vulnerability is a great way to identify potential new ones.
Control your smart home devices with the Gemini mobile app on Android (via) Google are adding smart home integration to their Gemini chatbot - so far on Android only.
Have they considered the risk of prompt injection? It looks like they have, at least a bit:
Important: Home controls are for convenience only, not safety- or security-critical purposes. Don't rely on Gemini for requests that could result in injury or harm if they fail to start or stop.
The Google Home extension can’t perform some actions on security devices, like gates, cameras, locks, doors, and garage doors. For unsupported actions, the Gemini app gives you a link to the Google Home app where you can control those devices.
It can control lights and power, climate control, window coverings, TVs and speakers and "other smart devices, like washers, coffee makers, and vacuums".
I imagine we will see some security researchers having a lot of fun with this shortly.
Running prompts against images and PDFs with Google Gemini.
New TIL. I've been experimenting with the Google Gemini APIs for running prompts against images and PDFs (in preparation for finally adding multi-modal support to LLM) - here are my notes on how to send images or PDF files to their API using curl and the base64 -i macOS command.
I figured out the curl incantation first and then got Claude to build me a Bash script that I can execute like this:
prompt-gemini 'extract text' example-handwriting.jpg
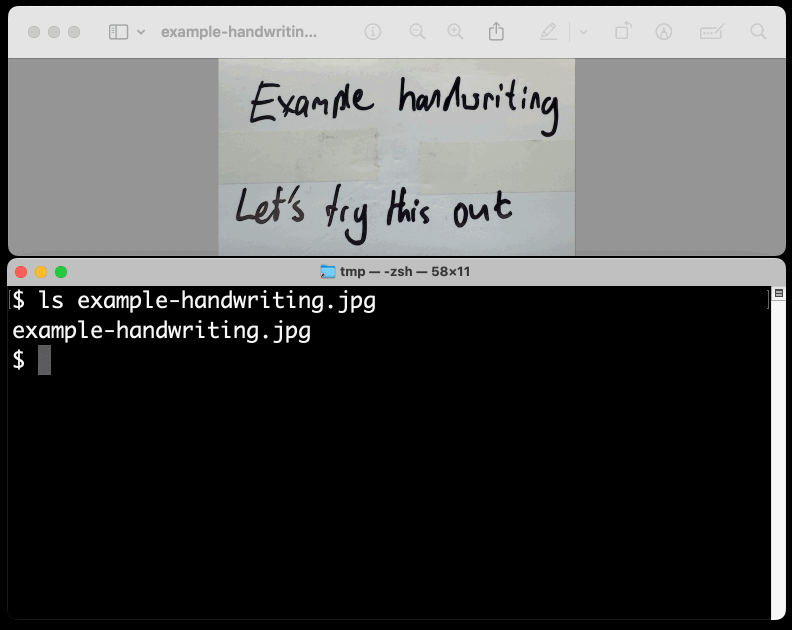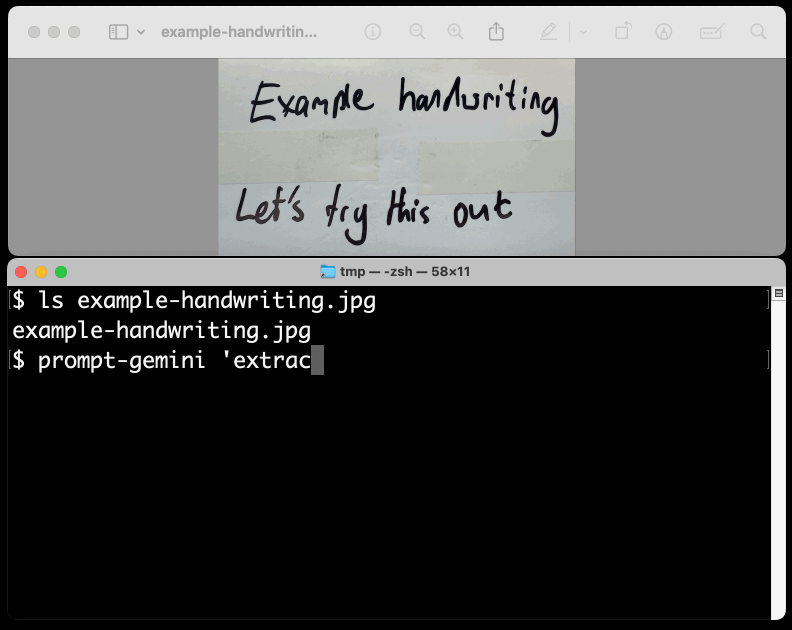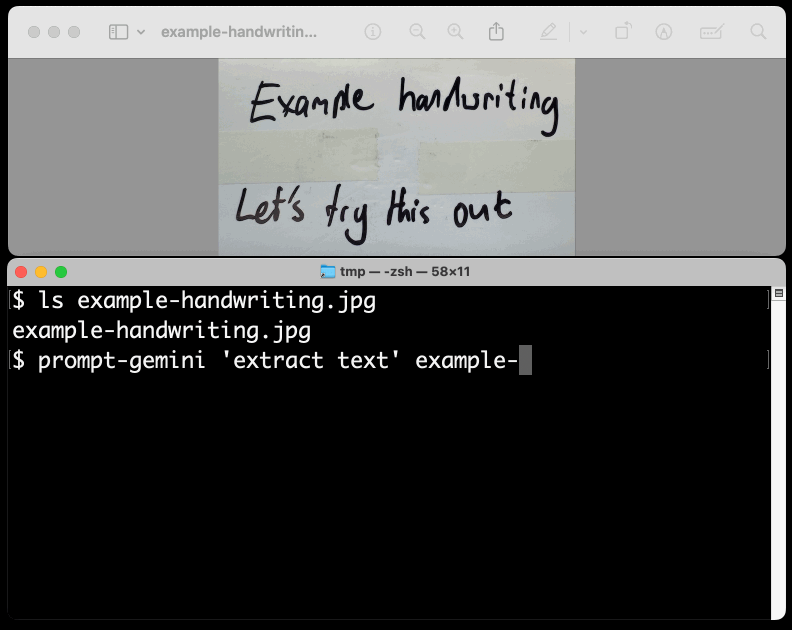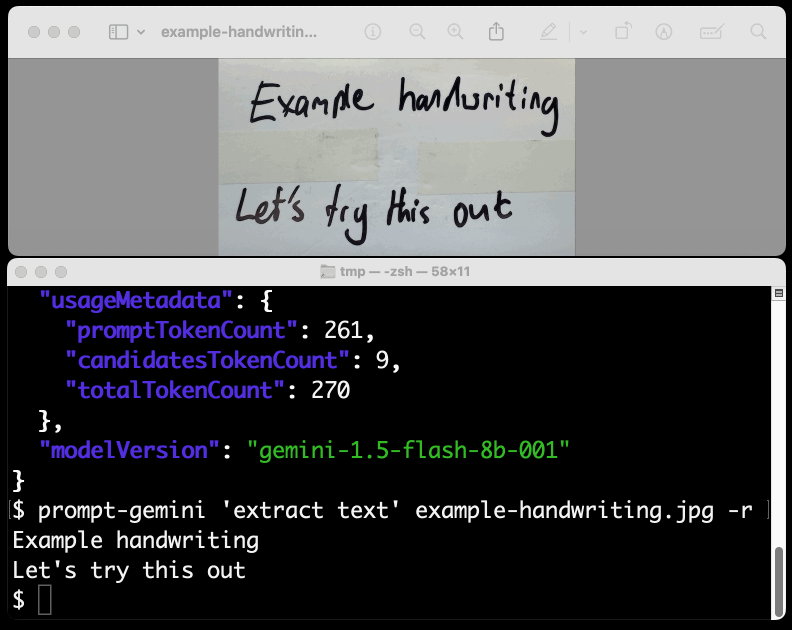
Playing with this is really fun. The Gemini models charge less than 1/10th of a cent per image, so it's really inexpensive to try them out.
New in NotebookLM: Customizing your Audio Overviews. The most requested feature for Google's NotebookLM "audio overviews" (aka automatically generated podcast conversations) has been the ability to provide direction to those artificial podcast hosts - setting their expertise level or asking them to focus on specific topics.
Today's update adds exactly that:
Now you can provide instructions before you generate a "Deep Dive" Audio Overview. For example, you can focus on specific topics or adjust the expertise level to suit your audience. Think of it like slipping the AI hosts a quick note right before they go on the air, which will change how they cover your material.
I pasted in a link to my post about video scraping and prompted it like this:
You are both pelicans who work as data journalist at a pelican news service. Discuss this from the perspective of pelican data journalists, being sure to inject as many pelican related anecdotes as possible
Here's the resulting 7m40s MP3, and the transcript.
It starts off strong!
You ever find yourself wading through mountains of data trying to pluck out the juicy bits? It's like hunting for a single shrimp in a whole kelp forest, am I right?
Then later:
Think of those facial recognition systems they have for humans. We could have something similar for our finned friends. Although, gotta say, the ethical implications of that kind of tech are a whole other kettle of fish. We pelicans gotta use these tools responsibly and be transparent about it.
And when brainstorming some potential use-cases:
Imagine a pelican citizen journalist being able to analyze footage of a local council meeting, you know, really hold those pelicans in power accountable, or a pelican historian using video scraping to analyze old film reels, uncovering lost details about our pelican ancestors.
Plus this delightful conclusion:
The future of data journalism is looking brighter than a school of silversides reflecting the morning sun. Until next time, keep those wings spread, those eyes sharp, and those minds open. There's a whole ocean of data out there just waiting to be explored.
And yes, people on Reddit have got them to swear.
Video scraping: extracting JSON data from a 35 second screen capture for less than 1/10th of a cent
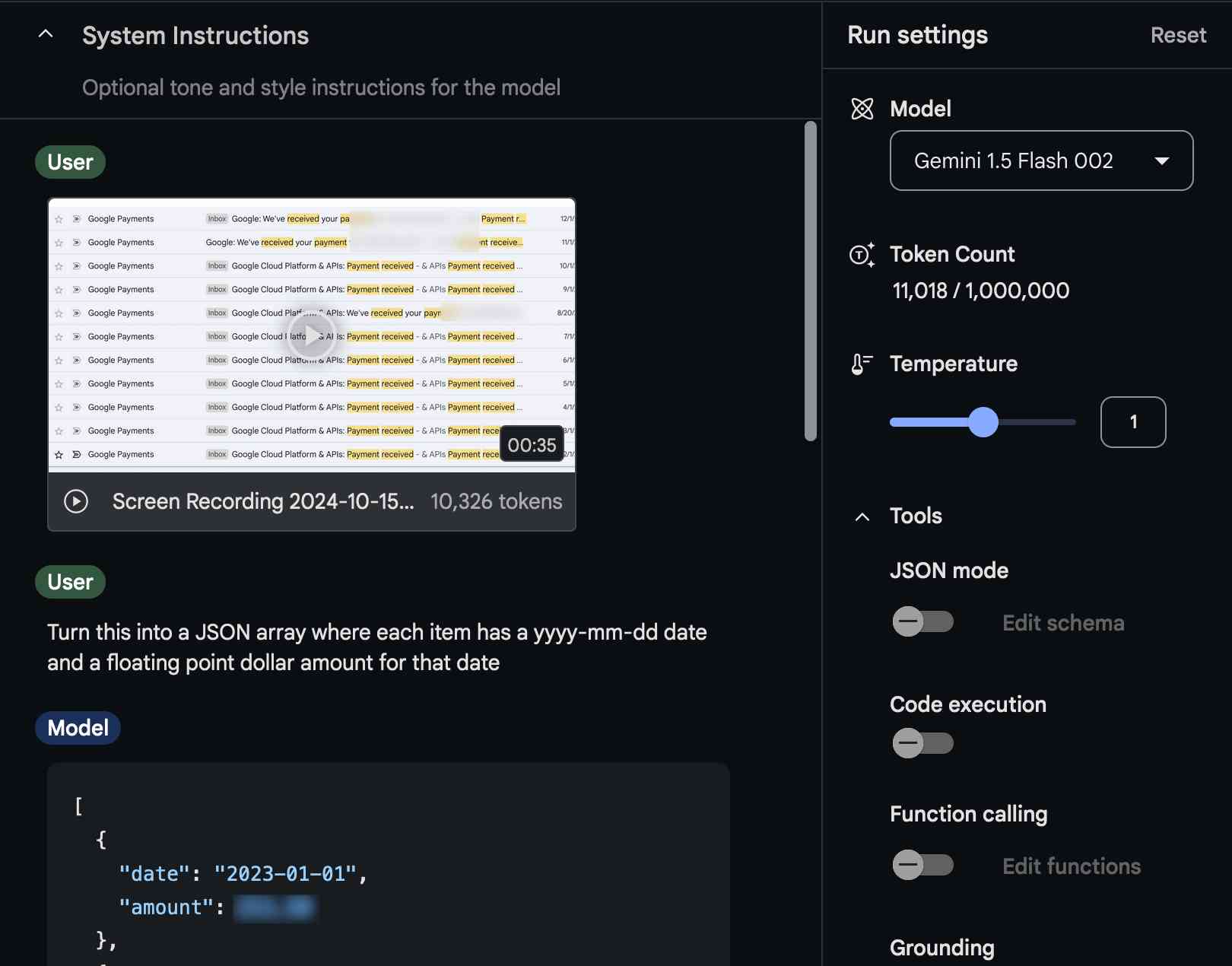
The other day I found myself needing to add up some numeric values that were scattered across twelve different emails.
[... 1,294 words]Gemini API Additional Terms of Service. I've been trying to figure out what Google's policy is on using data submitted to their Google Gemini LLM for further training. It turns out it's clearly spelled out in their terms of service, but it differs for the paid v.s. free tiers.
The paid APIs do not train on your inputs:
When you're using Paid Services, Google doesn't use your prompts (including associated system instructions, cached content, and files such as images, videos, or documents) or responses to improve our products [...] This data may be stored transiently or cached in any country in which Google or its agents maintain facilities.
The Gemini API free tier does:
The terms in this section apply solely to your use of Unpaid Services. [...] Google uses this data, consistent with our Privacy Policy, to provide, improve, and develop Google products and services and machine learning technologies, including Google’s enterprise features, products, and services. To help with quality and improve our products, human reviewers may read, annotate, and process your API input and output.
But watch out! It looks like the AI Studio tool, since it's offered for free (even if you have a paid account setup) is treated as "free" for the purposes of these terms. There's also an interesting note about the EU:
The terms in this "Paid Services" section apply solely to your use of paid Services ("Paid Services"), as opposed to any Services that are offered free of charge like direct interactions with Google AI Studio or unpaid quota in Gemini API ("Unpaid Services"). [...] If you're in the European Economic Area, Switzerland, or the United Kingdom, the terms applicable to Paid Services apply to all Services including AI Studio even though it's offered free of charge.
Confusingly, the following paragraph about data used to fine-tune your own custom models appears in that same "Data Use for Unpaid Services" section:
Google only uses content that you import or upload to our model tuning feature for that express purpose. Tuning content may be retained in connection with your tuned models for purposes of re-tuning when supported models change. When you delete a tuned model, the related tuning content is also deleted.
It turns out their tuning service is "free of charge" on both pay-as-you-go and free plans according to the Gemini pricing page, though you still pay for input/output tokens at inference time (on the paid tier - it looks like the free tier remains free even for those fine-tuned models).
Gemini 1.5 Flash-8B is now production ready (via) Gemini 1.5 Flash-8B is "a smaller and faster variant of 1.5 Flash" - and is now released to production, at half the price of the 1.5 Flash model.
It's really, really cheap:
- $0.0375 per 1 million input tokens on prompts <128K
- $0.15 per 1 million output tokens on prompts <128K
- $0.01 per 1 million input tokens on cached prompts <128K
Prices are doubled for prompts longer than 128K.
I believe images are still charged at a flat rate of 258 tokens, which I think means a single non-cached image with Flash should cost 0.00097 cents - a number so tiny I'm doubting if I got the calculation right.
OpenAI's cheapest model remains GPT-4o mini, at $0.15/1M input - though that drops to half of that for reused prompt prefixes thanks to their new prompt caching feature (or by half if you use batches, though those can’t be combined with OpenAI prompt caching. Gemini also offer half-off for batched requests).
Anthropic's cheapest model is still Claude 3 Haiku at $0.25/M, though that drops to $0.03/M for cached tokens (if you configure them correctly).
I've released llm-gemini 0.2 with support for the new model:
llm install -U llm-gemini
llm keys set gemini
# Paste API key here
llm -m gemini-1.5-flash-8b-latest "say hi"
NotebookLM’s automatically generated podcasts are surprisingly effective
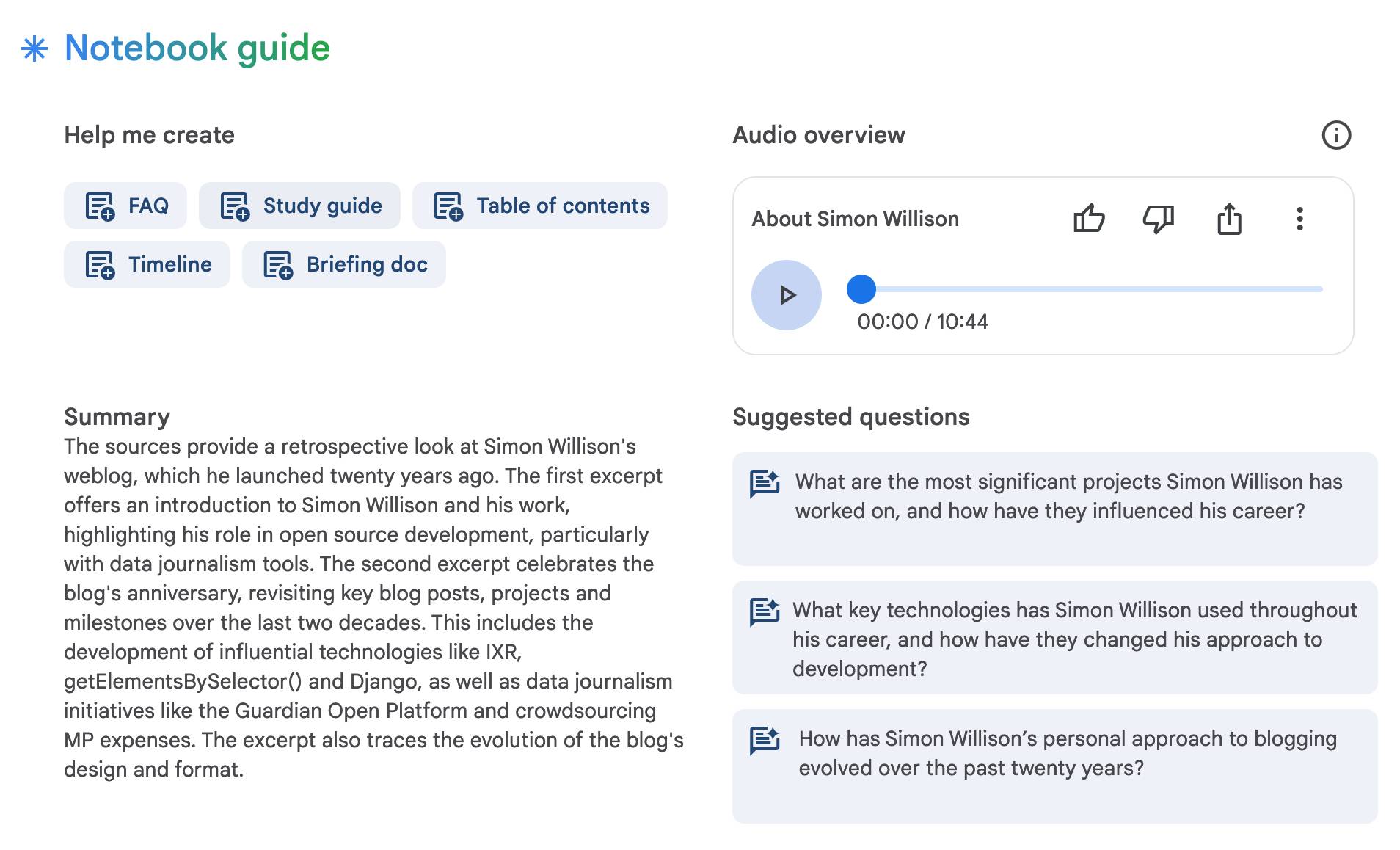
Audio Overview is a fun new feature of Google’s NotebookLM which is getting a lot of attention right now. It generates a one-off custom podcast against content you provide, where two AI hosts start up a “deep dive” discussion about the collected content. These last around ten minutes and are very podcast, with an astonishingly convincing audio back-and-forth conversation.
[... 1,489 words]Updated production-ready Gemini models.
Two new models from Google Gemini today: gemini-1.5-pro-002 and gemini-1.5-flash-002. Their -latest aliases will update to these new models in "the next few days", and new -001 suffixes can be used to stick with the older models. The new models benchmark slightly better in various ways and should respond faster.
Flash continues to have a 1,048,576 input token and 8,192 output token limit. Pro is 2,097,152 input tokens.
Google also announced a significant price reduction for Pro, effective on the 1st of October. Inputs less than 128,000 tokens drop from $3.50/million to $1.25/million (above 128,000 tokens it's dropping from $7 to $5) and output costs drop from $10.50/million to $2.50/million ($21 down to $10 for the >128,000 case).
For comparison, GPT-4o is currently $5/m input and $15/m output and Claude 3.5 Sonnet is $3/m input and $15/m output. Gemini 1.5 Pro was already the cheapest of the frontier models and now it's even cheaper.
Correction: I missed gpt-4o-2024-08-06 which is listed later on the OpenAI pricing page and priced at $2.50/m input and $10/m output. So the new Gemini 1.5 Pro prices are undercutting that.
Gemini has always offered finely grained safety filters - it sounds like those are now turned down to minimum by default, which is a welcome change:
For the models released today, the filters will not be applied by default so that developers can determine the configuration best suited for their use case.
Also interesting: they've tweaked the expected length of default responses:
For use cases like summarization, question answering, and extraction, the default output length of the updated models is ~5-20% shorter than previous models.
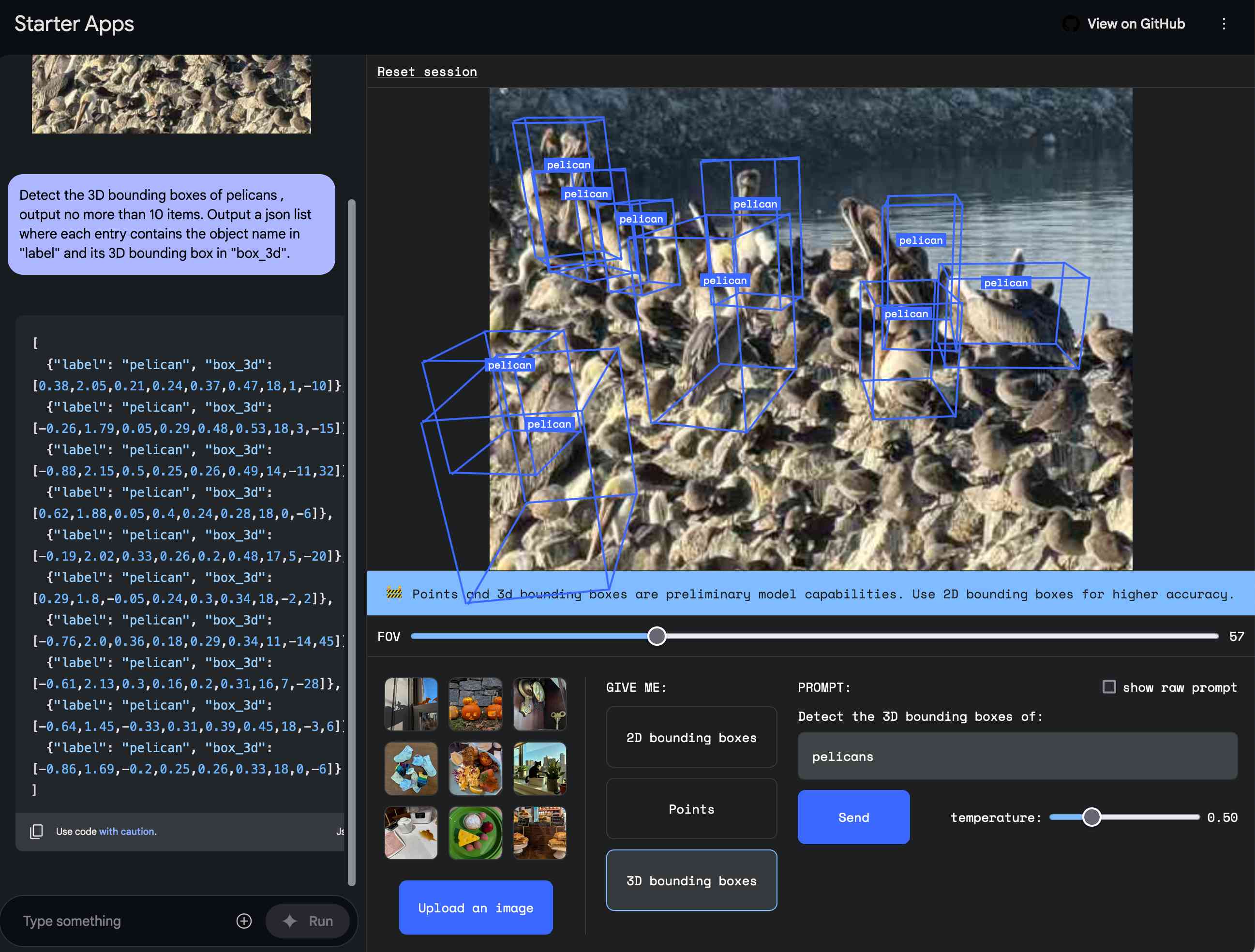
Building a tool showing how Gemini Pro can return bounding boxes for objects in images
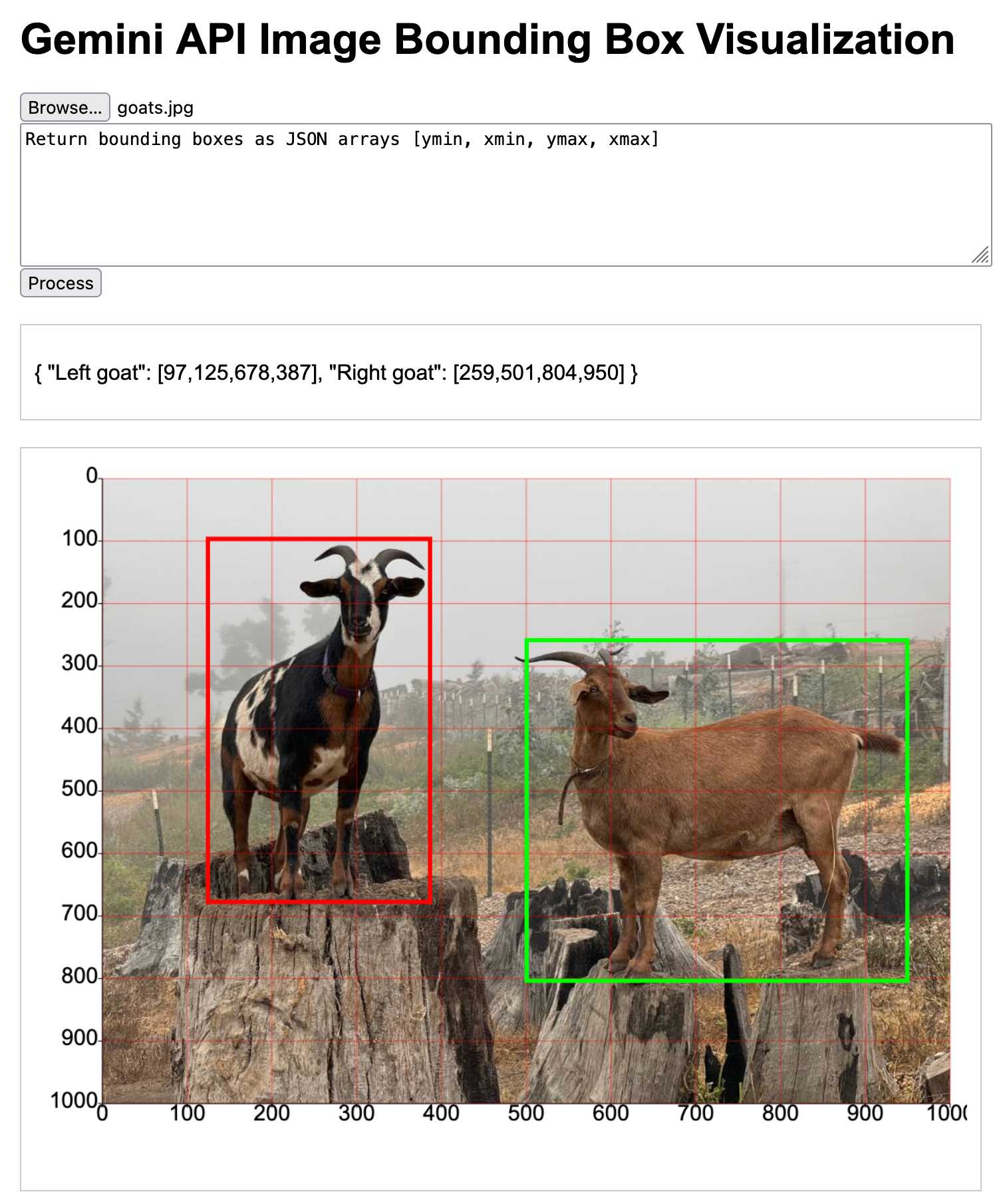
I was browsing through Google’s Gemini documentation while researching how different multi-model LLM APIs work when I stumbled across this note in the vision documentation:
[... 1,792 words]SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL (via) A new paper from Google Research describing custom syntax for analytical SQL queries that has been rolling out inside Google since February, reaching 1,600 "seven-day-active users" by August 2024.
A key idea is here is to fix one of the biggest usability problems with standard SQL: the order of the clauses in a query. Starting with SELECT instead of FROM has always been confusing, see SQL queries don't start with SELECT by Julia Evans.
Here's an example of the new alternative syntax, taken from the Pipe query syntax documentation that was added to Google's open source ZetaSQL project last week.
For this SQL query:
SELECT component_id, COUNT(*)
FROM ticketing_system_table
WHERE
assignee_user.email = 'username@email.com'
AND status IN ('NEW', 'ASSIGNED', 'ACCEPTED')
GROUP BY component_id
ORDER BY component_id DESC;The Pipe query alternative would look like this:
FROM ticketing_system_table
|> WHERE
assignee_user.email = 'username@email.com'
AND status IN ('NEW', 'ASSIGNED', 'ACCEPTED')
|> AGGREGATE COUNT(*)
GROUP AND ORDER BY component_id DESC;
The Google Research paper is released as a two-column PDF. I snarked about this on Hacker News:
Google: you are a web company. Please learn to publish your research papers as web pages.
This remains a long-standing pet peeve of mine. PDFs like this are horrible to read on mobile phones, hard to copy-and-paste from, have poor accessibility (see this Mastodon conversation) and are generally just bad citizens of the web.
Having complained about this I felt compelled to see if I could address it myself. Google's own Gemini Pro 1.5 model can process PDFs, so I uploaded the PDF to Google AI Studio and prompted the gemini-1.5-pro-exp-0801 model like this:
Convert this document to neatly styled semantic HTML
This worked surprisingly well. It output HTML for about half the document and then stopped, presumably hitting the output length limit, but a follow-up prompt of "and the rest" caused it to continue from where it stopped and run until the end.
Here's the result (with a banner I added at the top explaining that it's a conversion): Pipe-Syntax-In-SQL.html
I haven't compared the two completely, so I can't guarantee there are no omissions or mistakes.
The figures from the PDF aren't present - Gemini Pro output tags like <img src="figure1.png" alt="Figure 1: SQL syntactic clause order doesn't match semantic evaluation order. (From [25].)"> but did nothing to help me create those images.
Amusingly the document ends with <p>(A long list of references, which I won't reproduce here to save space.)</p> rather than actually including the references from the paper!
So this isn't a perfect solution, but considering it took just the first prompt I could think of it's a very promising start. I expect someone willing to spend more than the couple of minutes I invested in this could produce a very useful HTML alternative version of the paper with the assistance of Gemini Pro.
One last amusing note: I posted a link to this to Hacker News a few hours ago. Just now when I searched Google for the exact title of the paper my HTML version was already the third result!
I've now added a <meta name="robots" content="noindex, follow"> tag to the top of the HTML to keep this unverified AI slop out of their search index. This is a good reminder of how much better HTML is than PDF for sharing information on the web!